
基于长短期记忆神经网络的暖通空调系统能耗预测
2019-04-10 08:58廖文强王江宇陈焕新丁新磊尚鹏涛魏文天周镇新
制冷技术 2019年1期
廖文强,王江宇,陈焕新*,丁新磊,尚鹏涛,魏文天,周镇新
(1-华中科技大学中欧清洁与可再生能源学院,湖北武汉 430074; 2-华中科技大学能源与动力工程学院,湖北武汉430074)
0 引言
近年来我国经济一直处于高速发展的状态,同时能源消耗量也在不断地增长。2017年,我国能源消耗总量为 3,105 Mtoe(Million Tons of Oil Equivalent,百万吨石油当量),超过美国成为全球头号能源消耗巨头,占据着世界能源消耗总量的22%,并且还在不断地增长,2017年的能源消耗增长率达到2.3%,是2016年能源消耗增长率1.1%的两倍以上[1]。其中,建筑能耗占据着很重要的一部分,比重可达30%~40%[2-3],在建筑能耗中,暖通空调系统对能源的消耗量会占据30%~55%不等甚至更高[4-5]。
对于如何降低暖通空调系统能耗的研究一直都在不断地进行,其中很重要的一部分就是对暖通空调系统能耗的预测研究。周旋等[6]使用基于小波分解和支持向量机的方法对办公建筑空调负荷进行预测。张梦成等[7]使用基于FCM优化神经网络的方法对办公楼空调负荷进行预测。通过对暖通空调系统能耗的预测,分析高低能耗原因,调整系统的运行策略达到节能目的。KAWASHIMA[8]用人工神经网络(Artificial Neural Network,ANN)将空调负荷预测和控制结合起来,实验结果是ANN预测控制的耗电量比制冷机正常运行下的耗电量减少了6.9%,运行的费用也降低了13.5%,有显著降低能耗的效果。CURTISS[9]用ANN预测控制管理中央暖通空调(Heating Ventilation Air Condition,HVAC)系统的能耗,得出结论为在保证舒适度下,ANN系统能够明显达到节能效果。`
目前,比较流行的暖通空调系统能耗预测方法主要有:参数回归法、时间序列预测法、人工神经网络、支持向量机等[10]。其中参数回归和时间序列预测法又被归类为传统方法,人工神经网络和支持向量机则被归类为人工智能方法。周旋等[11]提出一种基于多元非线性回归法的商场空调负荷预测,在提高预测精度的同时还大大缩短了建模时间。孙靖等[12]提出了一种基于季节性时间序列模型的空调负荷预测的方法,有效解决了冰蓄冷系统优化控制问题。李帆等[13]提出了一种基于运行数据人工神经网络的空调系统逐时负荷预测方法,获得了5.20%左右的预测误差模型,能够较精确地预测未来24 h内的逐时负荷。王智锐等[14]提出了一种基于支持向量机的建筑物空调负荷预测模型,实现了反向传播(Back Propagation,BP)神经网络更佳的负荷预测结果。
由于传统模型无法同时兼顾负荷数据时序性和非线性的特点,如时间序列法没有考虑到非线性,一般只适用于空调负荷变化平稳的短期预测,当负荷变化剧烈时,预测跟随性很差。为了解决以上模型存在的问题,本文使用了一种基于长短期记忆神经网络(Long Short-term Memory,LSTM)的预测模型对暖通空调能耗进行预测。作为深度学习中非常重要的一种模型,LSTM在各个领域如语言模型[15]、图像分析[16]、文档摘要[17]、语音识别[18]、图像识别[19]、手写识别[20]、预测[21]等都广泛关注及运用。LSTM这种模型不仅可以像普通神经网络一样学习复杂数据之间的规律,最重要的是LSTM能够同时兼顾时序性和非线性关系[22],能够学习过去一段时间历史数据中的信息,选择性地保留有用信息,丢弃无用信息,然后运用于下一阶段的预测,使得预测更加的可靠、精确。
本文采用LSTM 建模进行暖通空调系统能耗预测,先进行数据的预处理,这里面包括了对异常值处理,对输入数据的归一化,将数据分为训练集和测试集等;然后是建立模型,调整参数、优化模型等;最后运用模型进行能耗预测,得到了相比支持向量回归、回归树模型更精确的预测结果。在考虑到了空调负荷数据的时序性关系后,得到了更好预测结果。
1 预测模型的建立
1.1 长短期记忆神经网络
长短期记忆神经网络是循环神经网络(Recurrent Neural Network,RNN)中的一种特殊类型,可以学习长期依赖信息。LSTM由HOCHREITER 和SCHMIDHUBER(1997)[23]提出,并被GRAVES[24]进行了改良和推广。在很多问题上,LSTM都取得了相当大的成功,并得到广泛运用。本文中LSTM模型都是基于Python 3.6中的Keras和TensorFlow库实现的,使用的优化器为RMSprop。
如图1所示LSTM的神经元结构,在这个神经元结构中有3个门结构,分别是输入门(input gate)、输出门(output gate)、遗忘门(forget gate)。在LSTM中,第一步通过遗忘门来决定我们会从细胞状态中丢弃什么信息;第二步在输入门中确定什么样的新信息会被放在细胞状态中;第三步在输出门中确定要输出的值。
在LSTM神经元结构中,令X = [x1,x2,x3,…,xt]作为输入的时序信号值,xt表示t时刻的神经元输入;令H = [h1,h2,h3,…,ht]作为输出的目标值,ht表示t时刻的输出;令C = [c1,c2,c3,…,ct]表示神经元的状态信息,ct表示t时刻神经元的状态。
遗忘门:
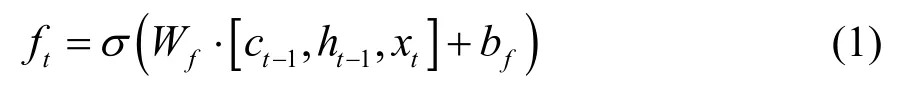
输入门:
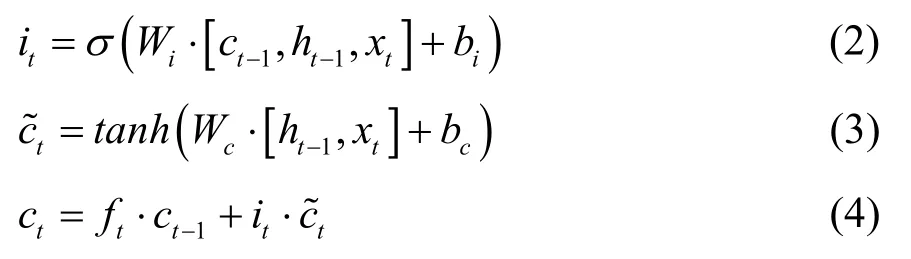
输出门:
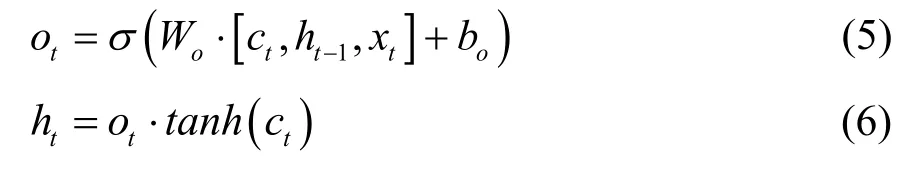
公式(1)到(6)表示LSTM的全过程,xt为输入,ht为输出,it为输入门的输出,ƒt为遗忘门的输出,ct为t时刻当前细胞的状态,ot为输出门的输出,W为权重矩阵,b为偏差矩阵,tanh、σ为激活函数。
输入门、遗忘门、输出门、激活函数之间相互配合工作,实现从历史数据中筛选有用信息保留下来,丢弃掉无用信息,具有更强的时间序列学习能力,更强大的信息选择能力,可以很好地应用于暖通空调系统能耗的预测工作。
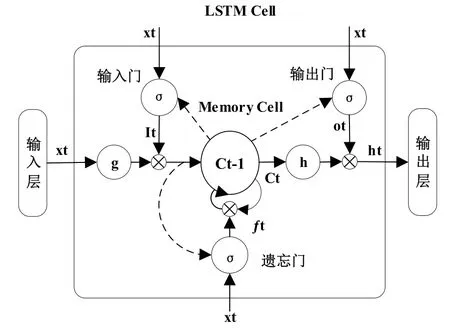
图1 LSTM 神经元结构
1.2 传统对比模型
为了能够与LSTM预测模型对比,本文还使用了其他两种预测模型分别为:回归决策树、支持向量回归。回归决策树(Regression Tree,RT)是时间序列预测模型的一种,它是以实际例子为基础的归纳式的一种学习算法,通过将没有次序、没有任何规律的事例进行分类,将分类以“树”的形式表示,自上而下进行递归分类,在决策树的内部节点上进行属性的选择,并对决策树进行剪枝。支持向量回归(Support Vector Regression,SVR)是在支持向量机(Support Vector Machine,SVM)的基础上引入不敏感函数得到的,其思想为通过核函数,将输入变量映射到高维空间,这样就可以将低维的非线性问题转化成高维空间中的线性问题来处理、解决。
2 数据来源以及处理
2.1 数据来源
实验数据来源于北方某地源热泵系统,时间是一整个供暖季节,数据的采样间隔为10 min,原始数据大约含有6,000个样本,机组为2台型号为HE1200B的涡旋机组,系统为两台循环泵运行,均采用定频控制,运行数据变量如表1所示。采用该地区对应时间的气象数据作为实验数据的另一组成部分,气象数据变量如表2所示。

表1 运行数据

表2 气象数据
2.2 数据预处理
1)变量选取
本文选取原始数据中的室外温度、露点温度、相对湿度、风速、高区二次供水温度、高区二次回水温度、高区瞬时质量流量、高区瞬时体积流量、指数加权移动平均(Exponential Weighted Moving Average,EWMA)历史能耗指标,预测变量为2 h后的采样间隔累计热量。
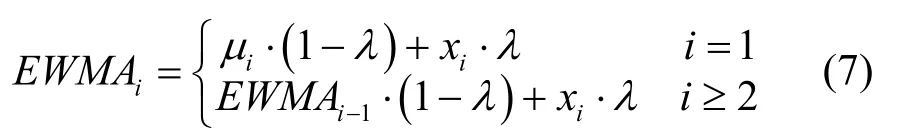
式中:
μ1——采暖季开始时刻的能耗值;
EWMAi——第i时刻的历史用能指标;
λ——衰减系数,或影响系数,用来衡量前一时刻用能对当前时刻用能的影响水平;
xi——当前时刻的区间累计热量值。
2)异常值处理
在原始数据里面,能耗值有部分为负值,这是明显的异常值,为了保护数据的时序性,本文采用零值填充的方法处理。
3)数据的归一化处理
输入的数据中,不同评价指标往往具有不同的量纲和量纲单位,这样的情况会影响到数据分析的结果,为了消除指标之间的量纲影响,需要进行数据标准化处理,以解决数据指标之间的可比性。原始数据经过数据标准化处理后,各指标处于同一数量级,适合进行综合对比评价。这里采用最大-最小标准化方法:
最大-最小标准化是对原始数据进行线性变换,设MinA和MaxA分别是属性A的最小值和最大值,将A的每一个原始值x通过最大-最小标准化映射到区间[0,1]的值xnorm,公式如式(8):
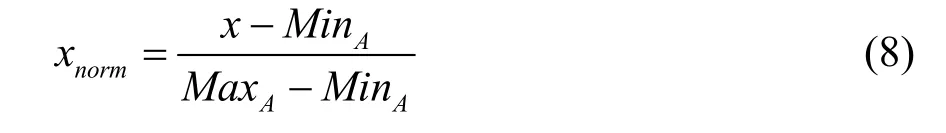
4)训练、测试集划分
经过前面的数据处理过程,数据总量为5,613个,取前4,500个作为训练集,剩余的作为测试集。
5)预测结果误差评价标准
采用平均绝对误差(Mean Absolute Error,MAE)和均方根误差(Root Mean Square Error,RMSE)两种评价标准,数值越低表示预测值与真实值相差越小。
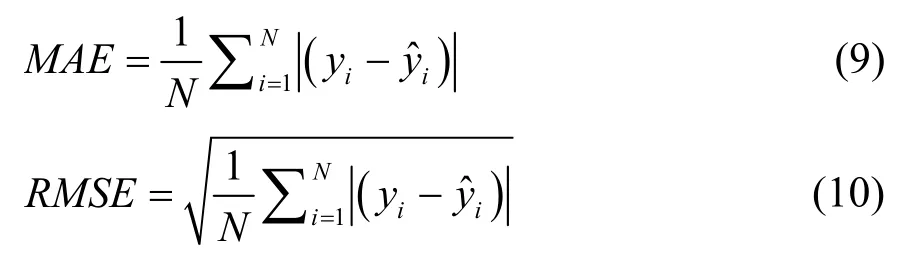
式中:
N——预测结果的总个数;
yi——真实值;
3 LSTM建模与预测
3.1 训练建模
1)选取原始数据中的9个变量为输入变量,对异常值进行处理。
2)对每一个变量数据运用最大-最小标准化方法进行归一化处理。
3)将输入数据转变换成[samples,time_steps,features]的三维形式,改变time_steps即历史时间序列长度大小,预测未来4 h的能耗负荷值。
4)选取最优的模型,对测试集数据进行预测。
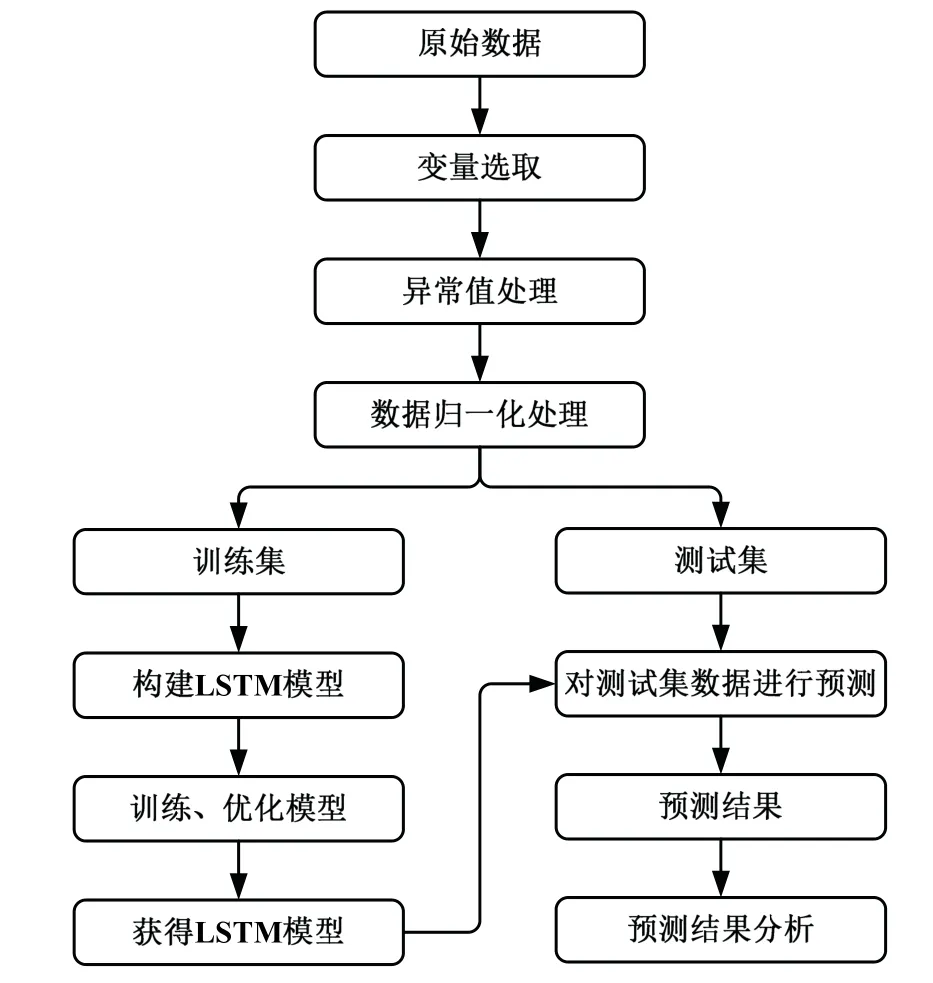
图2 流程图
3.2 预测
将测试集数据转换成[samples, time_steps, features]三维形式,输入得到LSTM预测模型和相应的能耗预测值,再对其进行反归一化,与真实能耗值进行对比。
4 预测结果分析
4.1 数据处理
4.1.1 异常值的处理
异常值的处理包括去除稳定不变的异常值和零值填充能耗负值,处理结果如图2~图3所示。
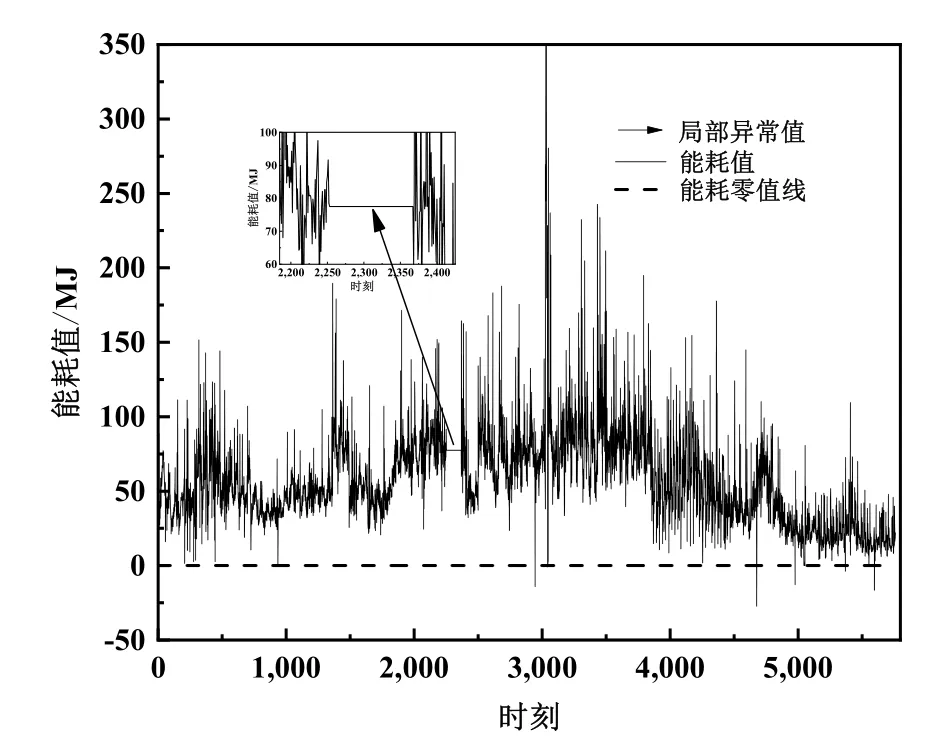
图2 原始数据分析
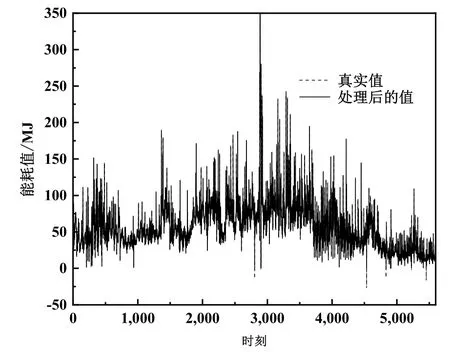
图3 异常值处理结果
在原始数据图2中,灰色柱状部分代表的是恒定能耗异常值区域,这一部分需要直接剔除。图中在黑色水平线以下的能耗值表示的是负值,但是能耗值是不会为负值的,所以这些值是不可以使用的。为了不损害数据的时序性,本文对这些负值采取零值填充处理,处理结果如图3所示。
将数据转换成能够输入进LSTM中的形式也是非常重要的一步,文章以其中的一种形式为例,如图4所示,LSTM模型的数据输入形式为Batch_input_shape:(samples,steps,features),samples为一个训练块中样本数量,steps为回溯的历史时间长度,features为数据的变量数目加上一个训练目标值,delay为预测未来的时间间隔长度。
4.1.2 数据转换
4.2 训练、测试结果
图5为LSTM模型能耗预测结果。
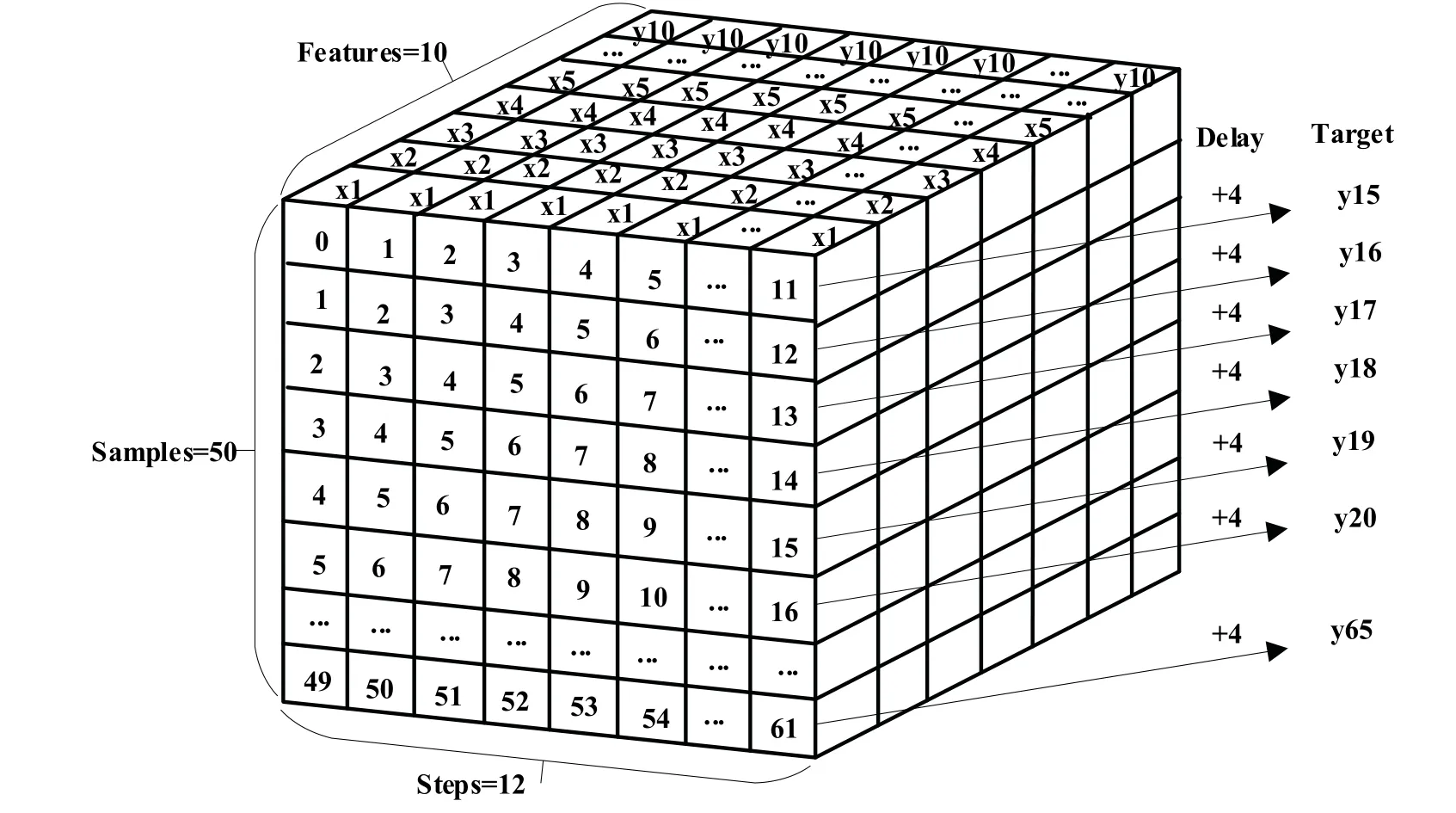
图4 模型输入数据转换示例
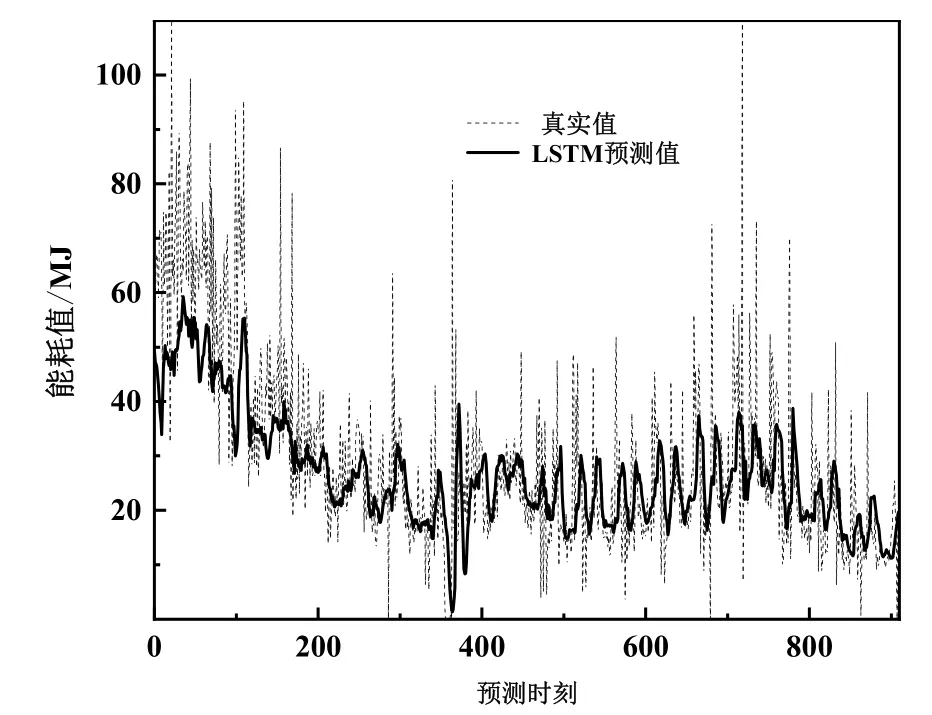
图5 LSTM模型能耗预测结果
4.3 对比模型结果
图6为SVR模型能耗预测结果。图7为回归树模型能耗预测结果。
支持向量回归、回归树的结果显示,这两种预测模型在预测的初期、前200个预测时刻点,都表现出较高的准确度,与原始数据的偏差较小。但是在之后,支持向量回归模型开始整体向上偏移,准确度大幅度下降。回归树模型在第400个预测时刻点前后开始漂移,完全脱离原始数据的变化特点,基本失去了预测能力。相比之下,LSTM模型整体预测结果与原始数据都有着稳定、准确的拟合,没有明显的漂移现象。可以看出,在结合了数据的时序性和相关性之后,模型的预测没有随着时间的推移而出现预测精度下降的现象,表现出更加优秀的预测能力。
用前4,500个数据训练模型,其余数据测试模型,得到3种预测模型的预测误差如表3所示。其中LSTM模型同时具有最小的MAE值为8.326和最小的RMSE值为11.835,相比传统模型RT和SVR都有明显的减小,LSTM模型的预测精度相比RT、SVR都有了很大的提高。在同时考虑数据的时序性和非线性时,LSTM模型可以从历史数据中提取到更多有效的信息。
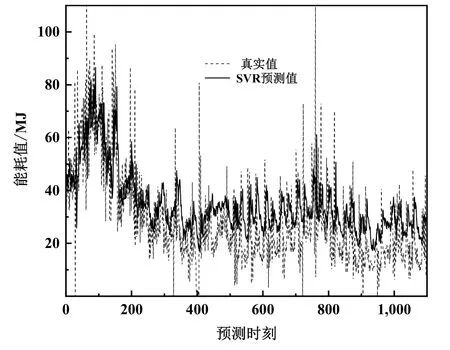
图6 SVR模型能耗预测结果
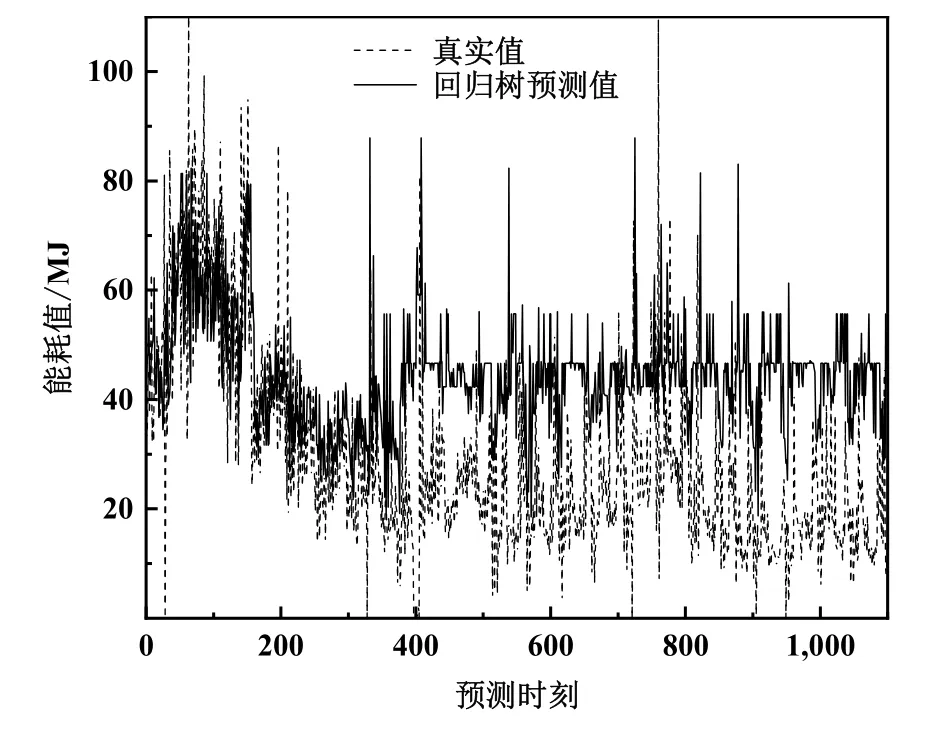
图7 回归树模型能耗预测结果

表3 负荷预测误差对比
5 结论
在对某暖通空调系统进行能耗预测中,本文使用改进的循环神经网络LSTM建立相应的预测模型,同时也采用了传统模型SVR、RT进行了相同的预测,将3种预测模型结果进行对比。实验结果证明,基于LSTM的预测模型预测值的平均方差、平均绝对偏差均优于SVR、RT模型,并且随着预测时间推移,LSTM模型具有良好的预测稳定性。LSTM 模型在同时考虑数据的时序性和非线性前提下,确实可以从历史数据中获取到更多的有用的信息,有效地提高了模型预测能力。因此,将LSTM引入到暖通空调系统的能耗负荷预测中,具有显著的理论意义和实际价值。
猜你喜欢
昆钢科技(2022年2期)2022-07-08
建材发展导向(2022年3期)2022-04-19
建材发展导向(2022年5期)2022-04-18
当代水产(2021年10期)2022-01-12
建材发展导向(2021年19期)2021-12-06
建材发展导向(2021年23期)2021-03-08
物联网技术(2020年12期)2021-01-27
建材发展导向(2019年5期)2019-09-09
华人时刊(2018年15期)2018-11-10
汽车零部件(2017年4期)2017-07-12
