
麦克风阵列的协同自适应滤波语音增强方法
2019-05-09 06:46赵益波杨蕾严涛李春彪
现代电子技术 2019年8期
赵益波,杨蕾,严涛,李春彪
(1.南京信息工程大学 电子与信息工程学院,江苏 南京 210044;2.江苏省大气环境与装备技术协同创新中心,江苏 南京 210044)
0 引言
单麦克风只能拾取一路信号,一般不能随声波一起运动,而且由于说话人的一些运动,使得基于单麦克风的语音增强效果并不理想[1]。麦克风阵列具有空间选择性,可以用“电子瞄准”的方式从所需的声源位置获得高品质的信号,同时抑制其他说话人的干扰声音和环境噪声,可以取得明显的消噪效果[2]。麦克风阵列不要求在声源本地放置传感器,也不会随着说话人的移动来移动麦克风位置以改变接收方向[3]。这些特性有利于其获得多个或移动声源,并且可用于一些特殊的场合[4]。
自适应滤波具有自适应性,在系统辨识、语音信号处理、图像处理等方面有着广泛的应用[5]。基于广义旁瓣抵消器(Generalized Sidelobes Canceller,GSC)的麦克风阵列自适应语音增强方法是将麦克风阵列和自适应滤波技术结合起来的语音增强方法。该方法根据麦克风阵列接收的信号统计特性的变化来调整滤波器的系数[1],对目标信号以外的信号进行滤除;同时提高了麦克风阵列的自适应性,能够在时变的语音环境中仍能实时跟踪目标信号[6]。在实际应用中,除了高斯白噪声,还可能存在非线性噪声,如脉冲噪声[7]。在这种情况下,仅基于线性自适应滤波的麦克风阵列语音增强方法难以获得好的去噪效果[8]。为此,本文提出一种新的麦克风阵列自适应滤波语音增强方法。此方法用协同自适应滤波取代线性自适应滤波,根据误差函数同时导出线性、非线性滤波器权值系数和协同因子的更新算法;能有效地消除语音信号中的瞬时脉冲噪声和高斯噪声,比传统的GSC优越得多。
1 自适应GSC语音增强
图1为麦克风阵列自适应GSC语音增强原理框图,其由“上”“下”两个处理模块组成。
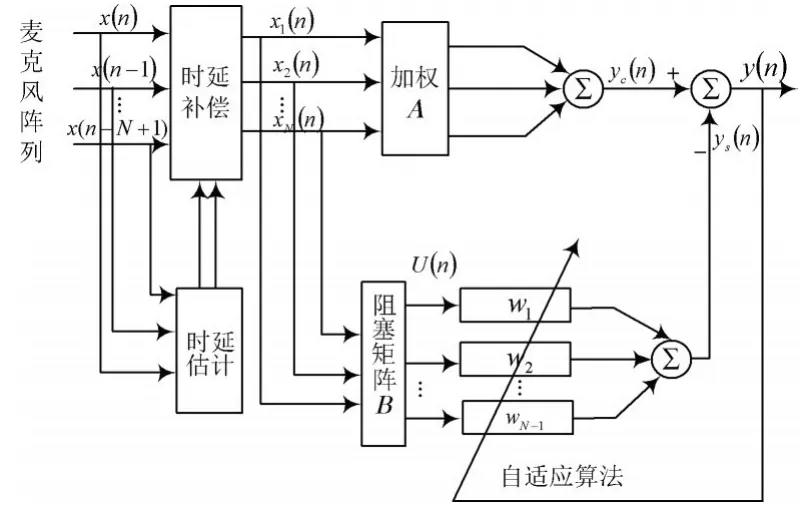
图1 麦克风阵列自适应GSC语音增强原理框图Fig.1 Principle block diagram of adaptive GSC speech enhancement based on microphone array
通过麦克风阵列采集的语音信号会出现一定的时延现象。先通过时延估计模块对其进行时延估计,然后利用时延补偿将采集到的信号进行同步,同步后的信号为X(n)=[x1(n),x2(n),…,xN(n)]T。“上”模块中加权矩阵对同步后的信号进行加权,加权系数是固定非自适应的,“上”模块的输出为:
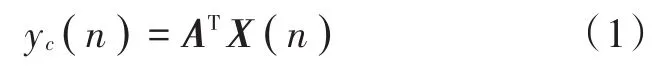
式中,A=[ɑ1,ɑ2,…,ɑN]T∈RN是权系数向量,为简单起见,满足:

“下”模块由阻塞矩阵和自适应滤波器构成,同步后信号经过阻塞矩阵后的输出信号为:
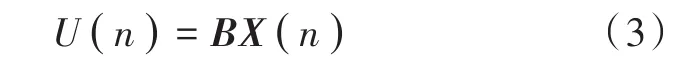
阻塞矩阵相当于空间陷波器,目的是将目标信号滤除,剩下的就是干扰和噪声部分。设表示阻塞矩阵第m行元素向量,且需满足:

由于bm是彼此线性独立,所以U(n)最多由N-1个线性独立元素组成,也就是说,阻塞矩阵B的行的维数一定不超过N-1。自适应滤波输出为:
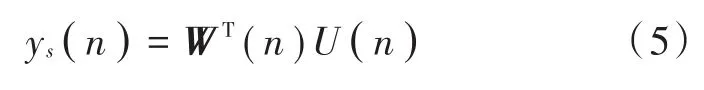
式中,W(n)=[w1(n),w2(n),…,wN-1(n)]T。利用LMS自适应滤波算法对权值矢量进行更新:
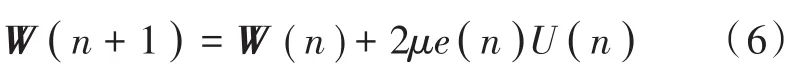
最后输出部分为增强后的语音信号:

式(1)~式(7)为基于线性自适应滤波的自适应GSC算法。ys(n)一般在高斯白噪声时估计效果较好,但对于具有显著尖峰脉冲状波形的非线性噪声时效果并不好,原因是线性自适应滤波在估计ys(n)过程中的非线性噪声时存在很大局限性。
2 协同自适应滤波语音增强
实际信号在获取和传输过程中会受到不同噪声的影响而产生变化。这些噪声除了干扰、加性的高斯噪声外还可能存在脉冲噪声。脉冲噪声具有非线性特性,而线性滤波器对脉冲噪声的平滑效果较差,非线性自适应滤波在处理这类非线性噪声方面具有明显的优势[9];但是当系统非线性噪声级可忽略时,纯非线性自适应滤波在处理高斯白噪声方面退化了系统行为,从而产生非优化滤波。为此,本文提出一种将线性滤波器与非线性滤波器协同组合的麦克风阵列语音增强方法。该方法既能保持线性自适应滤波处理白噪声的优点,也能更好地处理非线性脉冲噪声。图2是本文提出的麦克风阵列的协同自适应滤波麦克风阵列语音增强系统框图。
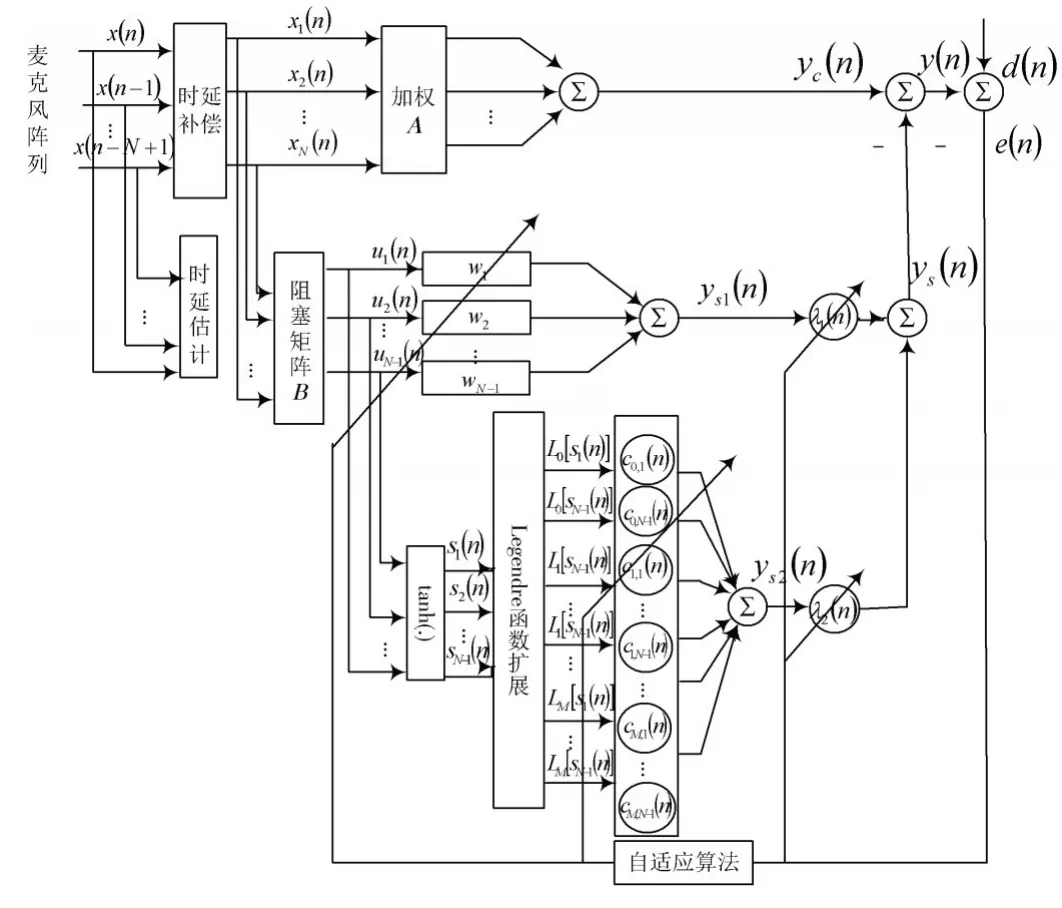
图2 麦克风阵列的协同自适应滤波语音增强系统框图Fig.2 Block diagram of speech enhancement system with collaborative adaptive filtering and microphone array
在“上”模块中,经过时延估计后进行补偿使信号同步,同步后的信号仍记为X(n)=[x1(n),x2(n),…,xN(n)]T。分别对经过阻塞矩阵后的噪声信号进行线性与非线性的滤除。双曲正切函数tanh(∙)是作为一个将输入信号映射到范围为(0,1)的单值函数的激活函数,目的是保证Legendre多项式自适应滤波的收敛条件[10]。激活函数tanh(∙)通过后信号向量为:

向量S(n)经Legendre多项式扩展后为:

式中:

i=0,1,2,…,M为第i阶Legendre多项式函数;M为Legendre多项式扩展的阶数。零阶、一阶Legendre多项式分别为L0(x)=1,L1(x)=x,其余项由公式(10)导出。
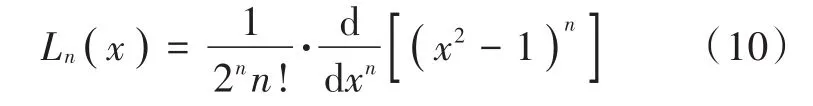
非线性滤波器的输出为:
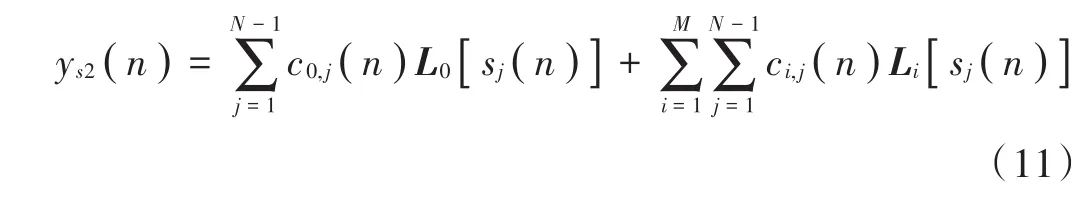
式中:c0,j(n)为对应L0[sj(n)]的权值系数;ci,j(n)是对应Legendre多项式Li[sj(n)]的权值系数;i=1,2,…,M;j=1,2,…,N-1。
本文利用NLMS对自适应滤波权值进行更新,可导出权值系数递推公式为:
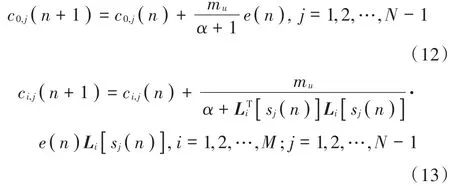
式中:e(n)=d(n)-y(n)为误差信号;d(n)为目标信号(干净语音信号);y(n)为系统输出包括“上”模块和“下”模块的差值;mu为调节因子;α是为了避免[sj(n)]·Li[sj(n)]过小而设定的参数,0<α<1。
分别对线性滤波器与非线性滤波器的输出进行协同组合,自适应滤波总输出为:
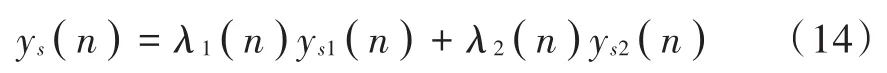
式中:ys1为线性自适应滤波器输出;ys2为非线性自适应滤波器输出;λi是协同因子,取:
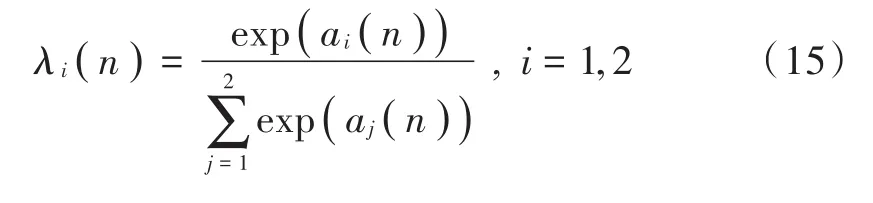
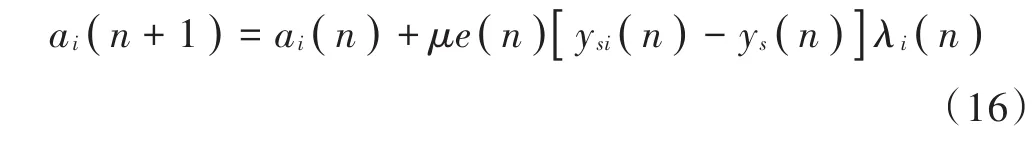
式中μ为迭代步长。
最后处理后的增强语音输出为:
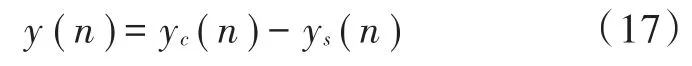
3 仿真实验
仿真实验是在Matlab R2016a环境中进行的。为了证明麦克风阵列的协同自适应滤波的语音增强效果比GSC的语音增强效果好,在相同的环境中对两种方法增强后的语音效果进行对比。其中仿真用的干净语音信号内容为:“第一课认识新同学”,同时加入方向性干扰。期望信号的方向是30°,干扰方向为80°。由于在实际生活中,观察到的信号除了有高斯噪声以外,还有的信号是非高斯的,并伴有显著的脉冲特性。为了营造较为真实的模拟环境,还加入了固定的脉冲噪声进行测试。分别利用不同信噪比的高斯噪声来进行仿真实验。图3、图4分别为干净语音信号和方向性干扰信号,麦克风阵列接收到的加入SNR=20 dB的高斯噪声和脉冲噪声的信号如图5所示。
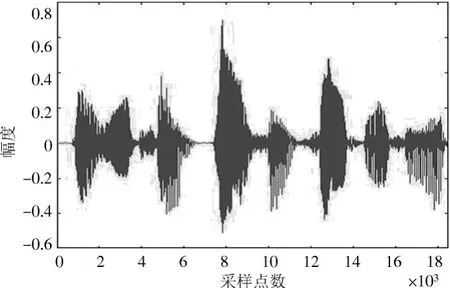
图3 干净语音信号Fig.3 Clean speech signals
图6为加入SNR=20 dB的高斯噪声后GSC处理后的增强语音信号。图7为加入SNR=20 dB的高斯噪声后麦克风阵列的协同自适应滤波增强的语音信号。对比图6和图7两张图可以看出,GSC处理后的增强语音信号中仍残留着脉冲噪声,而用本文所提方法处理后的增强语音信号中对脉冲进行了有效增强,效果明显。
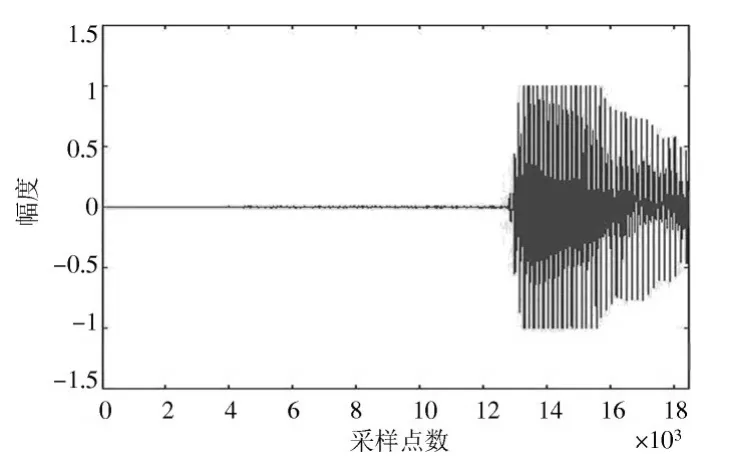
图4 方向性干扰Fig.4 Directional interference

图5 麦克风阵列接收到的带有脉冲噪声的信号(加入SNR=20 dB的高斯噪声)Fig.5 Signals with impulse noise and Gaussian noise(SNR=20 dB)received by microphone array

图6 GSC处理后的增强语音信号(一)Fig.6 Enhanced speech signals after GSC processing(Ⅰ)

图7 麦克风阵列的协同自适应滤波处理后的增强语音信号(一)Fig.7 Enhanced speech signals after collaborative adaptive filtering processing based on microphone array(Ⅰ)
图8为麦克风阵列接收到加入SNR=25 dB的高斯噪声和相同脉冲噪声的信号。图9为加入SNR=25 dB的高斯噪声后GSC处理的增强语音信号。图10为加入SNR=25 dB的高斯噪声后麦克风阵列的协同自适应滤波增强的语音信号。进一步对比图9和图10两张图可以看出,GSC处理后的增强语音信号中仍残留着脉冲噪声;而用本文所提方法处理后的增强语音信号中对脉冲进行了有效抑制,增强效果明显。
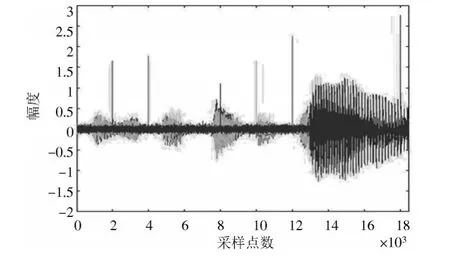
图8 麦克风阵列接收到的带有脉冲噪声的信号(加入SNR=25 dB的高斯噪声)Fig.8 Signals with impulse noise and Gaussian noise(SNR=25 dB)received by microphone array

图9 GSC处理后的增强语音信号(二)Fig.9 Enhanced speech signals after GSC processing(Ⅱ)

图10 麦克风阵列的协同自适应滤波处理后的增强语音信号(二)Fig.10 Enhanced speech signals after collaborative adaptive filtering processing based on microphone array(Ⅱ)
上述两组仿真均表明了所提方法的语音增强效果明显优于传统的GSC,为了更直观地表明本文所用方法的增强效果,用PESQ对增强后的语音进行评估。
PESQ是基于感知模型的语音质量客观评价标准[11]。对于正规的主观测试,得分[12]在1.0~4.5之间;在失真情况严重时,得分可能会低于1.0,但这种情况很少见;当语音结果与目标信号一致时,得分为4.5,也就是说得分越高,处理后的语音效果越好,清晰度也就越高。两种方法的语音增强效果PESQ评估值如表1所示。

表1 语音增强效果PESQ评估Table 1 PESQ assessment of speech enhancement effects
从表1可以看出,所提方法相比较于GSC方法的增强能力更强,对于脉冲信号也有更强的韧性。对比图6与图7,GSC处理后的语音信号PESQ得分为1.709 7,而用本文方法处理后的语音信号的PESQ得分为2.178 0,整体提高0.468 3。同时对比图9与图10,GSC处理后的语音信号PESQ得分为2.021 5,而用本文方法处理后的语音信号的PESQ得分为2.328 9,整体提高0.307 4。
4 结论
本文提出一种麦克风阵列的协同自适应滤波语音增强方法,在麦克风阵列GSC语音增强方法的基础上引入协同自适应滤波,将线性滤波与非线性滤波协同组成新的自适应滤波器。仿真实验结果表明,麦克风阵列的协同自适应滤波语音增强方法比GSC方法具有更好的去除脉冲噪声能力,语音增强的效果也更好。
猜你喜欢
小天使·二年级语数英综合(2019年4期)2019-10-06
小学生学习指导(低年级)(2019年6期)2019-07-22
复旦学报(自然科学版)(2019年3期)2019-07-19
电子制作(2019年11期)2019-07-04
电子测试(2018年23期)2018-12-29
电子制作(2018年16期)2018-09-26
小学科学(2016年12期)2017-01-06
系统工程与电子技术(2016年7期)2016-08-21
火控雷达技术(2016年2期)2016-02-06
做人与处世(2015年19期)2015-09-10
