
图书情报数据挖掘处理平台设计
2019-05-09 06:46高登文
现代电子技术 2019年8期
高登文
(宁夏师范学院,宁夏 固原 756000)
0 引言
图书情报学科每年都会有成千上万的论文发表刊登,图书情报工作人员则需要掌握比较详细的、准确的所有图书情报学科的数据,如涉及的专业范畴、内部构架和发展趋势等[1]。面对如此大量的论文,想要获取全面的信息,单纯地依赖于个人的阅读时间是不可取的[2]。近年来,根据共词分析和网络分析,提出一种新的解析方法,即定量分析。目前我国图书情报领域的服务主要还停留在基于数量规模的信息服务层面上。毫无疑问,借助先进的理念与技术,升华传统图书情报领域数据挖掘方法,转变传统挖掘模式,重构挖掘体系,提高挖掘精度,以更好的方法对所需图书情报数据进行挖掘。利用读者在数字图书馆的各种行为为基础,通过收集读者的浏览、定制、检索、下载等记录来进行研究,从而建立图书情报数据库;同时根据图书情报数据的开发,以数据库的形式将图书检索信息进行存储[3]。该平台采用元搜索技术对图书馆各种图书情报数据库、网络资源等进行搜索,再通过信息关注机制,对满足需求的数据进行选择。并用设定的方式方法将图书情报数据进行传输,建立反馈机制,允许相关人员进行人工选择和评价;然后将读者所需信息储存在数据库中,供数据挖掘所用。
1 图书情报数据挖掘处理平台设计
图书情报数据挖掘处理平台主要由7大模块组成,分别是数据解析模块、数据采集模块、接口模块、图书情报数据过滤模块、图书情报搜索引擎、图书情报数据推送模块和数据挖掘模块。数据解析模块重点是对通过需求规约工具得到的图书情报数据挖掘对象进行描述和挖掘策略相关文件[4]。数据采集模块与预处理模块主要是依据有关挖掘需求来对图书情报数据进行采集,并把采集到的图书情报数据转变为能够处理的模式。图书情报数据挖掘模块主要采用相关挖掘算法,排除掉不同算法间的差异,让挖掘算法在敏捷状态下进行挖掘工作[5]。整体平台可通过附加任务调度监控模块对挖掘任务的执行阶段进行仔细划分,保证在进行图书情报数据挖掘时可以及时得到反馈。涉及到的数据库为图书相关情报资源,根据以上分析确定平台结构如图1所示。
1.1 数据挖掘模块
数据挖掘模块主要功能是依据所选择的挖掘算法以及相关的技术参数,调用算法完成数据挖掘任务。因为整个挖掘算法的处理过程[6]都是通过数据集群运算完成的,期间不需要进行过多的操作和关注。因此,在本模块中,引入K-means算法,挖掘图书情报数据,并对挖掘结果直观有效的进行应用。
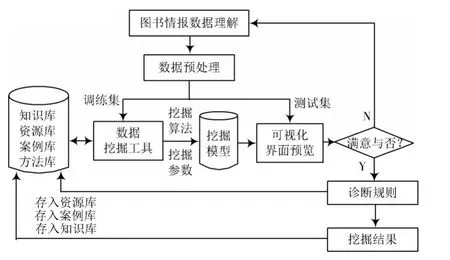
图2 数据挖掘模块Fig.2 Data mining module
1.2 数据存储模块
为了解决海量数据存储、检索和在线阅读的容量和性能问题,在有限的条件下建立高效存储平台是图书情报挖掘平台建设的重点。本平台采用分级存储的方式设计图书情报数据存储模块。第一级面向交互频繁,但I/O流量相对较小、随机存取负担较重的元数据库,采用服务器内置的SAS高速磁盘阵列平台存储和管理[7];第二级面向I/O流量较大、传输数据块较大,但访问频次较少的对象数据,采用的是基于ISCSI的IP-SAN网络接入的SATA磁盘阵列实现。
存储区域网络作为存储架构,其连接方式是采用高传输速率的光通道进行连接。在SAN中的任意节点之间提供多个备选图书情报数据转换[8],把数据保存在单独的存储活动范围内。由于采用的是独立网络,SAN可以更好地将存储设备和服务器之间频繁的数据传送与网络信息服务的信息包分割开来。不使用与IP网络冲突的网络资源[9],从而有效地消除网络瓶颈,并且能够尽量对数据共享、数据的优化管理和平台的无缝扩充进行支持。
在进行图书情报数据存储时,将获取的数据存储在平台上。该平台的存储层是一个由4个计算节点组成的集群,其利用了HDFS数据存储体系结构,将预处理后的数据或平台分析的数据以文本形式读入平台中[10]。平台为数据存储提供了强大的保护措施,平均每个情报数据都进行三次备份,能够很好地防止遇到突发事件而出现丢失图书情报数据,并且图书情报数据有附加性能,在平台发生意外故障时,能够保证后续图书情报数据存储无误。
1.3 数据解析模块
数据解析模块是此平台第二主要的功能模块,它包括用户聚类模块和用户行为分析模块两大类。本平台利用用户兴趣对用户进行分类汇总。当用户频繁访问图书情报数据的某个页面或在某个页面上停留较长时间时,表明用户对此类图书情报数据兴趣度很高[11]。在本文中,会使用这种兴趣度来对图书情报数据进行聚类解析。在同一时间,利用序列化模式挖掘算法和图书情报数据经常被访问的途径,针对该途径获取的图书情报数据进行解析工作。
2 软件设计
从功能的简易运行和设计的开拓性能角度出发,采用的挖掘算法延伸性应用具备两个特性:
1)挖掘算法的一些性能是比较卓越的,应用上更是灵便突出,但是灵便的后果就是操作相当麻烦。所以本文必须整理出多个演变算法,才能给外界够提供出简便的对恰接口,使操作的运用既能活灵活现又尽可能的简单便捷。
2)改良可插播式应用的挖掘算法,既能在原始算法上增加新的运算公式也能在已有公式的基础上进行算法改动或者撤销,还不会对原始模块产生相对明显的影响。这种算法不仅落实了对最初算法的改进,还跟进了应用改进算法。具体的图书情报数据挖掘流程如图3所示。

图3 数据挖掘流程图Fig.3 Flow chart of data mining
在进行图书情报数据挖掘时,用户可以依据需求,对挖掘策略模板文件事先进行挖掘算法的设置,来确定某些参数的值和在未来的时间里需要设置的参数。在这类文件中,为了完成特定的策略文件,需要为平台中的属性指定所需要的算法,确定哪些已经有明确值的挖掘参数,哪些参数是用户对此策略模板的解释说明,指导用户定义策略文件。
3 实验结果分析
3.1 测试环境
功能测试工具为Microsoft Visual Studio 2015 for software tester;性能测试工具为Loadrunner 10;测试管理工具为Mercury Quslity center 9.0。
3.2 平台运行环境
服务器,HP ML-370 G5;操作平台,Windows 2013 Server,TRS DB Server V6;CPU,Inter Pentium Ⅲ 1 GHz以上;内存,4 GB以上;硬盘,1 TB;网络,支持TCP/IP协议;数据库,SQL Server,MySQL。
3.3 实验结果分析
为了验证本文平台在数据挖掘方面的性能,将文献[5]平台作为对比,进行量化测试。测试将负载均衡离差值作为衡量指标。
负载均衡离差值是负载均衡性的体现,计算公式为:
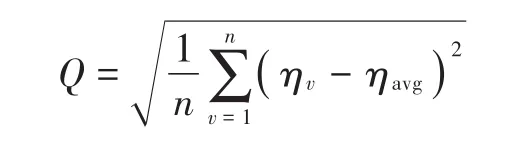
式中:n用于描述图书情报数据总量;ηv用于描述数据量为v时数据挖掘的负载;ηavg用于描述数据挖掘时的平均负载。
依据上式描述,将采用本文平台及文献[5]平台做比较,进行数据挖掘负载均衡离差值对比,结果见图4。
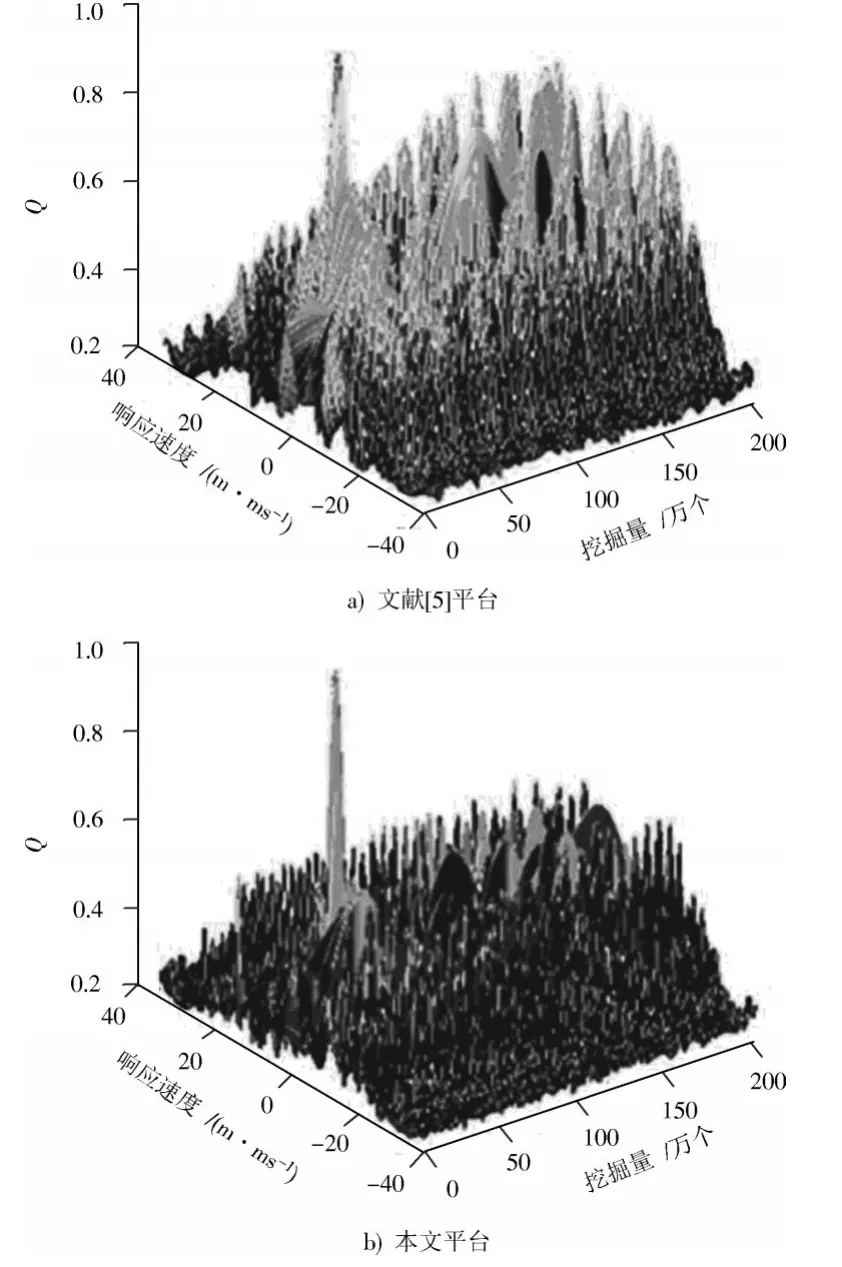
图4 不同平台挖掘负载均衡离差结果对比Fig.4 Comparison for load balance deviation results mined by different platforms
分析图4可知,在数据挖掘量和响应速度一定时,采用本文平台进行数据挖掘,其负载均衡离差值较为稳定,只有一处出现忽然增加的现象,均衡性较好的同时,稳定性较高,具有一定的优势;反之,采用文献[5]平台时,多处出现负载均衡离差值突然增高的现象,虽然均衡性较好,但稳定性较差,影响因素增多,需要进一步进行处理。
4 结论
针对传统平台一直存在数据挖掘中负载均衡差的问题,提出并设计了基于K-means算法的图书情报数据挖掘处理平台,并通过硬件及软件两部分进行分析,以负载均衡离差值为对比指标进行实验分析。结果表明,改进平台负载均衡较好,具有一定的优势。
猜你喜欢
现代装饰(2022年5期)2022-10-13
现代装饰(2022年3期)2022-07-05
现代装饰(2022年2期)2022-05-23
中学生数理化·高一版(2021年4期)2021-07-19
大众投资指南(2021年35期)2021-02-16
语文世界(小学版)(2018年3期)2018-03-22
商周刊(2017年12期)2017-06-22
电力与能源(2017年6期)2017-05-14
摄影之友(影像视觉)(2016年2期)2016-08-16
信息通信技术(2015年6期)2015-12-26
