
Web文档分类中TFIDF特征选择算法的改进
2019-05-17 02:52段国仑郭蕾蕾王晓莹
计算机技术与发展 2019年5期
段国仑,谢 钧,郭蕾蕾,王晓莹
(1.陆军工程大学 指挥控制工程学院,江苏 南京 210007;2.陆军工程大学 通信工程学院,江苏 南京 210007)
0 引 言
随着互联网技术的不断发展以及大规模应用,网络上的信息资源正以指数级爆炸式增长。Web已经成为一个巨大的资源海洋。如何管理这些海量信息是一个值得研究的问题。通过Web文档分类[1]手段能够有效解决这一问题,因此很多学者在不断努力寻求较好的分类技术。在Web文档分类中,文本信息是最重要的分类信息。分类之前通常将文本表示为向量空间模型(vector space model),但这种表示方法会使得文本向量维数很高。这带来了较大的特征空间和冗余信息,从而影响文本分类的效率和准确率。
特征选择是通过某种方式或算法选择出有益于分类的特征,去除那些无关或者关联性不强的特征,从而构造出更快,消耗更低的预测模型。
特征选择是文本分类中的关键环节[2-3]。目前已有很多种特征选择算法用于文本分类,能够较好地解决特征高维性带来的问题,但是针对这些方法仍然有很多需要改进的地方。
1 相关工作
1.1 向量空间模型
文本向量空间模型是为了将每一个文本表示为向量空间中的一个向量,将每一个不同的特征对应为向量空间中的一个维度,而每一维的值就是对应的特征项在文本中的特征值[4]。向量空间模型中,文档d表示为:V(d)=((t1,a1),(t2,a2),…,(tn,an))。其中ti为文档d中的特征项,ai为ti的特征值,一般取为词频的函数。有了这样的表示以后,就可以用分类器对样本分类。
1.2 特征选择
特征选择[5]的方式有多种,如过滤式、包裹式、嵌入式等。过滤式独立于后续要使用的模型,只针对数据本身而进行选择特征,从而将特征子集用于分类。由于Web文档分类维数较高,所以使用过滤式方法可以有效减少特征选择所用时间。文本特征选择,主要是根据某种准则从原始特征中选择部分最有区分类别能力的特征词。
目前,国内外常用的文本特征选择方法主要有以下几种:词频、TFIDF[6]、卡方统计量[7-9]、互信息[10-11]、信息增益[12-13]等,也可以通过遗传算法以及特征相关性等来进行选择[14]。
1.3 TFIDF特征选择算法
如果某个特征词在文档中出现的频率高,并且集中出现在少量文档之中,则认为该特征词具有很好的类别区分能力,适合用来分类。这就是TFIDF特征选择算法的主要思想[15]。TFIDF是比较常用的特征选择算法,因为它易于将那些词频较高又不在大量文章中出现的词项选出,而且计算复杂度不高,易于实现。
计算出特征项t的TFIDF的值,然后根据其值来进行特征选择。其计算公式如下:
TFIDF(t)=TF(t)*IDF(t)
(1)
其中,TF(t)表示特征项t在文档中出现的词频数;IDF(t)表示特征项t的逆文档频率数。
下面以一个较为简单的例子对TFIDF算法进行分析。假设有三个类C1、C2、C3,每个类包含3篇文档,特征词集合中有t1、t2、t3,分布情况如表1所示。
对于TFIDF的计算公式中词频计算方式有很多种,列举如表2所示。

表2 TF的计算方式
其中,ft为特征t在文档中出现的频数;maxft′为在文档中出现次数最多的特征t'对应的频数;K取值范围为(0,1)。
对于TFIDF的计算公式中逆文档频率的计算方式也有很多种,列举如表3所示。

表3 IDF的计算方式
其中,nt为出现特征t的文档频数;N为文档总个数;maxnt′为文档频数最多的特征t'对应的文档频数值。
通过表2和表3中的表达式,TFIDF的计算方法可以通过多种组合方式得到,如:
(2)
其中,ft表示特征t在文档中出现的词频数;nt表示包含特征t的文档个数;N表示文档总数。
从表1的分布中可以分析得到:t1有益于C1的分类,t2的作用明显没有t1大,t3对于分类毫无意义。三个特征的权重大小应该为:
w(t1)>w(t2)≫w(t3)
而通过式2计算t1、t2和t3的权重值为:
w(t1)=3.17=w(t2)=3.17>w(t3)=1.31
可以看出算法并没有十分突出分类能力的差异性,而且对于t3这种无助于分类的特征依然获得较大权重。所以,这样的结果并不能选出较好的特征。因此需要对权重值的计算进行调整。
2 TFIDF特征选择算法的改进
TFIDF用于特征选择具有一定的区分能力,但同时也存在不足之处。因此,很多研究人员对其进行了改进,如文献[16-17]使用了信息熵进行改进,文献[18-19]使用了类间散度和类内信息熵,Chen等将其改为TF-IGF[20]等。根据以上分析,以及参考前人研究成果,文中分析总结了TFIDF特征选择算法的两个缺点:
(1)没有考虑特征项在类间及类内的分布情况。集中出现在某个类别,而且在这一类中能够大量出现,在其他类中出现相对较少,这样的特征具有较好的分类能力。这些特征本应被选出,但是其IDF值可能并不高,通过TFIDF难以被选择出来。
(2)有的类别文档数较多,有的类别却很少,数据集不均衡是十分常见的问题。TFIDF并没有将类别考虑在内,这就使得选择出的特征词偏向于大类,而针对数据集较小的类的分类特征较少。
针对TFIDF的以上缺点,文中对该算法进行改进,不再使用IDF,而是使用了类内分布因子(α)以及类间分布因子(β)。
W(t)=TF(t)×α(t)×β(t)
(3)
式3考虑了词频、类内分布、类间分布以及数据集不均衡。特征权重值不依赖于类别,因此这是一个全局特征选择算法。
词频(term frequency,TF)反映的是特征项t在文档中出现的次数,词频高的有价值。这里选用的词频计算公式如下:
(4)
其中,maxft′为在文档中出现次数最多的特征t'对应的频数值。通过计算式4,词频较高的值较大,同时也将原来的词频选择作用弱化,并将值归一化。
类内分布因子(α)反映的是特征项t在所有类中分布最广的那一类的分布情况,其值越大表示该特征项在某类中的分布越广。计算公式如下:
α(t)=max(X1,···,Xi,···,Xk)
(5)

类间分布因子(β)反映的是特征项t在各类之间的分散程度,值越大说明特征越集中在某一类或几类当中,特征项越有价值。计算公式如下:
(6)
其中
(7)
希望选择的特征在各类之间分布差异越大越好。因为存在差异性的特征才是有益于分类的特征,β就是据此来定义的。这里考虑了数据集不均衡问题:在计算各类分布时,使用的是在各类中所占比重的因式。文献[18]提出过类似作用的因子,但没有考虑各类包含文档数的差异性。对于不均衡的数据集,只考虑各类之间包含特征t文档数的差异性显然没有意义。
上文已经对表1进行了分析,通过TFIDF算法计算得到的权重值并不能很好地代表各个特征对于分类的重要性。而通过式3计算t1、t2和t3的权重值为:
w(t1)=0.22>w(t2)=0.11>w(t3)=0
可以看出,改进方法算出的权重值可以将特征的类别区分能力较好地表现出来。文中将通过实验来验证改进方法的有效性。
3 实 验
实验在Anaconda环境下调用sklearn、matplotlib、numpy、math、re等模块实现,所有的实验结果均是在一台2.50 GHz Intel Core(TM) i7-4710MQ处理器,8 Gbytes内存的笔记本电脑上测试获得。
3.1 实验数据集
为了验证该方法的有效性,分别针对两个语料库进行分类实验,包括搜狗中文语料库以及从凤凰网和新浪网上爬取数据自建的语料库。
搜狗中文语料库是由搜狗实验室提供,这里选择了C000008财经(300篇)、C000010 IT(200篇)、C000013健康(100篇)、C000014体育(47篇)、C000016旅游(340篇)、C000020教育(350篇)、C000022招聘(350篇)、C000023文化(1 000篇)、C000024军事(500篇)。
自建语料库主要是通过python编程从凤凰网和新浪网爬取得到,其中包括文化(487篇)、娱乐(1 182篇)、财经(934篇)、健康(1 097篇)、历史(269篇)、军事(797篇)、体育(943篇)、科技(905篇)以及社会(897篇)。
选用的数据集类别较多但样本不多,同时也存在着数据集不均衡现象。
3.2 评价指标
分类模型评估指标有准确率p、召回率r和F度量值[21]。
(8)
(9)
(10)
其中,a表示实际属于该类并预测正确的个数;b表示实际不属于该类并预测正确的个数;c表示实际属于该类但预测错误的个数。
通常希望分类结果中准确率和召回率都要高,而且同等重要。文中使用的是β=1的F1度量值,即:
3.3 分类器
选用的分类器是支持向量机(support vector machine,SVM)。SVM是一种在缺乏先验知识的条件下,以最小化结构风险为目标,对有限样本进行学习的机器学习方法。支持向量机的基本思想是寻找一个最优超平面或最优超曲面,使得不同类样本之间的间距达到最大[22]。
支持向量机是目前文本分类中使用较多的分类器。支持向量机擅长解决小样本、高维度的分类问题,而文本分类就是一个高维度的分类问题,所以支持向量机相对较优。
文中实验选用的是python工具包svm.SVC的线性分类器,损失函数选用squared hinge loss,使用L2正则化,二类向多类的推广采用的是“一对多”的方式。
3.4 实验结果
对选用的两个语料库,分别使用TFIDF以及改进后的TFIDF特征选择算法。通过计算得到各个特征词的权重值,将权重值排序建立有序特征字典,然后根据字典选取topN个特征。在建立文本的向量空间模型时,特征对应的特征值是由TFIDF计算得到。于是,可将一个文档转化为一个N维向量。这里需要说明的是,实验中选用的特征是根据不同的特征选择算法计算出的权重值决定,即全部特征的子集,而向量空间模型中的特征值在文中均是使用其TFIDF值,当然也可以通过其他方式计算得到。也就是说权重值用于特征选择,而特征值是用于分类。
实验中,按照2∶1的比例将语料库分为训练集和测试集。针对训练集采用三次三折交叉验证方法确定分类器参数。最后在测试集上进行测试,计算分类的准确率、召回率以及F1度量,并对不同特征选择后的分类结果进行比较。实验流程如图1所示。

图1 文本分类实验流程
使用两种特征选择算法在两个语料库中的实验对比结果如图2和图3所示。图中清晰显示了在选取不同的特征维数时分类F1度量值的对比结果。

图2 采用搜狗语料库的F1度量值
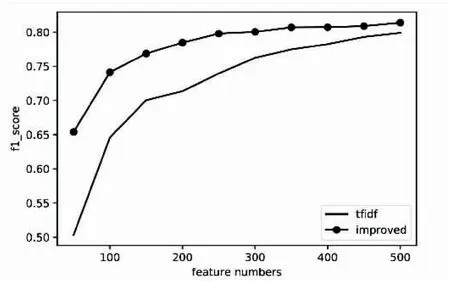
图3 采用自建语料库的F1度量值
实验结果表明:使用改进后的特征选择算法,在较少的特征维数下,与传统的TFIIDF算法相比能有效提升分类效果。表明提出的算法更加有效,同时也表明特征的重要性与其在类间与类内的分布关系密切。
4 结束语
针对传统的TFIDF特征选择算法,主要是针对逆文档频率的计算中没有考虑特征项类内分布、类间分布以及数据集不均衡状况,提出了一种改进方法。通过结合词频、类内分布因子以及类间分布因子,计算各个特征的权重值,并选择数值较高的特征项作为分类特征。通过实验与传统TFIDF算法进行了对比。实验中将两种特征选择算法分别应用于搜狗中文语料库以及自建语料库,采用支持向量机作为分类器。最后在测试集上进行测试,得到分类的F1度量值。对比结果表明,改进算法确实对Web文档分类效果有了一定的提升。
猜你喜欢
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
计算机测量与控制(2019年4期)2019-05-08
亚太教育(2018年5期)2018-12-01
长江丛刊(2017年27期)2017-12-01
现代电子技术(2016年23期)2017-01-12
电脑知识与技术(2016年25期)2016-11-16
电脑知识与技术(2016年15期)2016-07-04
电脑知识与技术(2016年14期)2016-06-30
科技视界(2015年24期)2015-08-22
