
一种顾及道路复杂度的增量路网构建方法
2019-06-10 02:42刘纪平张用川徐胜华钱新林仇阿根张福浩
测绘学报 2019年4期
刘纪平,张用川,徐胜华,钱新林,仇阿根,张福浩
1. 武汉大学资源与环境科学学院,湖北 武汉 430079; 2. 中国测绘科学研究院, 北京 100830
随着城市的日益扩张,道路不断翻修或拓建,交通规则也不时更新,导致路网信息不断变化。例如,对于北京、上海这样的大城市,每年有40%以上的地图内容应该得到更新,而采用传统的测绘方法更新常常需要几个月甚至半年以上的时间[1],同时需要耗费大量的人力、物力[2]。随着越来越多的公共交通工具都搭载GNSS定位设备,如出租车,公共汽车,以及其他公共服务车辆,产生大量GNSS轨迹数据。这些轨迹数据中蕴含了机动车行驶过道路的大量信息,为导航路网信息的实时收集和更新提供的新机遇。然而,从轨迹数据中提取导航地图信息,并自动构建导航路网地图是一项具有挑战的工作[3]。首先,由于普通定位设备存在较大误差,使得同一条道路行驶的不同车辆产生的轨迹也有较大差异,复杂的城市道路环境也导致接收到的卫星信号不稳定,加剧了误差的扩大;其次,普通车辆轨迹往往采样周期较长,使得相邻轨迹点较难体现出车辆真正行驶轨迹;再者,在立交桥、隧道、路网密集区域等复杂道路环境,通常难以确定某一轨迹点是否产生于某特定道路。由于以上问题,现实中导航路网地图生产仍然需要大量手工编辑[4]。
近年来,国内外许多学者开始探索从粗糙轨迹数据中自动获取道路信息来构建路网[5-9]。文献[10]提出了一种基于每条轨迹与道路中心线的距离和方向参数进行聚类的方法,基于高精度的DGPS设备采集到的轨迹数据和模拟数据验证了方法的有效性。文献[4]模拟物理引力模型对轨迹数据进行了除噪和预处理,然后通过逐步融合轨迹得到道路网,并用通勤车在微软园区专门采集的轨迹数据对其方法可行性进行了验证。文献[11]提出了一种以图像学为基础的混合方法,先将海量轨迹数据转换为图像,用图像学方法提取道路骨架进行提取,然后再对其进行优化,并用真实充满噪声数据进行了验证。文献[12]提出了交通路口识别及结构提取的方法,并用武汉市出租车轨迹数据进行试验证明了方法的有效性。另外,文献[13]提出基于朴素贝叶斯的方法,从低精度机动车轨迹数据中挖掘路网中的车道数量和车辆行驶方向等信息。文献[14]从人类活动轨迹的角度识别和提取城市交通网中的关键位置。文献[15]分析了轨迹数据的运动特征、几何模式等信息,利用Delauany三角网提取了加油站信息。已有算法采用的方法大致可以分为4类,如表1所示:①基于轨迹聚类,该类方法基本原理是对输入的原始轨迹数据利用诸如k-means等不同方法进行聚类,然后对聚类得到的道路片段进行融合,进而获取道路的中心线和交叉路口;②基于增量轨迹合并,该类方法首先假设路网图为空,然后遍历所有轨迹,根据规则逐步合并点和边,最终得到表示路网的一幅图;③基于道路交叉点连接,该类算法首先探测路网交叉点,然后通过识别合适的路段将交叉点连接形成路网;④基于数字图像处理算法,该类算法首先将轨迹数据转化为数字图像,利用数字图像处理方法对轨迹图像进行处理(如滤波去噪、形态学方法等),然后由处理后的图像提取骨架道路,最后再优化得到路网。另外,在评价算法自动构建路网的质量方面,构建路网与底图数据进行叠加后观察重叠度是常用的定性评价方法,F-score常用来定量比较构建道路的质量,也有学者利用有向Hausdorff距离、Frechet距离等度量来评估所构建路网的拓扑方面质量[16-17]。

表1 基于轨迹数据的道路构建算法分类
以上算法大多针对高精度(0~5 m)、密集采样(1~5 s)的小数据(一般少于百万个轨迹点),而对数据量巨大(数以亿计)、粗糙定位(>5 m)、稀疏采样(>15 s)的实际轨迹数据的处理情况少有研究。另一方面,现实中弯曲道路、立交桥和十字路口等复杂路口需要被描述得更为详细,而简单道路(如直线道路)可以用少量几个点表示,以上算法也未考虑这一因素,导致计算量的增加,也使得道路复杂路段得不到详细表达。笔者提出了一种顾及道路复杂度的增量路网构建算法,能有效地通过海量粗糙定位数据自动构建路网地图,并用海量真实轨迹数据进行试验,验证了其有效性。
1 定 义
定义1:粗糙轨迹数据,车辆在城市道路移动过程中,被所搭载GNSS接收装置按时间顺序连续记录的一系列位置原始坐标的集合。本文中,粗糙轨迹数据用集合C表示,其中任意位置点用p=(唯一标识号,时间,经度,纬度)表示。
定义2:规范轨迹,同一车辆行驶过程中连续记录的原始位置坐标序列经过滤选得到的子集traj={p1,p2,…pi,…,pn},其中pi为位置点,该子集满足中轨迹滤选模型设定的系列约束条件。
定义3:道路复杂度,指路网在数量、方向、交叠等方面的复杂程度。通常意义上,一个区域内道路的交叉口越多,立交桥越多,高架桥越多,那么该区域的道路网络就越复杂。本文通过计算一定区域内各道路方向角的信息熵来描述道路复杂度,其具体计算方法将在下面给出。
定义4:路网地图。路网地图为一幅有向图G=〈V,E〉,V表示道路节点或交叉点,E表示道路,E的方向表示道路的方向,道路的拓扑规则隐含在有向图中,E的属性表示道路平均速度和交通流量等信息。
本文提出的路网地图自动构建方法包含轨迹滤选和路网增量构建两步:第1步通过构建空间、时间、逻辑约束的规则模型,在消除数据中噪音和冗余的同时,将原始轨迹进行分割,筛选形成规范轨迹集合T;第2步利用信息熵计算轨迹点周围道路的复杂度以自动调节道路分割参数,不断将新产生的路段加入到路网,同时,计算道路平均交通流量和速度,遍历各轨迹的定位点重复以上处理过程,最终得到完整路网。
2 规范轨迹滤选
通常,粗糙轨迹数据存在大量质量问题:①GNSS接收机可能存在故障,产生大量定位异常轨迹;②在高建筑物、树荫、隧道、立交桥等区域,受卫星信号的影响,产生大量定位噪声,也称为漂移点;③车辆停靠或者特慢速行驶时,在局部区域产生大量轨迹冗余点,增加了数据处理计算量;④其他原因产生时间间隔较长定位点,其连线不能反映真实的道路情况。如图1所示,按时间顺序直接连接出租车行驶产生的原始轨迹点会产生大量不合理的“路径”,这些不合理路径在道路的交叉口表现明显,见图1(b)。以上问题给数据分析带来困难,影响路网提取结果的质量[25],需要对原始轨迹数据进行滤选和分割。

图1 粗糙的轨迹数据与OpenStreetMap地图(昆明市人民中路附近区域)Fig.1 Coarse trajectory data vs map from OpenStreetMap (around Kunming People’s Middle Road)
根据经验和大量试验分析,一条良好的轨迹应具有以下特征:①轨迹中两连续定位点的时间间隔Δt应等于设定的采样点间隔ζ;②两连续点间的距离Δd应小于某一距离阈值δ0。例如,规定城市高速路上车辆速度小于Vmax_speed,则两点间间隔一般小于Vmax_speed×Δt;③在数据不冗余情况下,任意两连续点间距离Δd应大于某距离阈值δ1;④轨迹内任意两点间距离的最大值dmax应大于某一阈值δ2。本文根据以上经验知识,提出一种基于规则模型的轨迹滤选方法对粗糙轨迹进行处理,滤选模型构建如下:
(1) 如果Δt≥3ζ,则将从这两点间将其划分为两条不同的轨迹。
(2) 如果Δd≥δ0,则将从这两点间将其划分为两条不同轨迹。
(3) 如果Δd≤δ1,则只保留前一个轨迹点。
(4) 如果dmax≤δ2,将轨迹删除。
该模型处理粗糙轨迹数据的流程如图2所示。通过该模型处理后,可以大幅度消除误差和漂移点,减少数据冗余,最终将粗糙的轨迹数据C组织为规范轨迹集合T={traj1,traj2,…,trajn},每条规范轨迹中,点方向角由其前后两轨迹点连线方向代替,首尾点方向由其相邻点连线方向角代替。

图2 基于规则模型的轨迹滤选流程Fig.2 Flowchart of trajectory filtering based on rule model
3 增量路网构建
轨迹滤选处理后,得到规范的轨迹集合T,将作为增量路网构建处理的输入,顾及道路复杂度的增量路网构建思路是:首先初始化代表路网的有向图G为空,然后遍历所有轨迹中的定位点,根据所遍历定位点周围道路的复杂度,自动计算阈值,根据阈值大小,将定位点插入到有向图中,或者与有向图中已构建点进行合并,更新节点之间的连接边,同时计算有向图中边的速度和其他属性信息,最终得到一幅交通路网图,方法的流程如图3所示,下文对流程中的重点进行阐述。
判断待处理点是否应该与已构建到道路网边融合。基于在同一条道路上行驶产生的轨迹数据有着相似性这一事实,这里主要考察两个参数:待处理轨迹点的方向与欲合并边的方向角差异ΔA;待处理点与拟融合边的距离Δh,这里取其投影距离。如果待处理点与拟合并边的方向角小于某一阈值θ,同时其投影点在边上,投影距离小于某一阈值φ,便将点与边融合,否则不融合。
p点周围道路轨迹复杂度计算。在给出轨迹点所处道路环境复杂度计算公式之前,首先约定路段p与路段l的方向距离Da(p,l),其计算如式(1)所示
Da(p,l)=sin(Ap-Al
(1)
式中,Ap为路段p的方向角;Al为路段l的方向角。从式(1)中容易看出,当两路段路方向相同或者相反时候,两者的方向距离为0,当两路段垂直时,两者的方向距离达到最大值1。
在任意待处理轨迹点邻域σ范围内,路段p方向上信息熵计算如式(2)所示
(2)

(3)
Hσ作为σ邻域内道路的复杂度,容易证明,当所有路段方向一致或者相反时,Hσ=0,随着道路复杂度的增加,如道路数量、道路角度的分布差异等增加,Hp,A值递增,其最大值为log(n)。
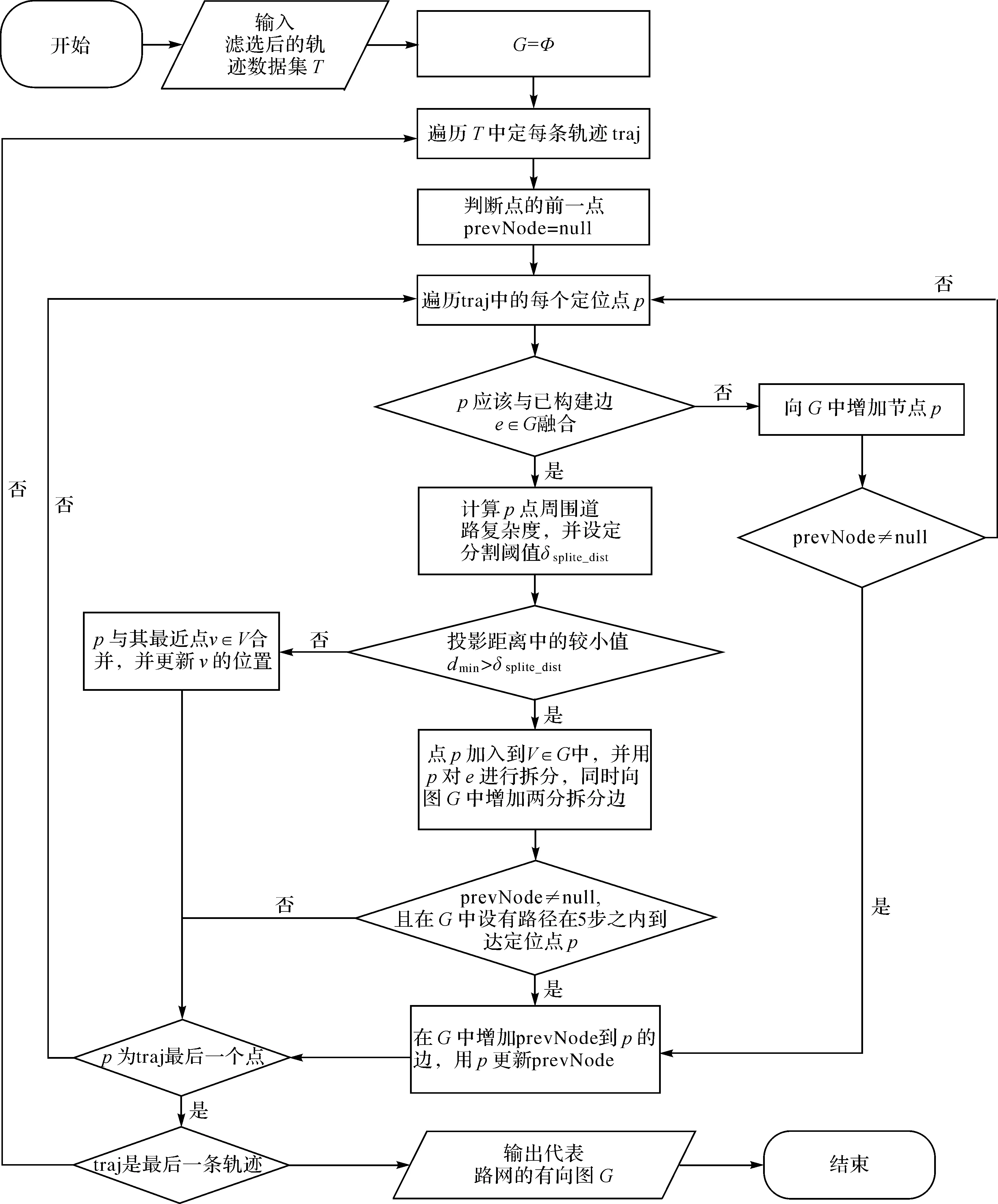
图3 顾及道路复杂度的增量路网构建流程Fig.3 Flowchart of incremental road network construction considering road complexity
设定分割阈值δsplite_dist大小。分割阈值δsplite_dist控制着构建路网中边的平均长度,即路网的详细程度。这里基于道路复杂度设定分割阈值δsplite_dist,待处理轨迹点周围区域σ由其半径r确定,其取值需综合道路的宽度和路网密度(一般城市道路取100 m左右),其计算如式(4)所示
(4)
式中,Lmax为最大分割长度,其值一般不会大于相邻轨迹点之间的距离。从式中不难看出,当轨迹点方向与已构建道路方向相同或相反,分割阈值为Lmax;当轨迹点与周围道路较复杂,δsplite_dist值将会越小,已构建道路将会被分割得越细,路网表达将会越详细。
p点与其临近点v融合。由于定位误差和车辆行驶时候的特点不同,轨迹线之间存在较大的差异,单条轨迹线难以准确地表示实际道路的中心线位置,所以需利用后加入轨迹的信息对先前构建的路网进行修正。新加入点与已构建边进行融合的过程中,可以实现对已有路网的修正。本文采用加权平均位置,权重由该点所包含的已融合点个数确定。同时,更新相关边的交通流量和速度信息。
路网增量构建的过程示例见图4,traj1={P1,P2,P3,P4}为输入的一条待处理的轨迹。G=〈V,E〉={{V1,V2,…,V8},{e1,e2,…,e7}}为已构建路网,其中,P1已与V2合并,P2为待处理轨迹点,其方向为P1P3方向。对P2点的主要的处理过程如下:
(1) 首先查找点P2周围阈值δ3范围内的所有已构建道路作为候选边,如图4中e2、e3、e6、e7。

(4) 如果①②③条件全部满足,将P2点与e2融合,并计算d1、d2中较小的值dmin=min(d1,d2),这里dmin=d1。
(5) 如果dmin小于分割阈值δsplite_dist,将P2点与e2中离投影点较近的端点V3合并,并重新计算合并到V3中所有点位置的重心更新V3位置。
(6) 如果dmin大于分割阈值δsplite_dist,用P2点对V2V3进行分割,P2加入到V∈G中,V2P2,P2V3加入到E∈G中,删除V2V3,并更新相应边的交通流量和速度属性。
(7) 判断P2的前一轨迹点P1(已合并到V2)是否为空(显然不为空),且在已构建路网中存在5步内连接到合并点V3的道路,所以不用增加连接路径。
(8) 更新判断点P2为前判断节点prevNode。再循环步骤(1)—(8), 处理轨迹traj1中剩余轨迹点,直到所有轨迹点处理完毕。读取其他轨迹,循环以上过程,直到所有轨迹处理完毕。

图4 路网构建过程Fig.4 Road network construction process
4 试验分析
4.1 试验环境与数据
运用Python2.7.15对本文方法进行了实现,试验硬件环境为一台Intel Xeon CPU E7-4807@1.87 GHz*2,64 GB内存的服务器。
试验数据为2016年11月昆明市200辆搭载GPS设备的出租车日常运营行驶所产生,覆盖昆明市约1000 km2区域。GPS轨迹点数据采样间隔为15~45 s不等,数据的定位精度为5~30 m不等,全部点数据约为6851万条,主要包括车辆ID、时间、经度、纬度等字段。考虑到数据的可获取性,试验对比数据选用OpenStreetMap地图数据。
4.2 试验结果与分析
轨迹滤选结果受采样间隔ζ,两连续点间的距离阈值下限δ0,距离间隔阈值上限δ1和出行最小范围阈值δ2影响,各阈值具体的选择取决于轨迹数据自身的特点,对试验数据描述性统计分析,结果见表2。

表2 对原始轨迹数据描述性统计
根据以上统计信息,试验选择各阈值ζ=15 s,δ0=5 m,δ1=200 m,δ2=500 m,共耗时2 min 9 s完成试验,产生约43.67万条轨迹,每条轨迹线平均包含137个轨迹点。试验结果显示,随着ζ增加,不合格的轨迹增加,随着ζ减小,轨迹数量增多,且每一条轨迹中包括更多的定位点;随着δ0减小,每条轨迹中的包含路段长度减小,包含轨迹点量增多;随着δ1的增加,会产生无效轨迹;随着δ2增加,更多轨迹点被删除,导致最终结果不平滑。图5显示轨迹滤选的整体结果,图5(a)为研究区域的OpenStreetMap背景地图。图5(b)中,直接将粗糙轨迹数据按照时间顺序连接,从图中观察到道路网骨架,但其中包括大量杂乱模糊的噪声。图5(c)展示经过轨迹滤选处理后的结果,从整体和局部放大的图可以观察到大量明显噪声数据已经被滤去,经过轨迹滤选后的轨迹能够更清楚表达道路结构。然而,由于轨迹定位误差等原因的存在,位于同一条道路的众多轨迹彼此不能完全重叠,道路的方向和几何拓扑关系也没有表现出来,十字路口周围也有大量杂乱线段,这些问题将在路网构建中得到解决。
在经过规范轨迹滤选处理后,得到规范的轨迹数据,再进行增量路网构建,路网构建的质量受轨迹融合条件参数方向角差异阈值θ、投影距离阈值φ、待处理点环境周边半径r、最大分割阈值Lmax的影响。经过大量试验,发现当θ=30°,φ=50 m,r=100 m,Lmax=1200 m时,本文提出方法能取得较好的试验结果。表3展示了上述参数取值情况下,经过路网构建得到结果的统计信息和文献[4]报道方法所得结果比较,包括路网中节点的数量、路段数量、路段的平均长度、整个路网的平均行驶速度信息。从表中可以看出,对于同一区域,本文方法能大量减少构建路网所需的节点数量和路段数量,平均路段长度有所增加,而平均速度变化不大。这是因为通过本文提出的道路复杂度H(σ),对分割阈值δsplite_dist进行了动态设定,一方面虽然在交叉路口等复杂路段区域增加了节点数量,但增加了复杂路段区域的详细程度,另一方在直线类型简单道路中大量减少了节点数量。试验表现出来总节点数量减少,但路网的质量得到提升。

表3 生成路网地图统计结果比较
图6(a)展现了试验构建的交通路网概况,绿色实线表示道路,黄色箭头表示道路方向,实线的粗细表示道路上的交通流量大小。结果与OSM地图数据叠加对比,可以发现生成的路网良好展现了试验区域内的大部分的路网、路网连通性等路网拓扑信息和道路的行驶规则,在类直线型的简单道路上节点较少,在拐弯情形等复杂路段使用了较多的节点进行表达。图6(b)展示了生成路网的与OSM地图的叠加效果,图中绿色线段为生成的路网,可以观察到生成路网与OSM地图能实现很好重合。
上述试验结果表明,本文描述基于规则模型的轨迹滤选方法可有效消除原始数据中存在的噪声,滤选出规范轨迹,极大地提升后续路网构建的质量;引入道路复杂度对分割阈值进行自动调节,能在减少路网整体节点的同时增强所构建路网的质量。另外,该方法也存在部分问题有待进一步解决问题:①某些路段在OSM地图中存在,在生成的路网中并不存在,一方面是因为轨迹数据的覆盖度有限,试验轨迹不能覆盖所有区域,尤其是机动车禁止行驶的步行道路,另一方面,试验数据为2016年昆明市轨迹数据,不能反映目前最新的道路状况;②生成的路网地图中将立交桥识别为十字路口,这是因为本文将路网建模为平面图,未来工作中可进一步研究立交桥、十字路口等复杂路网的精确提取;③某些交叉路口周围仍存在一些杂乱边,这是由于GNSS定位过程中存在系统误差,且路网较为复杂。未来工作中可尝试引入典型交叉路口模型,或者利用模式识别算法训练交叉路口轨迹点样本来解决这一问题。
5 结 论
通过粗糙轨迹数据自动构建导航交通路网,可作为传统实地测绘方法以及从遥感影像提取信息方法的有力补充,在减少导航信息采集成本、缩短导航地图信息更新时间、减少制图工作量方面有着重要意义。顾及道路复杂度的增量路网构建方法,由基于规则模型的轨迹滤选和考虑道路复杂度的增量路网构建两部分组成。试验结果表明,该轨迹滤选算法能有效消除噪声,滤选出规整轨迹,基于信息熵提出的路网的复杂度在构建路网时,能根据待处理轨迹点周围已构建道路的复杂度自动调节合并参数,在路网复杂的区域更为详尽地提取路网信息,最终自动构建完整道路网的几何骨架和拓扑信息。此外,该方法在构建路网几何信息同时,还计算了路网的平均交通流量和平均速度。与类似路网构建算法相比,本文方法能用更少的节点和路段,构建更高质量的路网。未来研究将会致力于提高本方法的运行效率,利用F-score,Hausdorff距离、Fréchet距离等度量方法对所路网的拓扑和几何属性进行定量评估,以及结合自动驾驶需求的导航地图自动构建。

图5 GNSS车辆轨迹滤选结果Fig.5 Results of GNSS vehicle trajectories filter
猜你喜欢
工会博览(2022年5期)2022-06-30
建材发展导向(2019年11期)2019-08-24
中国交通信息化(2019年12期)2019-08-13
中国惯性技术学报(2019年6期)2019-03-04
环球飞行(2018年7期)2018-06-27
中国公路(2017年11期)2017-07-31
中国公路(2017年7期)2017-07-24
中国公路(2017年10期)2017-07-21
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
公民与法治(2016年16期)2016-05-17
