
大数据的数据清洗技术及运用
2019-07-12 08:28卢星
电子技术与软件工程 2019年9期
文/卢星
1 数据清洗技术概述
数据清洗技术是为了提高数据质量而剔除数据中错误记录的一种技术手段,在实际应用中通常与数据挖掘技术、数据仓库技术、数据整合技术结合应用。数据清洗技术的基本原理为:在分析数据源特点的基础上,找出数据质量问题原因,确定清洗要求,建立起清洗模型,应用清洗算法、清洗策略和清洗方案对应到数据识别与处理中,最终清洗出满足质量要求的数据。具体如1所示。数据清洗是数据分析、数据挖掘的前提,也是数据预处理的关键环节,可保证数据质量和数据分析的准确性。在大数据环境下,数据清洗技术已经被广泛应用于大健康、银行、移动通信、交通等领域,在一定程度上保证了数据质量,为大数据决策提供了可靠依据。
2 大数据的数据清洗技术及应用
2.1 基于函数依赖的数据清洗技术
基于函数依赖的数据清洗技术,可解决数据异常、重复、错误、缺失等问题,能够在数据预处理环节对脏数据进行清洗,从数据源处减少噪声数据,提高数据清洗效率。该数据清洗技术可广泛应用于移动互联网数据分析等领域,具体应用步骤如下:
2.1.1 建立数据库
根据清洗特征建立数据库,在数据库中存储有质量问题的待清洗数据,对数据库进行优化,生成原始数据库。
2.1.2 数据筛选
对原始数据库中噪声数据进行分析,利用语义关联挖掘隐藏在字段间的关系,即字段间的函数依赖关系,进而确定数据的待清洗属性。
2.1.3 数据查找
根据字段间的函数依赖关系找出原始数据库中存在差异的数据,建立其高阶张量属性集。
2.1.4 数据清洗
在原始数据库中找出可信度较低的字段,利用字段间的函数依赖关系清洗字段和数据,并对数据进行修复。
2.1.5 数据获取
在数据库中更新清洗后的数据,生成目标数据库集,并对清洗过程进行记录,生成清洗日志。清洗日志主要包括原始数据、清洗时间、清洗操作、清洗后数据等信息,为日后数据处理和数据质量分析提供记录依据。
2.2 相似重复数据清洗技术
在大数据中,相似重复数据是数据清理的重点,具体表现为多种形式的记录描述目标却相同,或多条同样记录表达同样含义,其产生的原因多种多样,主要包括数据录入拼写错误、存储类型不一致、缩写不同等。由于相似重复数据的识别难度较大,所以必须借助重复检测算法进行检测,以保证相似重复记录数据的清洗效率,避免数据冗余。相似重复数据检测是对字段和记录是否存在重复性进行检测,前者主要采用编辑距离算法,后者却主要采用优先列队算法、排序邻居算法、N-Gram聚类算法。
2.2.1 基于排列合并算法的数据清洗技术
基于排列合并算法的相似重复数据清洗流程如下:分析源数据库的属性段,确定属性的关键值,根据关键值按照自上而下或自下而上的顺序排列源数据库中的数据;对数据库中的记录进行扫描,并将扫描后的数据与相邻数据进行比较,按照算法计算相邻数据的相似度;系统预设阈值,根据阈值评价计算出来的相似度是否在规定范围内,如果超过阈值,则说明这些相邻的数据或记录属于相似重复记录,采用合并数据或删除的方式处理数据。如果未超过阈值,则按照顺序继续扫描下面数据;在数据全部检测之后,输出检测后的数据。
2.2.2 基于N-Gram算法的数据清洗技术
该技术通过计算每条记录的N-Gram值,对相似重复数据进行排序。马尔科夫假设下一词出现的概率依赖于前一个或前几个词出现的概率,其数据模型表达式为P(S)=p(w1)p(w2|w1)p(w3|w2)…p(wi|wi-1)…p(wn|wn-1)
二元的Bigram认为,每条语句中的词有且仅有与其前面最相近的词存在相关,其概率数学模型表达式为:
P(S)=p(w1w2…wn)=p(w1)p(w2|w1)p(w3|w1w2)…p(wn|w1w2…wn-1) ≈ p(w1)p(w2|w1)p(w3|w2)…p(wn|wn-1)
三元的Trigram假设下一个词仅与前两个词存在依赖关系,其概率数学模型表达式为:
P(S)≈ p(w1)p(w2|w1)p(w3|w1w2)…p(wn|wn-2)wn-1)
数据清洗过程如下:处理带有标识性含义的标点或者无法识别的字符串;扫描整个数据库,建立起基于N-Gram算法的语料库;按照N-Gram算法对数据记录进行分割,计算重复矩阵;对待清洗数据记录计算它们的N-Gram值;按照N-Gram排序待清洗数据记录,计算记录之间的相似度,根据相似度高低判断记录是否重复。
2.3 不完整数据清洗技术
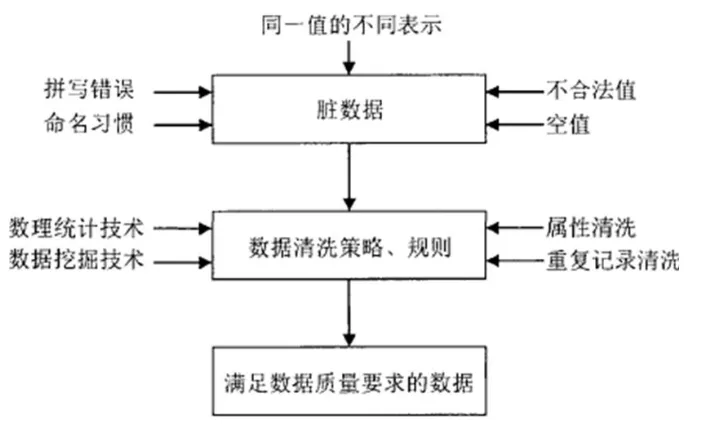
图1:数据清洗流程示意图
大数据时代下,在数据上报或接口调用时会存在大量不完整的数据,严重影响着数据质量。不完整数据主要包括属性值错误和空值,其中用于前者的检测方法为关联规则法、聚类方法、统计法,上述方法均通过总结规律对错误值进行查找,找到错误值后予以修复;后者的检测方法以人工填写空缺值、属性值为主,其空缺值包括最小值、最大值、中间值、平均值或概率统计函数值。在不完整数据清洗中,一般按照以下清洗流程:估计数据源的缺失值参数,为数据清洗提供依据;利用数据填充算法填充不完整数据的缺失值;填充后的数据为完整数据,将完整数据输出。
2.4 不一致数据修复技术
大数据环境下,数据源受多种因素的影响,违反完整性约束,造成大量不一致数据的产生。在数据清洗中,要利用不一致数据修复技术使不一致数据符合完整性约束,进而保证数据质量。数据修复流程如下:检测数据源中的数据格式,对数据格式进行预处理;检测预处理数据后的数据是否符合完整性,如果不符合,则要修复数据。如果在数据修复之后依然存在着与数据完整性约束不一致的情况,则要再次修复数据,直到数据符合要求;数据修复完成后,将其还原成原格式,为数据录入系统打下基础。
3 结论
总而言之,数据量大、价值密度低是大数据的特点,为了提高数据质量,必须在数据预处理阶段进行数据清洗,采用不完整数据清洗技术、不一致数据修复技术、相似重复数据清洗技术等,修复缺失数据、不一致数据和异常数据,合并或删除相似重复数据,进而保证数据预处理质量,提高数据利用效率。
猜你喜欢
江苏科技信息(2022年16期)2022-07-17
计算机与生活(2018年3期)2018-03-12
制导与引信(2017年3期)2017-11-02
中国科技期刊研究(2017年2期)2017-05-14
环境科技(2015年6期)2015-11-08
浙江大学学报(工学版)(2015年2期)2015-05-30
电网与清洁能源(2015年2期)2015-02-28
图书馆建设(2015年10期)2015-02-13
新世纪图书馆(2014年7期)2014-09-19
图书馆建设(2014年3期)2014-02-12
