
基于邻域关系矩阵的属性约简算法
2019-08-13 12:38徐波,冯山
小型微型计算机系统 2019年8期
徐 波,冯 山
(四川师范大学数学科学学院,成都610068)
E-mail:xuboxbox@163.com
1 引言
粗糙集理论[1]已被广泛应用于机器学习、规则挖掘、模式识别等领域[2,3].属性约简是其核心研究内容之一,在智能信息处理研究中占有重要地位.对给定任务数据集,不是所有属性都同等重要.例如,能够由其他属性导出的属性是冗余的,其存在会带来时空浪费,且干扰决策.属性约简正好是在保持或改善数据决策能力下删除不重要或冗余属性.
含有决策属性的数据集称为决策表,其属性约简并不一定唯一.找到具有最少条件属性子集的约简是人们的期望.但文献[4]表明,由于属性的组合爆炸,决策系统中基于粗糙集的最小属性约简是一个NP-hard问题.因此,在决策系统的约简算法中,融入启发信息以加快属性约简算法的收敛速度成为一个主流的研究方向[5].
根据启发信息的不同,启发式约简算法有关联差别矩阵[6]、信息度量(包括信息熵、互信息熵、条件信息熵、近似决策熵)[7-9]、三支决策[10]和属性重要度(正域)[11]等.在基于属性重要度的约简算法中,一般以等价关系区分对象,故只能直接处理离散型属性对象.实际上,离散型、连续型和混合型属性数据都大量存在,直接采用现有算法有局限.为此,Lin[12]提出了基于拓扑学中内点和闭包的邻域关系及邻域模型相关的概念.Yao[13]研究了1-step邻域系统与粗糙集近似的关系.基于此,胡清华等[14]研究了邻域系统的粗糙计算及属性约简,以邻域关系代替等价关系提出了基于邻域粗糙集模型的特征选择算法NRS,它可直接处理混合型属性数据集,是传统基于属性重要度的约简算法的直接拓展.因NRS的正域启发只考虑某类样本邻域信息粒的决策信息,忽略了邻域信息粒中多类样本的情形,导致约简效果不理想.于是文献[15]提出基于邻域决策误差最小化的特征选择算法NDEM,它将一致性指标引入邻域粗糙集中,由样本邻域信息粒的内部类分布和多数决策原则重新给各样本分配类别,进而统计实际类别与重分类别的差异率.但它只考虑各类分布不均匀时样本邻域信息粒中决策信息,无法准确反映各类分布均匀时样本邻域信息粒中的决策信息.目前,对邻域粗糙集中条件属性子集与决策属性间的不确定性度量研究已有一些成果,如文献[1http://archive.ics.uci.edu/ml,2013.6]的邻域精度、邻域信息熵等.
在文献[14-16]基础上,通过分析邻域决策系统的邻域信息粒中类分布,结合样本邻域信息粒的决策分布,本文提出一种能反映条件属性子集与决策属性间相关性的度量.以邻域关系矩阵表示邻域关系,将邻域关系间的集合运算转化为矩阵运算,探究了邻域关系矩阵的基本性质.证明了相关性度量的粒化单调性,结合排序思想与邻域关系矩阵对称性,改进了文献[17]计算单属性关系矩阵算法(Single Attribute Neighborhood Relation Matrix algorithm,SANRM),将其时间复杂度降低至对数级,并设计了基于邻域关系矩阵的启发式约简算法(heuristic Neighborhood Relation Matrix Attribute Reduction algotirhm,NRMAR).UCI1http://archive.ics.uci.edu/ml,2013.数据集实验的比较分析表明,NRMAR比NDEM选择更少的属性,且可以保持或改善数据集的分类能力.
2 邻域决策系统的概念与性质
一个信息系统是一个形如IS=(U,A,V,f)的四元组.U={x1,x2,…,xn}是论域;A 是属性集;V=∪Va( a∈A)是属性值域的并,Va是属性a的值域;f:U×A→V是映射,对 xi∈U,a∈A,有f(xi,a)∈Va.A=C∪D,C∩D= 时,C 为条件属性集,D为决策属性集.此时称为决策信息系统或决策系统,记 DIS=(U,C∪D,V,f).特别地,本文 D={d}.
对邻域决策系统 NDIS=(U,C∪D,V,f,δ),要引入距离函数与邻域半径δ来度量样本在属性集上的区分性.
对任意非空条件属性子集 BC,B={b1,b2,…,bm}, xi,xj,xk∈U(1≤i,j,k≤n),距离函数 ΔB(xi,xj)要满足:
1)ΔB(xi,xj)≥0,ΔB(xi,xi)=0(非负性);
2)ΔB(xi,xj)=ΔB(xj,xi)(对称性);
3)ΔB(xi,xk)≤ΔB(xi,xj)+ ΔB(xj,xk)(传递性).
ΔB(xi,xj)计算xi与xj在属性子集B下的距离.本文采取文[14]的欧氏距离函数,即:

其中,f(xi,bl)与 f(xj,bl)分别表示样本 xi与 xj在属性 bl下的属性值.
定义 1[14].NDIS=(U,C∪D,V,f,δ)中, xi∈U,给定 δ≥0,定义在B上的δ-邻域为:

其中 1≤i,j≤n.δ-邻域又称为邻域信息粒或样本邻域类,表示样本在属性集B下的不可区分样本集.它不仅蕴含样本间的不可区分性,也含有决策信息.
性质1[14].邻域nB(xi)具有如下基本性质:


性质2是条件属性子集与决策属性相关性度量的单调性理论基础.
定义 2[14].在 NDIS=(U,C∪D,V,f,δ)中,BC 可以确定邻域关系nr(B):

邻域关系是基于距离度量的一种相似关系,拓展了等价关系的适用范围.B为离散属性集时邻域半径δ=0,此时关系退化为等价关系;B为连续属性集时δ>0,此时可以直接处理混合型属性数据集.
3 基于邻域决策误差率最小化准则的分析

可引入0-1判别函数如下:

其中,ω(xi)为样本xi的真实类别.则邻域决策误差率可以定义为:

公式(2)只考虑了样本邻域信息粒中各类分布不均匀情况,在多数决策原则下只能反映多数样本信息粒的类别信息.当样本邻域信息粒中各类分布均匀时会出现错误决策.

图1 二维空间上的样本分布实例Fig.1 Sample distribution on two-dimensional space
如果论域样本的二维空间分布如图1.类为d1和d2.x1~x4的类为 ω(x1)=ω(x2)=ω(x4)=d1和 ω(x3)=d2,λ(ω(x1),d1)=0、λ(ω(x2),d2)=1、λ(ω(x3),d2)=0.对 x4,P(d1|nB(x4))=P(d2|nB(x4))=,由多数决策原则,它可以被判定为 d1或 d2类,故 λ(ω(x4),d.)=1 或0.显然,此时的邻域决策误差率无法正确反映各类均匀分布的样本邻域信息粒中的决策信息.为此,需要提出能够反映条件属性子集与决策属性相关性的度量,它依赖于每个样本在决策属性上的邻域信息粒与条件属性集上的邻域信息粒的融合所提供的信息量,以避免无法刻画各类均匀分布时样本邻域信息粒中决策信息的情况.

其中nD(xi)与样本xi真实类一致;nB(xi)是B下不能与xi区分的样本集,其每个样本类不尽相同.与公式(2)相比,公式(3)可以准确反映nB(xi)中各类不同分布时的类信息量,具体体现在n(B,D)(xi)中元素个数.当与xi不同的类中样本数居多时n(B,D)(xi)中元素多;当xi同类与xi不同的类中样本数相同时n(B,D)(xi)中元素相对减少;当只有 xi一类时 n(B,D)(xi)中元素最少,即nD(xi).综上,n(B,D)(xi)中的元素都可唯一确定.故基于融合信息粒可给出B和D的相关性度量定义.
定义4.NDIS=(U,C∪D,V,f,δ)中, xi∈U,D 关于 B的融合邻域信息粒n(B,D)(xi),B与D的相关性度量为:
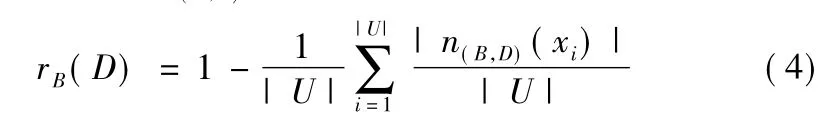
显然,公式(4)可以有效反映B与D的相关性,克服公式(2)无法准确反映邻域信息粒的决策信息不足,避免邻域信息粒的各类分布均匀时的错误决策,还具备粒化单调性.为证明公式(4)的相关性质,可引入邻域关系矩阵将邻域关系的集合运算转化为矩阵运算.
4 基于邻域关系矩阵的属性约简
4.1 邻域关系矩阵相关概念与性质
定义5.(邻域关系矩阵)NDIS=(U,C∪D,V,f,δ)中,U={x1,x2,…,xn},BA 有邻域关系 nr(B),则邻域关系矩阵为 MB=(mij)n×n,其中 n=|U|

命题1.(邻域关系矩阵与δ-邻域关系) xi∈U,若有B上 δ-邻域 nB(xi),如果 NDIS=(U,C∪D,V,f,δ)中的邻域关系矩阵 MB=(mij)n×n,n=|U|,则有:

证明:δ-邻域nB(xi)是样本集,将其与n维0-1向量建立一一对应关系,对应论域中所有样本,则有:

性质 3[17].邻域关系矩阵 MB=(rij)n×n具有如下性质:
1)对 i=1,2,…,n,有 rii=1(自反性).
2)MB是对称矩阵(对称性).
3) i,j,k∈{1,2,…,n},rij=rjk=1 时 rik=1(传递性).
由此,可以构建计算单属性下邻域关系矩阵的快速算法(SANRM).由于邻域关系矩阵是布尔矩阵,元素只有0和1,邻域关系矩阵的∧运算与∨运算可定义如下.


为了证明基于邻域关系矩阵的属性相关性度量的粒化单调性,可以定义矩阵间的如下偏序关系.

由命题1的邻域关系矩阵与δ-邻域的关系可知,MP中每一行的第j列取值1时,MQ中对应行列位置处取1或0;MP中每一行的第j列取值0时,MQ中对应行列位置的取值必为0.由定义7 可知,MPMQ.
4.2 基于邻域关系矩阵的属性约简的相关概念

其中,sum(M)表示矩阵M中元素为1的个数.
性质1.
1)规定 M=(1)n×n,若 B= ,则 mrB(D)=0;
2)当且仅当 MB=MD=diag(1)n×n,则 mrB(D)=1其中diag(1)n×n是元素值为1的n×n阶对角矩阵.
证明:

性质1说明,B= 时条件属性子集与决策属性无关,相关度达到最小值0;性质2说明,能够找到一个条件属性子集B与决策属性D的具有相近的决策能力.此时,两者的相关度达到最大值1
由定义4,rB(D)依赖于融合邻域信息粒n(B,D)(xi)中元素的个数.由命题1中集合与矩阵间的一一对应关系,定义8中mrB(D)=rB(D),在表示与计算上,前者基于邻域关系矩阵,后者基于集合.下面证明mrB(D)具有粒化单调性.



命题3表明,mrB(D)具有粒化单调递增性.条件属性子集B越大(即随着新条件属性的加入),mrB(D)值越大,所以mrB(D)能够作为启发信息构建启发式约简算法.
定义9.NDIS=(U,C∪D,V,f,δ)中, b∈BC,若 mrB(D)=mrB-{b}(D),称b为B基于邻域关系矩阵属性相关性度量的冗余属性;否则,mrB-{b}(D)<mrB(D)时称b为B基于邻域关系矩阵属性相关性度量的必要属性.
定义10.(基于邻域关系矩阵的属性约简)在 NDIS=(U,C∪D,V,f,ε)中,非空属性子集 BC 称为基于邻域关系矩阵的属性约简,如果其满足:
1) b∈B有mrB-{b}(D)<mrB(D),即B中属性都必要;
2)mrC(D)=mrB(D).
为加快约简算法收敛速度,减少不同属性集样本间距离计算,单属性集与多属性集下邻域关系矩阵有如下关系.

证明:令MB=(mij)n×n,由命题1中邻域关系矩阵与邻域的关系知mij=1xj∈nB(xi); {b}B,由性质2的 nB(xi)单调性有xj∈nB(xi)n{b}(xi),故
由命题4,多属性邻域关系矩阵计算可转为单属性邻域关系矩阵运算以减少样本间距离的计算次数,减少约简的时间.文献[17]的单属性关系矩阵计算主要基于样本间的依次比对,时间复杂度为O(|U|2).将有序性和邻域关系矩阵对称性融合,改进的计算单属性邻域关系矩阵算法(SANRM)时间复杂度为O(|U|log(|U|)).定义11是决策系统的矩阵表示.
定义11.对 DIS=(U,C∪D,V,f),|C∪D|=m,|U|=n,有信息矩阵Wn×m(记W),W中每一列描述样本的一种属性,每一行由样本的各属性值构成,最后一列是决策属性.
算法1.计算单属性下邻域关系矩阵(SANRM)

输出:邻域关系矩阵M{ai}.


算法1对论域样本进行给定属性的升序排列并一一记录对应的原始样本标号,排序后从第一个样本开始依次向下比对属性值,将满足邻域定义的其他样本记录在临时矩阵的两处位置(其一,对应第一个样本原始样本标号所在的行和其他样本原始样本标号所在的列;其二,将位置一中行和列对应临时矩阵的列和行的位置),直到不满足邻域定义,进入下一个样本,循环上述过程,直到最后一个样本处理结束,得到该属性下的临时邻域关系矩阵.步骤2的排序时间复杂度为O(|U|log(|U|)).假设论域样本的邻域平均对象数为q(q|U|),则步骤7-步骤20的时间复杂度为O(q),故步骤3-步骤21的时间复杂度为O(q|U|).因此,该算法的平均时间复杂度为O(|U|log(|U|)).
以邻域关系矩阵的属性相关性度量为基础,利用其粒化单调性,以算法1计算单属性下的邻域关系矩阵.进而可考虑条件属性的增加策略以构建启发式约简算法[18].为此,下面给出单条件属性重要度概念.
定义 12.NDIS=(U,C∪D,V,f,δ)中,对 BC,定义属性a∈C-B相对B关于D的基于邻域关系矩阵的属性相关性度量的属性重要度为:

基于mrB(D)的粒化单调递增性,(6)式刻画了单属性加入前后B与D相关度变化,由此可挑选出变化最大的属性,直到新属性加入时mrB(D)不再增加为止.因此,基于邻域关系矩阵的启发式约简算法可描述如下.
算法2.基于邻域关系矩阵的启发式约简算法(NRMAR)
输出:约简属性子集reduct.

算法2先算各属性的邻域关系矩阵.再依次加条件属性计算属性相关度,由属性重要度挑选属性到约简子集.重复直到重要度不再变化.其计算单属性邻域关系矩阵的复杂度为O(|C∪D||U|log(|U|)).步骤7按矩阵行并行计算,复杂度O(|

5 UCI数据集实验验证及分析
为验证NRMAR的有效性,我们先通过实验选取合理的邻域半径δ,再对NRMAR与NDEM的约简属性数量、质量和运行时间对比.如表1,实验从UCI机器学习数据库挑选6个数据集(3个连续型数据集Wine、Wdbc和Sonar,1个离散型数据集Tic,2个混合型数据集 Heart和 Thoraric).算法在MATLAB R2010b上实现.配置为:Intel(R)Core(TM)i5-2400、主频 3.10GHz、内存 2G、Windows 7.

表1 实验数据集的基本描述Table 1 Basic description of experiment data set
5.1 邻域半径选取分析
实验前要对连续属性数据归一化[19],它并不影响样本分布,只是消除不同取值的量级与量纲影响.假定采用最小-最大规范化,公式如下:

其中,f(xi,bj)为 xi在属性 bj下的取值,maxbj和 minbj为全部样本在属性bj下的最大和最小值.规范化后,xi在属性bj下的取值范围 f*(xi,bj)为[0,1].
由定义1,邻域信息粒生成的关键在邻域半径δ的选取.δ直接影响邻域信息粒中各个类的分布,从而影响着约简属性数量和约简属性子集质量.实验用表1的Wine、Heart和Thoraric确定 δ.δ∈[0,1],变化步长 0.01.δ对约简属性子集数量及分类准确率的影响如图2和图3所示.

图2 条件属性数量与δ取值关系Fig.2 Relationship of conditional attribute number and theδvalue

图3 分类准确率与δ取值关系Fig.3 Relationship of classification accuracy and theδvalue
图2 表明,用NRMAR约简时,不同δ对条件属性数影响明显.δ∈[0,0.1]及接近1 时属性数较少;δ∈[0.1,0.3]时属性数适中;δ∈[0.3,0.4]时属性数达到最大值并保持.
图3表明,NRMAR用于3个数据集时,约简后的属性子集在CART方法下的分类准确率与δ的取值变化关系.δ在0和1附近时准确率偏低;δ∈[0.05,0.15]时准确率较高,但Wine和Thoraric的分类准确率波动较大;δ∈[0.15,0.25]时准确率达到最大并保持.故δ的合理取值范围为[0.15,0.25].为使试验更客观,处理连续属性时取δ=0.15,否则δ=0.
5.2 约简属性子集数目与分类准确率
表1数据集在NRMAR和文[15]NDEM算法下的约简属性子集的结果如表2所示.

表2 NRMAR和NDEM算法下的约简属性子集Table 2 Subset of reduction attributes under NRMAR and NDEM
表2表明,算法能有效约简数据集.对连续型的Wine和Sonar,约简后的属性数明显减少,说明连续型数据集有大量冗余属性,其约简算法更加值得研究.两种算法对单个数据集的约简都有相同条件属性,但又不尽相同.差异源于约简算法的属性重要度差异.由此印证了基于邻域关系矩阵的属性相关性度量与文[15]的邻域决策误差率最小化准则度量的差异.对表2的约简质量,以CART分类[18]为准,以10次交叉验证算出分类准确率,结果如表3所示.

表3 基于CART分类器的分类准确率Table 3 Classification accuracies based on CART classification
表3表明,两种算法在连续型数据集Wine、Wdbc和Sonar上的约简属性子集属性数和分类准确度都较好.它源于:(1)数据采集的人为和仪器测量因素引起的误差,以及针对具体决策任务而言的属性冗余.(2)邻域关系是等价关系拓展来的相似关系,能一定程度上容忍数据误差,有效处理连续型数据集.其中,NRMAR比NDEM的结果更好.比如,Sonar的初始60个属性的准确率为71.15%,NRMAR选出5个属性的准确率为78.85%,而NDEM选出的11个属性的准确率为74.52%.它得益于NRMAR考虑了每个样本信息粒中各个类的均匀分布和融合其决策分布,强化了条件属性与决策属性间的相关性.另外,两种算法在离散型Tic上的优化不明显.原因是邻域关系退化成了等价关系,此时,样本邻域信息粒中各类分布因δ=0而不会发生改变.虽然表2中两种算法在Tic上的约简属性子集的属性及其被选顺序不尽相同,但最终准确率不低于初始准确率,表明两种算法都能直接有效处理离散型数据集.最后,对混合型Heart和Thoraric,算法结果都较好.其中 NRMAR比 NDEM 更优.比如,在 Heart上NRMAR只需6个属性即可达82.21%的准确率.两种算法对Thoraric约简优化效果不明显的主要原因是,Thoraric中的属性绝大部分是离散型.从均值看,约简后属性数都显著减少且准确率都有所提高,而NRMAR效果更好.
5.3 运行时间比较
将邻域关系间的集合运算转化为矩阵运算,同时,改进计算单属性邻域关系矩阵法及利用命题4中单属性与多属性的邻域关系矩阵,可得NRMAR时间复杂度为:

基于集合表示与运算的NDEM的时间复杂度为:

两种算法在6个数据集上的运行时间对比如图4所示.可见,NRMAR的用时更少,且与理论分析一致.
6 结论与展望
提出了基于邻域关系矩阵的属性约简算法(NRMAR),解决了NDEM无法准确反映各类分布均匀时的样本信息粒的决策信息问题.主要工作如下:
1)通过融合样本邻域信息粒与其决策分布提出了条件属性集与决策属性的相关性度量,用邻域关系矩阵表示邻域关系,并用基于邻域关系矩阵的属性相关性度量表示,证明了其粒化的单增性;
2)改进了单属性邻域关系矩阵计算方法,将时间复杂度控制在对数级,给出了单属性与多属性邻域关系矩阵的内在联系;
3)设计、实现了NRMAR算法,UCI数据集实验分析验证了NRMAR相比NDEM更能选择较少条件属性,且可保持或改善数据的分类能力.
NRMAR中的邻域半径直接影响着邻域信息粒中各个类的分布,从而影响属性约简的结果.下一步工作将考虑如何合理选择邻域半径.
猜你喜欢
农业工程学报(2022年7期)2022-07-09
中学生数理化(高中版.高一使用)(2021年9期)2021-12-02
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
逻辑学研究(2021年3期)2021-09-29
波谱学杂志(2021年3期)2021-09-07
计算机与生活(2021年8期)2021-08-07
计算机应用(2021年4期)2021-04-20
南京大学学报(数学半年刊)(2020年1期)2020-03-19
小型微型计算机系统(2019年10期)2019-11-11
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
