
基于栈式自编码器的制冷系统故障诊断
2019-08-28 06:58罗霄,孙俊
中国修船 2019年4期
罗 霄,孙 俊
(1.武汉理工大学 能源与动力工程学院,湖北 武汉 430063;2.国家水运安全中心,湖北 武汉 430063)
船舶制冷系统是船舶一个重要的辅助系统,故障诊断是保证其正常运行的重要手段之一。传统的故障诊断方法一般采用数据特征提取与机器学习模型分类相结合的形式。但设备运行数据呈现出高维度、高数量、高非线性等特点,传统智能诊断技术的诊断能力不足。基于深度学习的栈式自编码器(SAE)制冷系统的故障诊断方法比传统故障诊断方法在特征提取、泛化性、鲁棒性、精度方面存在明显的优势[1-4]。
1 栈式自编码器
SAE是由多个自编码器(AE)堆栈而成,训练SAE需先训练AE网络,图1为SAE网络结构示意图,虚线框内为一个AE网络结构示意图。
AE网络训练过程如下。
1)计算隐藏层输出。
Y=s(WX+b),
(1)
式中:Y为隐藏层矩阵;W为输入层与隐藏层之间的权值矩阵;X为输入矩阵;b为输入层与隐藏层之间的偏置向量;s为S型(sigmoid)函数。
2)计算输出层函数。
Z=s(W′Y+b′)=s(WTY+b′),
(2)
式中:Z为输出层矩阵;W′为隐藏层与输出层之间的权值矩阵;b′为隐藏层与输出层之间的偏置向量。
3)构造目标函数。
J(W,b,b′)=
(3)
式中:k为输入数据的样本数;xi为第i个样本的输入;zi为第i个样本的输出。使用梯度下降法求得J(W,b,b′)最小值。当J(W,b,b′)迭代到最小值时,停止AE网络训练。
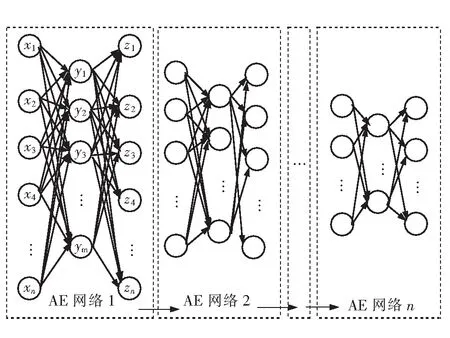
图1 SAE网络结构示意图
一个AE网络收敛后,只保留编码过程,隐藏层再与下个网络层组成AE网络进行训练,这就是通过贪婪训练算法来预训练SAE。预训练完成后,在输出层后加入一个softmax分类器,使之具备分类识别功能。最后使用有标签数据对SAE进行微调。SAE的微调过程,与普通BP神经网络训练过程无异。不同点在于SAE的参数初始值是经过预训练确定下来的值,不再是普通BP神经网络一样的随机数。SAE微调过程完成说明整个SAE训练过程完成。
2 基于SAE的故障诊断方法
基于SAE的制冷系统故障诊断流程见图2。
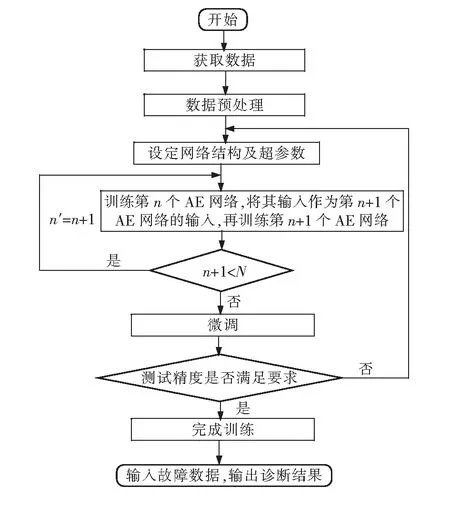
图2 故障诊断流程图
1)故障数据预处理。获取故障数据,对其进行归一化处理。
2)确定SAE的结构与超参数。通过研究分析网络层数、批尺寸(batch_size)、学习率对网络的影响,根据具体数据集选择合理的网络结构与超参数。
3)SAE的训练。先使用无标签数据预训练SAE,待网络收敛后,再使用含有故障标签的数据进行微调。网络再次收敛后,使用测试集中的故障数据测试网络性能,若故障精度无法满足要求,不断重复2)与3),直到测试精度满足要求为止。
4)利用SAE进行故障诊断。将未知故障的数据输入训练好的SAE中,输出诊断结果。
3 数据验证
3.1 实验数据
本次实验采用ASHRAE 1043-RP项目的制冷机组故障数据。实验对象是1台制冷量约为316 kW的制冷机组,分别模拟了冷却水流量不足、冷冻水流量不足、制冷剂泄漏、制冷剂过量、滑油过量、冷凝器结垢和制冷剂混入不凝性气体这7种故障率相对较高的单发渐变故障,并对每个故障进行了4个不同严重等级的划分。该系统共采集64个参数,其中48个参数由传感器直接得出,16个参数由VisSim软件实时计算得出。传感器参数包含29个温度参数,7个阀位参数,5个流量参数,5个压力参数,2个压缩机参数。
从ASHRAE 1043-RP项目的故障数据中,通过分层采样选取1组正常数据与7组单发故障数据,每组单发故障数据1 000个,共8 000个故障数据,并随机选取6 400个故障数据作为训练集,1 600个故障数据作为测试集。
3.2 数据预处理
在训练网络前,需要对输入数据进行归一化处理,这样可以消除不同属性不同量级的影响,保证最后故障诊断模型的稳定性、精确性与运行速度。因为故障(输出数据)互为独立事件,需对其进行独立编码处理,才能作为网络输出。
3.3 网络结构与超参数的选择与分析
3.3.1 网络深度的影响
先构建不同网络层数的SAE,每层网络神经元个数是从输入层的64个到输出层的8个呈等差数列排列,这里就将SAE的层数设置为3~9层,遍历训练集500次。不同网络层数的测试精度与训练时间如图3所示。
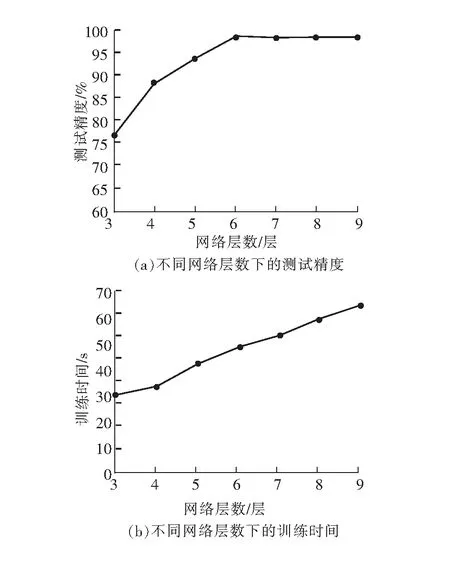
图3 不同网络层数的测试精度与训练时间
由图3可知,当网络层数从3增加到9时,测试精度从76.3%一直增加到98%左右,说明网络层数越深,网络越复杂,学习能力越强,越能学习到数据中深层次的特征信息。但网络层数从6增加到9时,测试精度却没有明显变化,说明对于该数据集,6层网络层的SAE已经可以学到足够多、足够深的特征信息。而3~9层网络层数的训练时间几乎呈正相关(从30.2 s一直增加到64.3 s),过深的网络只能无意义地增加训练时间。所以该SAE层数选择6层最为适宜。
3.3.2 不同batch_size的影响
使用梯度下降法进行一次参数更新,需要的训练样本数量最小可为1,最大为训练集的样本总数,实际采用的是折中的数量,这个数量便是batch_size。batch_size较小时,权值更新随机性强,但遍历一次训练集花费时间长,batch_size较大时,对电脑的配置有较高的要求,所以需要选择合适的batch_size。这里将batch_size分别设为32、64、128、256、512、1 028、2 560、5 120,每个网络遍历训练集500次。其测试精度与训练时间如图4所示。
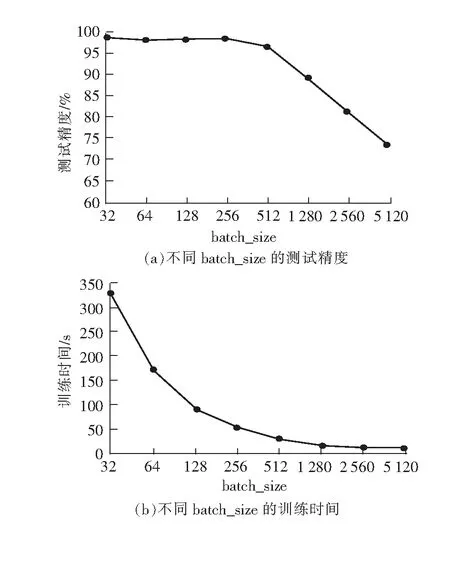
图4 不同batch_size的测试精度与训练时间
由图4可知,batch_size越小,测试精度越高,说明尽管batch_size较小时网络更新取值随机性强,但其权值更新次数高,大多数情况下网络同样能够收敛,batch_size较大时网络遍历一次训练集权值更新次数少,相同迭代次数下测试精度低,要达到相同的测试精度,需要更多的遍历次数,延长了训练时间。但随着batch_size减少,在相同遍历次数下网络训练时间几乎呈指数增长,也会延长训练时间,增加训练成本。综上所述,本次实验batch_size设为256最为合理。
3.3.3 不同学习率的影响
每一次网络参数更新幅度的大小叫做学习率,也叫做步长,是众多超参数中非常重要的一个。本次实验将学习率分别设为1、0.1、0.01、0.001、0.000 1、0.000 01,迭代次数为500次。这些网络的训练误差(cost值)与测试精度如图5所示。
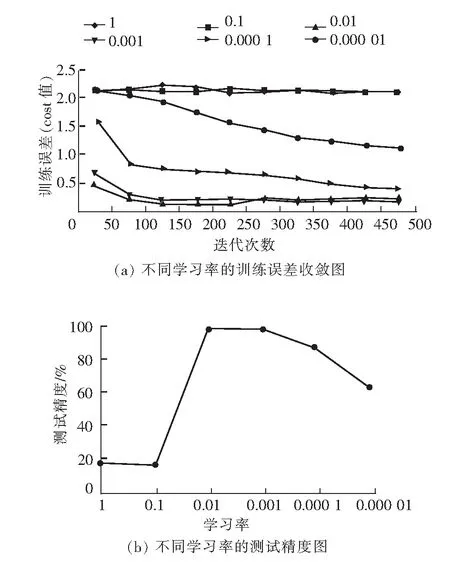
图5 不同学习率的训练误差收敛图与测试精度图
由图5知,当学习率为1和0.1时,cost值一直无法收敛,因为过大的学习率导致参数更新幅度过大,错过极小值的位置,即使更新到了极小值,也会由于幅度过大,跳出极小值位置,导致测试精度过低(17.5%左右),说明学习率为1和0.1对于该网络太大。当学习率为0.000 1与0.000 01时,cost值下降速度变慢,特别是学习率为0.000 01时,到了迭代结束时,cost值仍有下降趋势,测试精度也跟着下降,说明学习率过小,尽管网络会收敛,但收敛速度太慢,导致网络训练时间变长,增加训练的时间成本。当学习率为0.001时,cost值曲线下降迅速、平滑,最终测试精度理想(98%左右),所以学习率可以选择0.001。
3.4 与传统故障诊断方法对比
现将SAE与PCA+SVM、BP神经网络进行比较分析。PCA+SVM模型是先通过PCA模型对输入数据进行降维、特征提取,再通过SVM分类器,对数据进行故障识别,使用网格搜索法对SVM模型参数进行优化,使该模型尽可能达到最优性能。BP神经网络使用与SAE一样的网络结构,通过优化其他超参数,尽可能使BP神经网络达到最优性能。3种方法均使用同样的训练集与测试集,测试不同故障水平下的精度,如图6所示。
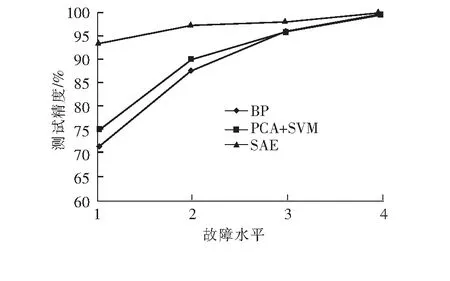
图6 不同方法在不同故障水平下的测试精度图
由图6可知,3种方法在故障水平4的情况下,都显示出优异的性能(测试精度在99%左右)。但在低故障水平下,SAE的测试精度要高于BP神经网络与PCA+SVM模型,在该情况下,许多参数与正常运行状态比较差别不大,PCA本质上是一种线性降维方法,与SAE的非线性降维相比,在提取更深层次的特征信息与处理非线性问题上显得不足。而BP神经网络虽然有足够复杂的网络结构去学习深层次的特征,但没有SAE的预训练过程,容易遇见梯度弥散问题,使得网络学习效率低下,无法达到理想的效果。SAE神经网络通过预训练的方式构造深层神经网络,自适应地提取特征信息,在故障诊断方面比传统故障诊断方法更具优势。
猜你喜欢
一重技术(2021年5期)2022-01-18
一重技术(2021年5期)2022-01-18
中学生数理化·八年级物理人教版(2019年9期)2019-11-25
中学生数理化·八年级物理人教版(2019年12期)2019-05-21
电子制作(2018年11期)2018-08-04
电子制作(2018年10期)2018-08-04
现代商贸工业(2017年23期)2017-09-13
北京航空航天大学学报(2016年6期)2016-11-16
物联网技术(2015年8期)2015-09-14
汽车电器(2014年5期)2014-02-28
