
基于交叉熵与困惑度的LDA-SVM主题研究
2019-09-12 10:41薛佳奇杨凡
智能计算机与应用 2019年4期
薛佳奇 杨凡


摘 要:目前对于中文影视剧本的分类主要借助人工经验,具有成本高、效率低等特点。当前没有针对中文影视剧本主题自动分类的相关研究,本文将对主题提取进行研究,传统主题生成模型借助于文档和段落、段落和语句、语句和词的相似性,而忽略了文本语句与语句之间的相似性。首先,采用ISOMAP方法降低样本集的向量空间维度;其次,提出交叉熵结合困惑度的算法模型,进而确定LDA需要提取的最优主题数目;最后,通过剧本-主题的方式,利用LDA算法挖掘剧本的隐含主题词,同时利用SVM对主题词做出进一步的分类。
关键词:中文影视剧本;ISOMAP降维;LDA;交叉熵;困惑度;SVM文章编号:2095-2163(2019)04-0045-06 中圖分类号:TP391.1 文献标志码:A
0 引 言
互联网上文本类型数据数量呈现指数式的激增,则使得当今社会各个方面对互联网数据挖掘方法的需求也越来越大[1-2]。与此同时,人们正更加倾向于随时随地浏览信息和观看影视作品,文学剧本的数量也开始急剧上升,也就必然给影视审核人员带来巨大的挑战,即剧审人员需要快速熟知海量剧本的主题。目前,自动化的剧本主题分析鲜有学者进行相关研究,本文即拟对影视剧本的主题词发现展开探讨与论述。
研究可知,剧本与文本同时存在维数过高的问题,因此需要采取降维方法。常见的降维方法有PCA降维和ISOMAP降维,其中PCA降维存在信息丢失问题,故而本文选用了ISOMAP降维方法。而研究中,将通过LDA来选取主题词,但考虑到LDA的参数K多会通过困惑度进行计算,本文则有针对性地提出了困惑度与交叉熵结合度的方法。文中对此可做研究分析如下。
1 主题提取相关研究
选择剧本主题特征词时,应选择能代表剧本类别的词作为特征,而在通过向量来表示剧本时,向量空间稀疏和高特征维数问题就是剧本提取特征词的研究热点。针对这一状况,通常需要进行特征降维,降维不仅能够缩减剧本的特征维数,减小模型训练时的迭代次数,也可以消除相似语义的特征,进而提高剧本主题分类的准确率、召回率和效率。相较于英文剧本,中文剧本有着更多的字词组合、更大的编码空间、更稀疏的原始特征空间,更高的矩阵维度等特点,为了获取高效的剧本特征降维方法,不影响剧本主题的分类性能,就需要选取适合于中文影视剧本的降维方法。这里可得研究内容分述如下。
1.1 PCA与ISOMAP降维
1.1.1 PCA降维
PCA[3]降维算法是为了去除剧本向量空间中相似的元素,消除维度灾难,从而得到有效的特征空间。PCA的计算过程详见如下。
在此基础上,计算协方差矩阵。协方差矩阵的第h行第g列的维度值的运算将用到如下计算公式:
将特征值按照从大到小排序,选出前K大个特征值。通常情况下,前K大特征值之和占总特征值之和的80%,即用前K个特征值来取代矩阵中的m个特征。第j个POI的Rank值公式具体如下:
1.1.2 ISOMAP降维
ISOMAP算法可以进行非线性降维,将高维空间中数据信息映射到低维空间,再通过特征提取方法获得提取后特征,该算法依据多维尺度变换(MDS),将数据点之间原来使用的欧几里得距离替换为测地线距离,保证降维后的数据信息损失最小,同时将高维空间有效映射到低维空间里,在减小计算量的基础上,提高运算速率。
ISOMAP算法引进了邻域图,距离很近的点可以用欧氏距离来代替,较远的点可通过最短路径算出距离,在此基础上进行降维保距。邻域图中相邻且靠近的点之间存在连接,而与之相反的便不存在连接,因此计算2个点之间的距离问题就是测地线距离计算问题,也即演变成了邻域图中2点之间的最短路径计算问题,最短路径的计算常采用经典Floyd算法或Dijkstra算法。
1.2 交叉熵与困惑度
1.2.1 交叉熵
在统计学中,利用困惑度评价模型的性能优劣,能够给测试数据得出更高概率值的算法显然更好[4],即困惑值越小,模型对实验的文本数据有更好的预测能力,因此困惑值与剧本潜在主题数量呈反比。在LDA主题模型中,困惑度计算公式可表示如下:
1.2.2 交叉熵结合困惑度方法
在计算主题相似度时,目前常用的方法有:Kullback-Leibler散度(KL散度)[5]、Jensen-Shanon散度(JS散度)[6]、交叉熵(Cross Entropy,CE)。其中,KL散度不满足对称性和三角不等式,JS散度也不能很好地衡量每个真实主题和预测的主题之间的相似性,因此本文选取交叉熵作为衡量剧本各个主题间相似度的标准。在交叉熵的基础上,将随机变量方差的概念引入到潜在主题空间中,即可衡量主题空间的整体差异性[7]。主题方差Var(T)是各个主题分别与其均值之间的距离平方和的平均数。主题方差的计算方法详述如下。
先计算求出主题-词概率分布均值-;再利用未曾应用于剧本主题的交叉熵来得到各个主题间的方差,数学公式可写作如下形式:
Var(T)可以计算得到隐藏主题之间的稳固性,Var(T)越大,稳固性越好,主题易于分类。困惑度可以用来作为模型预测能力评价指标,过分追求指标值会导致主题数偏大,因此可将二者相结合。由此提出如下的Perplexity-Var指标的公式:
Perplexity-Var指标含义是:从以上关系式分析得出,Perplexity-Var值最小时,则寻求的LDA主题模型为最优。
1.3 LDA主题模型
LDA模型可以提取出研究篇章中的隐含主题,通过主题、词频生成文档,因此属于生成模型。针对剧本,使用LDA模型可以生成主题,提取剧本的隐含语义并对剧本进行形式化的表示。假设剧本集D包含M篇剧本,每篇剧本的长度是Ni,在LDA模型中,LDA概率图模型如图1所示。完整的文档生成步骤参见如下。
图1中,M表示剧本数量,N表示单篇剧本中词的数量,K表示主题数量,W表示剧本集中的所有词,Z表示所有主题;参数θ表示文档-主题分布,由Dirichlet先验知识α控制产生;ψ表示主题-词分布,由Dirichlet先验知识β控制产生;矩形表示连续重复过程,外层矩形表示从Dirichlet分布中为剧本集D中的每篇剧本反复抽取主题分布,内层矩形表示从主题分布中反复抽样产生剧本d的词。
2 实验结果及分析
2.1 实验数据与处理
本文的数据来源于互联网资源,共计317篇外国剧本。该数据集是PDF格式,利用程序将PDF格式剧本文件转化为实验所需要的txt剧本格式,通过人工标注将317篇剧本分为20种类别,分别是爱情、传记、动作、犯罪、歌舞、记录、家庭、惊悚、剧情、科幻等。
首先,分词;然后,通过停用词表过滤掉剧本中的一些无关词,将剧本文字形式转化为TD-IDF的向量形式,使用TF-IDF算法;最后,将TF-IDF向量矩阵进行降维,降维后的TF-IDF作为LDA的输入参数。
2.2 基于ISOMAP的TF-IDF降维实验
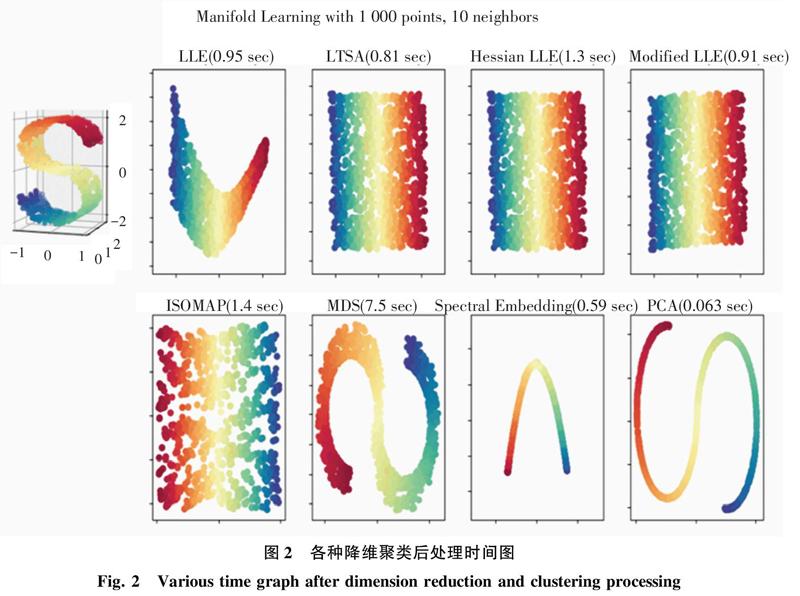
SVM模型中的输入是数据,因此本文可任选向量空间模型,权重采用TF-IDF权重值,但由于剧本转化为TF-IDF时维数达到了50万,超出了普通计算机的运算能力,故而仍需继续降维。而降维时,在保证信息损失最少的同时,同时还要保证可靠的计算效率。通过实验对比来观测PCA降维与ISOMAP降维的处理时间的对比,将高维数据降到2维,再聚类为10类,最终可得各种降维算法处理时间的结果对比如图2所示。
由图2可以看出,ISOMAP算法的处理时间要好于PCA算法,但是聚类效果明显优于PCA,如此就降低了信息的丢失率。故而,对于剧本特征降维,本文选择了ISOMAP算法。
通过实验得到4组数据,将得到的稀疏矩阵维数降为1 000维、3 000维、5 000维、10 000维。对这4组数据使用带有高斯核函数的SVM训练模型,并以训练语料测试分类准确率,研究得到的结果见表1。
PCA与ISOMAP降维对比结果曲线如图3所示。根据表1与图3的结果,当PCA与ISOMAP降到3 000维的时候,分类的准确率最高,同时可以证明,在剧本分类中,使用ISOMAP在特征降维方面要优于PCA降维,因此本实验中选取降维后的维数为3 000维。在图3中,PCA降维至5 000维之后,基本呈一条直线,考虑到PCA降维时可能造成大量信息损失,会使得分类准确率大致呈现线性下降趋势。
2.3 基于交叉熵与困惑度的最优主题数实验
研究中,根据困惑度、以及困惑度与交叉熵相结合的算法,并结合各种分类器进行对比实验,通过仿真来验证该算法的优越性。在进行对比实验时,将降维算法加以统一,LDA主题个数寻优实验选择PCA降维,同样,选择TF-IDF特征向量加权算法;SVM的核函数,选择高斯核函数。定义困惑度计算得到的主题数为Perp_K,定义困惑度和交叉熵相结合的主题数量为PerpSimla_K,通过本文提出的交叉熵与困惑度计算公式分别得到最优主题个数,Perp_K=200,PerpSimla_K=230。不同主题数的分类器的准确率见表2。
由表2得到的结果数据显示,利用交叉熵与困惑度结合的方法,使得各个分类器的分类准确率明显高于单独使用困惑度方法,困惑度计算可以为主题数量的确定提供有效参考,但并未能够保障构造得到最优分类器。因此需要进一步的仿真研究验证最优主题数是否准确且有效,需要将LDA的主题個数K值范围设置在经验数值50~450之间。交叉熵和困惑度结合下的不同主题数的对比结果值如图4所示。
由图4与表2可以得知,基于困惑度与交叉熵结合的方法,得到的最优主题数明显优于单纯基于困惑度计算剧本最优主题数。在接下来的部分实验中将会采用此方法,进行LDA主题提取。
2.4 LDA隐含主题特征词提取
一个主题下有大量相近的词,一个词也会依附于不同的主题,这些词语和该主题有很强的相关性,也正是这些词语共同定义了这一主题。对于一篇剧本来说,通常是由若干个主题生成。综上分析可知,LDA主题模型,能够发现隐含的主题。对降维过后的数据,进行LDA主题提取,以确保更低的维数,进而提取更准确的特征,后续即以LDA提取的特征作为SVM的输入。
由于剧本数量多,因此采用了stem图(火彩梗图)。此处,显示了前3篇剧本的可能的主题词的概率大小。运行结果如图5所示。
2.5 实验结果分析
由前文的实验部分确定了LDA的K值,紧接着将提取的特征向量,输入到各类分类器中,用来验证融合核函数对于剧本主题分类的优越性。
本节将从KNN、贝叶斯以及向量机分类器进行对比实验。在python环境里,SVM的模型参数可以选择自定义的核函数。各类分类器对比实验结果见表3。
由表3可以看出,线性核的准确率逼近融合核,验证了从低维映射到高维线性可分的理论,而且由于使用了ISOMAP降维方法以及LDA,使得特征空间基本处于线性可分的状态。同时表3给出的实验结果还验证了,相比其它核函数和分类器而言,SVM核函数对剧本及其它文本分类能够获得更好的研究效果。
3 结束语
本文首先将剧本集向量化,得到向量空间;传统的文本向量空间,通常是利用词频作为分析的依据。而剧本向量空间,采用TF-IDF算法得到词语加权向量空间。对比了PCA与ISOMAP降维效果,通过实验发现PCA与ISOMAP相比有着更快的执行速率,而ISOMAP有着更好的降维效果,因此在更大程度上有效提升了剧本主题的分类准确率。提出交叉熵结合困惑度的方法,通过实验表明,提出的交叉熵结合困惑度的方法,可以显著改善剧本主题词的个数不准确问题,进而提高剧本主题分类准确率。本文不足之处在于,没有对SVM核函数做进一步的实验研究,未来工作将是利用核函数融合进行深入的探讨与分析。
参考文献
[1] WU Xindong, ZHU Xingquan, WU Gongqing, et al. Data mining with big data[J]. IEEE Transactions on Knowledge and Data Engineering,2014,26(1):97-107.
[2]LAZER D,KENNEDY R, KING G, et al. The parable of Google Flu:Traps in big data analysis[J]. Science,2014,343(6176):1203-1205.
[3]刘海旭. 基于PCA和LDA的文本分类系统设计与实现[D]. 北京:北京邮电大学,2013.
[4]裘友荣. 相对熵在图像去噪中的应用[J]. 遥感信息, 2018, 33(3):124-129.
[5]孔锐, 施泽生, 郭立, 等. 利用组合核函数提高核主分量分析的性能[J]. 中国图象图形学报, 2004, 9(1):40-45.
[6]牟华英. 脑电信号特征提取的算法研究[D]. 广州:华南理工大学, 2010.
[7]李强. 基于主题模型的中文情感分类方法研究[D]. 杭州:杭州电子科技大学,2016.
[8]田象明. 基于视频流的车牌识别系统设计[D]. 西安:西安电子科技大学, 2017.
猜你喜欢
电子产品世界(2022年4期)2022-04-21
初中生世界·八年级(2019年6期)2019-08-13
软件导刊(2017年4期)2017-06-20
高中生学习·高三版(2017年6期)2017-06-12
博览群书·教育(2016年9期)2016-12-12
小学生导刊(低年级)(2016年9期)2016-10-13
小学生导刊(低年级)(2016年6期)2016-07-02
科技视界(2016年16期)2016-06-29
小学生导刊(低年级)(2016年4期)2016-04-12
卷宗(2014年10期)2014-11-19
