
基于音视频分析的区域安防管控平台
2019-10-21 09:21蔡烜蒋龙泉冯瑞
微型电脑应用 2019年6期
蔡烜 蒋龙泉 冯瑞

摘 要: 针对广场等区域人流量大、安保要求高的特点,设计并实现了一套基于音视频识别的区域安防管控平台。该平台从区域安防的需求出发,设计了嫌疑人员报警、人群拥挤报警和异常声音报警三大功能,以人脸识别、人群密度估计、异常声音识别三个音视频识别算法作为支撑,实现对区域内与人相关的异常事件的预警。首先介绍了基于深度神经网络的人脸识别算法,然后介绍了一种引入注意力机制的卷积神经网络模型来实现的人群密度估计算法,和一种基于多卷积神经网络模型融合的异常声音识别算法;最后介绍了平台需求与设计过程,主要包括平台建设的需求分析和界面设计。
关键词: 视频分析;音频分类;深度学习;人脸识别;人群密度估计;异常声音识别;区域安防管控;
中图分类号: TP311
文献标志碼: A
文章编号:1007-757X(2019)06-0017-04
Abstract: We design and complete a regional security control platform based on audio and video recognition in order to protect people in the area from dangerous situation. The platform is designed three functions: suspect alarm, crowd crowding alarm and abnormal voice alarm. It uses face recognition, crowd density estimation and abnormal voice recognition as the support to realize the early warning of abnormal events in the region. Firstly, it introduces the face recognition algorithm based on deep neural network, then a convolutional neural network model with attention mechanism is introduced to realize the population density estimation algorithm. Finally, it introduces an abnormal voice recognition algorithm based on multi-convolutional neural network model fusion. At last it introduces the platform requirements and design process, including the platform construction requirement analysis and interface design.
Key words: Video analysis; Audio classification; Deep learning; Crowd density estimation; Abnormal voice recognition; Regional security management
0 引言
近年来,我国经济保持高速发展,城镇化率不断提高,城镇人口增多,广场、景区、高铁站等人流量大的区域成为城市安全的重点管控区域,这些区域人员流动性大,人员身份难确认,存在各种安全隐患和威胁,现有传统视频监控手段还比较落后,监控中心无法实现实时视频全覆盖,单纯依靠人力无法及时发现区域内的风险和隐患,只能通过视频回放进行事后追查已经不符合新时期安防工作的需要。
与此同时,科技领域中音视频识别技术不断提升,如人脸识别技术、音频识别技术等,这些技术已逐步在各行各业中开始应用,在推动科技进步和经济发展同时,为安防管控新增了强有力的技术手段,区域安防管控平台也可以利用这些新技术手段提升管理水平。随着大数据、人工智能等技术的推广应用,安防管控平台的构建采用智能音视频分析手段已经成为一个必然趋势。
1 平台框架
平台架构一共分为三层,由下至上分别为算法层、应用层和平台层,如图1所示。
分层架构的优势是使各层之间相互独立,通过统一的接口进行通信,每层内部各个部分按功能模块相互独立,使其具有良好的可扩展性。
算法层由人脸识别算法、人群密度估计算法和异常声音识别算法构成;人脸识别算法和人群密度估计算法的输入为视频或图像,异常声音识别算法的输入为音频;人脸识别算法的输出为视频图像中的人脸与人脸库中的人脸的相似程度,人群密度估计算法的输出是单位面积下人的数量,异常声音识别的输出是音频段落中是否包括某个种类的音频;各算法相互独立,可扩展性强。
应用层通过与算法层的数据通信,获得算法的计算结果,并结合实际应用的业务逻辑,生成相应的结果和数据;其中嫌疑人员报警模块生成是否发现嫌疑人和发现哪位嫌疑人的信息,人群拥挤报警模块生成某区域人群密度数据以及是否超过警戒值的信息,异常声音报警模块则是生成音频中是否包含爆炸、尖叫等异常声音的信息;应用层将这些报警信息上报给平台层。
平台层主要完成人机交互、数据可视化和调度指挥的功能,将应用层上报的报警信息进行直观展示,并结合声光电的方式进行更明显的提示。平台及时响应,调用人力采用应急措施,将风险和威胁扼杀在萌芽阶段。
2 人脸识别
人脸识别属于生物特征识别的一种,主要用于人身份的识别;相比于指纹识别和虹膜识别,它具有易获得性,可以在被识别人无感的情况下进行识别,对于区域安防管控工作的开展具有明显的优势;计算机通过人脸识别算法对人脸图像进行特征提取,然后将两张或多张人脸的特征进行比对,判断该人脸是否与人脸库中的某个人脸相似,最终确认人员的身份。
2.1 算法步骤
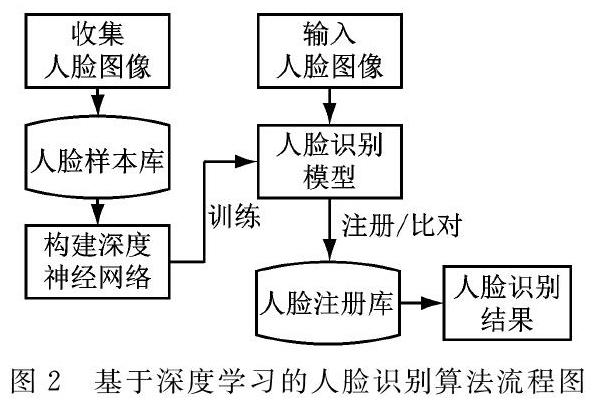
算法流程图如下如图2所示。
首先需要采集大量人脸的样本图像用于训练人脸特征,采集时要求按每个人进行分类归纳,每个人需要采集不同时期、不同角度、不同光照环境等情况下的多张照片,保证样本的数量和多样性,是训练一个优秀的分类识别模型的基本保障;然后对人脸进行特征提取:包括全局、人眼、鼻、嘴等多个特征点,然后得到训练样本的特征集合;最后使用样本图像的特征集合训练人脸识别的分类器。
识别比对时,算法将提取待识别的人脸图像的特征,获取到人脸图像的特征向量后,使用离线学习训练好的分类器进行特征比对,并将比对结果进行输出,从而得到人脸识别的结果。
2.2 算法结果
基于深度学习的人脸识别算法在效果上有两方面提升,一方面,算法不再采用传统已知人脸特征,由深度神经网络训练抽象特征,深度学习得到的特征表达具有人工设计特征表达不具备的重要特性;另一方面,深度学习网络中卷积层中滤波器的分辨率更小,使网络能够具备更精细的细节特征刻画能力。基于以上两点,使用基于深度学习的人脸识别算法在室外自然光线条件下具有更好的效果,更好的应用于区域安防管控平台。
3 人群密度估计
人群密度估计的主要任务是:人群场景的视频中的图像帧或拍摄的图片,计算单位面积内人群的密度,再将单位面积人群密度累加,得到整体场景的人群密度,连续的视频帧的人群密度即反映场景中的人群密度变化。
本文采用一种引入注意力机制的卷积神经网络模型,用以实现结构简单、训练消耗少的人群密度方法。
3.1 算法流程
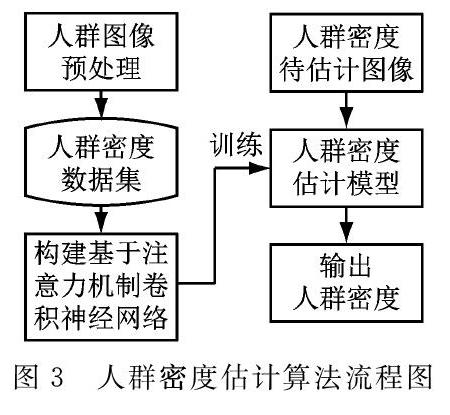
算法流程如图3所示。
a.将图像进行预处理获得预处理图像;预处理的操作包括图像分割及将分割的图像进行正则化;
b.构建基于注意力机制的卷积神经网络模型;
c.将多张已标注人群密度的图像组成训练集,将数据集输入步骤b中搭建的基于注意力机制的卷积神经网络模型,进行模型训练;
d.将待计算人群密度的图像输入步骤c中训练的基于注意力机制的卷积神经网络模型,计算得到该图像中的人群密度结果并进行输出。
3.2 算法结果
本文采用的通过引入注意力机制的卷积神经网络模型实现的人群密度估计算法,该模型的注意力机制可以使模型更好的定位到人群和识别人群的密度,因此,此模型能够学习到更多的特征,更好地进行特征表达,也更加适合高密度人群的人群密度估计任务,在高密度人群中的平均误差率只有10%左右;此外,该模型结构简单,不需要使用模型混合、多任务训练以及度量学习等方法,也提高了模型训练的效率。
4 异常声音识别
异常声音识别本质上是音频分类;随着近几年深度学习的发展和硬件性能的高速提升,音频分类作为计算机听觉领域一项基础的任务,其精度也得到了大幅提升。
视频图像一般受图像质量、光线等因素的影响,而声音是全向传播的,受影响的因素较小,所以异常声音识别能为安防工作提供听觉维度的异常预警。本文采用一种基于多卷积神经网络模型融合的异常声音识别方法,实现针对枪声、爆炸声、尖叫声三类异常声音的检测和分类。
4.1 算法流程
算法流程如如图4所示。
a.读入音频文件并进行分段处理,本文分为每2秒一段;
b.搭建多个深度卷积神经网络,包括但不限于如:ResNet-101、VGG16,Resnext;
c.将步骤a中完成分段的音频进行预处理,然后通过步骤b中的多个深度卷积神经网络分别提取音频特征;
d.把提取的训练集的音频段落的特征输入到步骤b中的多个卷积神经网络模型进行模型训练;
e.根据验证集使用不同网络模型进行识别的准确率,设定该模型的权值;
f.将需要识别的音频同样进行预处理然后输入步骤d中训练完成的卷积神经网络模型,综合步骤e各模型的权值计算,得到多模型联合预测的类别结果。
4.2 算法结果
在国际通用音频数据集UrbanSound、FreeSound中整理了包括枪声、爆炸声、尖叫声、啼哭声和玻璃破碎声共5类音频数据,采用上述的基于多卷积神经网络模型融合的异常声音识别方法进行识别。
从表1的算法效果可以看出,相较于传统的计算机听觉方法,本文采用的基于多卷积神经网络模型融合的异常声音识别方法大幅提升了音频分类的准确率,使区域安防管控平台的异常声音报警模块有了良好的准确率保证。
5 平台设计
從第1章中的平台架构图中可以看出,平台需要完成的主要任务是:人机交互、数据可视化和调度指挥。音视频识别算法将前端监控系统获取的音视频数据识别分析生成相应音视频文件的人员身份、人群密度或异常声音的结果,通过功能层编辑整理为实际业务数据,传输至平台进行直观呈现和交互。
5.1 需求分析
需求用例图如图5所示,需求点如下:
a.监控中心的值班人员通过平台能实时获取到报警信息;
b.报警信息呈现需准确显示报警出现的地理位置信息;
c.报警信息呈现需显示现场的视频图像或音频数据;
d.管理人员通过平台能进行嫌疑人员人脸数据的管理;
e.平台支持报警记录的查询。
5.2 界面设计
界面设计如图6所示。
其中报警信息的呈现采用弹窗和列表的方式进行信息提示,界面的中心部分是管控区域的GIS地图,地图中的弹窗位置对应报警信息的地理位置信息,报警信息弹窗中显示报警现场的视频图像或音频数据,报警记录查询的结果页通过列表显示,管理人员通过将嫌疑人员的人脸图像在平台中进行注册和删除来实现嫌疑人员管理;此外,平台还应该提供方便的接口实现应急响应,如平台与前端警务设备通过接口进行数据传输。
6 总结
文章通过人脸识别、人群密度估计和异常声音识别三个音视频识别算法的实现和应用,构建基于音视频识别的区域安防管控平台的应用功能模块,主要解决实际安防工作中监控手段单一、科技应用匮乏以及缺乏事前预警等问题;并对平台部分进行了需求分析和界面设计,平台具有良好的人机交互效果,并将算法结果进行数据可视化,让监控中心更好的进行调度指挥。但实际安防工作中业务更多、场景更复杂,安防管控平台需接入更多的功能模块,本文的设计范围和考虑因素还比较窄,实际工作中的设计和实现需要具有更高的集成度和统一调度指挥的业务逻辑。
参考文献
[1] 邹国锋,傅桂霞,李海涛等. 多姿态人脸识别综述[J].模式识别与人工智能,2015,28(7):613-625.
[2] 丁莲静,刘光帅,李旭瑞,等. 加权信息熵与增强局部二值模式结合的人脸识别[J].计算机应用,2019(4):1-8.
[3] Arun Kumar Dubey,Vanita Jain.A review of face recognition methods using deep learning network[J].Journal of Information and Optimization Sciences,2019,40(2):547-558.
[4] Sugiura, Motoaki,Miyauchi, Carlos Makoto,Kotozaki, Yuka, et al.Neural Mechanism for Mirrored Self-face Recognition[J].Cerebral cortex,2015,25(9):2806-2814.
[5] Hao-xiang Zhang,Peng An,De-xin Zhang.Application of robust face recognition in video surveillance systems[J].Optoelectronics letters,2018,14(2):152-155.
[6] Youmei Zhang, Chunluan Zhou, Faliang Chang, Alex C. Kot. Multi-resolution attention convolutional neural network for crowd counting[J]. Neurocomputing,2019, Volume 329:144-152.
[7] Luo H, Sang J, Wu W, et al. A High-Density Crowd Counting Method Based on Convolutional Feature Fusion[J]. Applied Sciences, 2018, 8(12):2367.
[11] Gunduz A E,Temozel T T,Temizel A.Density estimation in crowd videos[C].//2014 22nd Signal Processing and Communications Applications Conference: 2014 22nd Signal Processing and Communications Applications Conference (SIU2014), 23 – 25 April 2014, Trabzon, Turkey.2014:822-825.
[12] 曹金梦,倪蓉蓉,杨彪.基于多尺度多任务卷积神经网络的人群计数[J].计算机应用,2019,39(1):199-204.
[13] Brian M F, Justin S, Pablo B J. Adaptive Pooling Operators for Weakly Labeled Sound Event Detection[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2018, 26(11):2180-2193.
[14] 王开武. 基于深度神经网络的异常声音事件检测[D].重庆:重庆大学,2018.
[15] 吴晓东.智能视频监控技术在智慧城市中的深入应用[J].设备管理与维修,2019(6):150-152.
[16] 董炜.智能视频分析技术在智慧安防中的应用与展望[J].电子技术与软件工程,2019(7):251-252.
[17] 任龙刚,王伟,刘峰,等.基于平安校园建设的高校安全管理体系构建——以西安歐亚学院为例[J].安全,2019,40(3):68-71.
[18] 黄凯奇,陈晓棠,康运锋,等.智能视频监控技术综述[J].计算机学报,2015,38(6):1093-1118.
(收稿日期: 2019.05.01)
猜你喜欢
文萃报·周五版(2021年17期)2021-05-31
中国计算机报(2020年13期)2020-04-26
作文周刊(中考版)(2020年32期)2020-01-22
通信产业报(2018年10期)2018-04-13
小康(2017年28期)2017-10-13
江苏教育·中学教学版(2016年11期)2016-12-21
现代情报(2016年10期)2016-12-15
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
软件导刊(2016年9期)2016-11-07
