
基于云自适应粒子群优化算法和随机森林回归(CAPSO-RFR)的负载均衡预测
2019-10-23 11:23李雨泰李伟良尚智婕王洋董希杰
微型电脑应用 2019年10期
李雨泰, 李伟良, 尚智婕, 王洋, 董希杰
(国家电网有限公司 信息通信分公司, 北京 100761)
0 引言
云计算资源负载均衡预测的预测精度直接影响云计算系统的服务质量、安全性和经济性,其是云计算系统平台规划的重要构成部分[1]。根据历史负载数据,建立云计算资源负载之间的定量关系,从而实现云计算资源负载的预测,为云计算资源的规划、调度以及云计算平台的性能优化提供决策依据。由于云计算数据量的几何级数倍增以及其复杂性和非线性,传统的ARMA模型、ARIMA模型和FARIMA模型[2]已经无法保证云计算资源负载预测的精度。神经网络虽然适合非线性资源负载预测,但其预测精度易受其权值和阈值的影响,存在收敛速度慢和局部最优的问题。支持向量机[3]虽然适合短期资源负载预测,但其预测结果易受其参数选择的影响。随机森林[4](Random Forest,RF)是将随机子空间和Bagging集成学习理论结合提出的一种机器学习方法,其具有预测精度高、收敛速度快、稳健性好和调节参数少的优点。文献[5]为解决大部分虚拟机上任务不均衡和等待时间过长的问题,选择虚拟机的CPU和内存等资源的利用率为目标函数,提出一种基于粒子群算法优化随机森林的用于解决负载均衡问题。研究结果表明,PSO-RFR算法可以有效解决负载均衡问题,提高虚拟机的CPU和内存的资源利用率。针对其预测结果易受森林中树的数量Ntree、候选特征子集Mtry和叶节点的样本数Nodesize等参数影响,提出一种云自适应粒子群算法(cloud adaptive particle swarm optimization, CAPSO)优化RF参数的负载均衡高精度预测方法,并实现RF算法参数的自适应选择。
1 随机森林回归
随机森林回归[6](Random Forest Regression,RFR)算法是基于决策树分类器的组合算法,其利用bootstrap重抽样方法从原始样本中抽取多个样本,对每个bootstrap样本构建决策树,然后将所有决策树中出现最多的投票结果最为最终预测结果。假设随机参数向量θ对应的决策树为T(θ),其叶节点表示为l(x,θ),RFR算法步骤如下:
Step1:利用bootstrap方法重采样,随机产生k个训练集θ1,θ2,…,θk;利用每个训练集生成对应的决策树集{T(x,θ1)},{T(x,θ2)},…,{T(x,θk)};
Step2:假设特征有M维,从M维特征中随机抽取m个特征作为当前节点的分裂特征集,并以m个特征中最好的分裂方式对该节点进行分裂;
Step3:每个决策树均得到最大限度的生长,在此过程中不进行剪枝;
Step4:对于新的数据,单棵决策树T(θ)的预测可以通过叶节点l(x,θ)的观测值取平均获得,其中权重向量为wi(x,θ);

(1)
Step6:运用公式(7)通过对决策树权重wi(x,θt)(t=1,2,…,k)取平均得到每个观测值Yi(i=1,2,…,n)的权重wi(x)如式(2)、式(3)。
(2)
(3)
2 云自适应粒子群优化算法
粒子群优化(particle swarm optimization, PSO)算法是受鸟群觅食行为启发的研究,其算法更新式如下[7-8]如式(4)、式(5)。
(4)
(5)

更新公式中的w和c1,c2均为常数,寻优过程中,所有粒子的移动方向趋于一致性,使得粒子群体慢慢失去多样性,导致算法容易陷入局部最优和“早熟”问题。为了提高PSO算法的收敛速度和寻优精度,将云模型[10]的随机倾向性和稳定性引入PSO算法,提出云自适应粒子群优化算法,通过云算子对PSO算法的惯性权重w进行自适应改进,云算子的稳定性可以保证全局最优值,而随机性可以避免PSO算法陷入局部极值,云算子的调整方法可以详细描述如下:

(6)
(7)
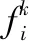
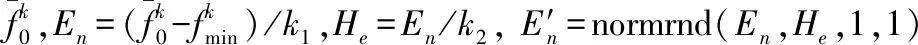
(8)
(9)
式中,k1,k2为控制系数。第k代惯性权重wk计算式为[11]式(10)。
(10)
式中,wmin,wmax分别为惯性权重w的最小值和最大值。
3 基于CAPSO-RFR的负载均衡预测
针对RFR预测结果易受森林中树的数量Ntree、候选特征子集Mtry和叶节点的样本数Nodesize等参数影响[12],在保证云计算资源负载预测误差最小情况下,实现森林中树的数量Ntree、候选特征子集Mtry和叶节点的样本数Nodesize等参数的自适应选择,其适应度函数如式(11)。
(11)
式中,Yi为第i样本点负载实际值,Xi为第i样本点负载预测值。基于CAPSO-RFR的云计算资源负载预测算法如下:
Step1:归一化云计算资源负载数据,并将数据划分为训练样本和测试样本,训练样本用于RFR模型的建立,而测试样本则用于验证RFR模型的效果;
Step2:CAPSO算法参数初始化:种群的规模N,最大迭代次数Tmax,学习因子c1和c2,惯性权重w,控制系数k1、k2;森林中树的数量Ntree、候选特征子集Mtry和叶节点的样本数Nodesize参数范围的初始化;
Step3:初始化粒子的位置和速度:输入训练样本,根据适应度函数(11)计算每个粒子的适应度;
Step4:更新粒子的速度和位置;
Step5:计算适应度并更新粒子的速度和位置;
Step6:判定CPSO算法终止条件,若满足则输出最优解;反之,执行Step3;
Step7:输出RFR模型的最优参数:森林中树的数量Ntree、候选特征子集Mtry和叶节点的样本数Nodesize,并将这三个最优参数用于云计算资源负载的预测。
4 实证分析
4.1 数据来源
为了验证CAPSO_RFR进行云计算资源负载预测的有效性,选择2018年7月16日-2018年7月26日11天的广东某运营商云计算平台提供的历史云计算资源负载数据为研究对象[13-14],其中每天每间隔1小时采集一点云计算资源负载数据,一共采集264组云计算资源负载数据,云计算资源负载数据如图1所示。

图1 云计算资源负载数据
4.2 评价指标
为评价云计算资源负载的预测结果,选择MAE、RMSE和nRMSE作为云计算资源负载预测的评价指标[15-16]如式(10)—式(12)。
(10)
(11)
(12)
4.3 结果分析
为了证明本文算法CAPSO-RFR进行云计算资源负载预测的优越性,将其与PSO-RFR、和RFR进行对比,对比结果如图2和图3以及表1所示。

图2 对比结果

图3 预测绝对误差

方法RMSEMAEn RMSECAPSO-RFR0.30940.18442.2032%PSO-RFR0.37340.24204.8478%RFR0.81260.62657.3074%
结合图2和图3以及表1不同算法进行云计算资源负载预测结果可知,在RMSE、MAE和nRMSE三个评价指标上,与RFR和PSO-RFR相比较,CAPSO-RFR具有更高的预测精度;其次,PSO-RFR的预测精度优于RFR;最后,RFR的预测精度最差,RMSE、MAE和nRMSE分别比CAPSO-RFR低0.5032、0.4421和5.1042%,通过对比可知,本文提出的算法CAPSO-RFR可以有效提高云计算资源负载预测的精度,同时实现RFR参数的自适应选择,为云计算资源负载预测预测提供新的方法和途径。
5 结论
针对传统的云计算资源负载预测算法存在精度低和误差大的缺点,提出一种基于CAPSO -RFR的云计算资源负载预测算法。在RMSE、MAE和nRMSE三个评价指标上,与RFR和PSO-RFR相比较,CAPSO-RFR具有更高的预测精度。研究结果表明,本文提出的算法CAPSO-RFR可以有效提高云计算资源负载预测的精度,为云计算资源的规划、调度以及云计算平台的性能优化提供决策依据。
猜你喜欢
电子科技大学学报(2022年4期)2022-07-15
湖南林业科技(2021年3期)2021-12-02
甘蔗糖业(2021年5期)2021-11-21
甘蔗糖业(2021年4期)2021-09-26
数码世界(2020年4期)2020-06-18
科学与财富(2020年6期)2020-05-19
科学与信息化(2019年28期)2019-10-21
科技与创新(2017年11期)2017-07-01
科学与财富(2016年32期)2017-03-04
软件(2016年5期)2016-08-30
