
一种快速全局中心模糊聚类方法
2019-10-30 02:14孙冬璞谭洁琼
哈尔滨理工大学学报 2019年4期
孙冬璞 谭洁琼

摘 要:针对模糊C均值算法对初始中心敏感、容易陷入局部最优解,且算法迭代速度慢等问题,依据模糊聚类的全局中心理论,建立了一种快速全局中心模糊聚类系统模型,并给出了相关理论分析和算法流程。该模型通过DKC值方案对各数据成员进行密集度分析来确定初始质心,并结合AM度量提出自定义寻优函数,依据该函数在算法运行的每一个阶段来逐一动态增加聚类中心,直至算法收敛。通过实验对比和验证,该过程降低了随机选取聚类中心对聚类结果的影响,跳出局部最优解,减少计算量,具有更高的聚类精度和更快的收敛速度。
关键词:模糊聚类;全局中心;DKC;AM度量;噪声点
DOI:10.15938/j.jhust.2019.04.019
中图分类号: TP311
文献标志码: A
文章编号: 1007-2683(2019)04-0110-08
Abstract:In terms of the problems that the fuzzy C-means algorithm is sensitive to the initial center, easy to fall into the local optimal solution, and the algorithm iteration speed is slow, a rapid global center fuzzy clustering system model is established according to the global center theory of fuzzy clustering, and the relevant theoretical analysis and algorithm process is given. In the model, the initial centroid is determined by the DKC value scheme, and the self-defined optimization function is proposed based on the AM metric. According to this function, the cluster centers are dynamically added one by one to every stage of algorithm operation until the algorithm converges. Through experimental comparison and verification, the process reduces the influence of random selection of cluster centers on clustering results, and jumps out of local optimal solution, reduces computation, and has higher clustering accuracy and faster convergence speed.
Keywords:fuzzy clustering; global center; DKC; AM metric; noise point
0 引 言
模糊C均值聚類[1-2](fuzzy C means clustering,FCM)是众多模糊聚类的代表,在传统的硬聚类算法中,每一个数据成员只隶属于一个类别[3],但在真实世界的数据集中,各成员对各自属于哪一类往往没有明显的界限。而FCM算法在执行过程中,根据不同的隶属度值,每个数据成员可以按照一定概率属于多个类别,FCM通过迭代式爬山算法来寻找问题的最优解。然而,该算法具有一定的局限性,比如,对初始条件较为敏感[4],容易陷入局部最优,易受噪声点影响,且聚类数目难以确定,算法执行速度慢等缺陷[5-6]。为此,国内外学者做了大量研究。有通过模拟自然进化过程的搜索最优解的方法,将遗传算法引入模糊聚类[7-8],避免算法陷入局部最优解,但仍存在局部搜索能力较弱、容易陷入“早熟”等缺点。也有将模拟退火算法与FCM相结合,使算法具有较强的局部搜索能力[9],但模拟退火算法本身对全局搜索空间了解不多,运算效率不高。文献[10]提出了一种非噪声敏感性FCM算法(INFCM),取消了对隶属度的限制条件,构建出一种增加了惩罚因子的目标方程,具有较好的鲁棒性,但算法依然不能保证跳出局部极小值、取得全局最优解。文[11]提出了快速全局FCM聚类算法,虽然该方法在很多方面弥补了FCM算法的不足,改善了算法性能,但仍容易受噪声点或孤立点的影响,且聚类精度低、速度慢等问题依然存在。
针对以上分析,本文提出将动态规划的全局思想和改进聚类中心点选取方法结合,在动态增加聚类划分并选取最佳聚类中心的过程中,通过计算所有数据对象的DKC值[12]确定样本分布密集区域且排除稀疏区域,降低外围孤立点的影响。同时,本文采用AM度量[13]来提高算法稳定性,并通过DKC值和AM度量所确定的自定义寻优函数寻找一个周围数据对象点分布比较密集且距离当前已有聚类中心都比较远的数据对象点作为下一个簇的最佳聚类初始中心,该函数综合AM度量和DKC值两者优势,更能快速且准确的确定出最佳聚类中心,加快算法收敛速度。
1 相关工作
FCM聚类算法是一种基于目标函数优化的无监督数据聚类方法,即一个反复更新聚类中心及隶属度从而使目标函数J最小化的过程,其工作原理是:随机初始化c个数据对象作为初始聚类中心,分别计算剩余对象与该c个成员的欧氏距离,再根据距离值将所有对象按照一定概率依次分配给最近的聚类中心,得到隶属度矩阵,分别计算新的类内成员平均值,再次更新聚类中心。将以上过程不断重复至算法收敛,则聚类过程结束[14]。
FCM算法虽然应用广泛、灵敏,却存在对初始值敏感、易陷入局部最优的问题,为此,模糊聚类的全局思想应运而生。
全局模糊聚类算法不再随机地为所有簇分别选取初始聚类中心,而是从一个簇的聚类问题开始,在算法每一次迭代过程中,试图动态地添加一个新的聚类中心,具体做法是:从次数q=1开始,实现一个簇的聚类划分,得到一个簇的最佳聚类中心;在寻找q=2簇划分结果时,默认第一个聚类中心为上一次迭代过程得到的聚类中心,并通过数据集中剩余的每一个样本作为第二个聚类中心的候选集合,然后用FCM算法对候选集合中的所有成员进行聚类,得到各自的聚类误差平方和,最后选择误差平方和最小的数据点作为第二个最佳聚类中心。在q=2聚类结果的基础上解决q=3的聚类划分,以此类推,得到q=c个簇的聚类问题。应用全局思想的模糊聚类算法不再受初始点影响,有效地避免了陷入局部最优解的风险,提高了聚类精确度。
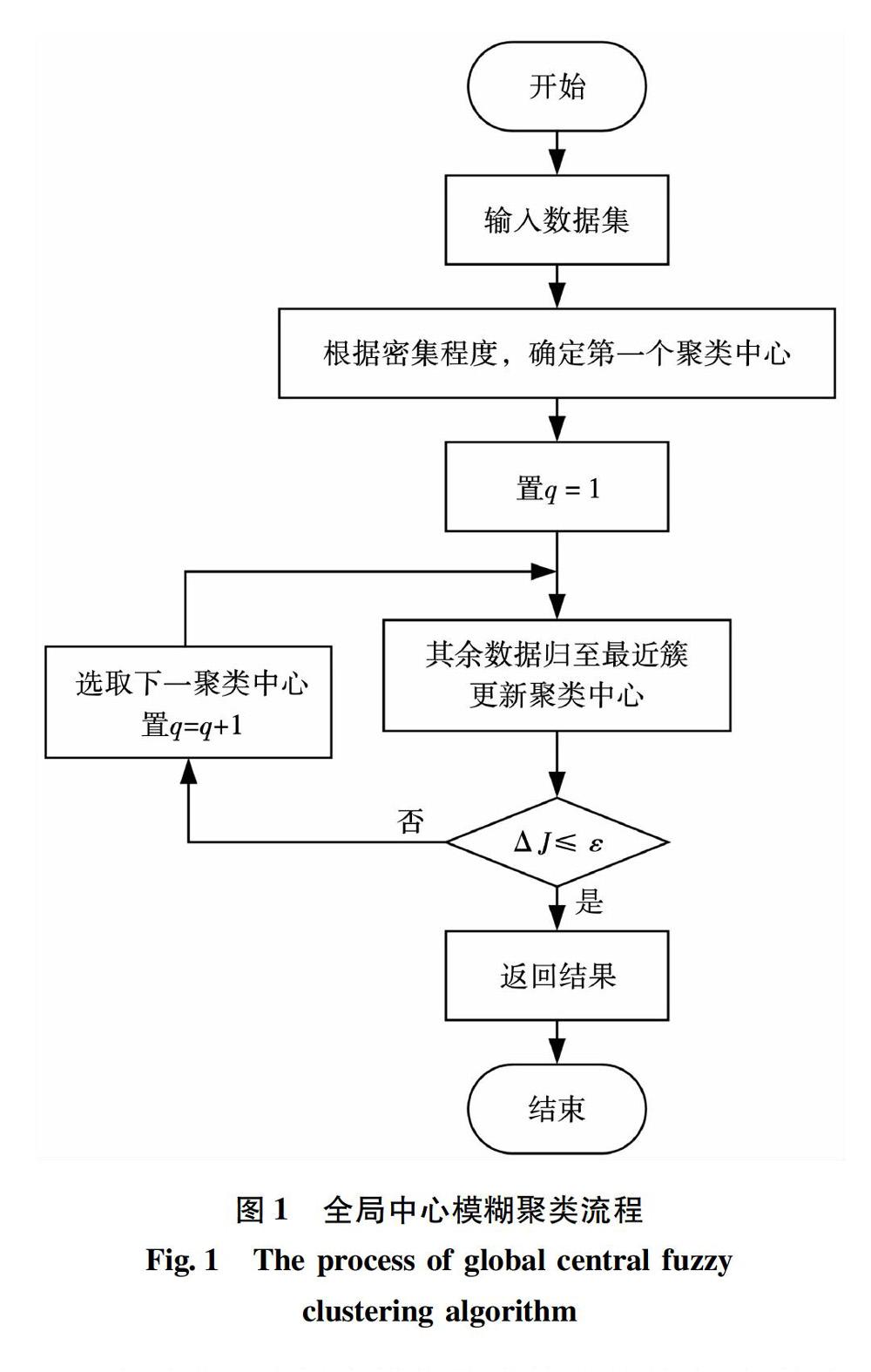
2 快速全局中心模糊聚类算法
2.1 算法的基本思想
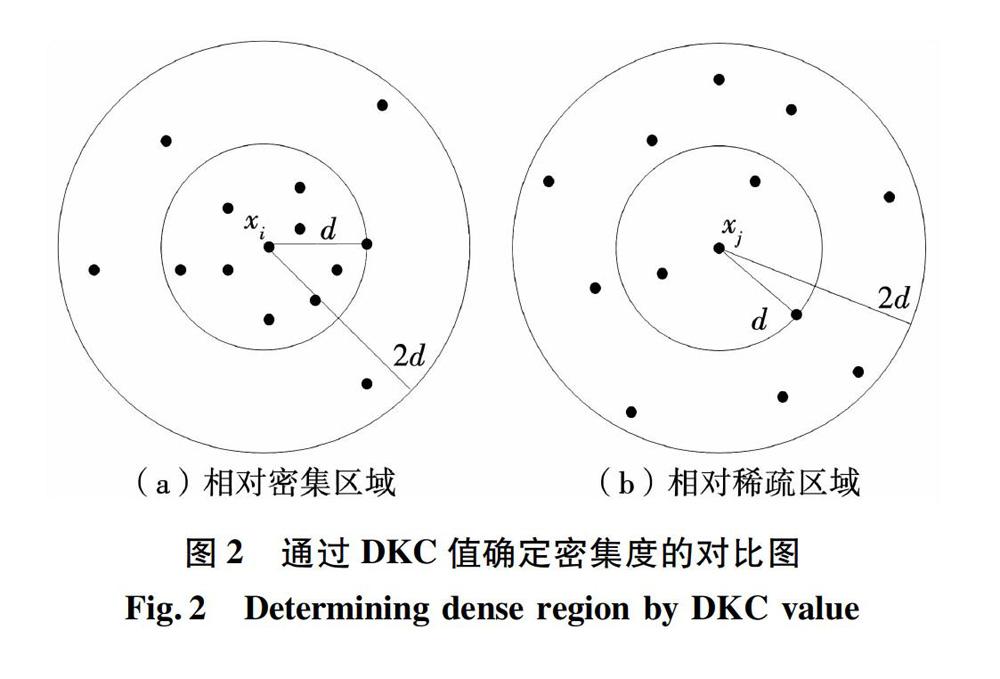
单纯的全局模糊聚类算法依然没有解决c值不确定的问题,且在聚类的每次划分过程中都需要进行N(N为数据集合中对象总个数)次算法迭代,整个过程共需进行c×N次,导致算法的运行速度较慢,其直接原因是在确定下一聚类中心点的过程中,要将数据集合中的每一个数据对象都作为聚类中心候选点进行算法迭代测试。实际上,数据集的各个聚类中心一定会分布在样本相对密集的区域,数据集合中的外围孤立点、稀疏区域对象集就不可能成为最佳聚类中心备选点,故算法在选取下一聚类中心的过程中,无需将集合中所有数据对象都作为初始聚类候选中心进行测试运算,只要在样本分布相对密集的区域寻找最佳聚类中心即可,故本文提出了一种确定样本分布密集度的全局中心的模糊聚类算法,基本思想为:
1)计算密集度,确定初始中心点
通过计算数据集中所有对象的密集程度,选择密集度最大的数据成员作为第一个聚类中心,并从质心备选集中删除稀疏区域样本点。
2)重新划分数据对象,更新聚类中心
对于当前确定的聚类中心,将数据集中的所有数据对象分配到距离当前已有聚类中心最近的簇,并更新聚類中心。
3)判断终止条件
前后两次目标函数差值的绝对值ΔJ小于等于给定的某个阈值ε时,算法停止,返回结果。
4)选取下一个聚类中心
在质心备选集中按照某种自定义优化规则选择下一个聚类中心,而不是把备选集中所有对象依次进行测试。
2.3 聚类中心的动态选择
在传统算法中,采用欧氏距离度量样本之间的相似性,但欧氏距离的度量方式只对同尺寸、同密度、同形状等相同信息且分布均匀的理想化数据具有稳定性。然而,现实数据往往都具有不同的特征,故欧氏距离度量方式使算法很容易受到外围孤立点、噪声点的影响,造成聚类结果的不稳定。本文在更新聚类中心和隶属度的过程中,利用基于非欧氏距离度量方式—AM度量[13][16]的单调有界性降低外围点或噪声点对确定聚类中心过程的影响,来增强聚类算法的稳定性和鲁棒性,并减少算法的迭代次数。
4 结 语
针对FCM聚类算法对初始聚类中心选取敏感,易受噪声点影响,以及聚类最终结果容易陷入局部最优的问题,本文提出了ADGFCM算法,该算法采用全局中心聚类思想,结合DKC值与AM度量,并提出自定义寻优函数fi,全面考虑了所有数据对象点的分布情况,缓解对噪声点敏感的问题。选取一个周围数据对象分布比较密集,且距离现有聚类中心都比较远的数据对象点作为下一个最佳聚类中心,不但使聚类结果趋于稳定,提高聚类精确度,而且减少了算法累加过程中的计算负担,加快聚类速度,在一定程度上跳出局部最优。实验结果表明,ADGFCM算法相比FCM算法和其他改进后的FCM算法精确度均有所提高,运行时间较短,聚类效果较为稳定,在实际数据集上有较好的应用价值。
参 考 文 献:
[1] SANAKAL R, JAYAKUMARI T. Prognosis of Diabetes Using Data Mining Approach-fuzzy C Means Clustering and Support Vector Machine[J]. Int. J. Comput. Trends Technol.(IJCTT), 2014, 11(2): 94.
[2] LIU L, SUN S Z, YU H, et al. A Modified Fuzzy C-Means (FCM) Clustering Algorithm and Its Application on Carbonate Fluid Identification[J]. Journal of Applied Geophysics, 2016, 129:28.
[3] 吴明阳, 张芮, 岳彩旭,等. 应用K-means聚类算法划分曲面及实验验证[J]. 哈尔滨理工大学学报, 2017(1):54.
[4] 武俊峰, 艾岭. 一种基于改进聚类算法的模糊模型辨识[J]. 哈尔滨理工大学学报, 2010, 15(3):1.
[5] NAYAK J, NAIK B, KANUNGO D P, et al. A Hybrid Elicit Teaching Learning Based Optimization with Fuzzy C-means (ETLBO-FCM) Algorithm for Data Clustering[J]. Ain Shams Engineering Journal, 2016(5):148.
[6] FILHO T M S, PIMENTEL B A, SOUZA R M C R, et al. Hybrid Methods for Fuzzy Clustering Based on Fuzzy C-means and Improved Particle Swarm Optimization[J]. Expert Systems with Applications, 2015, 42(17):6315.
[7] PAN X, LIU P, REN M, et al. Optimization of fuzzy C-means based on OBL-genetic algorithm[C]//Natural Computation, Fuzzy Systems and Knowledge Discovery (ICNC-FSKD), 2016 12th International Conference on. IEEE, 2016: 109.
[8] YE A X, JIN Y X. A Fuzzy C-Means Clustering AlgorithmBasedon Improved Quantum Genetic Algorithm[J]. International Journal of Database Theory and Application, 2016, 9(1): 227.
[9] LIU P,DUAN L, CHI X, et al. An Improved Fuzzy C-means Clustering Algorithm Based on Simulated Annealing[C]//Fuzzy Systems and Knowledge Discovery (FSKD), 2013 10th International Conference on. IEEE, 2013: 39.
[10]陳加顺, 皮德常. 一种非噪声敏感性的模糊C均值聚类算法[J]. 小型微型计算机系统, 2014, 35(6):1427.
[11]WANG W, ZHANG Y, LI Y, et al. The Global Fuzzy C-means Clustering Algorithm[C]//2006 6th World Congress on Intelligent Control and Automation. IEEE, 2006, 1:3604.
[12]任培花, 王丽珍. 不确定域环境下基于DKC值改进的K-means聚类算法[J]. 计算机科学, 2013, 40(4):181.
[13]WU K L, YANG M S. Alternative C-means Clustering Algorithms[J]. Pattern Recognition, 2002, 35(10):2267.
[14]李远成, 阴培培, 赵银亮. 基于模糊聚类的推测多线程划分算法[J]. 计算机学报, 2014, 37(3):580.
[15]谢娟英, 蒋帅, 王春霞,等. 一种改进的全局K-均值聚类算法[J]. 陕西师范大学学报:自然科学版, 2010,38(2):18.
[16]ZHANG Dao-qiang, Chen. A Comment on “Alternative C-means Clustering Algorithms”[J]. Pattern Recognition, 2004, 37(2):173.
[17]RASTGARPOUR M, ALIPOUR S, SHANBEHZADEH J. Improved Fast Two Cycle by using KFCM Clustering for Image Segmentation[J]. Lecture Notes in Engineering & Computer Science, 2012, 2195(1).
[18]AHMAD A,DEY L. A K-mean Clustering Algorithm for Mixed Numeric and Categorical Data[J]. Data & Knowledge Engineering, 2007, 63(2):503.
[19]BEZDEK J C. A Physical Interpretation of Fuzzy ISODATA[J]. IEEE Transactions on Systems Man & Cybernetics, 1976, 6(5):615.
[20]VANI H Y,ANUSUYA M A. Isolated Speech Recognition Using Fuzzy C Means Technique[C]// International Conference on Emerging Research in Electronics, Computer Science and Technology. IEEE, 2016:352-357.
(编辑:关 毅)
