
Wine数据集分析
2019-11-03 13:11姜改新
电脑知识与技术 2019年24期
关键词:支持向量机
姜改新

摘要:本文以UCI的Wine数据集为数据来源,该数据集为意大利同一地区生产的三个不同种类的葡萄酒的成分数据,对其178条数据进行分析处理,其中共有13个成分特征。为了解决人工评审葡萄酒分类时容易产生错误的问题,提高分类效率,采用机器学习中SVM的方法对其特征进行分析来确定葡萄酒的分类。
关键词:葡萄酒品种分类;支持向量机;分类评价;数据集
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2019)24-0004-02
开放科学(资源服务)标识码(OSID):
1 概述
本文以UCI的Wine数据集为数据来源,采用机器学习的方法利用Python语言对葡萄酒的成分进行分析,从而给出了可靠性比较高的分类。本数据集共有178个例子,样品有十三种成分,分别为Alcohol,Malic acid, Ash,Alcalinity of ash,Magnesium,Total phenols, Flavanoids,Nonflavanoid phenols,Proanthocyanins,Color intensity, Hue,OD280/OD315 of diluted wines,Proline。数据集一共收集了三个葡萄酒品种的数据,第一种有59例,第二种有71例,第三种有48例。
2 数据预处理
本数据集包含了三种葡萄酒的178条数据,由于数据集的每条数据都是连续的,而且没有缺失值,所以并没有对数据进行清洗。为了通过建模分析数据,将原始数据集划分为训练集和测试集,训练集占据样本的70%,测试集占据30%,分别为124条和54条数据。为了消除不同特征之间量纲和取值范围的影响,提高分类的精确率,分别对训练集和测试集数据进行离差标准化,然后对两个数据集进行PCA降维,在不太损失模型质量的情况下,提升了模型训练速度。
3 用皮尔森相关系数和随机森林方法实现不同特征和分类、各特征之间的相关系数分析
1)首先求出品种分类部分,以及品种的数据部分,用pearsonr()方法得出不同特征与分类的皮尔森系数,然后生成DataFrame类型的数据。由结果知,特征Flavanoid,OD280/OD315 of diluted wines,Total phenols与分类的相关性比较强,接近与1,而Ash特征与分类的相关性最弱,接近于0。
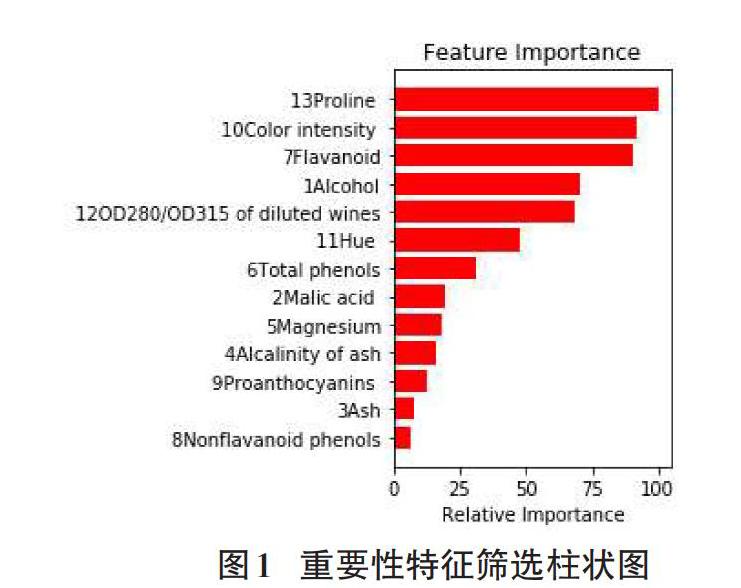
2)通过随机森林得到重要特征,并根据Numpy类库的筛选方法筛选出大于0的数据索引,根据这些索引得到特征与分类的作用的系数数组。柱状图结果如图所示:
从图中各个特征对于分类的作用所占百分比可以看出排列在前三位的三个特征对于分类的影响很大,而Ash特征对于分类的影响很小。
4 用聚类、SVM模型实现分析聚类的最佳聚类数和品种分类分析
1)利用sklearn类库的方法对降维的训练集数据构建K-Means聚类模型,并预测类别,提取分类标签。聚类模型将数据聚类为3类,而且除去个别数据外,3个类别之间具有明显的界限,那些不易分界的数据可能是因为有些特征的数据分布比较分散造成的。
2)评价聚类模型:将聚类的类数从2到15遍历。(1)用sklearn类库方法得到轮廓系数,用轮廓系数评价模型法评价,在某一点是若图像平均畸变程度最大,说明聚类数目为这一点所代表的数时,效果比较理想,還可以用Calinski—Harabasz指数来评价,某一聚类的指数最大时,聚类为此数目效果最理想。从结果可以看出,当聚类为3类时,指数最大,和轮廓系数评价模型结合可知,聚类数目为3时,聚类效果较好。
3)SVM(支持向量机)原理
相关学习算法如下:
输入:线性可分训练数据集T=
其中,核函数为K(*)
输出:最大间隔分类超平面和分类决策函数。
构造并求解约束函数最优化问题:
其中是松弛变量,C是惩罚常数,w和b分别为判决函数f(x)=(w*x+b)的权向量和阈值。
根据KKT条件:(其中为拉格朗日算子)
对于非线性问题,可以通过一个非线性变换将训练样本映射到特征空间,这样,分类问题通过在特征空间中求解线性支持向量机就可以完成。
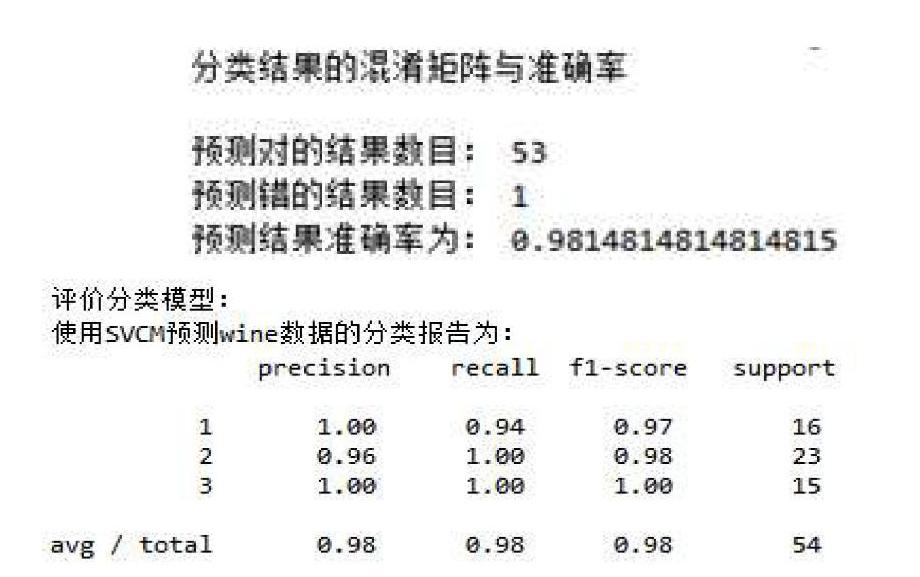
4)构建SVM分类模型,利用sklearn.svm的方法用训练集数据、训练集标签构建SVM模型,预测测试集的数据都是属于哪些分类,并描述预测结果以及准确率,最后做出SVM模型评价报告。
构建的SVM分类模型54条数据,预测正确的有53条,错误的仅仅一条,说明整体模型效果比较理想。对于分类为1的数据,精确率为1,召回率却不为1,分类为2的数据,精确率不为1,但召回率却为1,说明预测错误的那条数据原本应该为第一类,但是SVM模型却预测为第二类,所以导致了上述结果,分类为3的数据全部预测正确。可以看出整体效果比较理想。
5 结语
本文介绍了一些数据分析的基本步骤,比如数据读取、预处理、画图等,还有聚类建模,分类建模以及皮尔森相关系数的运用等等。在对每条数据进行分类时构建的SVM模型,对于测试集的54条数据,53条预测正确,正确率达到98%,SVM模型整体比较理想。在对大量数据进行分析求得想要挖掘的有价值信息时可以有很大的参考价值。
参考文献:
[1] 不均衡数据下基于SVM的分类算法研究与应用[J].哈尔滨工程大学硕士学位论文.
[2] 黄红梅,张良均.Python数据分析与应用[M].人民邮电出版社.
【通联编辑:李雅琪】
猜你喜欢
现代电子技术(2016年23期)2017-01-12
现代电子技术(2016年23期)2017-01-12
中国水运(2016年11期)2017-01-04
科学与财富(2016年28期)2016-10-14
考试周刊(2016年53期)2016-07-15
