
一种改进的半监督k均值算法研究
2019-11-03 13:11吴湘华曹丽君
电脑知识与技术 2019年24期
吴湘华 曹丽君
(湖南城市学院,湖南 益阳 413000)
摘要:初始聚类中心的选择对k均值聚类算法效率影响比较大,半监督k均值算法就是将标记数据应用于k均值聚类算法中,标记数据虽然具有非常强的导向性,但也可能存在异常的情况,这时候,聚类算法效率会变得很差。本文提出改进的半监督k均值算法,先处理异常标记数据,并结合一定方法选取的初始聚类中心,得到新的初始聚类中心。改进的算法迭代次数明显下降,算法效率明显提高。
关键词: 初始聚类中心;k均值;半监督;标记数据;迭代次数
中图分类号:TP319 文献标识码:A
文章编号:1009-3044(2019)24-0016-02
开放科学(资源服务)标识码(OSID):
聚类分析是数据挖掘领域一个重要的分支,在国内外得到了广泛的研究与应用。其中,k均值聚类算法[1]是最经典的算法之一,该算法一般采取某种方法选取k个初始聚类中心,将每个样本聚类到距离最短的簇中,并通过不断迭代,使整体目标函数达到最优。k均值算法具有原理简单、容易实现、效率高、伸縮性好等优点,其缺点主要有k值一般需要人为指定,对初始聚类中心依赖性强,结果有时候会出现局部最优等。半监督学习是将无监督学习和监督学习结合起来的一种方法,半监督k均值算法[2]就是将少量的标记数据应用于k均值聚类过程的算法。
1 半监督k均值及实验分析
1.1 半监督k均值算法描述
聚类分析是将数据等对象的集合按照相似的原则分成若干个簇的过程,属于无监督学习。半监督聚类分析是则是综合运用少量标记数据[3]和大量未标记数据,将少量“昂贵的”标记数据和大量“廉价的”未标记数据有机地结合在一起,避免了数据资源的极大浪费[4];从而从很大程度上避免了无监督聚类过程中的盲目性[5],提高算法的效率,减少运行时间,提升最终簇类的质量。半监督k均值算法就是在k均值聚类分析过程中引用少量的标记数据,从标记数据中采用一定的方法选取初始聚类中心,然后再使用k均值迭代算法进行聚类。
1.2 半监督k均值算法实验及分析
对 dataset1数据集中的数据进行聚类分析,该数据集是一组描述有关身高、体重和性别的数据集,k值为2,使用传统k均值聚类时,如果随机选取初始聚类中心,最小迭代次数为2,最大迭代次数为13,平均迭代次数为6.6。使用半监督k均值聚类算法对dataset1数据集中所有数据进行聚类,实验如下:
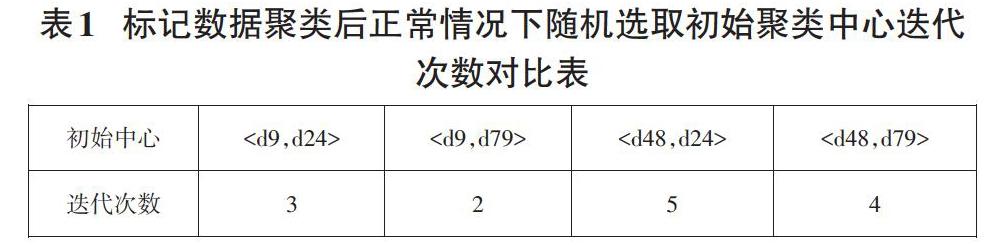
1.2.1 标记数据聚类后正常的情况
标记数据集为:A={d9,d48}?class1,B={d24,d79}?class2,用
从上表可以得出,在标记数据集合中分别随机选取初始聚类中心的平均迭代次数3.5。用|A|和|B|分别表示集合A和集合B均值,如果以|A|和|B|分别作为聚类的初始中心,迭代次数为3。
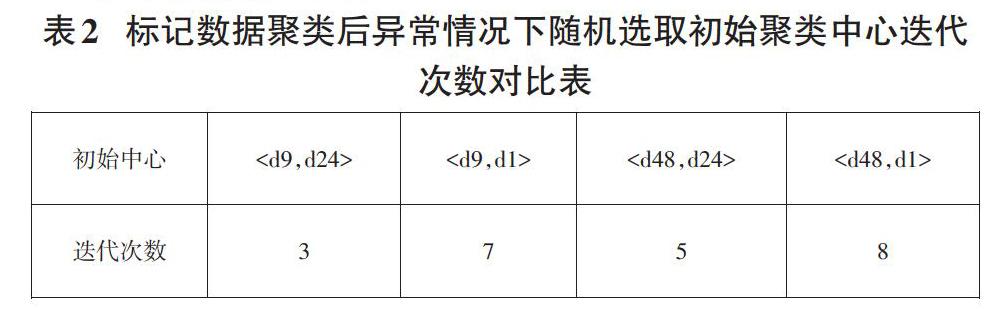
1.2.2 标记数据聚类后异常的情况
标记数据集为:A={d9,d48}?class1,B={d24,d1}?class2,从集合A和B中分别随机选取两个聚类的初始聚类中心,然后进行半监督k均值聚类,分别有4种情形,聚类后,集合A和集合B中的数据d1在class1中,集合B中的数据d24在class2中,此时出现了标记数据聚类后异常的情况。选取不同初始聚类中心时的迭代次数,如下表1:
从上表可以得出,在标记数据集合中分别随机选取初始聚类中心的平均迭代次数5.8。用|A|和|B|分别表示集合A和集合B均值,如果以|A|和|B|分别作为聚类的初始中心,迭代次数为7。
1.2.3 实验结果分析
聚类后,如果标记数据没有出现在别的簇中,无论是从标记数据中随机选取初始聚类中心,还是使用标记数据的均值作为初始聚类中心进行半监督k均值聚类,其迭代次数明显小于传统的k均值算法,而且使用均值作为初始聚类中心更加具有优势,因为标记数据对聚类具有很强的指导意义。聚类后,当标记数据到了别的簇中,不管是采用随机选取初始聚类中的方法心,还是以标记数据的均值作为初始聚类中心,都会带来很大负面的偏离,导致迭代次数大大增加,算法效率甚至劣于传统的k均值算法。
2 半监督k均值及实验分析
2.1 半监督k均值算法的改进
为了避免异常标记数据给聚类带来的负面影响,在标记数据的指导下,选取合适的初始聚类中心。对半监督k均值聚类算法做如下改进:(1)在原始数据集中随机选取若干个数据构成数据集R,和标记数据集M一起构成一个子集N;(2)对子集N进行半监督k均值聚类;(3)通过聚类后的簇,找出标记数据中有出现异常的数据,并在初始标记数据集中删除,得到处理后的标记数据集M1;(4)在原始数据集中采用某种选择初始聚类中心的方法(如基于点密度的方法)选取k个初始聚类中心,将这k个点分别置于M1中,得到M2,(5)以M2中各类点的均值作为初始聚类中心,对原始数据进行k均值聚类。
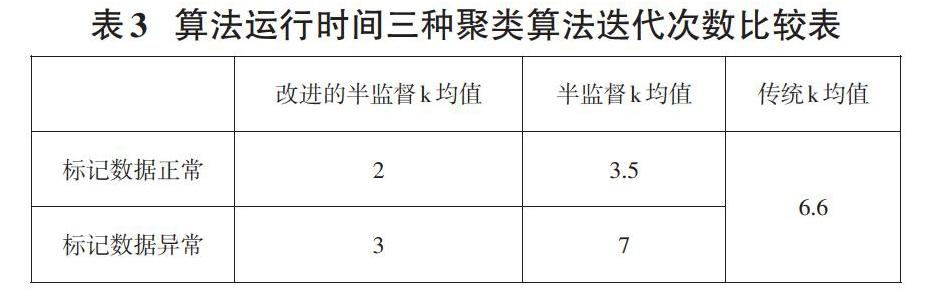
2.2 改进的半监督k均值算法实验及分析
对 dataset1数据集中的数据进行聚类分析,迭代次数对比如表3:
笔者同时对Glass、Ecoli、Irisdata和Rice等数据集进行实验,发现改进的半监督k均值算法更为有效,在选取初始聚类中心时,比传统的k均值算法和半监督k均值算法具有更强的针对性,引进并处理过后的标记数据,大大提高了算法的效率。
3 结束语
改进的半监督k均值算法对标记数据进行处理,尽可能地避免异常标记数据给聚类带来不良影响,同时考虑k均值聚类算法中确定优质初始聚类中心的经验,也将其作为标记数据,并将优质初始聚类中心也当作一个标记数据,由这两类数据共同确定初始聚类中心,使得选取的初始聚类中心尽可能靠近聚类后的中心,提高算法的效率。
参考文献:
[1] Agrawal R,et al. Database mining: A performance perspective [A].IEEE Transactions on knowledge and Data Engineering [C].1993, 5(6): 914-925.
[2] 高滢,刘大有,齐红,等.一种半监督K均值多关系数据聚类算法[J].软件学报,2008(11):2814-2821.
[3] Bates Matthew E,Keisler Jeffrey M,ZussblattNiels P, Plourde Kenton J,Wender Ben A,LinkovIgor.Corrigendum: Balancing research and funding using value of information and portfolio tools for nanomaterial risk Classification[J].Nature Nanotechnology,2016,11(4):395-403.
[4] 刘方.数据挖掘中半监督K-均值聚类算法的研究与改进硕士论文[D].吉林大学,2010.
[5] Zhi-Yong Li,Jiao-Hong Yi,Gai-GeWang.A New Swarm Intelligence Approach for Clustering Based on Krill Herd with Elitism Strategy[J].Algorithms,2015 ,18(4):951-964.
【通联编辑:朱宝贵】
