
基于融合深度学习模型的长鳍金枪鱼渔情预测研究
2019-11-13 06:22袁红春陈骢昊
渔业现代化 2019年5期
袁红春,陈骢昊
(上海海洋大学信息学院,上海 201306)
远洋长鳍金枪鱼延绳钓渔业经过长期不断地发展,现已成为中国远洋渔业最主要的产业之一[1]。在南太平洋海域,长鳍金枪鱼(Thunnusalalunga)作为一种具有高经济收益的鱼类产品,已经成为中国及其海域周边国家的主要捕获对象[2],而且年产量正逐年上升[3]。又由于其产量占南太平洋海域金枪鱼类总产量的50%以上,因此该鱼种具有较大的开发潜力。如何提高南太平洋长鳍金枪鱼的渔情预测水平已成为国内学术界研究的热点之一。
在对南太平洋长鳍金枪鱼渔场影响因子研究方面,闫敏[4]分析了海表面温度(SST)、叶绿素a(CHLA)及海面高度距平(SSH)各环境因子与单位捕捞努力量渔获量(CPUE)的相关性;范永超等[5]通过叶绿素a(CHLa)、SST和海洋表面盐度(SSS)对南太平洋长鳍金枪鱼渔场进行分析与预报;张嘉容等[6]通过广义可加模型分析得出纬度对南太平洋长鳍金枪鱼渔场最大的影响因子,经度以及SST、海表面高度、叶绿素a等环境因子也对渔场有较大的影响力。
在利用神经网络模型进行渔情预测分析方面,Aoki等[7]搭建包含三层隐层的BP人工神经网络模型,实现对日本远东拟沙丁鱼渔获量的预测;毛江美等[8]搭建BP人工神经网络模型,并调整模型结构及参数,以月份、经度、纬度、SST、SSH等作为时空变量进行了分析,从而实现对渔场CPUE值的预测。
由于单个渔场范围较大,如果采用传统渔情预测方法对渔场内各点的环境数据取均值得到渔场所对应的环境数据,会存在一定环境数据特征丢失现象[9]。因此提出一种CNN-GRU-Attention模型,以实现对南太平洋长鳍金枪鱼渔场CPUE的有效预测。
1 数据处理
1.1 数据来源
渔业作业数据取自中西太平洋渔业委员会(WCPFC)的南太平洋延绳钓数据。为排除捕捞手段等技术因素的影响,采用捕捞手段基本一致的2000年1月至2011年12月的南太平洋海域长鳍金枪鱼渔业数据[10],时间分辨率为月,海域范围取为5°S~40°S,135°W~110°E,数据包含年、月、经度、纬度、钓钩数(千钩)、长鳍金枪鱼渔获量(尾),空间分辨率5°× 5°。其中,单位捕捞努力渔获量(CPUE)为预测参数[11],其计算公式为:
XCPUE=A/H
(1)
式中:XCPUE—单位捕捞努力量,尾/千钩(ind/khooks);A—渔获量,尾(ind);H表示钓钩数,千钩(khooks)。处理后的渔业数据见表1。

表1 渔业数据
注:“⋮”表示省略的年、月、经纬度等数据
选取环境数据(包括月、经度、纬度、叶绿素a浓度、海面高度、海面温度[12]),空间分辨率为1°× 1°,时间分辨率为月,海域范围取为3°S~42°S、133°W~108°E;叶绿素a(CHLA)、海表温度(SST)数据来源于美国国家海洋和大气管理局(NOAA)环境数据库;海面高度(SSH)数据来自于哥白尼海洋环境监测服务中心(CMEMS),将环境数据按照年、月、经度、纬度进行整合得到数据集(表2)。
1.2 样本集构成
由于环境数据与渔业数据空间分辨率不一致,将5°× 5°范围内所有1°× 1°环境因子数据取均值,再与渔业数据合并,得到数据集A(表3)。将5°× 5°范围内25条1°× 1°的环境数据与CPUE作为一个样本,得到数据集B(表4)。

表2 环境数据
注:“⋮”表示省略的年、月、经纬度等数据,下同

表3 数据集A
表4 数据集B
月、经度、纬度、海面温度、海面高度、叶绿素a为训练参数,选取每月CPUE为预测参数,将数据集A、B按照年、月、经度、纬度和年、月、纬度、经度分别排序得到数据集A1、B1和A2、B2,使用A1、B1和A2、B2分别在模型上进行训练,目的是排除单一实验导致实验结果存在偶然性。由于整个数据集的时间长度为12年,所以将这4个数据集按照比例为10∶1∶1划分为训练集、验证集、测试集。
1.3 缺失数据处理
由于海洋环境数据每月都存在个别渔场的数据缺失,所以利用插值法(2)对于缺失的环境数据进行补全[13],即利用同时间点的其余渔场的环境数据构建回归函数来得到缺失数据。
Y(a,b)=f(a,b)
(2)
式中:Y(a,b)为该年月纬度为a,经度为b的环境数据;f为该年月其他数据以经纬度为自变量、环境数据为因变量所得到函数。
1.4 数据归一化
将各影响因子和目标变量分别采用公式(3)分别归一化至[0.1,1]区间内,从而消除由于数据各因子的量级不同而对训练模型造成不良影响[14]。
(3)
式中:xn表示某影响因子的第n条数据;xmax表示该影响因子的最大值;xmin表示该影响因子的最小值。
2 深度学习模型
2.1 CNN模型介绍
卷积神经网络(CNN)模型是近些年来深度学习领域使用最广泛的模型之一。CNN是一种前馈神经网络,由Lecun等[15]首先提出,利用卷积层提取局部的有效特征,通过池化层降低参数,最后由全连接层得到所需的权值向量。CNN主要神经层包括卷积层(C)、池化层(S)以及全连接层(F)[16](图1)。通过反复使用卷积层和池化层提取渔场范围内的环境因子及时空因子的特征值,最终通过全连接层汇总获取与CPUE对应的一维向量,作为GRU模型的输入向量。
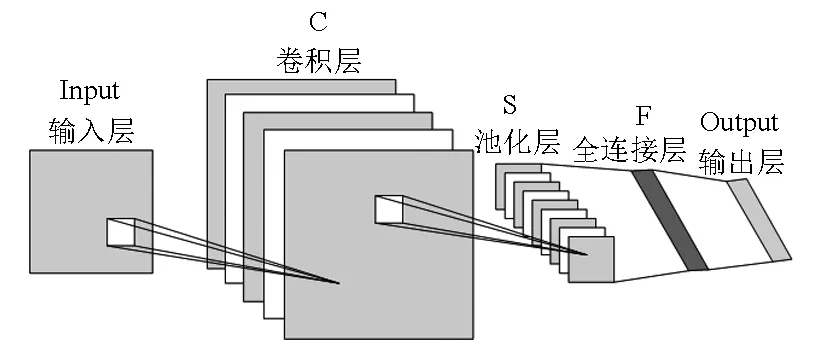
图1 CNN模型
2.2 GRU模型介绍
门控循环单元(GRU)是一种递归循环神经网络,其发展经历了从简单循环神经网络(SRN)至循环神经网络(RNN)再到长短期记忆网络(LSTM)的发展过程[17]。本研究所使用的模型是LSTM模型的一种变种[18],在其基础上做出改进。GRU模型相较LSTM模型,其最大的改进主要在于两点[19]:1)将输入门、遗忘门、输出门改为更新门及重置门;2)将单元状态C与短期状态h融合为一个状态h。因此,与LSTM模型性能相当,但其运算效率远高于LSTM,相同的训练集,其训练时长远低于LSTM模型,但效果基本一致。
GRU的前向计算公式[20]:
更新门计算公式:
zt=σ(Wzg[ht-1,xt])
(4)
重置门计算公式:
rt=σ(Wrg[ht-1,xt])
(5)
输出部分计算公式:
(6)
(7)
yt=relu(W0ght)
(8)
式中:Wz为更新门的权重矩阵;Wr为重置门的权重矩阵;ht-1为t-1时刻的单元状态输出值;xt为t时刻的单元数据的输入值;σ指激活函数sigmoid;tanh表示输出层激活函数为tanh。GRU模型结构如图2所示。
2.3 CNN-GRU-Attention模型
CNN-GRU-Attention模型以每个渔场5°× 5°范围内所有1°× 1°的月份、经度、纬度、叶绿素a、海面盐度、海面温度为输入数据,通过CNN提取出特征向量,再与渔场对应的CPUE结合成全新的时间序列数据,通过GRU模型进行时间序列上的预测,再使用Attention层提取各隐藏层的权值并与GRU模型各隐层输出相结合作为样本的特征表达[21]。Attention机制是通过自动加权变换,将GRU模型的隐藏层的输出信息Git通过tanh函数得到uit,再与注意力矩阵uw相乘,最后行归一化输出,得到各隐藏层输出的权值αit,整合各隐层输出得到最终输出si,公式见(9)、(10)和(11),最终模型构造如图3所示。
uit=tanh(kiGit+bt)
(9)
(10)
si=∑αitGit
(11)
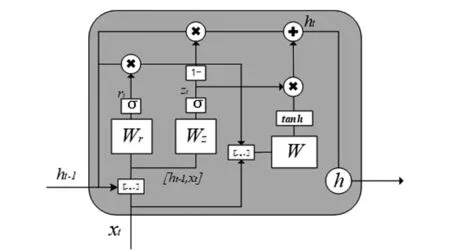
图2 GRU模型

图3 CNN-GRU-Attention模型
图3中,G表示用于卷积的训练参数数据;M1到Mn表示第1条到第n条训练参数数据;数据进入CNN的P1到Pn表示输入样本第1个到第n个参数;k1到kn表示提取的各GRU隐藏层权值;yt表示对应的预测参数数据。
3 试验及结果分析
3.1 试验平台
试验环境为基于Python3.7的TensorFlow 1.13.1框架,操作系统为Windows10,GPU为NVIDIA GTX 1060,通过CUDA9.0进行加速运算,CPU为Intel i7-7700K。
3.2 试验过程
为验证CNN-GRU-Attention模型的有效性,在基于Anaconda3的Keras深度学习平台上实现BP、GRU、CNN-GRU、CNN-GRU-Attention模型。数据集A1在BP模型和GRU模型上试验,数据集B1在CNN-GRU和CNN-GRU-Attention模型上实验,在数据集A2、B2上进行同类实验。最后通过2组对比实验的结果进行综合判定。以B1数据集在CNN-GRU-Attention模型上试验为例,训练过程如下:
在CCN-GRU-Attention模型中,数据的输入形式是一个三维的张量(None,5,6),None表示每批次训练输入的样本的数量,数据先经过激活函数为Relu函数的一维卷积层(Conv1D),含有64个1×3的卷积核,此时张量维度变为(None,5,64);再经过一个窗口为4的最大池化层(Maxpooling1D),张量维度变为(None,1,64);接着通过含有32个1×3卷积核的一维卷积层(Conv1D),张量变为(None,1,32);然后通过一个窗口为1的最大池化层(Maxpooling1D)连接一个输出维度为6的全连接层(Dense),张量维度为(None,1,6);数据再进入一个输出维度为6的GRU模型中进行训练,由于每月数据为192条,遂batch_size(批尺寸)选择192,再获取其隐藏层输出,输入Attention层得到输出各节点权值矩阵,与GRU模型输出向量相乘,再通过输出维度为6的全连接层,由过滤值为0.2的Dropout层进行过拟合预防处理,最后通过激活函数为Sigmoid的全连接层输出得到最终的预测值。
为确保模型训练得到最佳状态,设置早停函数忍耐值为30,模式为min,即30次迭代训练过程中训练集的损失值没有减少,则停止训练。4种模型的试验过程如图4所示。
3.3 试验结果
3.3.1 误差结果
为评价模型性能,根据相关文献[22],使用平均绝对误差(XMAE)、均方根误差(XRMSE)作为评价各神经网络的模型性能,误差计算按以下公式:
(12)
(13)
式中:Ct为预测值;Rt为真实值。XMAE越小,表明模型预测越准确;XRMSE越小,表明模型预测性能越稳定。试验误差结果见表5。
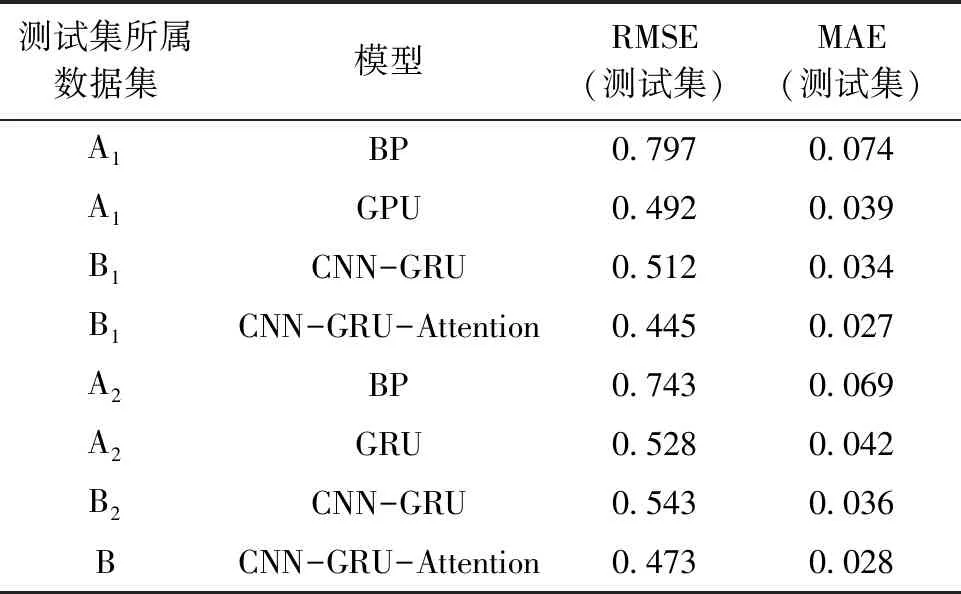
表5 误差结果对比
由于A1和A2在GRU模型上的RMSE比其在BP模型上分别降低0.305、0.215,MAE分别下降0.035、0.027,表明使用GRU模型比BP预测性能更稳定,预测精度更高。由于B1在CNN-GRU模型的MAE比A1在GRU模型降低0.005,B2在CNN-GRU模型的测试集MAE比A2在GRU模型降低0.006,说明使用CNN提取区域内各节点环境数据的特征值对CPUE预测比直接计算区域内环境因子数据的平均值对CPUE预测,精度更高,也证明了使用CNN提取渔场环境因子的空间特征数据的有效性。但B1、B2在CNN-GRU模型的测试集RMSE比A1、A2在GRU模型上分别上升0.02、0.015,说明使用CNN提取渔场区域内的环境因子造成模型预测稳定性的一定下降。
由于数据集B1、B2在CNN-GRU-Attention模型的测试集RMSE比其在CNN-GRU模型分别降低0.067、0.07,说明Attention机制解决了CNN-GRU所存在的稳定性下降问题;又由于B1、B2在CNN-GRU-Attention模型的测试集MAE比其在CNN-GRU模型分别降低0.007、0.008,说明Attention机制在解决CNN-GRU稳定性下降的同时,还使模型的预测精度有所提高。
综上所述,在CNN-GRU-Attention模型最优情况下,相较于BP(多层前馈网络),绝对误差降低0.047,均方根误差降低0.352;与GRU相比,绝对误差降低0.012,均方根误差降低0.055。
3.3.2 损失值结果
数据集B1、B2在CNN-GRU模型、CNN-GRU-Attention模型上的训练集与验证集损失值如图5所示。图中横坐标为迭代次数,纵坐标为损失值,train为训练集损失值,validation为验证集损失值。从图中可以得出,B1、B2在CNN-GRU-Attention模型上分别迭代282、309次完成训练,在CNN-GRU模型上分别迭代166、184次完成训练,这说明加入Attention层后,虽然模型复杂度上升,但模型的收敛速度加快。由此可见,Attention机制对于模型训练起到了一定的优化作用。

图5 损失值图
4 讨论
4.1 多层前馈神经网络与循环神经网络预测性能的对比
GRU及其改进模型在精度及稳定性上明显优于BP模型,这是由于训练带有时间序列特征的数据集时,具有记忆功能的循环神经网络及其改进网络相较于传统的BP网络能够更好地保留数据的变化特征。而以往的渔场CPUE预测方法通过调整BP结构来进行渔场分析[5],虽然通过反复试验得到了各影响因子所适合的模型权重,但在数据集变化时,需要对模型各层权重重新进行矫正,而GRU模型中利用不断更新的单元状态及更新门权重,保持了隐层权重与目标因子的拟合度,从而实现了对目标因子的准确预测。
4.2 融合模型所带来的影响及其优化
通过CNN处理环境因子的融合模型CNN-GRU相较于取均值进行预测的GRU模型在精度上有明显提高,说明卷积处理因子数据相较于均值法能更加有效地提取影响因子的特征。但CNN-GRU模型的稳定性有所下降,这是由于模型复杂度上升,异常数据所导致的误差也因此放大,所以导致试验结果均方根误差上升。相较于同样由于渔场过大所采用的聚类分析法[23],通过聚类得到渔场的数个重心点,再对渔场相同半径范围内进行分析,因此丢失一些单独捕捞点的数据。虽然本文的卷积提取法充分利用了渔场数据,但也增加了无效点对模型参数的干扰,所以,利用Attention层对CNN-GRU模型的隐层输出做附权值处理,可降低异常数据及空数据对输出值的影响,同时加快模型的收敛速度,实现对模型异常数据处理能力的优化,使得CNN-GRU-Attention模型的预测性能相较于原模型GRU具有全面的提升。
5 结论
通过分析渔场环境因子数据来解决CPUE的逐点预测问题,结果表明,CNN-GRU-Attention模型相较于传统的渔情预测方法,预测精度及其稳定性都明显提高,从环境数据的融合处理方面为南太平洋长鳍金枪鱼渔情预测提供了一种新的思路。但本文主要分析CPUE与环境因子的空间特征数据,缺少对时间关联性的考虑,后期准备将前一年或多年的同月的渔场CPUE添加到影响因子中,并根据月份调整权值进行预测,希望能够完善渔场CPUE逐点预测模型,并提高模型的预测精度。
□
猜你喜欢
趣味(数学)(2022年3期)2022-06-02
军事文摘(2021年22期)2022-01-18
中国水产(2021年12期)2021-12-06
北京航空航天大学学报(2021年9期)2021-11-02
阅读与作文(小学高年级版)(2021年8期)2021-09-12
大自然探索(2021年12期)2021-02-07
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
当代水产(2019年4期)2019-05-16
商周刊(2018年19期)2018-12-06
