
浅析手机取证中的文本分类
2019-12-07 05:39徐红
科技与创新 2019年22期
徐红
浅析手机取证中的文本分类
徐红
(四川警察学院,四川 泸州 646000)
如今,智能手机已不只是一个通话工具,还是一个综合处理的平台,存储着大量信息。公安机关在调查取证时,有越来越多从智能手机中获取电子证据的需求,所以手机取证得到了广泛的关注和研究。对手机取证进行了简要分析,重点探讨了手机取证中的文本分类的操作流程和相关算法。
电子证据;手机取证;文本分类;分类算法
1 引言
自智能手机诞生以来,在中国逐步得到了普及应用,使用智能手机的人数不断增加,据调查数据显示,2018年中国的智能手机用户数量达到了13亿。
智能手机的广泛应用极大地改变了人们的工作和生活方式,给社会创造了新的需求,给各行各业带来了新的思维,促进了经济和社会的发展。然而,另一方面,不法分子使用智能手机进行犯罪的活动也不时发生,为了打击这类犯罪,必须进行手机取证,以获取犯罪证据。此外,公安机关在调查其他类型案件时,也常常需要通过手机取证以获得与案件相关的证据。
所谓手机取证,就是对保存在手机中和案件相关的信息进行提取,获得具有法律效力的证据。这些信息包含多种数据,例如手机通讯录、浏览器浏览记录、微信记录、地理数据、手机通话记录等等。
智能手机属于高科技产品,要想顺利开展手机取证,必须有强大的技术手段来支撑。智能手机存储容量在不断攀升,往往从中取证得到的数据量相当大,此时已不可能依靠人工进行证据的分析,而需要采用智能的方法进行证据的自动分析,而文本分类方法就是其中之一。
本文对手机取证进行简要介绍,分析相关的手机取证技术,重点探讨手机取证中涉及到的文本分类方法。
2 手机取证简介
2.1 手机取证的数据来源和种类
手机取证的数据来源主要是SIM卡和存储卡。SIM卡中存储的信息主要有手机用户数据,如通讯录、通话记录和短信息。手机固化数据,如语音加密秘钥等。存储卡中存储的信息主要有操作系统、APP、用户数据以及操作系统和APP运行产生的临时数据等。
对手机取证而言,感兴趣的数据种类主要有通话记录、短信息、QQ、微信,从中可以分析当事人社交关系;从GPS、地图中可以分析当事人的行为轨迹;从浏览器中可以分析当事人的兴趣偏好;另外还可以从短信息、QQ、微信中分析当事人的思想及行为状态。
2.2 手机取证的基本原则
手机取证必须在法律许可的条件下进行,取证过程必须恪守如下原则:①合法取证原则。对手机的取证权必须得到法律的允许;手机取证所使用的取证技术必须可靠,不得篡改和损坏手机数据;取证程序必须严格按照法律规定执行。②及时取证原则。手机上电运行就会产生新的数据,可能会造成新数据覆盖原来的数据,所以取证应及时。③全面取证原则。尽可能保证取证的数据是完整的,特别是确保重要数据的完整性。④无损取证原则。确保取证的数据维持原来的真实状态。
2.3 手机取证的工作过程
手机取证过程按美国国家标准与技术研究院(NIST)的要求可以分为下列几个阶段。
2.3.1 证据保全
证据保全阶段工作的目的是保护手机中的数据。具体操作步骤是记录当前手机的状态,如系统时间、图标、电量状况等;将手机与外部通信完全隔离,可通过将手机放入屏蔽容器等方法实现。
2.3.2 证据获取
证据获取阶段利用物理获取、逻辑获取和手工获取的方法来获得手机中的数据。物理获取通过与手机芯片直接交互提取数据;逻辑获取将手机与计算机建立连接,通过软件工具提取数据;手工获取通过人工操作手机原有的APP提取数据。其中,物理获取优于逻辑获取,而逻辑获取又优于人工获取。
2.3.3 证据分析
证据分析是手机取证的关键环节,该阶段的主要工作是对提取得到的数据进行分析,以得到有力的证据。该阶段涉及多种分析方法,文本分类就是其中之一。
2.3.4 生成报告
生成报告阶段将取证过程中的全部操作和结论进行总结并形成报告,它代表手机取证过程的完结。
3 手机取证中的文本分类简析
3.1 文本分类简介
文本分类是利用相应的算法将文本划分成不同的类别。它首先要建立训练文本集,经训练得到文本特征和类别的关系模型,然后用这个关系模型来判断待测文本的类别。
具体的文本分类操作步骤如下:①预处理。文本的形式是多种多样的,必须进行预处理。如果待分析的文本是非结构化的中文文本,这就需要进行分词和去停用词处理。②文本表示。将文本变换成计算机可理解和计算的形式——通常表示为向量,这是通过文本表示模型实现的。布尔模型、向量空间模型和概率模型是常用的文本表示模型。③文本特征提取。文本转换为计算机可理解的形式后,往往得到的向量具有较高的维数,不便于处理,需要提取最能体现文本的特征,常见的特征选择算法有信息增益、互信息和2统计量。④训练。对训练数据使用分类器进行训练,分类器常用的分类算法有贝叶斯算法、K邻近算法和支持向量机算法。⑤分类。将待分类数据完成上述处理后,输入分类器可以得到分类结果。
3.2 适用于手机取证的文本分类
不同于普通的文本分类,智能手机中的信息多以短文本为主,例如短信息、通讯录、备忘录和聊天记录等,对这样的文本进行分类时,往往面临着特征不足的问题,这会造成文本分类的效果较差。所以,对手机取证的文本进行分类,其操作步骤虽然和上述的文本分类方法相同,但是在实践操作中需要有针对性进行适应性改进。因为短文本的特征不足,改进的思路简言之就是扩展特征。将训练用的短文本进行扩展特征后,用于分类器的训练,以训练出适应于手机短文本的分类器。
对短文本扩展特征可行的做法是利用知识库来扩展特征。例如,手机取证文本只包含一两个词,可以通过知识库查找针对它们的解释,解释中的相关词汇和原词具有逻辑相关性,所以可以用这些词汇来扩展原有文本的特征。实践中知识库通常选取维基百科。得到维基百科对于手机取证文本词汇的解释文本后,将解释文本转换成向量,选取与原文本相关度最高的部分作为新增的特征项,然后和原文本生成的特征一起组成最终特征向量,进行后续的计算。
3.3 手机取证文本分类算法
构造分类器是文本分类的核心,所采用的分类算法直接决定了文本分类的效果。
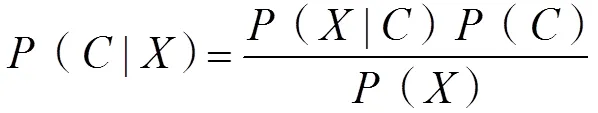
K邻近算法的思路是计算待分类文本与训练集中各文本的相似度和样本类别权重,找到个相似度最高的样本,合并属于相同类别的样本类别权重,根据权重判断待分类文本所属类别。该方法思想简单,无需事先训练样本,但是当训练集大时,计算量会很大。
支持向量机算法的思路简言之就是在样本空间中寻找最优的超平面以分隔不同类别的样本,实践表明支持向量机具有较好的分类效果。
4 结论
手机取证是获取电子证据、打击犯罪的重要手段。本文对手机取证进行了讨论,介绍了手机取证的数据来源和种类、基本原则、工作过程,重点分析了手机取证中的文本分类的操作过程和相关的分类算法。
[1]杨雪.Android手机取证技术研究综述[J].计算机时代,2015(6):7-9.
[2]秦玉梅,孙奕.智能手机取证[M].北京:清华大学出版社,2014.
[3]罗会明.Android智能手机取证研究[D].北京:北京化工大学,2013.
[4]陈德俊,丁红军.手机取证研究概述[J].中国公共安全(学术版),2012(3):100-102.
[5]刘洋洋.手机取证技术研究[J].网络安全技术与应用,2011(5):31-33.
TP391
A
10.15913/j.cnki.kjycx.2019.22.031
2095-6835(2019)22-0087-02
〔编辑:严丽琴〕
猜你喜欢
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
少儿画王(3-6岁)(2020年4期)2020-09-13
东方教育(2018年20期)2018-08-22
软件导刊(2017年4期)2017-06-20
幼儿智力世界(2016年6期)2016-05-14
祝你幸福·知心(2016年3期)2016-03-29
小雪花·初中高分作文(2015年10期)2015-10-24
微型计算机(2009年4期)2009-12-23
