
数据驱动的锂电池健康状态估算方法比较
2019-12-11 03:13白云飞
储能科学与技术 2019年6期
陈 翌,白云飞,何 瑛
(同济大学汽车学院,上海 201804)
近年来,新能源汽车市场的蓬勃发展造就了锂离子电池市场的繁荣,研究锂电池健康状态SOH预测与健康管理,对系统整体的安全性、稳定性和经济性具有重要意义[1]。
目前,锂电池SOH 估算方法主要分为三类:基于模型的估算方法、数据驱动的估算方法、基于融合法的估算方法[2]。基于模型的方法包括基于电化学模型、等效电路模型、经验模型等方法[3]。数据驱动的方法主要包括自回归模型、人工神经网络、支持向量回归和高斯过程回归,上述方法都需要大量的数据支撑来提高模型的精度[2]。由于无需考虑动力电池内部复杂的电化学反应,数据驱动法成为动力电池SOH 估计方法的热门方法。基于融合法的估计方法旨在融合多种方法,发挥各种方法的优点,是一个重要的研究方向,但当前研究成果较少。
2017 年7 月,新能源汽车国家大数据联盟在北京成立,为SOH 的估算研究提供了大量数据支撑。因此本文将重点分析比较数据驱动方法,以发现该方法在此背景下的应用价值。
1 数据驱动的估算方法综述
1.1 人工神经网络
人工神经网络(artificial neural network,ANN)是一种典型的机器学习方法。ANN 的基本特性是非线性,适合模拟动力电池,且能达到较高的精确度,但需要大量的、全面的样本数据对模型进行训练,且估计误差在很大程度上受训练数据的影响[4]。在动力电池SOH 预测研究中,BP(back propagation)神经网络、Elman 神经网络、RBF(radical basis function)神经网络应用较为广泛。
BP 神经网络典型结构如图1 所示[5]。神经网络的输入层通常是与电池健康状态相关的变量,输出层根据应用场景的不同,可能是电池直流内阻或电池容量[6]。

图1 典型BP 神经网络结构Fig.1 Typical BP neural network structure
神经网络的训练是对网络的阈值和权值进行的重复修正,由于基础的梯度下降法存在收敛速度慢、容易形成局部最小的缺点,多数研究从学习算法方面改进。黄业伟[3]应用LM(levenbergmarquardt)学习算法对神经网络权值和阈值进行训练,加快了训练收敛速度,解决了局部最小的问题,但隐含层节点很多时,LM 算法的存储需求会增大。张昊[7]使用遗传算法(genetic algorithm,GA)对神经网络的初始权值、阈值进行优化;汤露曦[8]将T-S 型模糊模型与多层前馈神经网络相结合,融合了模糊规则经验对样本的要求较低、可以利用专家知识库等优点和神经网络的自学习、自适应性等优点;肖仁鑫[6]运用蚁群算法优化了神经网络输入参数,实现了高精度的估算。
Elman 神经网络隐含层存在反馈环节,能记录以前时刻隐含层状态。韩丽等[9]建立Elman 神经网络模型,并通过遗传算法对模型中的初始权值和阈值进行优化,根据阀控铅酸电池的浅度放电的测量数据,进行了电池劣化程度的预测;刘婉晴[10]选用遗传和蚁群的混合算法对Elman 神经网络进行训练,改善了电池SOH 预测的运算速度和精度;汤露曦[8]利用 LM 学习算法对Elman 神经网络进行训练,与前文所述的T-S 型模糊神经网络算法对比发现,Elman 神经网络算法具有速度快、精度高的优势。
RBF 神经网络是一种局部逼近网络,相比于BP 神经网络,它只需要对少量权值和阈值进行修正,因此训练速度快[5]。LIN 等[11]采用概率神经网络(probabilistic neural network, PNN)的方法,对Li-Co 电池SOH 进行了估算,模型输入变量为:恒流充电时间、放电开始时电压降和开路电压;张任等[12]认为PNN 采用相同的平滑参数,识别率较低,因此利用粒子群优化(particle swarm optimization, PSO)算法来优化RBF 神经网络权值,使其有更好的非线性函数逼近能力。
在输入变量的选取方面,当前研究呈现出从定性分析转向定量选择的趋势。黄业伟、汤露曦、韩丽、刘婉晴等[3,8-10]仅通过定性分析选取了电压、电流、温度、电池内阻等参数作为神经网络输入变量;张昊、张任、刘海洋等[7,12-13]通过对实验数据进行相关性分析、敏感性分析等,科学选择了对电池健康状态有影响的关键参数。
1.2 支持向量回归
支持向量回归(support vector regression, SVR)是支持向量机(support vector machine, SVM)在回归问题上的推广。锂电池SOH 估算问题属于线性不可分问题,因此需要引入核函数将数据从低维空间映射到高维空间,转化为线性可分[14-16]。核函数选取和超参数优化关系着模型的计算量和准确性。SVR 方法所需存储空间小,适合应用于BMS[17],而且SVR 方法泛化能力强,理论基础完善,是锂电池SOH 估算领域最有效的方法之一;但SVR 模型在处理大样本数据集时,不具备速度优势[18],核函数必须满足mercer 条件,且稀疏性不足,不能给出估计结果的置信区间[19]。
为了解决SVR 模型中的超参数优化问题,刘皓等[20]提出一种结合遗传算法和SVR(genetic algorithm-support vector regression,GA-SVR)的锂电池 SOH 预测算法,利用GA 算法进行参数寻优;卢明哲[18]从电池的实验室充放电循环数据出发,采用C-SVR 算法估计了电池的健康状态;孙猛猛[17]基于锂离子电池部分恒流充电数据和SVM方法估算SOH,为解决SVM 处理大量数据速度慢的问题,又挖掘了可以描述电池SOH 老化的局部放电电压曲线,建立了LS-SVM(least squares support vector machine)模型,为获得模型稀疏性,最后建立了fixed size LS-SVM 模型;ADNAN NUHIC 等[21]基于真实行驶数据,应用SVR 算法实现了SOH 估算;WENG 等[22]基于部分充电数据,通过增量容量分析识别出与电池老化相关的可靠特征,并采用SVR 方法实现了SOH 的实时估算。
SVR 模型输入特征变量的选取,呈现出与神经网络方法类似的趋势。少量研究仍将直接测量量作为特征变量[20],最近的文献则通过数据分析,挖掘出更能反映电池健康状态的特征参数[14-15],其中容量增量分析法应用最为广泛[16,22]。
1.3 高斯过程回归
高斯过程回归(gaussian process regression,GPR)适于处理高维数、小样本和非线性等复杂回归问题,与NN 和SVR 相比,该方法具有容易实现、超参数自适应获取以及输出具有置信区间等优点[23]。然而GPR 方法在处理大数据集时,存在计算量大和无法实时更新预测模型的缺点。
卢明哲[18]从电池的实验室充放电循环数据出发,采用SVM 和GPR 两种方法估计了电池的健康状态,结果表明,GPR 方法能够更加准确地预测出电池的健康状态,同时能够给出估计结果的置信区间;何晶[24]采用标准GPR、稀疏伪输入法、迭代GPR 进行建模,并就时间复杂度和预测精度进行比较。结果表明:相比于稀疏伪输入法,迭代GPR 具有更高的精度,相比于标准GPR,迭代GPR 能在保证精度的前提下,有效减少回归预测时间,并在新样本加入时实时更新模型;刘大同等[25]为解决SOH 的长远预测问题,应用了GPFR(gaussian process functional regression)算法进行预测,考虑到电池自充电现象对剩余有效寿命预测的影响,提出了综合协方差函数和均值函数的LGPFR(GPFR with linear mean function)方法来进行SOH 估算;周頔等[26]基于充电片段数据,采用扩展卡尔曼滤波和GPR 等机器学习算法进行电动汽车全充时间估算和容量估算,进而估算了电池实时SOH。
综上所述,三种数据驱动方法的标准方法在计算量、准确性、概率意义方面各有优缺点,定性比较结果如表1 所示。

表1 数据驱动方法定性比较Table 1 Qualitative comparison of data driven methods
此外,数据驱动方法输入特征的选取都呈现出从定性分析转向定量选择的趋势。当前电池健康状态研究多数是基于实验条件锂电池的循环数据[3,17-18],实验条件包括:恒温、恒流放电、完全充放电等,而电动汽车实际行驶中,环境温度、放电电流具有波动性,且很少完全充放电;为此,部分研究将电池置于标准工况下循环[10,27],而这种加速循环的方法没有考虑到电池存储中的健康状态衰退,因此当前SOH 估算研究的实用性还有待提高。
2 数据驱动的估算方法定量比较
2016 年 10 月 1 日开始实行的 GB/T 32960.1 要求车载终端应按照GB/T 32960.2 的要求,从车辆上采集整车及各个部件的数据,参数范围至少要包含GB/T 32960.3 的要求,并将数据发送到企业平台。本部分将基于该数据,进行数据预处理和建模分析,以对上文所述3 种数据驱动方法进行定量比较。
2.1 数据特征提取
本节将基于2018 年全国高校新能源汽车大数据创新创业大赛(下文简称双创大赛)所提供的数据,通过提取行驶片段、相关性分析来提取特征变量。
数据样本空间为北京、上海、广州的个人乘用车、出租乘用车、公交客车、物流特种车四类车各50 辆,在一个月内的车辆实时数据。数据采样频率为0.1 Hz,包括整车数据、极值数据、报警数据等,根据电池SOH 影响因素的定性分析,这里选取总电压、总电流、SOC、最高温度值、最低温度值几个变量举例呈现,如表2 所示。

表2 上-租-49 车辆实时数据Table 2 Vehicle real-time data of Shanghai-taxi-49
根据该数据字段描述,DC-DC 数据为1 和2分别表示DC-DC 工作和断开。通过DC-DC 状态准确判断车辆在充放电还是停车熄火,进而依据电池SOC 上下波动的趋势,区分出车辆放电和充电过程。据此提取了该出租车一个月内的充电过程片段。
然而数据中没有给出准确的电池容量或电池内阻,作为模型的目标输出。充电过程数据包含了每隔10 s 的总电压、总电流,对离散数据进行积分可以计算各充电片段的充电能量E,又考虑到基于电池容量的SOH 定义未能反映电池额定电压的衰退,本文提出利用电池满充能量表征电池健康状态,如式(1)所示

其中,E0为出厂时电池满充能量,Et为当前电池满充能量。
由于电池容量与电池能量线性相关,因此可以利用SOC 计算各片段对应的满充能量,如式(2)所示

其中,Ei为第i个片段充电能量,SOCstart和SOCend分别是起止SOC。
所以本文将各充电片段的充电能量作为模型的目标变量。积分计算公式如式(3)所示。
脑卒中是中老年人的常见病、多发病,大部分患者会遗留不同程度的功能障碍, 偏瘫上肢活动障碍对患者生活质量影响很大[1]。上肢在皮层中占的比例大,受损后脑功能重组难度大,偏瘫上肢常呈屈曲痉挛模式、手抓握状畸形、肩手综合症等是康复难题,临床上常予以肩部悬吊、肌内效贴、磁热疗法、针灸、神经肌肉电刺激等进行对症处理,但效果欠佳。因此,进一步探索新的康复治疗方法,更好地改善偏瘫患者上肢功能,具有十分重要的意义。本研究对脑卒中偏瘫上肢运用新Bobath技术治疗脑卒中偏瘫患者,疗效较好,报道如下。

最终有效片段有32 段,如表3 所示。
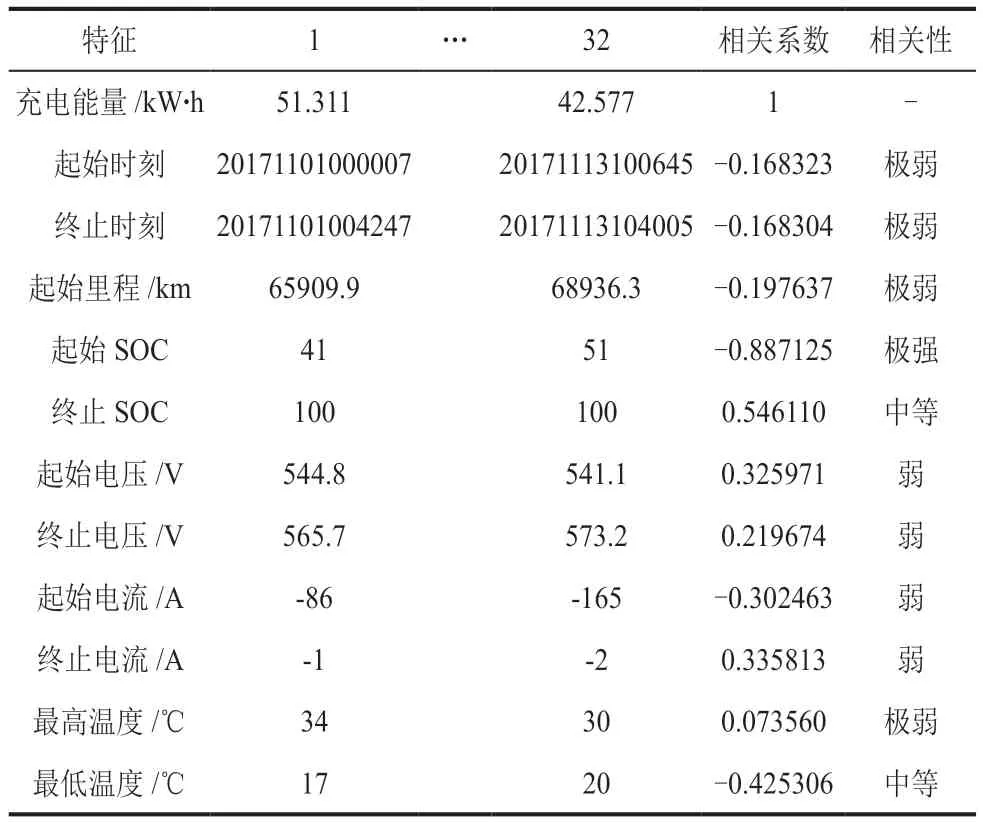
表3 上-租-49 充电片段Table 3 charging clip of Shanghai-taxi-49
本文采用Pandas 库的函数,来获取初选的特征变量与充电能量的Pearson 相关系数,结果如表3 所示。由相关性分析结果,下节将选用起始SOC、终止SOC、起始电压、终止电压、起始电流、终止电流、最低温度作为数据驱动方法的输入特征。
2.2 数据驱动方法的实现
本文针对双创大赛创新组数据分别采用了BP神经网络、SVR、GPR 等三种方法进行建模分析。该数据包含一辆车2017 年11 月1 日到2018 年7月12 日间有666 个充电片段数据,格式与表3 相同。对上述数据进行了min-max 归一化,便于后续模型训练。
2.2.1 神经网络
本文基于Tensorflow 框架搭建了BP 神经网络,在反向传播过程中训练参数,而后喂入测试集数据进行预测。具体来讲,前向传播过程搭建的BP 神经网络结构为7×3×1,输入特征包括7 个变量,故输入层节点数为7,充电能量为唯一训练目标,故输出层节点数为1,隐藏层节点数由经验公式(4)结合试验确定为3。

其中,m为隐含层节点数;n为输入层节点数;l为输出层节点数;α为1 ~10 间的常数。
由于数据集较小,要注意避免模型过拟合,因此在反向传播过程中,本文将均方误差MSE(mean square error)作为损失函数,并引入正则化;采用指数衰减学习率,Adam 优化器训练神经网络参数;使用滑动平均以增加模型泛化性;设置目标MSE为0.0005,以提前结束训练。
本文采用数据集的90%进行训练,BP 神经网络反向传播过程耗时约12.3 秒。训练过程中的MSE 变化如图2 所示。

图2 NN 训练过程中MSE 变化曲线Fig.2 MSE curve during NN training
利用剩下10%的数据测试,耗时约395 毫秒,预测结果MSE 为0.000692。模型预测值与真实值如图3 所示。

图3 NN 预测值与真实值Fig.3 NN prediction and true value
2.2.2 支持向量回归
Sklearn(scikit-learn) 是一个非常优秀的Python 库,它封装了机器学习中常用的算法。本文基于 Sklearn 库 API(application programming interface),通过交叉验证和网格搜索进行参数寻优,并据此建立SVR 预测模型。具体来讲,首先定义参数字典,包含了rbf、linear、sigmoid、poly 等核函数及其对应的待优化参数;接着实例化Gridsearch CV 对象,将均方误差作为评价标准,采用5 折交叉验证,基于训练集数据对参数字典进行网格搜索,得到的最佳参数组合是: Sigmoid 核函数惩罚参数C=100,核函数参数gamma=0.1。最后采用最佳参数组合建立SVR 模型,对训练集和测试集数据进行拟合与预测。训练集拟合耗时约3.9 秒,MSE 变化趋势如图4 所示。

图4 SVR 拟合过程中MSE 变化曲线Fig.4 MSE curve during SVR fitting
测试集预测结果如图5 所示,预测耗时约59.7微秒,MSE 为0.001484。

图5 SVR 预测值与真实值Fig.5 SVR prediction and true value
2.2.3 高斯过程回归
本文基于Sklearn 库中的gaussian process regressor对象实例化GPR 模型。该对象支持多种核函数及其组合;依次试验结果如表4 所示,选用RBF+WhiteKernel 组合核函数的模型预测MSE 最小。
实例化GPR 模型中,使用默认优化器优化核函数超参数,并设置n_starts_optimizer=10,10 次重复优化过程,以寻求全局最优超参数。接着将该模型拟合训练集数据,耗时约10.3 秒,拟合过程中MSE 变化趋势如图6 所示。

表4 核函数性能对比Table 4 Kernel functions performance comparison

图6 GPR 拟合过程中MSE 变化曲线Fig.6 MSE curve during GPR fitting
拟合完成后,模型对测试集预测结果如图7 所示,真实值基本被包含在预测结果95%置信区间中。预测耗时约2.35 毫秒,MSE 为0.000152。
本节分别用BP 神经网络、SVR、GPR 方法对充电能量进行了预测,记录了各种方法的耗时和MSE,总结如表5 所示。
从表5 可知,在本文试验条件下,SVR 方法在速度上有显著优势,BP 神经网络和GPR 方法精确度较高。当数据规模更大时,各种方法的性能优劣仍有待探索。

表5 数据驱动方法预测性能对比Table 5 Data driven methods predictive performance comparison
本部分基于新能源汽车大数据和三种数据驱动方法对动力电池充电能量进行了预测,预测结果验证了三种方法在运算量和精确度方面的特点。该结论也表明,数据驱动方法与新能源汽车大数据在动力电池SOH 估算研究中有广阔的应用前景。
3 结 论
(1)本文对3 种主流数据驱动方法进行了定性和定量的比较,总结了它们在速度、通用性、精度、有无置信区间上的特点。
(2)为了将随电池衰退而降低的额定电压体现在SOH 中,本文提出采用电池满充能量定义电池健康状态。
(3)数据驱动方法和新能源汽车大数据在动力电池SOH 估算研究领域具有广阔的应用前景。
猜你喜欢
今日农业(2022年14期)2022-09-15
军事文摘(2022年14期)2022-08-26
汽车实用技术(2022年7期)2022-04-20
科学大众(2021年21期)2022-01-18
小学科学(学生版)(2021年12期)2021-12-31
房地产导刊(2020年11期)2020-12-28
电子制作(2019年19期)2019-11-23
铁道通信信号(2019年4期)2019-10-10
电子制作(2019年24期)2019-02-23
通信电源技术(2016年1期)2016-04-16
