
基于模糊粗糙最近邻算法的不平衡数据分类
2020-01-05 07:00章春梅
软件导刊 2020年11期
关键词:分类器


摘 要:为了提升不平衡数据中少数类的分类精度,利用SMOTE采样方法对数据集进行平衡化预处理;为了减轻样本重新合成过程中产生的类重叠和噪声对分类精度的影响,选择模糊粗糙最近邻算法(FRNN)作为分类器。在14个不平衡数据集上进行的仿真实验表明,该方法具有较好的分类表现,F值和G值最高分别可达0.965、0.932,是一种适用于不平衡率偏高数据集的分类方法。
关键词:不平衡数据;分类器;SMOTE;模糊粗糙最近邻算法
DOI:10. 11907/rjdk. 201674
中图分类号:TP301 文献标识码:A 文章编号:1672-7800(2020)011-0037-05
A Classification Method for Imbalanced Data Based on
Fuzzy Rough Nearest Neighbor
ZHANG Chun-mei
(Institute of Artificial Intelligence, Nanjing Vocational College of Information Technology, Nanjing 210023,China)
Abstract: In order to improve the classification accuracy of the minority classes in imbalanced data, the paper employs synthetic minority over - sampling technique(SMOTE) to balance data set firstly. Considering that the process of sample re-synthesis always leads to some noises such as class overlapping, fuzzy rough neareswast neighbor algorithm (FRNN) is selected as the classifier to alleviate the effect of noise. Classification experiment conducted on 14 unbalanced data sets shows that the proposed method performs well, and the F value and G value can reach 0.965 and 0.932 respectively. It reveals that the proposed method is suitable for the classification on data sets with high imbalance rate.
Key Words: imbalanced data; classifier;SMOTE;fuzzy rough nearest neighbor algorithm
0 引言
在机器学习和数据挖掘领域,不平衡数据分类受到研究者的广泛关注。与一般意义上的数据分类不同,本文研究的不平衡分类更看重整体中的个别:少数类的分类准确率。同时,在异常检测[1]、市场行情判断[2]、精准医疗[3]等诸多数据分析实际应用中,重要的决策信息往往蕴藏在少数类样本中。因此,对这些样本进行正确地判断归类更具实际价值。
SMOTE(Synthetic Minority Over-sampling Technique)[4]及其衍生方法[5-10]是一种被广泛使用的改善数据不平衡分布的重采样方法,其基本思想是对少数类样本进行过采样,并在此基础上合成新的样本。与其它方法相比, SMOTE对数据的预处理更为有效, 因而引起研究者的广泛兴趣。SMOTE这类方法的不足之处在于新样本的合成过程中会产生样本重叠和噪声。模糊粗糙最近邻(Fuzzy Rough Nearest Neighbor,FRNN)[11-13]是一种在特征不完备数据集上有良好分类性能的算法,该算法能有效减少重叠和噪声对分类的影响。在实际数据中,不仅存在不平衡现象,而且存在属性不足问题,即数据集本身具有粗糙性[14]。因此,将这两类方法相结合实现不平衡数据分类颇具意义。
1 不平衡問题产生的原因
不平衡问题产生的主要原因是类与类之间的样本数量不均衡,某个类的样本数量明显少于其它类样本数量。一般而言,高的总体分类精度是各种经典以及衍生分类模型的追逐目标,在这种目标驱动下,训练模型将着重去拟合多数类样本,势必导致分类器在少数类样本上的分类性能下降。一个大家熟知的例子是:对于一个不平衡率为 99∶1的数据集而言,分类器在将少数类样本完全误判为多数类的情况下,所获总体分类精度仍然很高,为99%,而此时少数类样本的错分率却是100%。此外,相关研究也指出,在某类样本中间由于存在样本重叠现象,也可能导致一种不平衡,称之为类内不平衡[15]。类内不平衡现象也是造成分类器性能下降、泛化能力减弱的一个原因。
2 不平衡问题处理办法
不平衡数据分类性能提升方法主要有两种:数据层面和算法层面。数据层面就是改善数据分布,使数据重新趋于平衡,主要是重新采样技术;算法层面是优化分类算法,关注点是提高算法在少数类上的分类精度。
2.1 数据层面
重采样技术是处理不平衡数据分类的一类主要技术,重采样是对训练样本集中多数类样本采用欠采样方法,对训练样本集中少数类样本采用过采样方法,从而达到提高训练样本类分布均衡程度的目的,是当前提高不平衡数据分类器性能的一种有效途径。其中,欠采样技术基本思想是删除部分多数类样本,故而会造成分类信息丢失;过采样技术主要是增加少数类样本,原始分类信息能够得到较好保留。因此,在某些对各类样本分类准确率均要求较高的领域,通常选择过采样技术[16]。
5.2 評价指标
考虑不平衡数据集上的二分类问题:设P为少数类,N 代表多数类,FP代表多数类样本错分数目;FN指少数类样本错分数目;FP和TN分别表示少数类和多数类样本被正确分类的数目。如式(18)—式(22)所示,TPR为少数类样本正确率(或称召回率);TNR为多数类样本正确率;Precision为少数类分类精度;G为几何平均正确率;F是少数类样本正确率和分类精度的调和均值。
G和F是两个常用不平衡数据分类性能的评价标准,指标G综合考虑了少数类和多数类两类样本的分类性能,F能全面反映分类器性能[19]。由式(22)可以看出,只有Precision和TPR同步增大时,F才会相应增大,非常适合评价不平衡数据分类质量。
5.3 结果分析
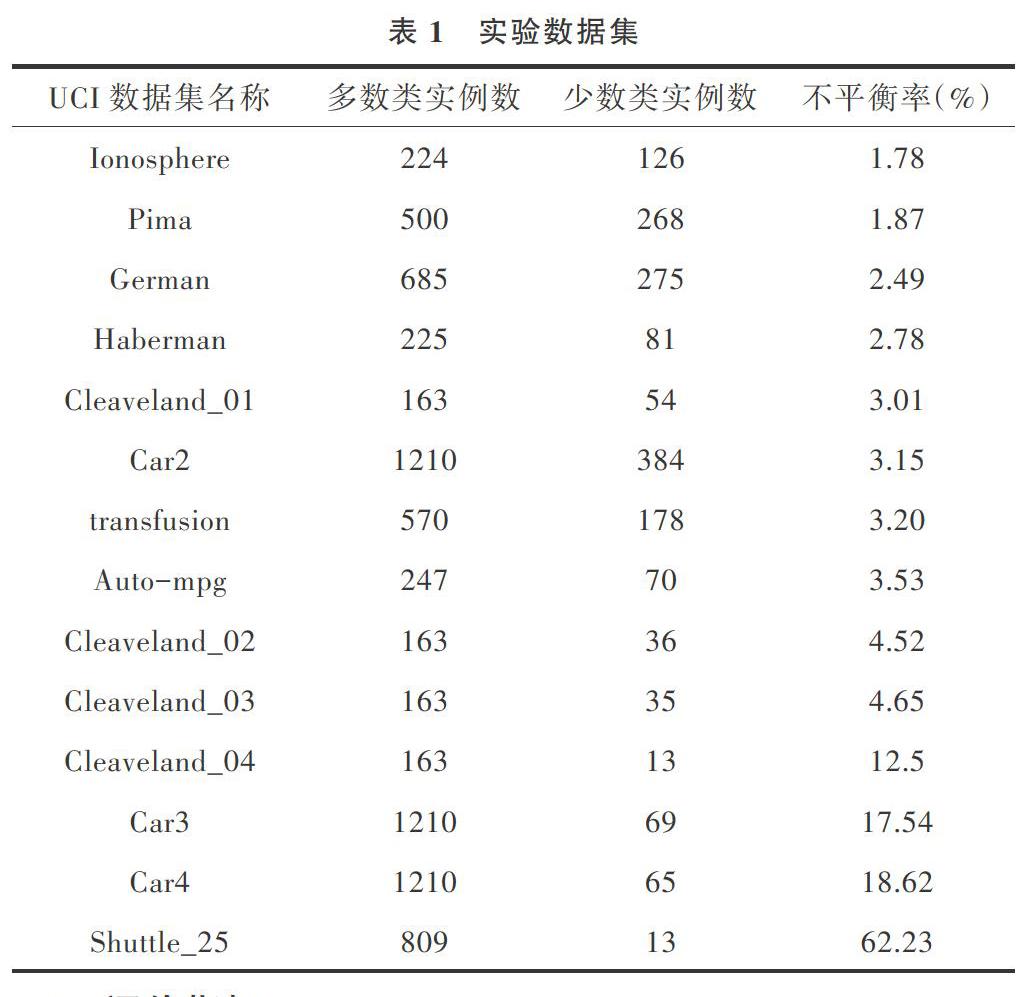
本文在Win10平台下采用Eclipse 4.13,实现了EUSBOOST、HDDT+Bagging及SMOTE+FRNN 3种算法。其中,前两种是颇具有代表性算法,每种算法在各数据集上运行10次,取G和F值的平均结果作比较,如表2、表3所示。
综合表2、表3数据发现,在对不平衡数据集中的少数样本进行分类时,相比其它已有方法,本文方法分类精度更高,且数据集不平衡率越高,分类优势越明显。据此可以认为,在不平衡数据分类问题上,先使用SMOTE方法作预处理,再使用FRNN算法进行分类确实是一种有效的组合方案,值得进一步研究。
6 结语
在不平衡数据分类问题上,将重采样技术和分类算法结合使用不是一个新的研究课题,已出现了很多有价值的研究文献,文献中的方法在实验中也取得了较好效果。开展这类尝试性研究的关键是要在掌握有关方法内在机理的基础上,有针对性地进行选取并优化组合,而不是为了组合而组合。真实数据中往往不仅存在不平衡现象,往往还伴有重叠和噪声,其中的属性特征也经常不完整。FRNN算法既可以对属性不足的数据进行分类,又能有效地对抗样本重叠和噪声。该方法的不足就在于它对于所有类的关注是等同的,缺乏将多数类和少数类区别处理的机制,因此在对不平衡数据分类问题上,它与SMOTE方法具有明显契合性,这也是本文研究的立足点所在。本文目前关注的仅是不平衡数据二分类问题,在多分类问题上还未作进一步研究。此外,减小FRNN算法计算开销也是需考虑的问题。
参考文献:
[1] LUO M,WANG K,CAI Z,et al.Using imbalanced triangle synthetic data for machine learning anomaly detection[J]. Computers,Materials & Continua,2019,58(1):15-26.
[2] CAHYA R A,BACHTIAR F A. Weakening feature independence of na?ve bayes using feature weighting and selection on imbalanced customer review data[C]. The 5th International Conference on Science in Information Technology(ICSITech),2019:182-187.
[3] 陈旭,刘鹏鹤,孙毓忠,等. 基于不平衡医疗数据集的疾病预测模型研究[J]. 计算机学报,2019,42(3):596-609.
[4] FERNANDEZ A,GARCIA S,CHAWLA N V,et al. SMOTE for learning from imbalanced data: progress and challenges, marking the 15-year anniversary[J]. Journal of Artificial Intelligence Research,2018,61:863-905.
[5] GEORGIOS D,FERNANDO B,FELIX L. Improving imbalanced learning through a heuristic oversampling method based on k-means and SMOTE[J]. Information Sciences,2018,465:1-20.
[6] DOUZAS G,BACAO F,LAST F.Improving imbalanced learning through a heuristic oversampling method based on k-means and SMOTE[J]. Information sciences,2018,465:1-20.
[7] DOUZAS G,BACAO F. Geometric SMOTE a geometrically enhanced drop-in replacement for SMOTE[J]. Information sciences,2019,501:118-135.
[8] QI W,ZHIHAO L,JINCAI H,et al.A Novel ensemble method for imbalanced data learning: bagging of extrapolation-SMOTE SVM[J]. Computational Intelligence & Neuroence,2017:1827016.
[9] MA L,FAN S.CURE-SMOTE algorithm and hybrid algorithm for feature selection and parameter optimization based on random forests[J]. BMC Bioinformatics,2017,18(1):1-18.
[10] GONG C,GU L.A Novel SMOTE-Based classification approach to online data imbalance problem[J]. Mathematical Problems in Engineering,2016(5):1-14.
[11] JENSEN R,CORNELIS C. Fuzzy rough nearest neighbour classification and prediction[J]. Theoretical Computer Science,2011,412(42):5871-5884.
[12] JENSEN R,CORNELIS C.Fuzzy-rough nearest neighbor classification[M]. Berlin: Springer Berlin Heidelberg,2011.
[13] SARKAR M. Fuzzy-rough nearest neighbor algorithms in classification[J]. Fuzzy Sets and Systems,2007,158(19):2134-2152.
[14] 何力,卢冰原. 基于EM 的模糊-粗糙集最近邻算法[J]. 计算机工程,2010,36(24):136-138.
[15] 陶新民,郝思媛,张冬雪,等. 不均衡数据分类算法的综述[J]. 重庆邮电大学学报( 自然科学版), 2013,25(1): 101-121.
[16] 王超学,张涛,马春森. 面向不平衡数据集的改进型SMOTE算法[J]. 计算机科学与探索,2014,8(6):727-734.
[17] 刘余霞,刘三民,刘涛,等. 一种新的过采样算法DB_SMOTE[J]. 计算机工程与应用,2014,50(6):92-95.
[18] ENISLAY R,SARAH V,NELE V,et al.IFROWANN:Imbalanced fuzzy-rough ordered weighted average nearest neighbor classification[J]. IEEE Transactions on Fuzzy Systems,2014(99):1-15.
[19] LEE Y H,HU P J H,CHENG T H,et al. A preclustering-based ensemble learning technique for acute appendicitis diagnoses[J]. Artificial Intelligence in Medicine,2013,58(2):115-12.
(责任编辑:孙 娟)
收稿日期:2020-07-09
作者簡介:章春梅(1979-),女,硕士,南京信息职业技术学院人工智能学院讲师,研究方向为网络应用程序开发、数据挖掘。
猜你喜欢
电子测试(2018年1期)2018-04-18
计算机应用(2017年4期)2017-06-27
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
计算机工程与科学(2015年1期)2015-04-01
电子世界(2014年12期)2014-10-21
航天返回与遥感(2014年5期)2014-07-31
电测与仪表(2014年18期)2014-04-04
电测与仪表(2014年15期)2014-04-04
中原工学院学报(2014年4期)2014-04-01
