
分布式主题舆情采集与分析系统设计
2020-01-05 07:00董富江张文学
软件导刊 2020年11期
董富江 张文学


摘 要:在大数据和移动互联网的时代背景下,舆情信息的迅猛增长为其采集与分析带来挑战。运用分布式计算技术,有利于对领域海量主题舆情的快速采集与分析。研究主题舆情采集与分析关键技术,包括主题舆情采集技术、领域词典和中文分词,探讨分布式计算环境下的主题舆情采集与舆情数据分析,并利用面向对象的分析与设计方法,基于开源爬虫设计并实现了一个分布式主题舆情采集与分析系统。利用4个爬虫节点进行分布式采集,相比传统采集模式,该系统的平均采集速度提升了2.74倍。
关键词:分布式;主题舆情;信息采集;开源爬虫
DOI:10. 11907/rjdk. 201708 开放科学(资源服务)标识码(OSID):
中图分类号:TP319 文献标识码:A 文章编号:1672-7800(2020)011-0116-04
The Design of a Distributed Subject Public Opinion Collection and Analysis System
DONG Fu-jiang,ZHANG Wen-xue
(College of Science,Ningxia Medical University,Yinchuan 750004,China)
Abstract: In the era of big data and mobile Internet, the rapid growth of public opinion information brings challenges to its collection and analysis, and the design of distributed subject public opinion collection and analysis system is conducive to the rapid collection and analysis of mass subject public opinion information. The key technologies of subject public opinion collection and analysis are studied, including subject public opinion collection, field dictionary and segmentation of Chinese word. The collection and analysis technology of subject public opinion in distributed computing environment is discussed.A distributed subject public opinion collection and analysis system based on open source crawler is designed and implemented by object-oriented analysis and design method. Four crawler nodes are used for distributed collection, and the average collection speed is improved by 2.74 times compared with the single-machine collection mode.
Key Words:distributed; subject public opinion; information collection; open source crawler
0 引言
在大數据与移动互联网蓬勃发展的时代背景下,网络舆情具有传播迅速、快速裂变、纷繁复杂等特点,对这些网络舆情进行有效的管理、控制与引导,避免酿成不良网络舆情事件,对于保障社会稳定具有重要意义。借助于舆情监控平台,可帮助相关部门或行业对互联网舆情信息进行跟踪、分析与管理[1-2]。设计面向各政府部门或行业的主题网络舆情信息采集与分析系统,如医疗[3-4]、疫情[5]、食品安全[6]等领域,可辅助政府部门或企业及时获取所需的舆情信息[7-12],为进一步舆情管理与决策奠定基础。当前互联网上的舆情信息飞速增长,呈现海量性特点,给传统的舆情采集与分析带来极大挑战[13-14]。运用分布式技术,可提高对大规模主题舆情信息的采集、分析与处理效率。
1 主题舆情采集与分析关键技术
1.1 主题网络舆情采集
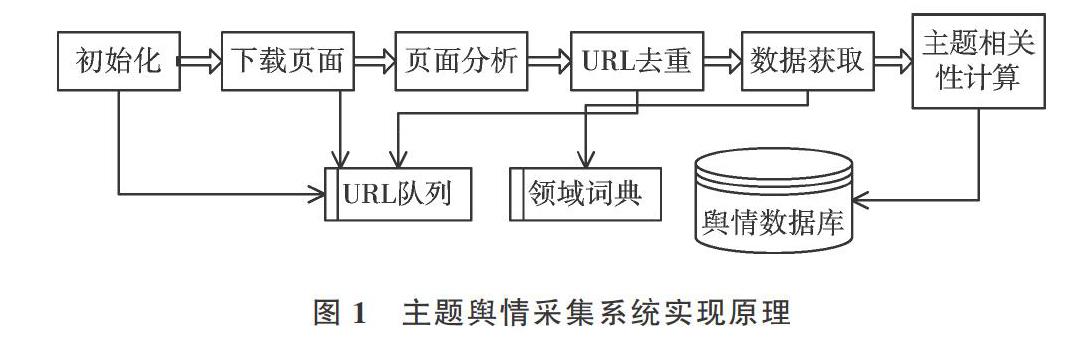
广义的主题网络舆情采集是指针对特定领域或特定行业的舆情信息采集,如药品安全舆情采集等;狭义的主题网络舆情采集是指采集某领域关于某个或某些事件的舆情信息,如针对某个城市新冠肺炎疫情防控的舆情信息采集等。基于开源通用网络爬虫如Nutch、WebCollector、Scrapy等构建主题爬虫系统,是主题舆情采集系统的低成本设计与实现方案。主题舆情采集系统具体实现原理如图1所示。
在图1中,方框代表采集系统的模块,粗线箭头代表系统流程,细线箭头代表模块对数据的应用。初始化模块用于设置要采集的舆情信息主题或者输入主题词,设置种子链接列表;网页下载模块在初始化完成后,从种子链接开始,利用爬取算法对页面进行下载;页面分析模块可对网页下载模块获取到的网页进行解析,提取出页面中的链接与文本内容;URL去重模块用于过滤重复网页,若判断当前页面已存在于URL队列中,则不进行存储;数据获取模块采用某种算法从Web页面中抽取所需数据;主题相关性计算模块是系统的关键模块,其根据设计好的算法计算当前页面与给定主题的相关性,若相关则进行保存,否则予以丢弃。URL队列采取FIFO方式存储待下载的页面链接,领域词典保存面向特定主题的词汇,支撑中文分词与数据获取。
1.2 关键词提取
主题舆情采集方法之一是利用基于主题词的方法,在采集时由人工输入一个或多个主题词,主题相关性计算模块首先提取网页上的文本关键词,然后匹配输入的主题词及网页关键词。若匹配成功,说明网页是主题网页,系统保存该网页的舆情数据。系统设计采用TF-IDF算法,其思想是若某词语在某文本中出现次数相对较多,但在其余文本中出现次数相对较少,则该词语为关键词[15]。
1.3 主题向量
采用主题自动生成方法,在系统运行前利用一些人工采集的主题页面,经过机器学习算法如LDA[16]学习得到用向量模式表示的特定主题,对页面进行下载与处理后也表示成向量空间模型,之后系统利用设计好的相关性计算算法比较主题向量与页面主题。若计算结果大于设定阈值,则判定该页面为面向特定主题的页面,系统将从该页面提取的数据作为主题舆情进行保存。由于移动互联网时代信息增长迅速,新的网络语言和网络词汇不断涌现,将导致系统采集性能下降,所以可利用系统采集的数据定期重新计算主题向量。为提高计算效率,可利用之前采集数据时所得的主题相关度高的页面进行计算,或随机抽取一些主题页面进行计算。
1.4 中文分词与领域词典
中文分词模块是数据获取模块的重要组成部分。若要下载的页面中含有中文信息,提取所需数据前须对页面中的文本进行中文分词处理,将中文文本拆分为中文词语序列。中文分词和领域词典维护流程如图2所示。分词模块使用领域词典将中文文本分解为词语构成的列表。去停用词模块使用停用词表去除词语集合中诸如“a,the”和“啊,了”等出现频率高,但信息含量很低的词。
中文分词词典对于分词精度有着重要影响,面向特定主题的领域词典能进一步提高主题舆情采集系统的分词精度及系统处理性能。在构建系统时设计词典调整模块,该模块能够采用自动统计方法向词典中加入新词汇。在系统运行初期可采用通用分词词典,随着系统的运行,词典调整模块能够自动增加词汇,从而进一步提升主题舆情采集精度。
2 分布式技术应用
分布式技术思想是先将分布式计算系统部署在一些廉价计算设备上,然后将大型计算项目分解成许多小的计算任务,再把这些任务分配到廉价计算设施上进行计算,待各个小任务处理完成后进行结果合并,即得到所需的计算结果。因此,将分布式技术运用于主题舆情采集,从理论上而言,可提高对于大量主题舆情数据的采集与分析效率。
2.1 分布式主题舆情采集
分布式主题舆情采集使用分布式爬虫系统,采用基于局域网的主从模式[17]。该模式利用一台机器作为Master,负责管理各爬虫节点,并分配任务。因为各爬虫运行在同一局域网中,爬虫之间以及爬虫与控制节点之间通信效率较高。在该模式下,爬虫节点之间甚至无需进行通讯。系统实现的分布式主题爬虫架构如图3所示。
架构中SpiderMaster指任务中央控制节点,由Master启动,其功能是将任务分解、分配给SpiderWorker;SpiderWorker指爬虫节点,由Worker启动,负责舆情采集工作,SpiderWorker功能如1.1节所述;URL队列用来保存待爬取的链接,可采用Key-Value数据库实现;舆情数据库可采用文件数据库,用来存放采集的主题舆情数据。
2.2 分布式舆情分析
舆情分析包括主题相关度分析、热点分析、焦点分析和情感分析等[18]。主题关注度是指在已逝去的某时段内,某舆情主题被大家所关注的水平,通常用与该主题相关的页面数量进行度量。热点是指在已逝去的某时段内被集中关注的舆情主题。热点计算方法为:首先计算某舆情主题关注度,其次比较该关注度与事先设定的某个阈值,若该关注度大于等于该阈值,则此主题舆情为热点,否则不是热点。焦点是指在已逝去的某时段内被各类媒体报道频次较高的舆情信息。焦点计算方法为:首先计算某主题舆情在某时间间隔的焦度,接下来判断计算得到的焦度与事先设定好的焦度阈值的关系,若焦度大于等于阈值,则该舆情信息为舆情焦点,否则不是舆情焦点。舆情信息焦度等于时间间隔两端点处与该主题舆情相关的网页数之差。由舆情分析的描述可知,针对海量舆情信息进行舆情分析,使用分布式技术可加快舆情分析速度。基于分布式技术的舆情分析如图4所示。
以焦度计算为例,可以先在各个节点上计算舆情信息N的焦度,然后對从这些节点上计算得到的焦度进行综合,即可得到该舆情信息在整个网络上的焦度。
3 系统设计与实现
3.1 系统分析与设计
主题舆情采集系统首先能够从各大门户网站、微博、论坛等平台及时、准确、全面地抓取与特定主题有关的页面,接下来对抓取的页面进行信息提取,然后进行分词,最后对得到的数据进行主题相关性计算,如果主题相关则存储到舆情数据库中。系统应具备以下功能:①舆情主题生成。利用人工采集的主题网页或舆情数据库中的数据,通过分析与计算得到舆情主题向量;②领域词库自动维护。基于通用词库,通过系统的运行生成与完善领域词典;③主题舆情采集。通过分布式主题网络舆情采集爬虫获取主题舆情数据,并保存在舆情数据库中;④舆情分析。利用采集的舆情数据进行舆情热点、焦点计算及情感分析等。
为了便于系统日后维护,采用面向对象技术进行系统分析与设计。在需求分析完成后构建系统用例,之后画出系统的分析类图和设计类图,使用序列图描述系统活动,最后基于开源爬虫实现系统。主题舆情采集模块设计类图如图5所示。
舆情管理类OpinionManager通过爬虫类Spider进行页面下载、分析与分词;Opinions是舆情集合类,与舆情类Opinion之间是聚合关系;页面类Page可进行关键词提取与中文分词;舆情类Opinion进行主题相关性计算与舆情信息保存;舆情管理类OpinionManager借助于舆情集合类Opinions进行舆情数据分析。
3.2 舆情数据库设计
MongoDB适合于分布式环境下数据的快速存储[19]。MongoDB是一个基于分布式文件存储的NoSQL数据库,其中的数据库(database) 概念对应关系型数据库中的模式(schema),集合(colloction)对应表(Table),文档(document)对应行(row) [20]。为便于大量主题舆情数据在分布环境下存储,采用MongoDB数据库。为提高检索速度、提升系统性能,将不同类型页面对应的舆情数据保存在不同的舆情数据集合中。以微博舆情信息采集为例,微博舆情数据集合如下:
……
{ “NID”:1,
“Owner”:“owner1”,
“keyWords”:[{“name”:“新冠”,“fre”:3},{“name”:“药” ,“fre”:3 }]
“Text”:“俄罗斯批准使用法维拉韦。……”,
“Url”:“https://weibo.com/owner1?refer_flag=1005055013_& is_all=1”,
……
}
……
以上集合显示了一个文档,该文档表示编号为1的舆情信息。该舆情信息对应页面的博主为“Owner1”,舆情采集系统分析出的关键词“新冠”在页面中出现了3次。文档还存储了微博正文信息和页面的URL。
3.3 系统实现与运行
基于Nutch实现分布式网络爬虫是可行的[21]。分布式主题舆情采集系统实现原理如图6所示,其基于Nutch2.3。利用爬虫抓取页面并提取结构化信息后,再经过分词和主题相关性计算实现主题舆情采集。任务数据库(队列)基于Key-Value数据库Redis实现,可将所有爬虫需要爬取的URL队列和已爬取的URL队列放在共享的URL数据库中。爬虫节点从该共享队列中按需取出URL进行爬取,已爬取过的页面不会重复爬取[22]。
采用图6所示的方法对Parse模块进行扩展、改造,使其具有主题相关性计算功能。若解析得到的数据与主题相关,则将其存入舆情数据库,并继续利用从该页面解析得到的URL继续进行深度爬行,否则仅进行深度爬行。该方法的数据提取、主题相关性计算是在线进行的,即边下载网页边计算其主题相关性,下载花费时间较长,且不利于利用网络拥堵低峰期,因此完成采集任务所需时间较长。如果经过主题相关性计算后发现页面不是主题相关的,则不利用该页面继续进行深度爬行,从而提高采集速度,但可能导致一些主题相关页面丢失。
以下对比分布式采集模式与单机采集模式的性能。分布式采集系统利用5台机器搭建,1台部署SpiderMaster,其余4台部署SpiderSlave,采用相同的机器配置:CPU为酷睿i3-2100,内存为4GB(DDR3-1333MHz),磁盘容量为250GB(SATA)。局域网出口带宽为100Mb/s,交换机上下行带宽均为100Mb/s。单机采集系统仅用1台上述机器实现。系统调试成功后,设置Seed页面数为5个,depth为10,节点线程数为5,topN为100。选取关键词主题模式并手动输入关键词,分别运行15、30和60min进行实验,分布式采集与单机采集处理的链接数Ld和Ls如表1所示。
由表1可知,在该局域网部署4爬虫节点的分布式主题舆情采集系统,采集平均速度约为单机采集系统的2.74倍。因此,利用廉价或老旧计算机实施分布式主题舆情采集与分析系统,是实现快速、大规模主题舆情采集的高性价比解决途径。
4 结语
截至目前,针对网络舆情采集技术,国内外都取得了较多研究成果,但是针对主题舆情采集、中文舆情采集以及分布计算技术应用等内容仍有待深入研究。本文基于Nutch设计了一个分布式主题舆情采集与分析系统,可用来初步采集与分析网络主题舆情信息。相比传统采集模式,该系统平均采集速度提升了2.74倍。未来还将针对分布计算环境下的舆情信息处理、舆情应对决策、主题生成技术、领域词典自动化维护技术等作进一步研究。
参考文献:
[1] 李彦辰,艾庆忠,王少非. 基于Redis的分布式搜索引擎研究[J]. 软件导刊,2018, 17(3):201-204.
[2] 萬文兵. 面向主题搜索的网络爬虫信息采集策略研究[J]. 软件导刊, 2015, 14(11):68-70.
[3] 冯思度,杨健叶,韩煦. 基于医疗信息的网络爬虫系统的研究与设计[J]. 现代信息科技,2019,3(10):23-25.
[4] 周桓. 面向检验检疫领域主题爬虫的研究及系统实现[D]. 杭州:浙江大学,2017.
[5] 王相军,刘春晓,刁慕言,等. 全球传染病疫情信息自动收集系统的研发[J]. 中国国境卫生检疫杂志, 2017, 40(6):431-434.
[6] 汪睿. 基于核方法的食品安全舆情分析方法研究[D]. 天津:天津科技大学,2018.
[7] 郑文振. 社交网络中危害国家安全的突发事件搜索研究[D]. 北京:北京邮电大学,2018.
[8] 孙学诚, 陈前, 唐家骏,等. 大数据背景下的恐怖主义信息传播途径分析[J]. 吉林大学学报(信息科学版), 2019, 37(1):91-98.
[9] 马汉超. 基于主题网络爬虫的汽车行业多元信息web系统设计与实现[D]. 成都:西南交通大学,2015.
[10] 郑燕娥,郑志明. 基于Heritrix与Solr的就业主题搜索引擎的研究与优化[J]. 齐齐哈尔大学学报(自然科学版),2018,34(4):13-20.
[11] 李俊,周玉英,唐志航. 基于主题网络爬虫的服装信息采集[J]. 信息技术与信息化,2018(8):97-99.
[12] 刘建成,吴保国,陈栋. 基于网络爬虫的森林经营知识采集系统研建[J]. 浙江农林大学学报, 2017, 34(4): 743-750.
[13] 段玉风. 大数据环境下分布式数据抓取策略的研究与应用[J]. 网络安全技术与应用,2019(12):75-76
[14] 陶影辉, 道瑶瑶, 殷晓靓,等. 基于Hadoop的舆情分析系统模型研究[J]. 中国新通信,2019(14):167.
[15] 蔡天鸿,邓金,史国阳,等. 基于TF-IDF 方法的文本人物群体人格分析方法[J]. 计算机应用与软件,2019,36(5):35-38.
[16] LILI J. Emotional analysis of e-commerce online comment data[C]. Singapore:3rd International Conference on Education,Economics and Management Research,2019.
[17] 刘林. 科技人才信息分布式采集及处理关键技术研究[D]. 杭州:杭州电子科技大学,2018.
[18] 廖海涵,王曰芬,关鹏. 微博舆情传播周期中不同传播者的主题挖掘与观点识别[J]. 图书情报工作,2018,62(19):77-85.
[19] YINYI C, KEFA Z, JINLIN W. Performance analysis of PostgreSQL and MongoDB databases for unstructured data[C]. Changsha:International Conference on Mathematics, Big Data Analysis and Simulation and Modeling,2019.
[20] 任明飛,李学军,崔蒙蒙,等. 基于MongoDB的非关系型数据库的设计与开发[J]. 电脑知识与技术,2019,15(34):1-2.
[21] 马蕾,冯锡炜,窦予梓,等. 分布式爬虫的研究与实现[J]. 计算机技术与发展, 2019, 30(2): 192-196.
[22] 罗娇敏,耿茜. 一种基于Redis的分布式爬虫系统设计与实现[J]. 软件,2017,38(10):83-87.
(责任编辑:黄 健)
猜你喜欢
制导与引信(2017年3期)2017-11-02
中国经贸(2016年19期)2016-12-12
自动化博览(2014年12期)2014-02-28
汽车电器(2014年5期)2014-02-28
