
IPv6网络拓扑测量目标选择技术
2020-03-18 01:39产毛宁
智能计算机与应用 2020年9期
产毛宁, 张 宇
(哈尔滨工业大学 计算机科学与技术学院, 哈尔滨 150001)
0 引 言
互联网向基于 IPv6 的下一代互联网演进已成为全球普遍共识,目前IPv6的部署和使用正在飞速增长,但是由于IPv6 地址空间巨大,地址规划复杂,地址空间划分政策多样,以及地址实际使用率低等这些不同于IPv4 的问题,使得IPv6 网络拓扑测量成为一个巨大的挑战。作为IPv6 网络拓扑测量的输入,IPv6 拓扑测量目标选择技术研究如何通过有效地选择目标来提高拓扑测量的有效性和完整性。
为了克服上述问题,大量的研究工作从IPv6存活地址列表收集、IPv6地址分析、IPv6地址生成和IPv6网络拓扑测量的角度展开。IPv6 存活地址列表(Hitlists)的收集技术包括主动技术如随机探测::1[1],完整探测每个声明的/32前缀中的每个/48中的::1地址[2],rDNS zone 游走,被动技术如基于BGP update或从流量中获取[3,4]。Gasser等观察到存活地址列表本身包含聚类,从均衡性和无偏性的角度提出了TUM Hitlist[5];Ullrich等使用递归的算法来发现和提取IPv6地址模式[6];Foremski等提出了Entropy/IP 系统,使用了贝叶斯模型和聚类分析的机器学习技术来发现IPv6地址结构[7];Murdock等设计了6Gen目标生成器,利用地址局域性,迭代识别高密集区域[8]。上述工作的主要目标为IPv6网络主机发现,而非IPv6网络拓扑发现。CAIDA Ark利用分布式测量点对每个全球声明的BGP可路由的/48或更短前缀中1个::1地址和1个随机地址做ICMP-Paris traceroute,但实践中无法细粒度地抽样,同时存在大量冗余探测。与本文类似,Beverly等将存活地址列表用于IPv6 接口级网络拓扑发现[9],但缺少预测存活地址前缀列表的独立研究。
本文从IPv6存活地址列表的角度,首先探究多源的IPv6存活地址列表收集技术,用尽可能多的来源保证IPv6存活地址的完整性;然后从多角度分析收集到的IPv6存活地址列表的特征,观察并总结该列表所体现出特性以及针对IPv6网络拓扑测量的使用上的指导,为了补充列表采集中的可能缺失和猜测未来可能增长的地址空间,提出IPv6 存活地址前缀列表的预测算法并评估;最后给出IPv6网络拓扑测量目标生成的技术方案,研究的总体流程如图1所示。本文的主要贡献如下:
(1)利用IPv6存活地址列表指导IPv6网络拓扑测量目标选取。
(2)提出存活地址前缀预测算法。
(3)提出IPv6网络拓扑测量目标选取的综合方案。
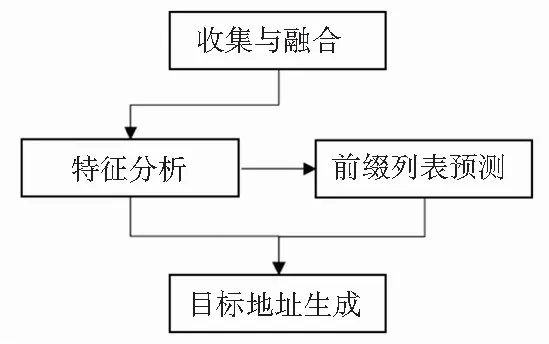
图1 目标选取技术总体流程设计
1 IPv6网络拓扑测量目标选取技术
1.1 IPv6存活地址列表收集与融合
类似于IPv4,IPv6存活地址列表(Hitlist)指一组能够大体上覆盖和代表IPv6网络的地址集合,并具有存活性,地址被分配、部署并在使用中;完整性,覆盖所有存活的IPv6地址空间;稳定性,地址列表随着时间变化尽可能小。本文尝试从5种不同的地址来源获取IPv6存活地址列表,包括:
(1)Rapid7_FDNS:FDNS数据是Rapid7的Project Sonar公开数据一部分,本文采用其中的fdns_any数据,包括所有对ANY 查询的回复,通过提取其中的AAAA记录,最终得到IPv6地址。
(2)CAIDA_Ark:IPv6 拓扑数据集作为CAIDA Ark 平台测量数据的一部分,通过使用Paris Traceroute技术探测所有声明的/48或者更短的IPv6前缀中的随机地址。本文从CAIDA 2月的IPv6拓扑数据里提取路径中出现所有IPv6地址。
(3)Bitnodes:Bitnodes 通过发现网络中的所有可达节点来评估比特币网络的大小,本文使用Bitnodes提供的API,从节点名称中提取IPv6地址。
(4)TUM_Responsive:德国TUM 大学通过对IPv6 存活地址列表的研究,提供IPv6 Hitlist服务,本文直接采用服务提供的回复的IPv6地址。
(5)TUM_Seeds:德国TUM大学的Hitlist服务作为一个收集项目,本身也采用了不同的收集源,根据其仓库中的实际数据,包括有Alexa、CAIDA_dnsname、CT(Certifcate Transparency)、Zonefiles、Openipmap和Traceroute,其中前4个根据提取的域名,查询AAAA记录,来获取IPv6地址;Openipmap为从RIPE ipmap 项目中提取的IPv6地址;Traceroute为对所有其它源中的地址Traceroute再提取所有的路由器IPv6地址。本文将该仓库里不同来源地址综合作为一个收集源。
最后对不同来源存活地址列表清洗再合并,得到融合后的IPv6地址存活列表。由于收集到的地址中还包括特殊目的的全球单播地址,如过渡方案中的6to4地址等,需根据IANA提供的最新全球单播地址分配做筛选。
1.2 IPv6存活地址特征分析
为了探究IPv6 存活地址列表在IPv6网络拓扑测量上的最佳实践,有必要对收集到的IPv6存活地址列表深度分析,观察IPv6地址空间的部署和使用,揭示IPv6地址结构上的聚类,总结IPv6存活地址列表对IPv6网络拓扑测量目标选取上的指导作用。IPv6地址一般可以分为网络前缀和接口标识两部分。
1.2.1 IPv6网络前缀分析
IPv6网络前缀一般指IPv6地址的前64比特。本文为了拓展讨论将前缀长度放宽至128比特,选择长度范围[32,128]来分析前缀,/32作为下届,因为/32前缀通常是区域性互联网注册机构(Regional Internet Registries,RIRs)分配给本地互联网注册机构(Local Internet Registries,LIRs)的最小块,128是IPv6地址的最大长度。输入为不同来源的IPv6存活地址列表,并尝试从频率分布,相邻长度前缀关联性,密度3个角度分析IPv6前缀。首先从IPv6存活地址列表中提取不同长度前缀列表,再依次进行以下分析:
(1)不同长度前缀频率分布分析。统计不同长度前缀列表中的不同前缀频率。
(2)相邻长度前缀关联性分析。Plonka等介绍了前缀聚集计数比率(Aggregate Count Ratio,ACR)[10],对于给定的N个地址,将其聚合成不同长度的前缀,接着对于给定前缀长度p,聚集计数np作为不同/p包含的地址数量,并设定p为0时np为1,则rp=np+x/np,其中x代表相邻前缀的长度差,单位为比特。本文依次取x为 4、8、12和16计算ACR。
(3)不同前缀长度密度分析。统计不同长度前缀列表中不同前缀包含的IPv6存活地址数M,再计算各长度前缀列表中M的四分位数。
1.2.2 IPv6接口标识分析
IPv6接口标识一般指IPv6地址的后64比特,从生成类别上可以分为人工指定和算法自动生成两种,不同的生成方案见表1。张千里等总结了不同的接口标识生成方案,其中人工指定的方案包括[11]:
(1)基于低字节的接口标识(Low-byte)生成方案,一般指的是除最低两个字节外接口标识的大部分设为0。
(2)基于IPv4地址(Embed-IPv4)的生成方案,一般指将IPv4地址作为接口标识的最后4个字节或者将IPv4地址的每个字节对应编码到最后的4个16比特中。
(3)基于服务、端口号(Embed-port)的生成方案,一般指将服务器的端口号或编号嵌入到接口标识中。
(4)基于单词(wordy-based)的生成方案,一般指使用易于记忆的单词代替16进制数字作为接口标识。
算法自动生成的方案包括:
(1)基于MAC地址的IEEE EUI-64(IEEE-based)的生成方案,通常由48位的硬件地址,中间嵌入0xfffe得到,使得接口标识绑定机器硬件且全局唯一。
(2)保护用户隐私的生成方案,一般随机生成且随时间变化而变化。
(3)稳定、语义不透明的生成方案,目的是为了解决临时地址变化频繁导致的复杂的网络管理和部署问题,接口标识随机生成但对同一子网、同一网络接口产生地址相同。
(4)绑定地址与主机的生成方案,源于局域网内安全风险与多宿主机,生成IID随机,一般有加密生成接口标识方案和基于哈希的地址生成方式。本文使用addr6工具统计融合后IPv6存活地址列表中不同接口标识生成方案的占比,分析不同方案的实际部署和使用情况。

表1 常见的接口标识生成方案
1.3 IPv6存活地址前缀列表预测
考虑到IPv6存活地址列表由于收集来源的缺失如不包括非公开数据源,和限制如缺少长时间的积累,可能带来的不完整性,以及IPv6地址部署和使用的快速增长带来的滞后性,有必要设计一种方法能够根据已知收集的IPv6存活地址列表,预测未被收集的潜在存活和未来可能部署和使用的地址,作为IPv6网络拓扑测量目标的补充来提高拓扑发现的完整性。IPv6存活地址前缀列表指一组包含IPv6存活地址的前缀集合。本文为了更完整地探测特定IPv6可路由前缀R下的目标网络拓扑,基于收集的IPv6存活地址列表,从网络拓扑测量中按前缀均匀抽样的常用方法出发,提出IPv6存活地址前缀列表预测算法PrefixPrediction,即根据IPv6存活地址列表提取前缀集合,再结合多层级密度聚类和启发式后缀拓展,来预测未被收集的IPv6存活地址前缀列表,最终作为拓扑测量目标生成的一部分。
根据实践中地址分配体现出的层级性,以半字节即4比特为单位划分;和局部聚集性,分配的地址聚集在相邻或相近的前缀下,本文提出的算法核心思想为针对特定IPv6可路由前缀R下的目标网络,根据R包含的IPv6 存活地址列表HL中提取的IPv6 存活地址前缀列表,预测固定长度为L的IPv6 存活地址前缀列表。R的长度LR∈[32,64],L∈{40,48,…,64}。对于用32位16进制数xj表示的IPv6地址Xi,则包含n个地址的HL形式化表示(1):
HL={X1,X2,…,Xi,…,Xn},
(1)
(1)多层级密度聚类。按不同前缀长度32~64,以8位间隔来划分层级,采用32作为最小长度,而64比特的位置一般作为网络标识和接口标识的分界。对于层级Levelp形式化表示(2):
(2)
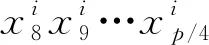
(3)

(4)
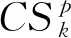
(5)
结合(1)(2)步,得到Levelp的预测的IPv6存活前缀列表HPLp,形式化表示为式(6):
(6)
最终合并不同HPLp得到输出HPL。
1.4 IPv6网络拓扑测量目标选取
在IPv6网络拓扑测量目标选取一般采用对BGP路由前缀列表均匀随机抽样的策略。基于这种均匀随机抽样的方法,本文从IPv6存活地址列表的角度出发,分为两步选取IPv6网络拓扑测量的目标:
(1)对存活地址列表按/64前缀均匀随机抽取;
(2)根据IPv6存活地址前缀列表预测算法,得到预测的/64前缀列表,并对每个前缀拼接随机接口标识,最终合并这两步的输出。基于IPv6存活地址列表的IPv6网络拓扑测量目标选取的综合方案如图2所示。

图2 目标选取的综合方案
2 实验结果与分析
2.1 IPv6存活地址列表收集与融合
合并不同来源的存活地址列表,得到融合的IPv6存活地址列表约17M。不同来源的IPv6存活地址列表统计结果见表2,可以观察到不同来源在融合的IPv6 存活地址列表中贡献的差异。其中,独占:融合的IPv6 存活地址列表中仅由该源提供的地址数量;占比:采用该源的地址与融合的IPv6 存活地址列表交集数占融合的IPv6 存活地址列表的比例。可以发现不同来源占比以及独占比差距不大,CAIDA_Ark 甚至基本一致,说明这些不同来源背后采集技术的不同,导致不同来源存活地址列表独立性强,都应该被采用。

表2 IPv6存活地址列表统计
2.2 IPv6存活地址特征分析
IPv6存活地址特征主要针对最终融合的IPv6存活地址列表。
2.2.1 IPv6网络前缀分析
不同长度前缀频率分布结果如图3所示。数据包括最终融合的IPv6存活地址列表Total及其最主要的3个收集来源,Rapid7_FDNS、CAIDA_Ark和TUM_Responsive,可以观察到不同来源IPv6存活地址列表的频率分布存在共性,随着前缀长度的增加,在[32,64]的区间内呈现明显的上升趋势,而在[64,128]的区间内趋于平缓,表明存在大量的IPv6存活地址聚集在64长度以下的IPv6前缀中。
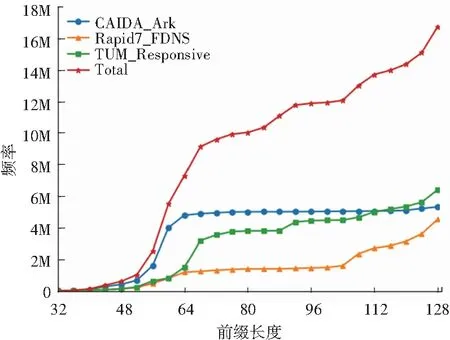
图3 IPv6存活地址列表不同长度前缀频率分布
融合IPv6存活地址列表的不同长度前缀ACR值分布如图4所示。可以观察到不同相邻前缀的长度差下ACR值随着前缀长度的增长,总体在[32,64]区间变化大且多呈现下降趋势,在[64,128]区间变化较小且增减交替,相邻前缀的长度差越小,ACR值变化越多,表明相邻前缀的长度差越小,越能反应相邻前缀的差异。
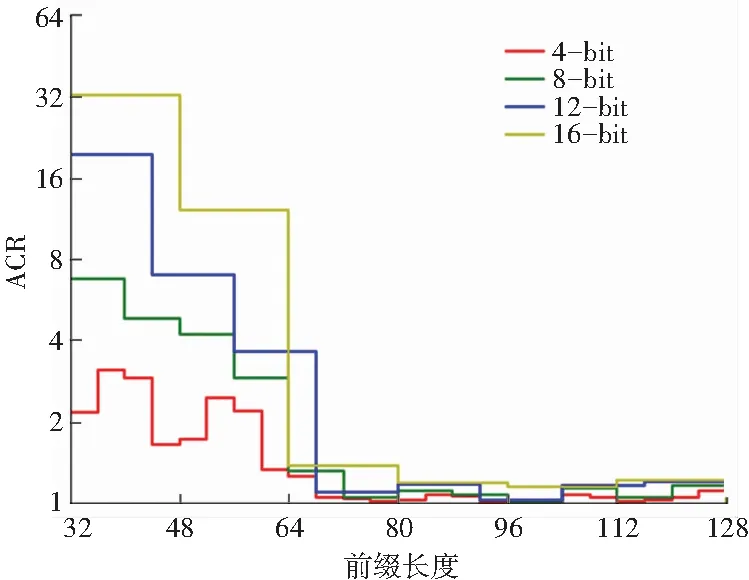
图4 IPv6存活地址列表不同长度前缀ACR值分布
融合IPv6存活地址列表的不同长度前缀密度分布如图5所示。可以观察到[32,64]区间内前缀长度越短,相对地址密度越大,在前缀长度[40,128]区间包含存活地址数的中位数都为1,甚至在[60,128]上四分位数和下四分位数也为1,表明该区间的大多数前缀仅包含1个存活地址,同时[32,40]区间的中位数都不超过10,表明IPv6存活地址列表中不同长度的特定前缀包含存活地址都偏少,数值在1~10之间,呈现出低密度性。
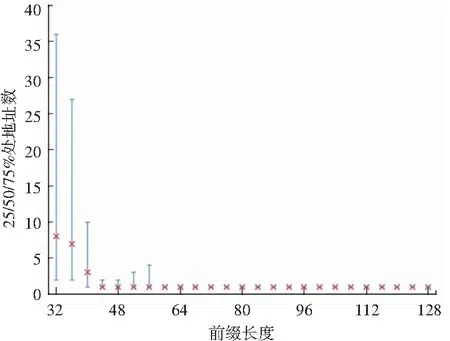
图5 IPv6存活地址列表不同长度前缀密度分布
2.2.2 IPv6 接口标识分析
IPv6接口标识(IID)分析的结果见表3。可以观察到,随机化的地址在不同来源中占据大部分,为50%~80%,表明大多数接口标识是随机的,而基于IPv4地址和端口号的生成方案地址在不同来源中占比较小,基于低字节和IEEE EUI-64方案的地址占比相对较多。此外,不同收集来源下接口标识生成方案占比分布不同,除随机化地址外,Rapid7_FDNS中基于低字节方案的地址最多,而CAIDA_Ark 和 TUM_Responsive 中EUI-64地址最多。
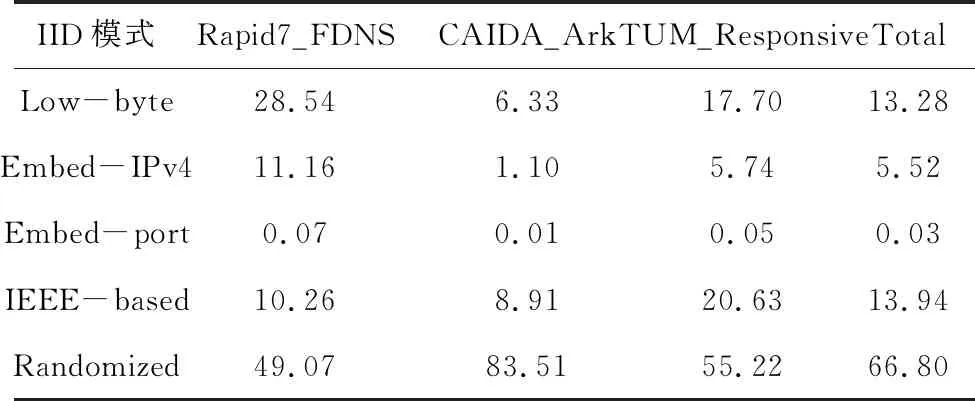
表3 不同IID模式在存活地址列表中占比统计
综上,融合的IPv6存活地址列表呈现高聚集,即大量地址聚集在较短的前缀中;多层次,即长度差越小,越能反应相邻前缀的差异性;低密度,即不同长度前缀包含存活地址数的中位数为1~10;接口标识不可预测性,即大部分接口标识是随机的。
2.3 IPv6存活地址前缀列表预测
为了评估预测算法的效果,针对特定/32前缀网络,对IPv6存活地址列表过滤得到/64存活前缀列表,对该列表的随机50%作为训练集,剩余50%作为测试集,计算本文算法PrefixPrediction(PP)的正确率,并与Entropy/IP(EIP)结果作比较。预测集:输出的与测试集相同数量的预测前缀列表;正确率:预测集与测试集的交集占测试集的比例。本文在3个数据集H1、H2和H3做实验,实验结果见表4。

表4 PrefixPrediction与Entropy/IP实验结果对比
实验结果表明,本文的前缀预测算法PrefixPrediction正确率相比Entropy/IP 高,在1.4~5.5倍之间,同时二者预测前缀的交集小,有强互补性。预测集增长下的正确率变化趋势如图6所示,可以发现随着预测集增长,PrefixPrediction比Entropy/IP正确率都要高,二者的正确率都呈现线性增趋势,表明两种算法的预测能力都具有稳定性。
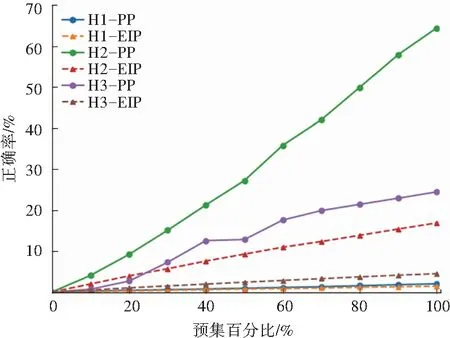
图6 预测集增长下正确率变化趋势
2.4 IPv6拓扑测量目标选取
为了验证本文基于IPv6存活地址列表的IPv6网络拓扑测量目标选取方法的效果,针对特定/32可路由前缀的目标网络,分别采用本文方法HS和按/64均匀随机抽样方法URS,对一定数量目标采用ICMP-paris的探测方法,对比结果的节点数和链接数。目标网络包括T1(2001:16b8::/32)、T2(2a02:06b8::/32)和T3(240e:00e0::/32)。本文方法中对存活地址列表按/64均匀随机抽样数的2倍,相应的URS为从均匀随机抽样的地址中再随机抽取该数量;traceroute路径中发现的不同IPv6接口地址数;traceroute路径中发现的不同IPv6接口地址连接数。本文对3个数据集T1、T2和T3分别采用不同测量点做实验,实验结果见表5。
实验结果表明,本文基于IPv6存活地址列表的IPv6网络拓扑测量目标选取方法HS比均匀随机抽样方法URS明显提高了拓扑发现的完整性,拓扑新发现率在94%以上,拓扑发现结果随探测目标增长变化如图7和图8所示,HS相比URS结果表现一直要好。拓扑的完整性即发现的节点数和链接数,拓扑新发现率即HS相比URS新发现的节点和链接占HS的比率。

表5 HS和URS 实验结果对比
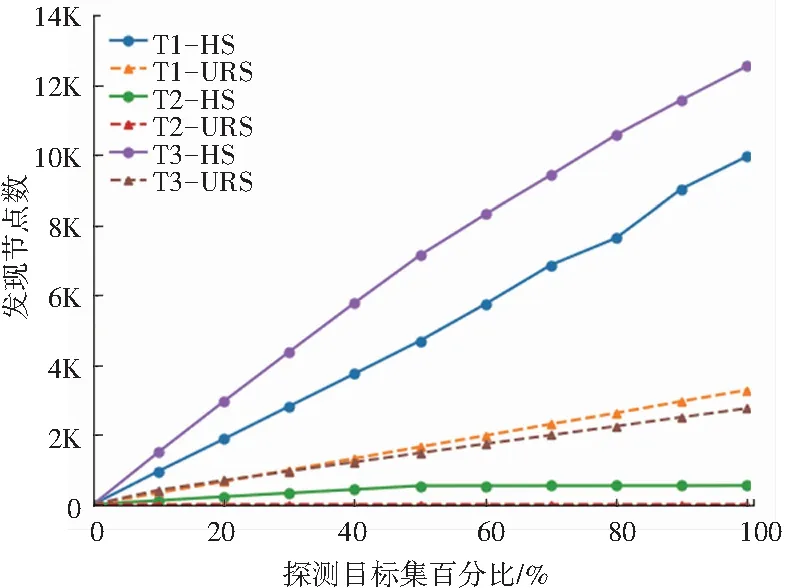
图7 发现节点数随探测测量目标数增长变化

图8 发现链接数随探测目标数增长变化
3 结束语
本文提出一种IPv6 网络拓扑测量目标选取技术,用于提高IPv6网络拓扑测量的有效性和完整性。首先,收集并融合不同来源的IPv6存活地址列表得到约17M的地址;其次,分析了IPv6存活地址列表的特征,发现融合存活地址列表呈现出高聚集、多层次、低密度和接口标识不可预测性,提出了IPv6 存活地址前缀列表的预测算法PrefixPrediction,对比Entropy/IP预测的正确率更高,发现二者结果具有强互补性;最后,给出了IPv6网络拓扑测量目标选取的综合方案HS,对比URS明显提高拓扑发现的完整性,拓扑新发现率超过94%。未来将进一步丰富收集技术,提高IPv6存活地址列表的完整性,结合多种IPv6存活地址前缀预测算法来提高预测正确率,从而更深入地进行IPv6网络拓扑测量的研究。
猜你喜欢
课堂内外(初中版)(2020年5期)2020-06-19
爱你(2018年24期)2018-08-16
爱你·阳光少年(2018年8期)2018-05-14
大自然探索(2017年11期)2017-11-28
中学生数理化·教与学(2017年4期)2017-04-22
电子技术与软件工程(2016年23期)2017-03-06
数字技术与应用(2016年9期)2016-11-09
电脑知识与技术(2016年21期)2016-10-18
电脑知识与技术(2016年12期)2016-06-14
中学生数理化·中考版(2015年10期)2015-09-10
