
基于TF-IDF特征词提取的不平衡文本分类
2020-03-18 01:39王忠震
智能计算机与应用 2020年9期
陈 欢, 王忠震
(上海工程技术大学, 电子电气工程学院, 上海 201620)
0 引 言
随着web2.0时代的到来,我国的网民规模飞速增长,达到了9.04亿,网络文本数据也随时间大量累积。对文本分类、整理,发掘文本中的潜在信息成为了研究的热点。然而在实际的网络文本分类过程中,类别分布不均衡制约着文本分类技术的发展。
传统的解决数据类别分布不均衡的方法是通过重采样,数据增强等方法。如张忠林等针对不平衡分类过程中,数据集中存在噪声数据使得边界模糊的现象,提出了将少数样本划分,只对边界样本进行SMOTE插值,然后数据清洗,去除噪声数据[1];蒋华等针对不平衡数据集分类时边界偏移的问题,提出用ADASYN和SMOTE算法生成小类样本点[2];史明华等通过使用聚类算法进行聚类,根据类别簇不平衡比的大小对该簇进行相应的处理[3]。
随着深度学习技术的发展,给文本的不平衡分类技术发展提供了新的思路。如陈志等针对训练神经网络模型时参数会被多数类所主导,在损失函数中加入类别标签,强化少数类对模型参数的影响[4];林怀逸等利用小类别区分的预训练词向量来初始化目标模型,并结合均衡过采样,保持模型在大类别上的精度[5];万志超等针对文本分布不均衡分类时局限于特征维数过高、数据稀疏、分布不均衡的特点,通过使用有监督的特征选择方法,减少特征词数量,降低特征维度[6];程艳等提出将不平衡数据划分为若干组均衡数据,使用CNN神经网络训练,并使用EWC克服CNN的灾难性遗忘的缺点[7];唐焕玲等使用有监督的主题模型SLDA,建立主题和稀少类别之间的映射,以提高少数类分类的精度[8];钟将等针对文本特征维度大和训练样本分布不均衡的问题,提出使用LSA降维,并利用改进的KNN进行文本分类[9]。
综上所述,在进行数据不平衡分类的过程中,主要通过强化类别的边界,去除噪声数据等方法[10]。与其不同的是,在文本分类过程中,解决数据类别分布不均衡的方法,主要有强化类别标签、过采样等方法。因此,本文通过使用TF-IDF构建类别特征词,与原有文本拼接来强化各类的类别特征,并使用注意力机制进行文本特征权重分配。
本文的主要工作如下:
(1)利用TF-IDF给文本中词赋权的方法进行类别关键词提取。将数据集划分为若干个平衡的子数据集,输入到TF-IDF模型进行类别关键词提取。
(2)将训练集和测试集输入到word2vec词嵌入模型进行词向量训练,得到TF-IDF提取到的关键词和原有的文本数据拼接后的词向量表达,输入到注意力机制模型训练和权重分配,最终进行文本分类。
1 基础理论
1.1 TF-IDF特征权重计算方法
TF-IDF是一种用于信息检索的文本加权技术,在文本信息检索的过程中,通过对文本赋予不同的权重,从而判断与检索词的关系,提高检索的准确率和召回率。
TF-IDF的具体思想可以表述为:在一篇文章中,如果一个词在该篇文章中出现的频率较高,而在语料集的其它文章中出现的频率较低,则该词更能代表该篇文章。其中,TF表示词频;IDF表示包含该词的文档数目。在数学上可以表示为公式(1)、(2)、(3)。
TF-IDF=tfi,j*idfi,
(1)
(2)
(3)
其中,ni,j表示词语i在文档j中的频率;|j|表示文档j中词的总数;|D|表示语料集中文档的总数;dfi表示语料集中包含词语i的文档总数。idfi的计算过程中分母加1是为了防止违反运算法则的情况出现。
1.2 LDA文本降维
LDA模型是一种主题概率模型,将文本表示为文本-主题、主题-词的概率分布。LDA的概率图模型如图1所示。其中,K表示主题数;D表示文档数;N表示一篇文档中词的数目。
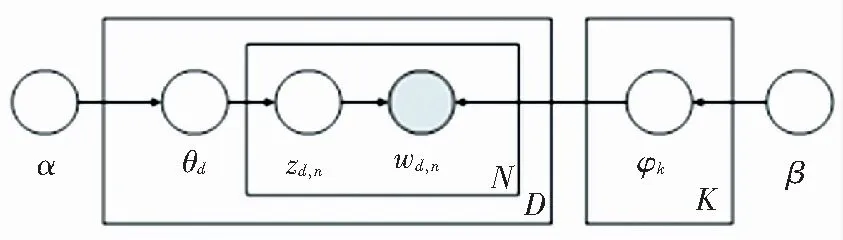
图1 LDA概率图模型
(1)模型假设文档的主题先验分布服从参数为α的Dirichlet概率分布,其中文档d的主题概率分布为θd=Dirichlet(α)。
(2)模型假设主题中的词的先验分布服从参数为β的先验概率分布。其中,主题k的词概率分布为φk=Dirichlet(β)。
(3)文档d中的第n个词,从主题分布获得其主题编号概率分布为zdn=multi(θd)。
(4)文档d中的第n个词分布wdn的概率分布为wdn=multi(φzdn)。
由于Dirichlet-multi是共轭分布,可以利用贝叶斯推断的方法求得后验分布,在得到文档主题,主题词的后验概率分布后,利用Gibbs采样的方法获得每个文档的主题分布和每个主题的词分布。
1.3 注意力机制
注意力机制首先被提出用于图像特征提取领域,其次被Bahdanau等人推广到自然语言处理领域。其思想可以描述为通过改变模型参数来加强某个输入对输出的影响[11-12]。其中google提出的最初注意力计算方法如公式(4)所示,ks(key)与vs(value)一一对应,通过计算qt(query)和各个ks的内积,求得与各个vs的相似度,然后加权求和归一化。
(4)

2 模型描述
2.1 模型框架
基于词嵌入的不平衡文本数据分类框架如图2所示。

图2 模型结构
模型主要分为三个部分:首先,使用TF-IDF进行类别关键词提取,与原有文本拼接,输入到word2vec模型进行词向量训练;其次,使用TF-IDF对文本降维,并和类别关键词拼接,并将其用词向量表示;最后,使用Self-Attention对词向量表示后的文本进行特征权重分配。
2.2 TF-IDF类别关键词特征提取
类别关键词特征作为类别之间的区分,具有明显的类别特性。将数据集划分为若干个平衡的子数据集,输入到TF-IDF模型,获得子数据集每个文本的TF-IDF表示,统计每个类别的TF-IDF权值大的词作为类别的关键词特征。
划分为平衡数据集是为了TF-IDF在词特征提取的过程中能够有更好的效果。否则可能出现少数类别文章关键词存在本文属于高频,而在语料集中很少出现,就会导致该词的权重过大,但该词并不能代表该类别。
2.3 LDA文本降维
将文本输入到LDA模型,得到每篇文章的主题词分布和主题分布,通过这两个分布可以将文章的主要特征进行表示,从而实现文章的降维。设每篇文章的主题词分布为t_w=[w1,w2,...,wN],文章主题分布为d_t={z1,z2,...,zK}。通过将两个分布对应相乘,选择结果较大的词作为LDA降维后的文本特征,并将其用词向量的形式表示,进行下一步的操作。
2.4 Self-Attention权重分配
传统的注意力机制通过计算源端的每个词与目标端的每个词之间的依赖关系来更新训练参数,Self-Attention机制仅通过关注自身信息更新训练参数,不需要添加额外的信息。将前述通过CBOW模型得到的融合主题特征的评论文本向量输入到Self-Attention层,通过公式(5)计算权重分布。
(5)
2.5 模型分类
将注意力机制编码后获得的文本信息,使用交叉熵作为损失函数,利用adam更新网络参数。利用公式(6)求解文本特征向量γx属于类别yx的概率,n_c为类别的数目。以公式(7)为损失函数,其目的是通过迭代的更新参数最小化监督标签gx和预测标签之间的交叉熵。
(6)
(7)
3 实验分析
3.1 实验数据集
实验数据集采用复旦大学中文文本分类数据集,该数据集分为训练集和测试集两部分,共有20个类别,类别数最多的文本有1 357篇,最少文本的只有27篇。本文选择其中文本较多的9个类别进行文本分类。各个类别分布如图3所示,其中类别数最多的有1 357篇,最少的有466篇。

图3 训练集各类别数据分布
3.2 TF-IDF 类别关键词提取
将训练的数据集划分为两个训练集,输入到TF-IDF模型进行训练。其中,低于1 000的数据集进行两次模型训练,高于1 000的划分为两个部分输入到模型训练。
TF-IDF提取到的类别关键词特征示例,见表1。可以看到,每个领域的特征词都有明显的领域特征,因此与原有文章进行拼接可以加强少数类的类别特征,从而提高文本分类的准确率。

表1 TF-IDF提取类别关键词特征示例
3.3 模型对比分析
目前的分类评价方法评价指标有精确度、召回率和F1值,本文也采用这些指标进行分类结果评价。
使用gensim库进行LDA和word2vec词嵌入模型训练,同时和其它几种基于LDA和word2vec的模型进行训练,得到准确率对比,见表2。实验证明了本文提出的方法优于其它的传统方法。

表2 结果对比分析
4 结束语
针对文本数据分类不均衡的问题,本文提出使用TF-IDF进行类别关键词特征提取,然后输入到注意力机制模型进行文本分类。在复旦大学语料集上证明了本文提出模型优于其它的经典模型,具有更好的分类效果。但本文提出的模型也有一定的不足,如在TF-IDF特征词提取的过程中,TF-IDF不能得到很好的效果,其中有一些词不具有类别代表性,因此需要对其进行人工筛选。
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
电脑爱好者(2021年9期)2021-05-12
少儿画王(3-6岁)(2020年4期)2020-09-13
东方教育(2018年20期)2018-08-22
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
电脑爱好者(2017年7期)2017-05-06
少儿科学周刊·少年版(2015年3期)2015-07-07
