
基于深度学习的文本情感分析
2020-04-08 13:26李丽华胡小龙
湖北大学学报(自然科学版) 2020年2期
李丽华,胡小龙
(中南大学计算机学院,湖南 长沙 410075)
0 引言
随着互联网技术的飞速发展,人们的生活与互联网越来越密不可分.越来越多的用户喜欢在网络上分享个人生活,发表个人见解.微博、博客、论坛、Twitter、微信等在线社交媒体在各种舆论的传播方面发挥着越来越重要的作用.微博通过评论、转发、点赞、分享等方式吸引越来越多的用户使用,允许用户通过文字、视频及图片等方式发表观点.微博因其在信息沟通方面给予用户自由性和快捷性,使其作为一种社交网络平台脱颖而出.2018年新浪微博发布的第三季度末审计财报中微博月活跃用户数已增至4.46亿,成为全球第7家活跃用户规模突破4亿的社交产品.普通用户喜欢通过该平台表达自己对社会突发事件、娱乐事件及商品信息等的看法.同时,公司以及政府部门等组织机构也开始使用微博作为市场营销和公共关系管理的一种工具.因此,对微博文本情感分析研究具有理论和实际价值.
情感分析是对带有感情色彩的文本数据进行处理和分析,从中提出具有价值的信息.由于微博平台的特点,用户所发表的言论比较口语化,同时文本比较简短,这也使得对微博文本情感分析增加相应难度.传统文本情感分析方法主要包含基于情感词典和基于机器学习的方法,这两种方法都各自有相应优缺点.近年来,深度学习技术开始应用于自然语言处理领域[1],但是传统的深度学习模型将所有的特征赋予相同的权重进行训练,这样会导致无法更好地关注稀疏特征短文本中对情感类别贡献较为关键的特征[2].为此,本文中提出一种自注意力机制与长短时记忆网络和卷积神经网络相结合的情感分析模型,并通过在相同数据集上对比多种模型验证该模型的准确性和有效性.
1 相关研究
情感分析的应用非常广泛,可以进行用户评论分析、舆情监控、市场预测等[3].目前已有的情感分析方法主要包含基于情感词典的方法、基于特征向量的方法和基于深度学习的方法.
基于情感词典的方法是通过构建情感词典对文本进行情感计算从而判断文本的情感倾向.孙本旺等[4]通过借助中文情感词典资源构建藏文情感词典的方法对微博情感进行研究,实验表明他所构建的词典相比其他藏文情感词典实用性更好一点.王志涛等[5]利用40万条微博数据构建新词词典, 对已有情感资源进行拓展, 并对不同语言层次定义不同的规则,还以表情符号作为附加信息提供辅助作用.在国外E.D′Andrea等[6]通过构建文本词典、机器学习中的SVM以及利用卷积神经网络等3种方式进行比较,分别对tweets中抓取到的关于疫苗接种话题的内容进行分析,通过实验比较并且基于使用最简单的方案为目标最终确定利用机器学习的SVM分类器完成实验,并且达到很好的结果.基于情感词典的方法比较简单,但是需要人工构建一个比较完善的情感词典,而且要考虑到具体领域内的领域词,适用性并不强.在大数据时代,对于庞大的数据体系构建完备的情感词典需要耗费大量的人力体力.
基于特征向量的方法主要是通过对文本数据进行特征提取,将特征转换成向量的形式表示,然后通过机器学习相关的方法进行分类.常用的机器学习方法有朴素贝叶斯、SVM、随机森林、最大熵等.Timur Sokhin等[7]提出一种基于主题模型的半监督情感分析方法,主要包括基于主题的识别、建模等相关内容的提取和标记,通过实验的方式验证该方法的有效性.Liu S等[8]提出一种自适应SVM多分类器模型,模型应用于Twitter数据集,通过优化,未标记数据选择和自适应特征扩展等步骤解决Twitter数据集稀疏问题,最终通过与监督和半监督机器学习方法相比较,验证该模型在公共Twitter语料库的6个主题上准确性都有提高.基于机器学习的方法依赖于特征的选取,分类效果的好坏同样依赖于特征的好坏,要想达到更高更好的分类效果往往需要人工构造大量特征.
基于深度学习的方法主要是使用神经网络避免人工构造大量文本特征.Hochreiter等[9]在1997年提出并实现了LSTM(长短时记忆网络),通过引入“门”的机制较好的改善了RNN的梯度消失以及爆炸问题.Maha Heikal等[11]通过构建CNN模型和LSTM模型对阿拉伯语言进行情感分析.Ahmed Sulaiman M.Alharbi等[10]使用卷积神经网络对Twitter中数据进行情感分析建立一种情感分类系统,将用户行为信息合并到文本中通过实验对比发现卷积神经网络比常用的机器学习算法比如朴素贝叶斯、SVM等效果更好.但上述方法都是比较传统的深度学习方法,无法更好地关注短文本中对情感类别贡献较为关键的特征.2014年,Google Mind团队首次提出Attention注意力机制进行图像识别.它可以聚焦图像中较为重要的区域,提高图像识别的精度[2].Bahdanau 等[12]将Attention应用到机器翻译中,取得的效果要比传统的神经网络模型更好.刘峰等[13]基于Multi-head Attention 和 Bi-LSTM对实体关系进行分类研究,经过验证效果也比之前的深度学习模型要好.吴小华等[2]利用Self-Attention和Bi-LSTM提出基于字向量的中文文本情感分析,分类效果比单独使用LSTM、CNN等神经网络在微博数据集上可以提高1.15%.虽然很多专家及学者通过实验已经表明引入注意力机制的双向循环神经网络模型在文本分类上已经取得很好的效果并且超过单独使用CNN网络,但是由于微博文本的特点短句子偏多使得循环神经网络并没有取到很好的句子信息,因而在一些实验上循环神经网络的效果甚至还不如CNN.因此,在文献[2]提出的模型基础上提出基于句向量的Self-Attention+Bi-LSTM的模型并添加CNN网络,并对神经网络中相关参数通过实验验证的方式进行相关修改,对于两种模型提取特征的优势进行互补,并在这两种模型基础上引入自注意力机制对句子中的关键词给予更多的注意力,以便更好地获取句子中的情感信息实现更准确的分类,并在所抓取的微博语料集上验证本模型的准确性.
2 基于Self-Attention和BI-LSTM+CNN的模型结构
采用双向长短时记忆网络(BI-LSTM)和卷积神经网络(CNN)对文本进行情感分类,并引入Self-Attention机制.自注意力机制主要是抽取重要词语的语义信息,并且作为分类器的输入.本研究所描述的模型包含5个部分,模型结构图如图1所示.

图1 模型结构图
(1)文本预处理及向量表示:文本清洗、分词及除停用词,将词转换成词向量,通过TF-IDF将词向量转换为句向量.
(2)BI-LSTM层:通过BI-LSTM提取文本上下文全局特征,作为CNN的输入.
(3)CNN层:根据BI-LSTM的输出提取局部特征.
(4)Selft-Attention层:进行注意力机制计算,将结果进行映射,得出最终句子的特征表示.
(5)输出层:采用softmax作为分类器,得到最终的情感极性.
2.1 文本预处理及向量表示
2.1.1 文本预处理 中文文本不能直接被计算机所识别,因此在训练模型之前需要对中文文本进行预处理.首先将文本进行分词,本文使用的是python中的jieba分词工具,然后是去除停用词,停用词指的是在文本中大量出现但是对于自然语言处理任务没有意义的词,本文所选用的停用词表是将“哈工大停用词库”和“四川大学机器学习智能实验室停用词库”进行整理归纳所得.通过分词后的文本和停用词表进行对照,从而将文本中匹配到的停用词去除.通过去除停用词可以有效减少数据噪音,降低模型训练时间并提高模型性能.
2.1.2 文本向量表示 文本向量表示指将分词后的结果用向量形式表示,本文采用的向量表示方法是FastText.FastText是Facebook2016年提出的文本分类工具,是一种高效的浅层网络.FastText模型架构和Word2Vec的CBOW模型类似,FastText模型一共有3层,输入层、隐藏层、输出层.输入都是多个经向量表示的单词,输出都是一个特定的Target,隐含层都是多个词向量的叠加平均.不同的是CBOW的输入是目标单词的上下文,FastText的输入是多个单词及其n-gram特征,这些特征用来表示单个文档;CBOW的输入单词被onehot编码过,FastText的输入特征是被embedding过;CBOW的输出是目标词汇,FastText的输出是文档对应的类标.FastText充分利用了h-softmax的分类功能,遍历分类树的所有叶节点,找到概率最大的label.本文直接使用的是Gensim库中的FastText模型,对语料库中的文本迭代10 000次,删除文本长度小于2的词.FastText模型结构如图2所示(此模型图来自于文献[15]).
FastText模型训练的词向量可以更加方便地计算词语之间的相关性,利用词向量之间的余弦距离表示词语之间的关系,余弦距离越大,词语之间的关系就越大.表1所示是对抓取到的微博进行预处理之后计算与“开心”这词最相关的10个词.

图2 FastText模型结构图

表1 词向量语义相似度
2.2 双向长短时神经网络LSTM是一种特殊的循环神经网络,它通过引入“门”结构能够学习 Long-term 依赖问题并缓解梯度爆炸问题.LSTM主要包含输入门(it)、遗忘门(ft)、输出门(Ot)与一个记忆单元(Ct).计算第t时刻对应的各个状态值由下面几个公式可得:
ft=σ(Wf×ht-1+Uf×xt+bf),it=σ(Wi×ht-1+Ui×xt+bi),at=tanh(Wa×ht-1+Ua×xt+ba),Ct=Ct-1⊙ft+it⊙at,Ot=σ(Wo×ht-1+Uo×xt+bo),ht=ot⊙tanh(Ct),
其中,ht-1表示t-1的隐藏状态;xt表示第t时刻的输入;Wf,Uf,Wi,Ui,Wa,Ua,Wo,Uo表示对应遗忘门、输入门以及输出门权重矩阵;bf,bi,ba,bo分别表示遗忘门、输入门以及输出门的偏倚;⊙表示同或;σ表示sigmoid激活函数;tanh表示双曲正切激活函数;Ct-1,Ct表示第t-1时刻和第t时刻细胞状态,前面遗忘门和输入门的结果都会作用于细胞状态Ct;ht表示第t时刻的隐藏状态;Ot表示第t时刻的输出.
在自然语言文本处理中,LSTM只考虑上文信息,没有考虑下文信息会导致语义丢失的问题.使用双向的LSTM,就是一层从前往后,一层从后往前,每一层都是上文所提及的原始的LSTM,最终输出值是由这两部分语义组成.比如对“我爱中国”这句话进行编码,分词之后成为{“我”,“爱”,“中国”},输入前向的LSTM可以得到三个向量{hL0,hL1,hL2},输入后向的LSTM可以得到{hR0,hR1,hR2},在情感分析中一般是将前向最后一项输出和后向最后一项输出进行拼接得到[hL2,hR2],如图3所示.
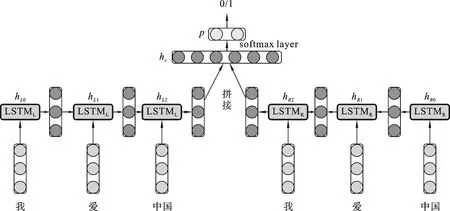
图3 向量拼接情感分类图
2.3 卷积神经网络卷积神经网络是一类包含卷积计算且具有深度结构的前馈神经网络,一般应用于计算机视觉领域做图像分类、检测之类的任务.后来,研究学者发现CNN应用于文本分类中也可以取得较好的效果[18],从此使用CNN来做自然语言处理任务的工作越来越多.卷积神经网络的基本结构包含输入层、卷积层、池化层、全连接层以及输出层.CNN用于文本分类模型结构图如图4所示[19].

图4 CNN文本分类模型图
图4中是将卷积核大小设置为(2,3,4),每个相同大小的卷积核的通道数设置为2.卷积核大小为 2,3,4的卷积分别提取了语句中的 2-gram,3-gram,4-gram特征,传统的机器学习方法也能提取n-gram,但是随着gram的增加,训练集词表大小将会呈指数级增长,这就会使得训练很难进行.在本文中将CNN中卷积核大小设置为(3,4,5),进一步提取由BILSTM输出的基于上下文信息的特征.
池化层的主要作用是下采样,不断地降低维数,以减少网络中的参数和计算次数.池化层之后基本就是全连接层,全连接层就是将之前的结果平坦化之后接到最基本的神经网络,同时,为了防止过拟合会通过Dropout操作,之后通过Softmax分类器进行分类.
2.4 自注意力机制注意力机制被广泛用于语音识别、机器翻译以及图像处理等领域.Self-Attention机制在文献[16]中提出,它的实质是一个加权求和的过程.注意力得分计算公式如下:
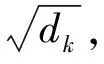
2.5 全连接及输出层在本文中,情感分析属于分类问题.经过Attention机制提取出的重要特征,输入到全连接层,为了防止过拟合问题,主要采用L2正则和Dropout机制,然后使用Softmax函数进行分类.
3 实验与分析
3.1 实验环境本研究的实验环境以及相关配置如表2所示.
3.2 实验数据收集与处理以微博平台为研究对象,通过网络爬虫的方式爬取新浪微博10万多条数据.根据微博文本内容的规则,其中含有“//@”一般为转发微博,首先根据正则表达式进行文本匹配,若文本中含有“//@”,则通过程序删除此文本.将删除之后的文本放在excel中进行筛选,对于重复的文本内容进行最后删除.将经过预处理之后的文本中包含的表情符号替换成对应文本文字,使用0和1对此微博语料进行人工标注,正面情感标注为1,负面情感标注为0,具体的标注规则如表3所示,由3个人进行标注审核保证语料集的可信性,最终得到含有正负面情感的微博文本数据各2万条.标注完成之后的数据格式如表4所示.
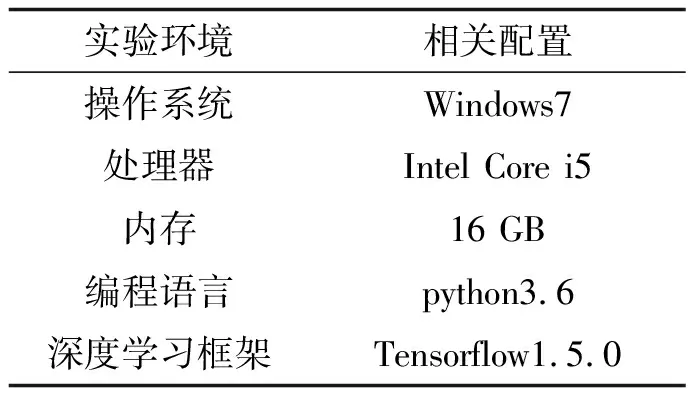
表2 实验环境配置

表3 人工标注情感分类规则

表4 文本情感标注数据示例
选取其中3万条样本作为训练集,1万条样本作为测试集.对这些数据进行分词和除去停用词,并利用FastText模型训练词向量,然后结合TF-IDF,将词向量转换为句向量,作为BI-LSTM模型的输入.
3.3 实验评价指标使用通用的3个评价指标作为评价标准:准确率(PPrecision)、召回率(PRecall)及F1值(F)对实验结果进行评价.本研究给出的分类混淆矩阵如表5所示.
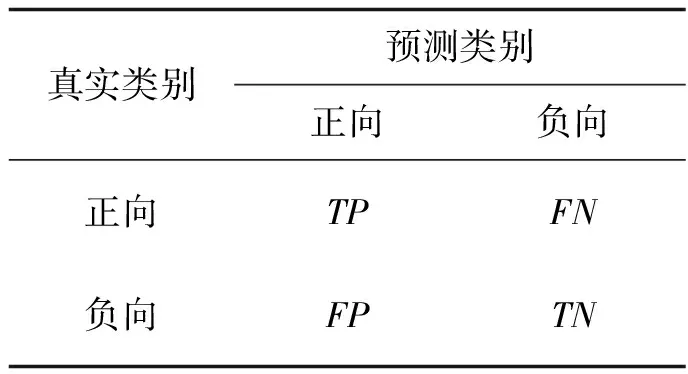
表5 分类结果混淆矩阵

表6 FastText词向量训练参数
其中,TP指正向类预测为正向类的数目,FP指负向类预测为正向类的数目,FN指正向类预测为负向类的数目,TN指负向类预测为负向类的数目.评价标准的计算公式如下所示:

3.4 实验参数设置实验参数设置会直接影响实验效果.实验中首先将微博文本的最大长度设置为200,超过的进行截取.表6列出的是在训练FastText向量时设置的参数值.表7列出的是双向长短时记忆网络对应的参数值.表8列出的是卷积神经网络训练时对应的参数值.实验过程中BILSTM的词向量参数比较了100维、200维和300维,最终选用200维;层数默认为2;隐藏层的大小比较了64、128、256,最终选取128;通过比较最后选用表7中设置的参数可以达到最好的准确率.
CNN参数选取过程中,将卷积核大小设为固定的(3,4,5),窗口数量对比了64、128、256,Dropout比例对比了0.3、0.4、0.5,通过对比上述参数对模型的影响,最终确定的参数如表8所示.

表7 BILSTM神经网络参数设置
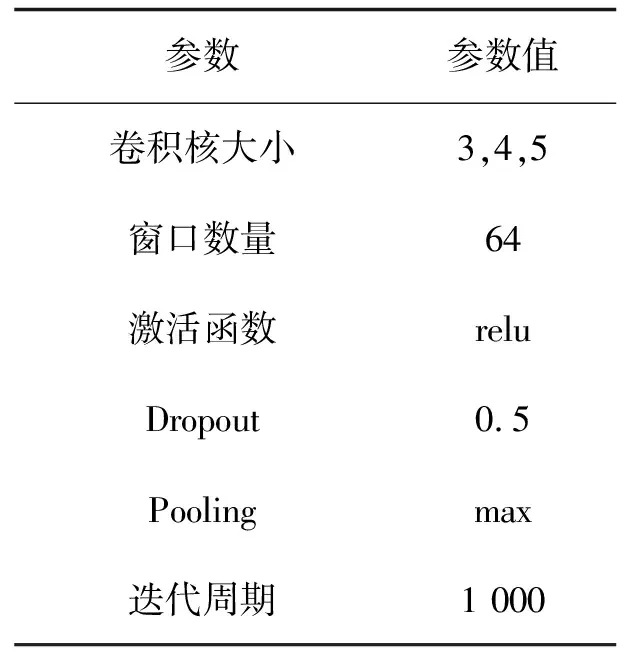
表8 卷积神经网络参数值
3.5 实验结果为将本模型和其他模型效果进行对比,试验所采用的数据集均为本实验中所抓取到的微博文本数据.模型中的词向量均是使用FastText算法在本文数据集上进行预训练得到的.本文实验数据设置几组实验:
(1)SVM模型:SVM模型是机器学习中比较典型的分类模型,在深度学习提出之前,SVM模型在分类任务上取得了不错的分类效果.
(2)CNN模型:将卷积核设置为3,4,5进行卷积,由于卷积神经网络只能提取局部特征,最后的分类效果并不是很好.
(3)LSTM模型与Bi-LSTM模型:单向神经网络模型与双向的神经网络模型对照,证明双向的LSTM模型使分类效果有所提升.
(4)Self-Attention+BI-LSTM模型:验证添加自注意力机制后双向神经网络模型在情感分析任务上性能得到了提升.
(5)Self-Attention+BI-LSTM+CNN模型:验证本文所提出使用FastText算法表示的向量结合Self-Attention+BI-LSTM+CNN的微博文本情感分析性能.
不同模型在相同微博数据集上的对比.图5显示的是微博数据集在LSTM,BI-LSTM,Self-Attention+BI-LSTM,CNN,Self-Attention+BI-LSTM+CNN模型上的损失函数loss值随迭代次数的变化而变化.对比图5可知所有模型均下降到相对较低的稳定值,提出的SCBILSTM模型的loss值下降速度较快,并且最终收敛到一个比较低的稳定值.表9显示的是不同模型在微博数据集上评价指标的对比.由表9可知各神经网络模型较原始机器学习中分类算法都有所提高.

图5 不同模型loss损失变化图

表9 不同模型评价标准对比
1)通过比较LSTM和BI-LSTM的实验结果可知,增加反向传播单元后可以同时考虑文本上下文信息,比单向的LSTM效果更优.2)通过比较BI-LSTM和Self-BILSTM的实验结果可知,加入自注意力机制后,模型的准确率、召回率和F1的值分别提高了1.09%、2.3%、0.83%.3)通过比较Self-BILSTM和Self-BI-LSTM-CNN的实验结果可知,通过加入Self-Attention和CNN可以更好的提取局部关键特征,使得模型的准确率、召回率和F1的值分别提高2.01%、2.41%、2.30%.由此可以证明本文所提出算法的有效性.
4 结语
本文中提出了基于Self-Attention机制的BI-LSTM结合CNN的微博文本情感分析算法.通过FastText算法将文本表示为词向量,结合TF-IDF算法将词向量表示为句向量,利用BI-LSTM网络提取文本的上下文特征,将提取的特征输入卷积神经网络,将卷积核的大小设置为3、4、5并引入自注意力机制对特征的重要程度动态调整,在抓取的微博数据集上通过与其他基本模型进行对比证明该算法的有效性.由于研究只考虑文本的上下文信息,没有考虑具体的词性问题,并且只在抓取到的微博数据集上进行验证,未来的工作可以考虑词性问题对分类的影响以及如何进一步改进Attention机制进行研究.
猜你喜欢
现代电力(2022年2期)2022-05-23
新高考·高一数学(2022年3期)2022-04-28
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
电子制作(2019年13期)2020-01-14
电子制作(2019年19期)2019-11-23
电子制作(2019年11期)2019-07-04
电子制作(2019年24期)2019-02-23
北京航空航天大学学报(2018年1期)2018-04-20
北京航空航天大学学报(2017年12期)2017-04-23
