
基于循环一致性对抗网络的室内火焰图像场景迁移
2020-04-11 02:00杨植凯卜乐平欧阳继能
光学精密工程 2020年3期
杨植凯,卜乐平,王 腾,欧阳继能
(海军工程大学 电气工程学院,湖北 武汉 430033)
1 引 言
随着深度学习的发展,基于深度卷积神经网络(Deep Convolutional Neural Networks,DCNN)的火灾识别方法得到大量应用。而深度学习的方法依赖于训练集的样本的数量和质量。正样本(火灾视频)与负样本(背景干扰)不均衡会影响到深度神经网络识别的准确率[1]。由于受到安全限制,很多场景下,如厂房、仓库、办公室等场所无法直接点火采集火灾视频数据或测试火灾监控模型。而由固定的试验场所采集的数据则存在背景、干扰情况单一的缺陷。以上限制造成数据集中正样本(不同背景下的火灾视频)数量偏少,正负样本不平衡,限制了深度学习火灾识别算法的作用和效果。
为解决数据不平衡的问题,Kisantal等设计了多次复制小目标图像的数据增广(Data Argument, DA)方法以增加数据集中小目标图像的数量[2]。与常见的目标检测数据集不同,火焰没有明显的分割边缘。并且当火焰燃烧时自身产生的烟雾以及周围物体的颜色都会发生相应变化,这些因素都限制了火焰在场景中的提取与复制,同时限制了对火焰图像的增广。基于此,本文提出一种将火焰与场景相融合的方法。该模型满足火焰数据增广的三个要求:第一是火焰的多样性即生成的火焰形状、颜色等特征多样。第二是生成图像应尽量具备视觉真实性,即火焰的颜色、产生的烟雾及其附近物体的反光等,应符合该场景条件下的经验值。第三是添加火焰的区域与整体场景的拼接处应平滑地过渡。
由于生成对抗网络的应用(Generative Adversarial Network, GAN)[3]的应用,图像转换领域快速发展并取得了良好效果,本文任务由图像转换(Image-to-Image translation, I2I)完成。虽然目前已有多种不同功能的图像转换网络结构。比如,超分辨率重建[4-5], 语意合成[6-7], 图像增强[8-9]及 图像编辑[10-12]等。但以上应用中并没有适用于解决本文问题的方法。一方面,传统I2I方法的一个常见的限制是它们的确定性输出[5,7]。受到Gaty[13]的启发,文献[14-16]将图像信息分解为两部分:内容信息和风格信息。其中内容信息包含了图像潜在的空间结构、形状等在图像转换过程中需要保留的信息。而风格信息包含了纹理、颜色以及其他在转换中需要改变的信息等。但对同一个输入,这类方法只能得到一个固定的输出,无法满足在同一场景下火焰多样性的要求。
另一方面,虽然BicycleGAN[17]等多模态I2I提出在输出和隐空间之间使用双射变换,将图像的风格信息回归为白噪声,通过改变白噪声改变转换图像的风格,对同一图像的转换具有多样性的输出。然而噪声形式的解缠绕表达虽然可以增加输出的多样性,但无法确定生成图像的风格。类似地,Multimodal Unsupervised Image-to-Image Translation(MUNIT)[18]将图像的内容信息与风格信息分别解缠绕为隐编码的形式,通过改变代表风格的隐编码得到多样性的输出。但这种方法生成的图像清晰度低,而且通过编码器自动习得的隐编码没有明确的含义,可解释性差。在通过编码器抽取图像信息的同时,文献[19-20]通过显式编码控制图像生成。这些编码有明确意义,可解释性强。AgeGAN[19]采用了与InfoGAN[21]类似的方法,从由编码向量生成的图像中解缠绕出向量自身以初始化编码器。这个向量由白噪声以及表示年龄的条件编码c组成,通过c在转换阶段控制所生成人脸的年龄。Ganimation[20]则使用了表示人脸表情的17维向量控制生成人脸的表情。这种由编码形式的解缠绕表示所生成的图像有一个明显的缺陷,即图像信息就压缩至编码的过程中会造成信息的大量丢失,由编码重建图像时,引起失真问题。由于以上多模态I2I方法[18-20]主要在保留人脸发色、肤色的基础上重构五官,五官形状和背景颜色的改变是被允许的。但并不适合本文问题中保持背景细节的要求。
与编码形式的输入相比,可解释性更强的方法是使用图像输入。文献[22]将图像中解纠缠出的人脸编码与图像形式的五官轮廓结合,以重组人脸表情。文献[23]则使用了梯度意义的线条。Progressive Image Reconstruction Network with Edge and Color Domain(PI-REC)[24]使用色块与五官边缘,重建人脸。因为线条与色块比编码包含的信息更为准确具体,使用这种图像作为条件输入所获得的结果更加明确,可控性更强。
受到这种图像形式的显式表示方法的启发,从信息的保留与传递考虑,本文设计了以火焰图像作为条件输入的场景迁移模型,在保证转换图像背景细节质量的同时增强火焰的多样性、可控性。同时为了便于数据集制作,本文设计了基于CycleGAN的场景迁移模型以解除非匹配数据对于模型训练的限制。
2 问题描述
2.1 火焰场景融合
本文目的是寻求无火场景In在火焰形态c条件下到有火场景Iyc的映射:M:(In|c)→Iyc,通过改变c达到增加火焰多样性的目的。
由于编码形式的信息高度抽象,因此无法包含足够具体的信息准确描述火焰的形态、位置及其与背景的关系。通过编码器将条件c或风格信息映射到隐编码空间的方式会导致c的意义不明确,影响火焰形态的可控性。此外,以编码形式作为生成火焰的控制条件会引起图像其他位置的扭曲、变色,背景的细节将难以保持。
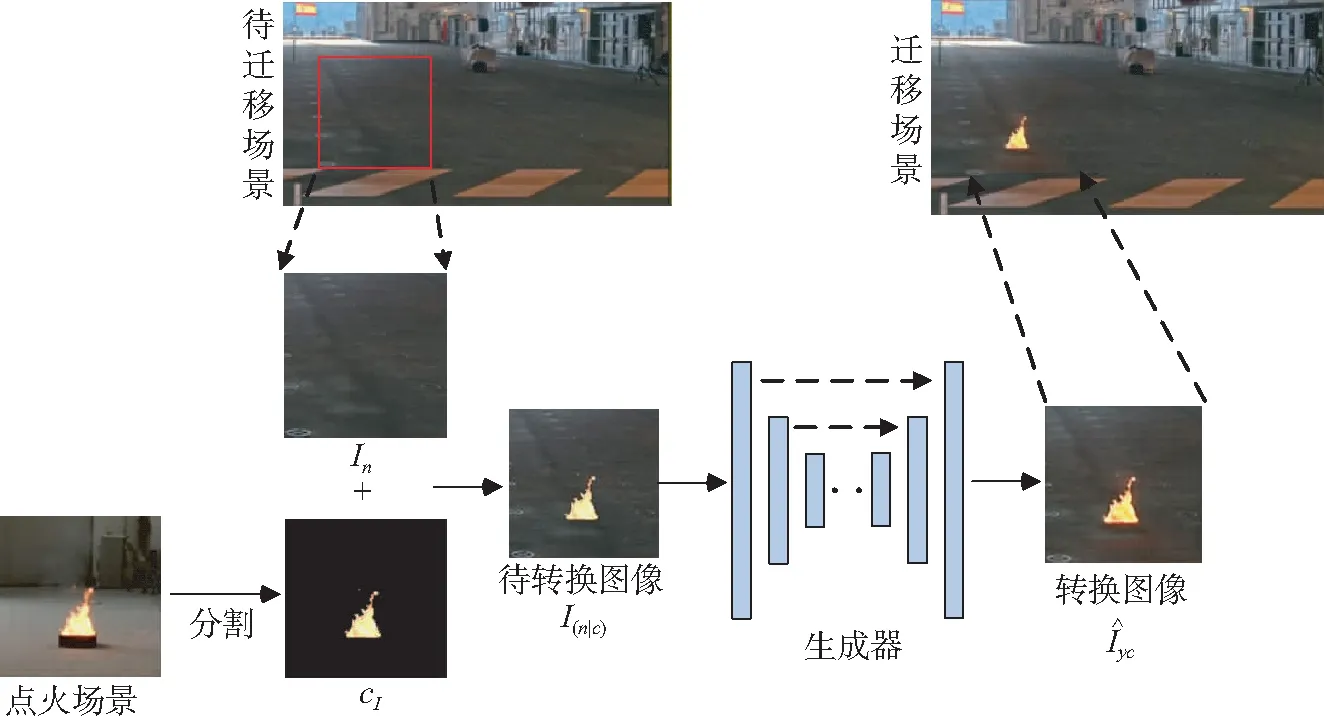
图1 火焰场景融合示意Fig.1 Model architecture of scene and flame fusing

图2 复杂场景下火焰分割缺陷示意Fig.2 Defect of flame segmentation in complex scenarios
考虑到以上因素,本文提出将映射M:(In|c)→Iyc中编码形式的条件c改为图像形式的条件cI。同时,将火焰也看作待转换图像的内容信息,将cI植入场景中,覆盖相应位置的背景像素。其中cI来自于已有视频中相似场景下的火焰,I(n|cI)与Iyc的差异表现在烟雾、物体的反光等火焰燃烧时对场景图像的纹理和颜色所造成的改变等方面,这些可以看作风格信息。I(n|cI)则以图像形式完整包含了着火场景中的内容信息如火焰的位置、形态和背景等,以明确的内容信息为基础进行图像转换,将迁移的火焰与场景相融合,从而避免因修改内容信息而引起生成图像失真。最终本文火焰场景融合方法的数学表示为映射M:I(n|cI)→Iyc,其流程如图1所示。
2.2 循环一致性对抗网络与非匹配数据集

图3 匹配与非匹配数据集Fig.3 Paired and unpaired datasets
一般情况下,样本的多样性越高,训练的网络模型处理复杂情况的稳定性越好。但数据集的制作难度随着场景的复杂程度增长:当火焰附近存在与火颜色相近的物体时;或在低光照条件下,光滑表面反射的火光与火焰颜色相似,都将难以从场景中分割出火焰(如图2红圈所示,彩图见期刊电子版)。如图4所示,为了降低数据制作的难度,本文在制作数据集时,将相同光照条件下由简单场景下分割出的火焰cI移植到复杂场景中作为I(n|cI);而将复杂场景中真实的火焰燃烧图像作为Iyc,通过CycleGAN结构训练图像转换网络。

图4 复杂场景下数据集制作示意Fig.4 Dataset production in complex scenarios
3 基于CycleGAN的场景迁移网络结构
3.1 模型整体结构
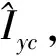
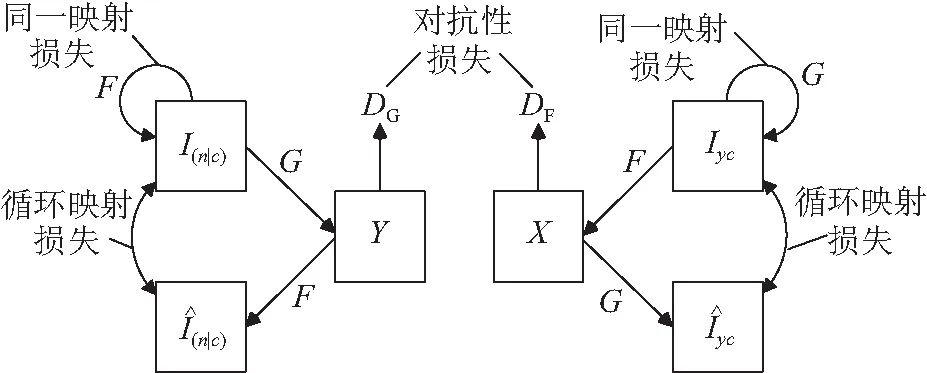
图5 网络整体结构Fig.5 Overall structure of network
由于循环一致性对抗网络形成了链状的映射结构,训练中无法清晰地界定G与F的映射关系。为了G与F学习到准确的映射关系,本文引入了同一映射损失,即当G与F各自将目标图像域中的图像仍然映射至各自的目标图像域中时,目标图像在转换后应与转换前保持一致。
3.2 生成器
本文的两个生成器G与F都使用了相同的结构,其结构如图6所示。为了避免背景在转换过程中产生形变采用了U-net[25]结构。U-net在编码器和解码器层与层之间具有跳跃连接,可以很好地避免输出图像模糊和扭曲。除此之外,注意力机制也被引入,用以提升火焰与场景融合的效果。
图6 生成器模型结构
Fig.6 Model structure of generator
3.3 注意力机制
不同于常见的图像转换任务,火焰场景迁移只需要对火焰及其周围进行相应转换。通过训练,注意力机制可以对感兴趣区域产生高度响应,从而有针对性地提升生成图像的质量。目前注意力机制可以根据情况和自身功能加载在生成器的前端[26]、中间[27]和末端[20]。为使最终生成的图像与场景的拼接可以更加自然,本文采用了图像遮罩[28]的方式融合转换前图像I(n|cI)与转换后图像If,并采用GANimagtion[20]中的方式训练注意力层。
图像遮罩可以表示为式(1):
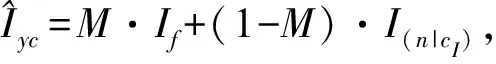
(1)
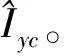
注意力损失函数为:
(2)
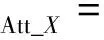
(3)
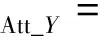
(4)
其中:A=G(I(n|cI)),B=F(Iyc),Ai,j,Bi,j表示图像矩阵A或B中第i行第j列的元素值。
3.4 判别器
由于图像的转换区域集中在火焰附近,因此本文的两个判别器DC和DF都使用了PatchGAN[6,29]的判别器结构。这种结构不是对图像的整体进行真实性评价,而是将整体图像分为N×N的小区域,分别判断每个区域的真实性。除了最后一层卷积层,每层卷积层之后都伴随有Leaky ReLU[30]激活层。通过Sigmoid函数将最后的输出归一化。判别器的结构如图7所示。
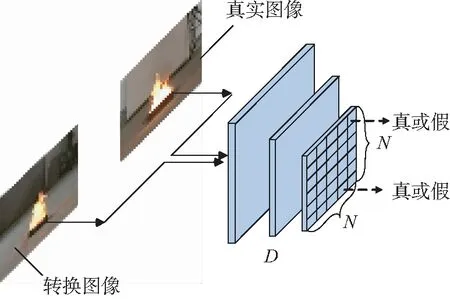
图7 判别器模型结构Fig.7 Structure of discriminator
3.5 损失函数
循环一致性损失:
(5)
其中:
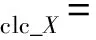
(6)
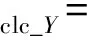
(7)
同一映射损失:
(8)
其中:
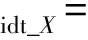
(9)
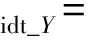
(10)
对于生成器G与判别器D,本文使用了训练过程相对稳定的Least Squares GAN(LSGAN)[31]作为对抗性损失。对于生成器的输入z与目标图像x,有:
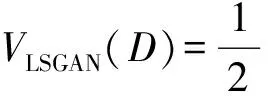
(11)
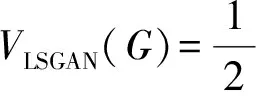
(12)
本文采用常用设置:a=0,c=1,b=1。
因此生成器G与判别器DG的损失函数分别为:
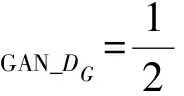
(13)
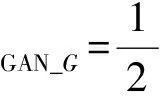
(14)
而生成器F与判别器DF的损失函数分别为:
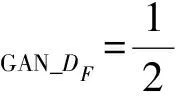
(15)
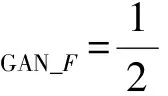
(16)
最终对抗性损失为:
(17)
训练整个网络的联合损失函数为:
(18)
本文设置λ1=5,λ2=0.5,λ3=1,λ4=10-5。
4 实验与结果分析
4.1 数据集和训练细节
本文在仓库场景下录制了20段视频,并记录了光照强度。本文实验参考仓库的照度标准,绝大多数视频的环境光照强度在50~400 Lux之间。以此为基础,分别制作了火焰图像数据集cI以及燃烧场景数据集Iy。
最终从16段视频中分别选用800张I(n|cI)和Iy图像用于训练。从另外4段视频中选取100对用于测试。对于难以分割火焰图像的复杂场景,本文从相同光照条件下的简单场景中分割出火焰cI植入复杂场景相同位置作为I(n|cI),而将实际录制的复杂场景中的燃烧图像作为Iyc。对于简单场景,则使用不同时刻的I(n|cI)与Iyc。因此,I(n|cI)与Iyc是非匹配的。
本文实验均使用Pytorch0.4.1深度学习框架,在英伟达GPU(泰坦Pascal X)进行训练。BicycleGAN,MUNIT以及本文模型都使用Adam优化的随机梯度下降法(Stochastic Gradient Descent,SGD)更新网络参数(β1= 0.5,β2= 0.999),学习率lr分别为0.000 2,0.000 2,0.000 1, Batchsize=1,本文模型训练200Epoch, BicycleGAN训练200Epoch, MUNIT训练400Epoch分别达到稳定的结果。
AgeGAN使用Adam优化的SGD(β1= 0.5,β2= 0.999), 学习率lr=0.001, Batchsize=32,训练200Epoch达到稳定的结果。
4.2 评价方式
本文通过消融实验对模型结构进行评价及分析;通过与BicycleGAN、MUNIT等相关模型的比较对火焰迁移模型进行定性评价;通过FID(Fréchet Inception Distance)[32-33]和Learned Perceptual Image Patch Similarity(LPIPS)[34]两个接近人类视觉的评价指标对图像质量进行定量评价。
Fréchet距离用于衡量两个高斯分布的差异,FID计算两个图片集在InceptionNet[35]各层间响应的Fréchet距离衡量两组图像的差异。
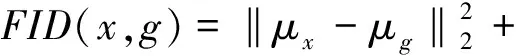
(19)
对不断增加的干扰而言,FID的测试结果与人类的判断相一致。与IS[36]相比,FID对噪声的抵抗能力较强,对模型坍塌更加敏感。较低的FID意味着较高的图片质量和多样性。
LPIPS 通过计算生成图像与实际图像映射在预训练的DCNN特征空间的距离评价生成图像与实际图像的相似度。LPIPS也展示出了与人类视觉相似的评价体系,与传统的图像相似度度量方法不同[37],感知相似度对噪声更不敏感,对模糊更敏感。LPIPS值越小,生成图像在人类感知上越接近真实图像。LPIPS可以表示为:
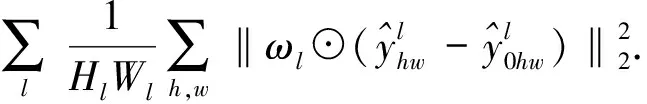
(20)
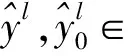
本文取测试图像的均值:
(21)
4.3 消融实验
4.3.1 模型作用评估
在第1节中讨论了图像形式的条件cI在图像转换上的不同影响。图8(f)展示出本文的方法具有保持背景图像质量和增强火焰真实性的优点,这一优势同样在图8(e)和图8(g)中有所体现。图8(f)给出了本文模型的转换结果,它对移植了火焰的场景进行转换(图8(d))。图8(a)给出了相同结构下,使用场景进行转换得到的结果,可以看出它只会生硬地添加火焰图像。
另一方面,直接对图像进行转换而不是通过编码重建图像的方式也便于选择带有跳跃连接的生成器以维持背景图像的清晰度。与图8(f)相比,通过编码器-解码器(Encoder-Decoder)[14]方式生成的图像(图8(g))背景颜色改变较大,说明U-net在维持背景方面具有优势。

图8 消融实验结果对比Fig.8 Result comparison of ablation experiment
4.3.2 注意力机制评估
在没有注意力结构的情况下,本文的模型采用了图像翻译过程中最简单的方法,即接近一致地改变输入背景的颜色(图8(e))。而采用注意力结构的生成器将背景颜色的改变限制在火焰的附近(图8(f)),使结果更加真实。可以相信,随着数据集的扩充和训练的进行,这种能力会得到更大提升。

图9 场景光照强度对注意力的影响Fig.9 Scene illumination intensity effects on attention mechanism
4.4 迁移图像与环境的关系
4.4.1 光照强度对迁移效果的影响
本文将不同光照强度下拍摄的火焰迁移至同一场景中以分析火焰颜色特征对转换效果的影响。图11中火焰内核图像取自于图10所示场景。图10中场景光照强度从左到右分别为78、140、180、400、1 500 Lux。而图11中3个场景的光照强度分别为186、50、32 Lux。

图10 火焰内核来源,图像下方为场景光照强度Fig.10 Sources of fire kernel, labels below each figure is illumination intensity of the scene

图11 不同光照强度下火焰的迁移结果(火焰内核来自于图9)Fig.11 Migration results of flame recorded at different illumination intensity(fire kernels taken from Fig.9)
可以看出,火焰在地面的反射光几乎不受迁移场景光照强度的影响,而是与火焰内核的颜色相关。火焰亮度越高,迁移进场景地面反射光越强烈。并且,由于32 Lux的场景中地面的灰度值最低,转换图像的地面反光是这3个场景中最强的。当场景光照强度达到400 Lux时,无论是真实图像还是转换图像,火焰附近都难以看到地面的反光。从图11可以看出,在同样的场景中,火焰面积越大,地面的反光越强,这说明除了火焰颜色,火焰面积也是控制转换结果的一个条件因素。因此可以推断出本文的模型主要是根据火焰的颜色特征和火焰附近背景的灰度值而补充相应的反射和火焰的边缘。这是符合常识和预期的,因为摄像机的光圈会自动调整曝光以适应不同的光照强度,因此场景图像不会因为光照强度变化显示出非常大的区别。而火焰的明度通常在一个固定的区间内,因此不同曝光下的火焰图像呈现出不同的颜色特征。
4.4.2 风对迁移效果的影响
当环境中有风时,火焰受风的影响几何中心发生偏移。相应地,火焰在地面反光的中心也会随之偏移。图12选取了3张因风吹而偏移中心位置的火焰(图12(a)),将其迁移至4个不同场景之中(图12(b)~图12(e))。可以看出,4个场景的火焰迁移结果都体现出这一改变。因为训练集中绝大部分图像火焰下方位置是盛放燃油的油盘,而迁移场景在该位置缺少油盘,图像转换网络无法对该区域做出合理转换,因此图12(d)和图12(e)效果略差。

图12 风对室内火焰场景迁移的影响
Fig.12 Wind effects on scene migration of indoor flame
4.5 与其他方法的比较
在图13中,本文将MUNIT,AgeGAN,BicycleGAN以及本文方法用于火焰与场景融合的效果进行了定性比较。其中,对MUNIT和BicycleGAN分别使用了场景(bg)和移植了火焰的场景(ip)两种图像作为待转换图像进行训练。本文的模型在火焰真实性和背景分辨率保持方面都优于最先进的方法。总体来说,MUNIT,AgeGAN及BicycleGAN显示出了使用隐式编码表示图像的缺陷,而且使用移植了火焰的场景(ip)作为待转换图像所得结果优于将场景(bg)作为输入。在仅用场景作为输入的结果中,BicycleGAN(图13(a))只能生硬地向场景图像中添加火焰,而MUNIT(图13(b))及AgeGAN(图13(c))则无法描述火焰位置。并且这种生硬的映射改变了图像的内容信息,导致转换图像背景的大面积失真。
尽管通过向场景移植火焰以完善待转换图像的内容信息,但是BicycleGAN中固定长度为8的样式向量不能包含足够的信息来完美地表示图像风格,最终导致图像中出现不均匀的色块(图13(e))。同样, MUNIT提取的固定长度风格及内容向量不能包含足够的信息保证重建图像的分辨率(图13(d))。简单地增加向量的长度对于背景分辨率的保持是徒劳的。在这一点上,本文的模型不仅输入具有明确的内容空间,可以准确地描述画面结构,而且生成器中的跳跃连接可以将图像的背景的分辨率保持在较高质量(图9(b))。各主要相关方法的关键差异见表1。
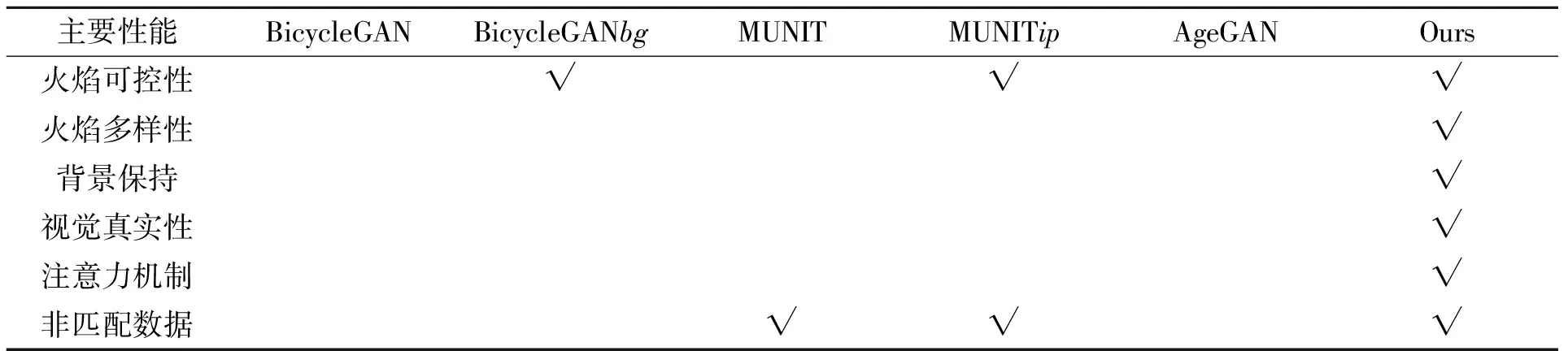
表1 本文及相关方法的主要性能比较
图13 AgeGAN、MUNIT及BicycleGAN用于火焰迁移的结果比较
Fig.13 Comparison between AgeGAN, MUNIT and BicycleGAN used for fire migration
4.6 质量评价
本文对比了MUNIT,BicycleGAN,AgeGAN以及本文模型在重建的场景图像与实际场景图像间的FID与LPIPS值。其中,MUNIT和BicycleGAN分别使用了单纯的背景(bg)和植入了火焰的背景(ip)作为待转换图像。从表2可知,单纯的背景输入(BicycleGANbg,MUNITbg,AgeGAN)所得结果在FID与LPIPS值上与植入火焰的背景(BicycleGANtp,MUNITtp,Ours)差距明显,侧面反映了图像形式的条件输入在处理本文问题上所具有的优势。与BicycleGANtp和MUNITtp相比,用本文模型重建的图像的FID与LPIPS值是最小的,分别为119.6和0.134 2,说明同样以植入了火焰的背景作为输入的情况下,本文模型火焰场景迁移问题上仍然优于BicycleGAN与MUNIT。
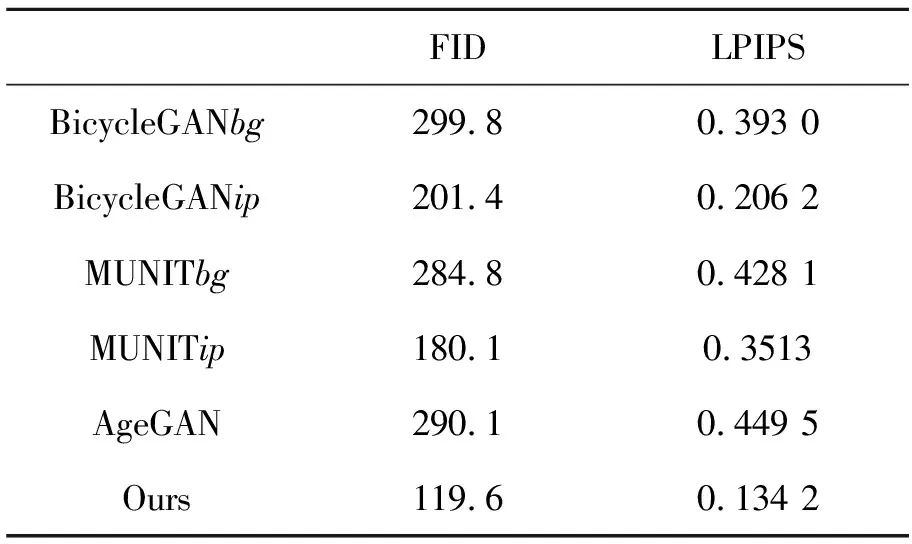
表2 不同模型的FID与LPIPS
4.6 讨 论
不同于常见的图像转换,本文问题聚焦于火焰周围图像而不是整体图像的风格变化。因此本文选择添加注意力层以限制图像转换的区域。虽然注意力结构的使用提升了火焰场景融合的效果,可以更加准确地在火焰附近的地面添加火光倒影,但无法完全达到人类经验和逻辑水平。一定程度上,由于火焰根部的储油盘是黑色的,吸收了大量的可见光,无法显示出I(n|cI)与Iyc的差异,影响了学习的效果。另外由于存在拍摄距离、角度、背景亮度和火焰大小等干扰因素,相同光照强度下所拍摄火焰的亮度以及地面反光存在差异。总体而言,场景环境中光照强度高,火焰图像颜色偏黄,地面的火焰反射光越淡;光照强度低,火焰图像颜色偏青,地面的火焰反光越明显。转换模型能够根据经验,依据火焰颜色、面积以及场景的颜色向图像中添加火焰虚化的边缘和地面的反光。
5 结 论
本文提出了一种新的室内火焰燃烧图像的场景迁移方法。该方法基于循环一致性生成对抗网络并添加了注意力结构以提升效果,通过迁移其它视频中的火焰图像在未点火场景中生成火焰,目前该领域尚未有人做出相关研究。从信息的保留与传递考虑,该方法以显式的图像形式取代隐式的编码以表示火焰形态,在改善火焰的可控性和生成图像的真实性,以及维持转换图像高质量的背景细节方面取得了良好的表现。实验表明,与BicycleGAN、MUNIT以及AgeGAN等采用编码方式控制图像生成的方法相比,本文方法改善了控制条件的可解释性从而提升了火焰形态的可控性,并且取得了相对逼真的效果。通过在测试集上使用FID和LPIPS两个接近人类视觉的评价方式对转换结果的打分显示,本文方法所得结果最为真实,其分值分别为119.6和0.134 2。在一定程度上,这项工作可以用来制作和增广危险场合下的火焰燃烧图像及训练集。
猜你喜欢
音乐天地(音乐创作版)(2022年1期)2022-04-26
汽车工程师(2021年12期)2022-01-17
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09
学苑创造·A版(2021年2期)2021-03-11
当代陕西(2020年14期)2021-01-08
汉字汉语研究(2020年2期)2020-08-13
奥秘(创新大赛)(2020年7期)2020-07-27
电子制作(2019年22期)2020-01-14
动漫星空(兴趣百科)(2019年5期)2019-05-11
疯狂英语·新读写(2018年3期)2018-11-29
