
基于最大幅值变分模态分解和均方根熵的滚动轴承故障诊断
2020-05-29 11:54岳建辉邢婷婷
计量学报 2020年4期
孟 宗, 岳建辉, 邢婷婷,2, 李 晶, 殷 娜
(1. 燕山大学电气工程学院, 河北 秦皇岛 066004;2. 唐山工业职业技术学院, 河北 唐山 063000)
1 引 言
滚动轴承是机械设备中最容易损坏的元件之一,据统计,在使用滚动轴承的旋转机械中,大约有30%的机械故障都是由滚动轴承引起的。滚动轴承工作状态直接影响整台机械设备安全可靠运行,因此,对滚动轴承进行故障诊断具有十分重要的意义[1,2]。滚动轴承的振动信号包含着丰富的故障特征信息,当发生故障时,振动信号表现出非线性与非平稳性。变分模态分解(variational mode decomposition, VMD)[3]作为一种自适应时频分析方法,能将复杂的非平稳信号分解成若干个本征模态函数(intrinsic mode function, IMF),且能有效减弱经验模态分解(empirical mode decomposition, EMD)[4]和局部均值分解(local mean decomposition, LMD)[5]方法中出现的模态混叠和端点效应问题。但VMD中分解层数K需提前设定,由于IMF必须遵循窄带特性,若K值过小会违背此性质并使分解不彻底;过大会使分量中产生虚假成分[6~8],影响特征提取的准确性及故障诊断结果。因此,最优K值的选取方法是影响VMD算法的关键因素。为使IMF分量中所包含的有效信息得到准确体现,熵被广泛应用于故障信号的特征提取中[9~11]。丁闯等[12]将排列熵(permutation entropy, PE)作为特征量应用在故障诊断中,实现故障类型判别。均方根熵(root mean square entropy, RMSE)是针对每组信号的所有分量进行计算,反映了不同故障信号振动能量的不同,相比于排列熵计算量更少,可引入VMD中对多种不同的轴承故障进行分类识别[13]。
为了找到模态参数的最佳值,本文提出一种预设K值的方法,利用VMD分解时各分量频率的最大幅值(maximum amplitude, MA)特性来选择合适的K值。并以均方根熵作为特征提取量,与粒子群算法(particle swarm optimization, PSO)优化的支持向量机(support vector machine, SVM)共同搭建故障分类模型。最后,通过滚动轴承实测信号进行实验,验证本文方法的有效性。
2 基于MA的VMD参数确定方法
2.1 VMD算法
VMD是一种完全非递归的分解方法,其关键问题是变分模型的构建和求解。
首先,假设将原信号s分解为K个IMF分量uk(t),k=1,2,…,K,对其做Hilbert变换,得到各模态解析信号;其次,预估解析信号中心频率e-jωkt,将每个模态的频谱调制到相应的基频带;最后,计算解调信号梯度的平方L2范数,估计各模态信号带宽[14]。由此可得约束变分模型为:
(1)
式中:{uk}={u1,…,uk}为分解得到的K个模态分量;{ωk}={ω1,…,ωk}为各分量的中心频率;t为中心频率对应的时刻;*代表卷积运算。
变分问题的求解即是求K个模态函数uk(t),使每个模态的估计带宽之和最小。为求取约束变分问题的最优解,引入二次惩罚因子α和Lagrange算子λ(t),将变分问题由约束性变为非约束性,则式(1)变为增广Lagrange表达式,即:
(2)
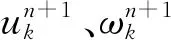
(3)
(4)
(5)
在VMD求解过程中,各模态分量的中心频率及带宽不断更新,实现信号的自适应分解,其中,迭代终止条件为:
(6)
2.2 MA-VMD原理
振幅在整个频率段随频率的变化而改变,而中心频率对应的幅值即为整个分量中的MA为Amax。基于快速傅里叶变换(FFT)理论求取Amax时,若设X(n) 为一长度为N的序列,则它的离散傅里叶变换(DFT)定义为:
(7)
式中:n=0,1,…,N-1;WN=e-j 2π /N。
在VMD分解中,若K值过大,会出现虚假分量或过分解2种情况:出现虚假分量时:该分量经迭代所得的中心频率模糊,其对应幅值虽然在本分量中是最大值但相对其它分量却极小;过分解时:会产生两中心频率非常接近的情况,由于中心频率与Amax之间的一一对应关系,也会出现2个Amax近似现象。这2种情况不会同时出现,若在第1种情况中出现了相近Amax,可能是信号本身存在相近频率成分,不可轻易舍弃。由以上几点即可确定最优分解层数的取值,避免了以往只观察相近中心频率从而产生漏判的现象,具体实现步骤如下:
1) 将分解层数由小到大预设为多个连续数值;
2) 分别进行变分模态分解,计算各分量在每一采样点的幅值;
3) 选取各层的Amax;
4) 当取模态个数为m时,若第m层Amax相较于其余几层Amax非常小,则可认为第m层为虚假分量。此时,若剩余几层Amax均不相近,则取K=m-1进行分解;若剩余几层有相近Amax,则取K=m进行分解,后续应用时将虚假分量去除即可;
5) 当取模态个数为m时,若步骤4不成立,只出现邻近两层Amax十分接近,则可认为此时产生了过分解,直接取K=m-1进行分解,并将其分量全部应用于后续操作中。
3 均方根熵
均方根误差(eRMS)标志着振动信号采样周期内瞬时信号幅度的变化,能反映不同振动信号的振动能量。信息熵用来表示由多种不确定因素导致的系统复杂程度。将均方根融入信息熵中得到均方根熵(ERMS),此熵综合了二者的优势,可用不同的均方根熵值代表不同的故障类型,均方根熵的计算过程为:
1) 计算VMD分解后各IMF分量的均方根值:
(8)
式中:Ri为第i个分量的均方根值;N为样本点的个数。
2) 将均方根值组成特征向量A:
A=[R1,R2,…,Rk]
(9)
3) 归一化均方根值:
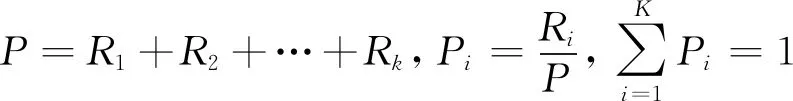
(10)
4) 均方根熵可由信息熵定义得到:
(11)
式中:K为IMF分量个数;ERMS为均方根熵。不同振动信号的均方根熵同样可以求得。
4 基于MA-VMD和均方根熵的故障诊断
基于MA-VMD和均方根熵的故障诊断方法的具体步骤为: 1) 对滚动轴承的M种状态分别进行L组采样,得到M×L组样本数据; 2) 利用MA-VMD方法对每种状态下的原始信号进行分解,通过判断是否产生过分解确定最佳分解层数K; 3) 对M种状态的L组采样数据进行VMD分解,分别得到K个分量,结合K个分量计算每组的均方根熵值; 4) 分别将每种状态的前L/2组ERMS构成特征向量T=[ERMS,1,ERMS,2,…,ERMS,L/2];5) 将T作为训练样本,输入PSO-SVM中进行训练;6) 将每种状态剩余L/2组ERMS作为测试样本,输入训练后的PSO-SVM,由输出结果判定测试样本的状态类型。
5 实验研究
采用美国西储大学的滚动轴承数据进行实验,实验使用电火花加工技术在深沟球轴承上制造故障直径为0.533 4 mm的单点故障,并设置转速为 1 730 r/min, 采样频率为12 kHZ,采样点数为 2 048, 使用加速度传感器采集正常状态、内圈故障、外圈故障和滚动体故障4种状态下的轴承振动数据。图1为4种不同状态的时域波形。
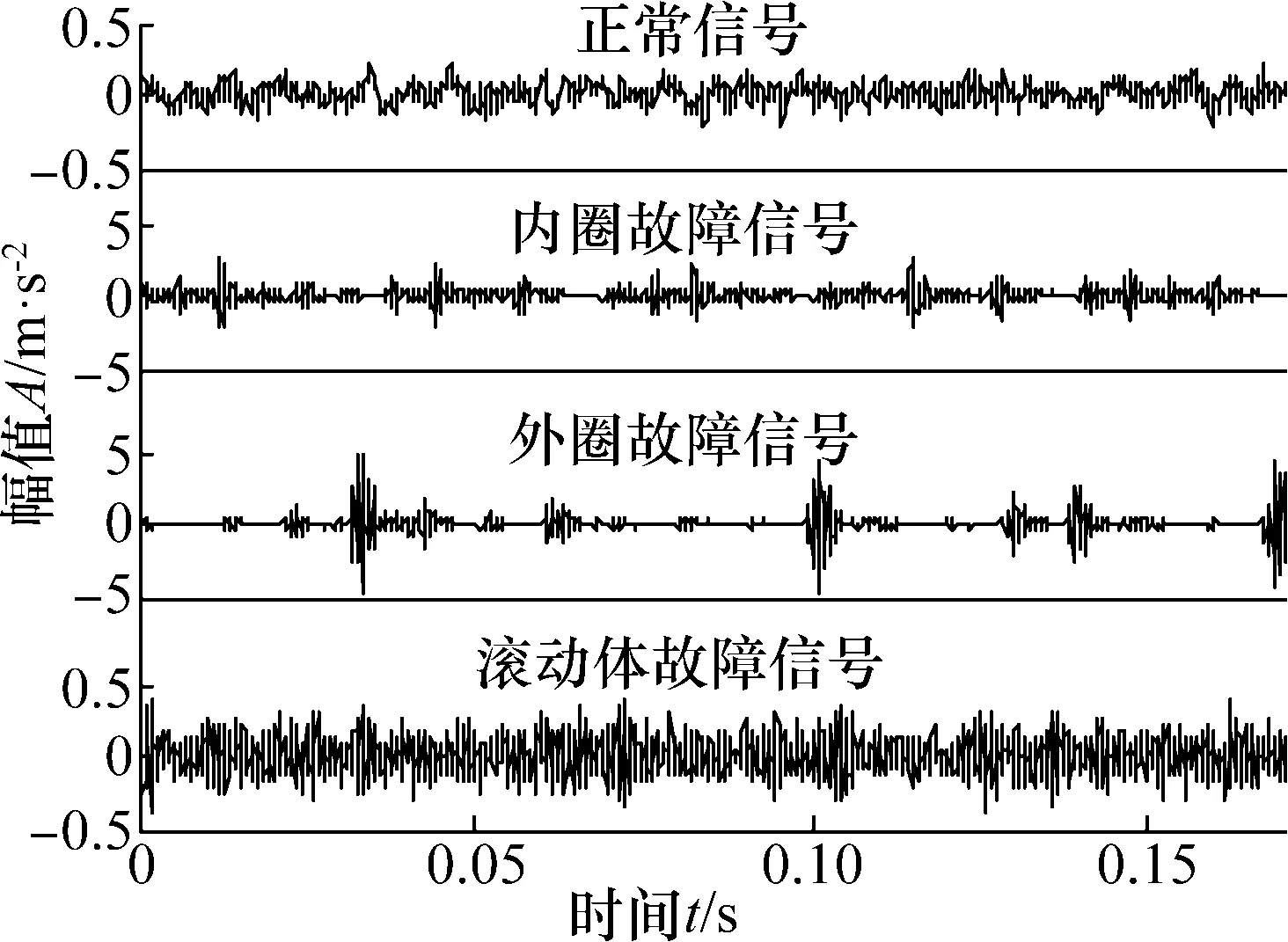
图1 4种状态时域波形图
5.1 MA-VMD分解实验
将MA-VMD应用于实际滚动轴承信号中。通过预设K值并对各分量的Amax进行分析得出4种状态的K值设定情况为:正常状态4层;内圈和外圈故障均6层;滚动体故障5层。运用预分解方法确定K值,即将LMD的分解层数应用到VMD中,结果为:正常状态5层,内圈、外圈和滚动体分别6层。本文将2种方法对滚动体信号进行分解时的差异表示在图2中;且滚动体信号在MA-VMD方法不同K值下的Amax如表1所示。
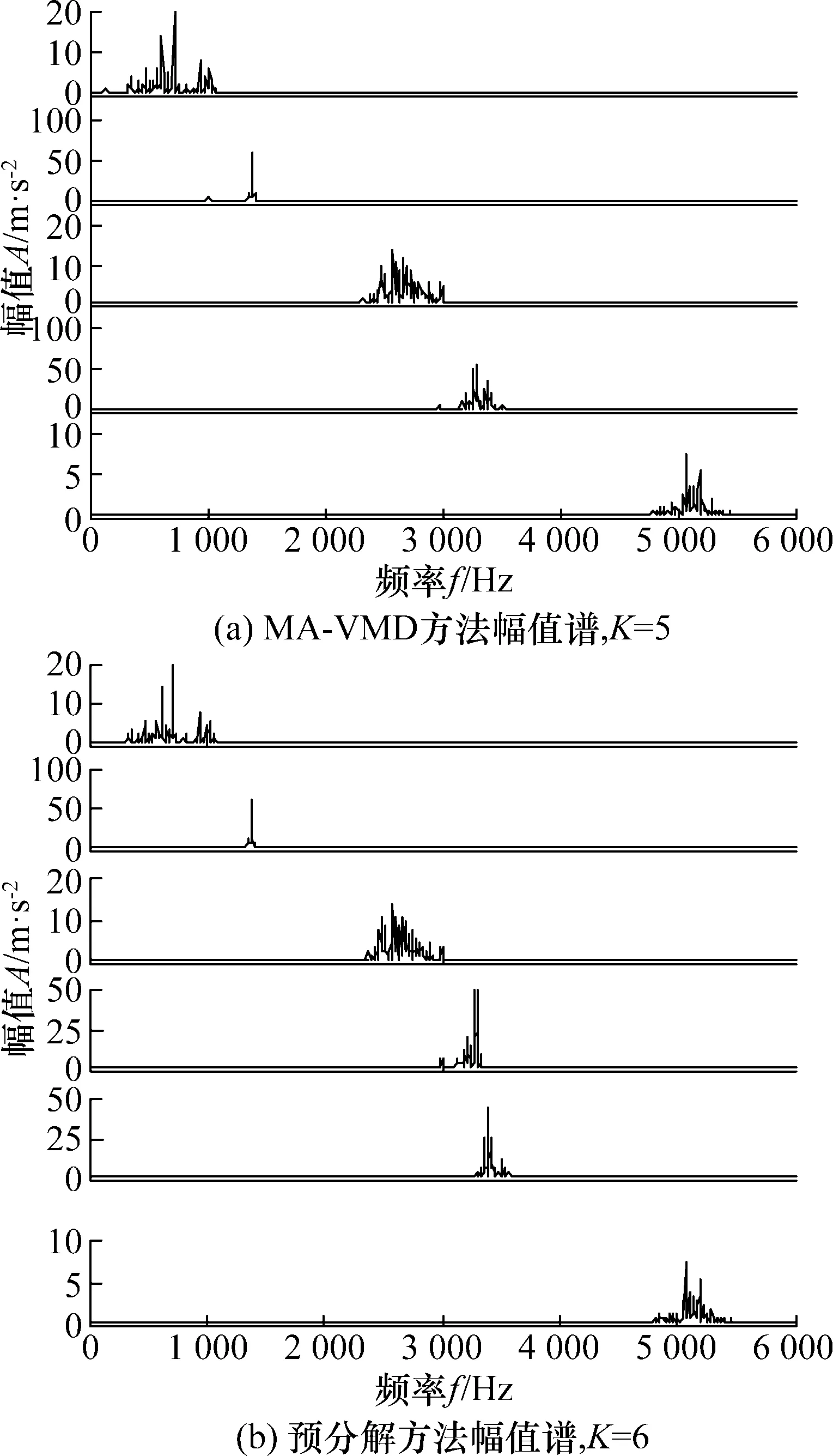
图2 2种方法对滚动体信号的分解差异
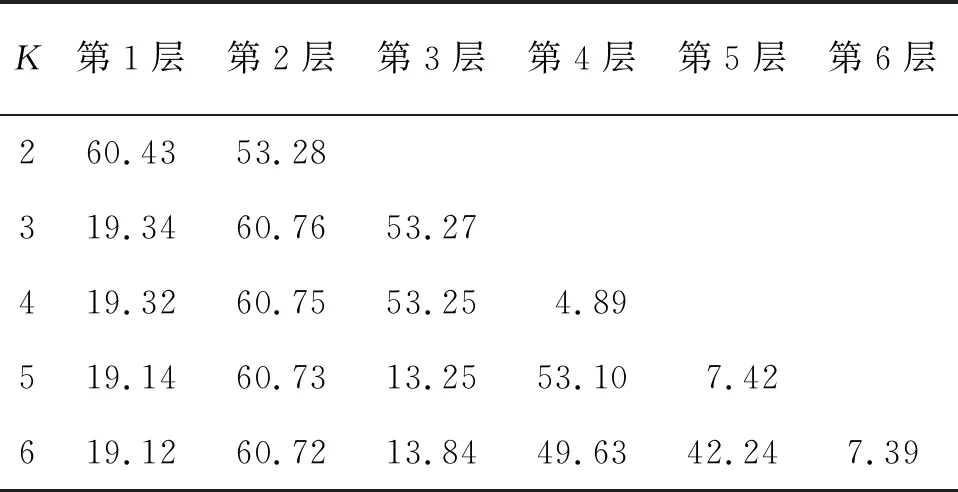
表1 不同K值下各层的Amax
由表1可知:相比于其它K值,当K=6时,出现了更明显的相邻层Amax接近情况,根据MA-VMD中理论可认为此时产生了过分解,在此可取VMD的最佳模态个数为5。
由图2可以看出,在MA-VMD方法下,滚动体信号被分解为5层,且每一层中频率分布没有混叠,分解效果良好;而在预分解方法下,滚动体信号被分解为6层,在幅值谱中出现了混频,即过分解现象。对比可知,MA-VMD方法下所得的分解效果优于预分解法。
5.2 均方根熵特征提取实验
对4种不同状态分别采集40组振动信号作为样本,进行MA-VMD分解和预分解,并计算分解之后每一组的均方根熵值。图3为利用本文MA-VMD方法随机抽取的15组样本的ERMS值排列情况。图4为预分解法下随机抽取的15组样本的ERMS值排列情况。使用MA-VMD方法对信号进行分解后,选取前3个分量,计算其PE。图5为4种信号各15组样本的排列熵均值分布情况。
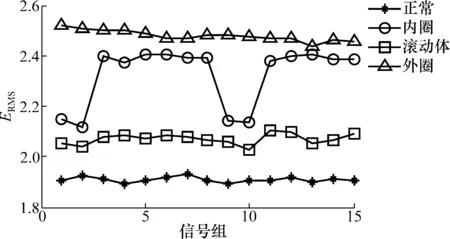
图3 4种状态15组样本的ERMS分布(MA-VMD)
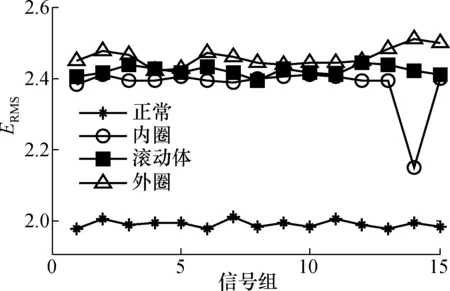
图4 4种状态15组样本的ERMS分布(预分解法)
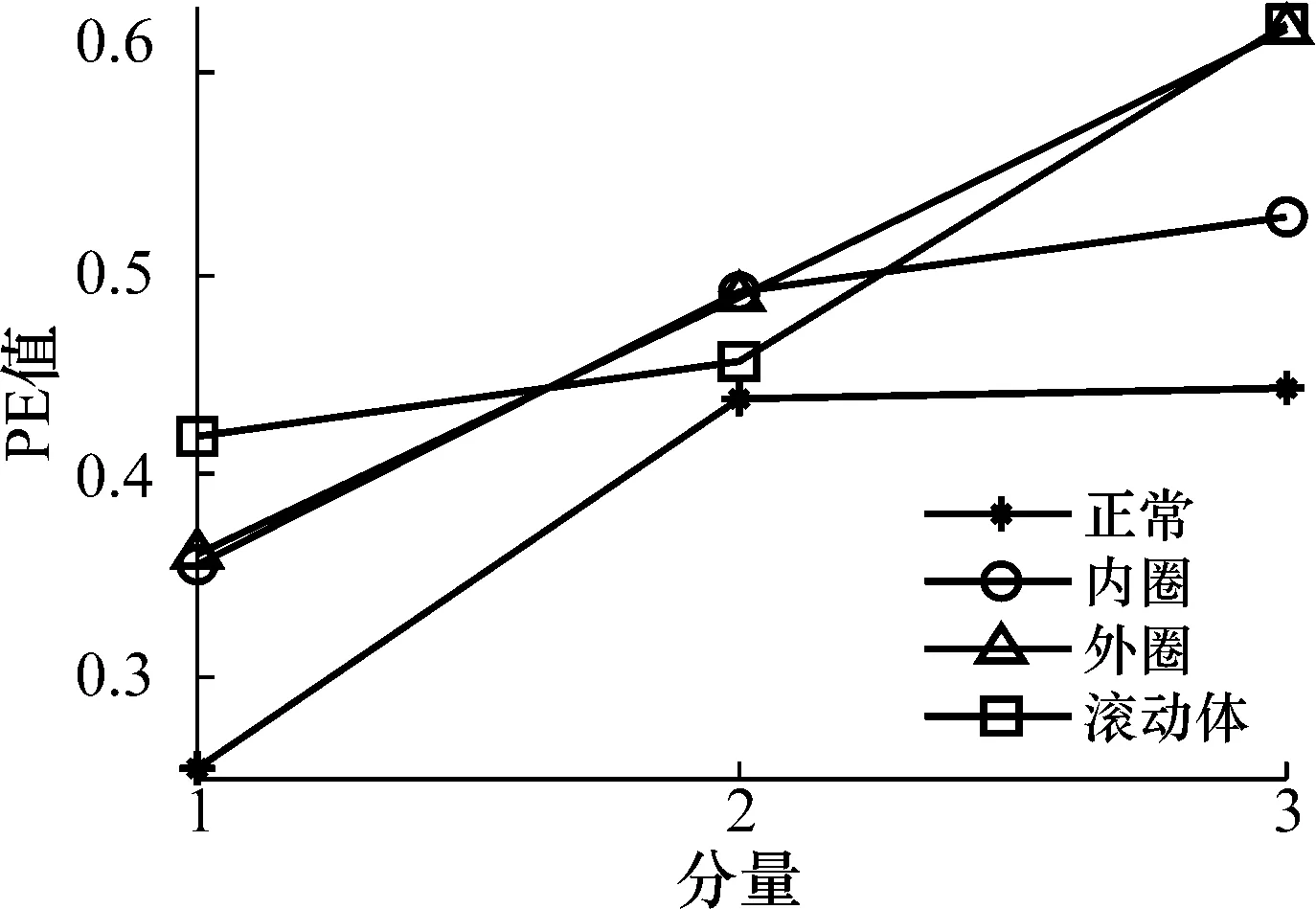
图5 15组样本排列熵均值分布图(MA-VMD)
由图3可知,针对不同的故障类型,其ERMS值在不同的数值范围波动,经排列对比可大致对故障进行分类。观察图4,可以看出此时有3种状态的ERMS值非常接近,不利于接下来SVM对其进行训练。在图5中,可以看出4种信号前3个分量的排列熵均值有一些交叉,对最终的训练及分类结果会产生干扰。
5.3 滚动轴承故障分类对比实验
对信号分解后,选取每种状态40组数据中的前20组组成特征向量,作为PSO-SVM的训练样本,剩余20组作为测试样本,并通过训练样本来搭建网络模型。图6~图8分别为采用本文MA-VMD法与ERMS进行分类、预分解法与ERMS进行分类、MA-VMD法与排列熵进行分类的效果图。图6~图8中,纵坐标的1代表正常状态,2代表内圈故障,3代表外圈故障,4代表滚动体故障。
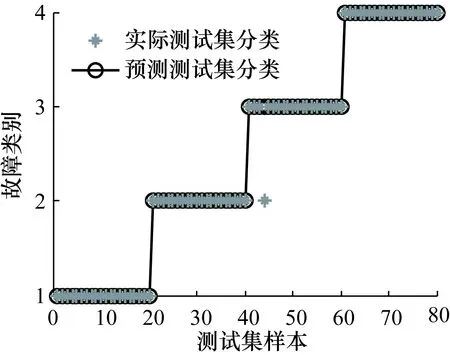
图6 MA-VMD法+ERMS分类效果图

图7 预分解法+ERMS分类效果图
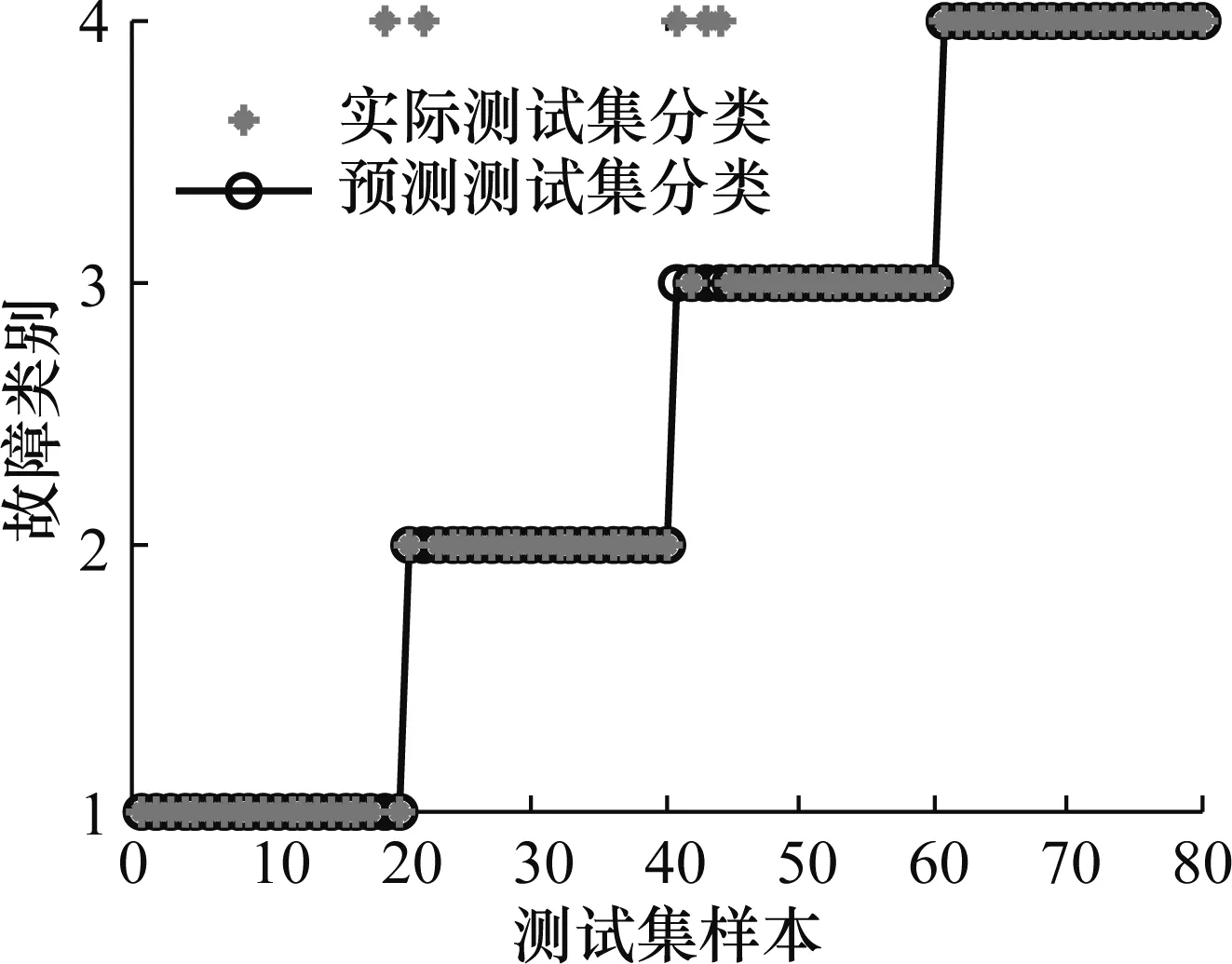
图8 MA-VMD+PE分类效果图
表2为3种方法对4种轴承状态的分类准确率对比情况。
通过表2可以看到,预分解方法下提取ERMS作为特征参量,对内圈、外圈和滚动体的识别准确率为83.75%。但是采用本文方法,将ERMS作为特征向量融入MA-VMD方法中,能将正常状态、内圈故障、滚动体故障进行100%的正确分类,对4种状态整体识别准确率也高达98.75%。
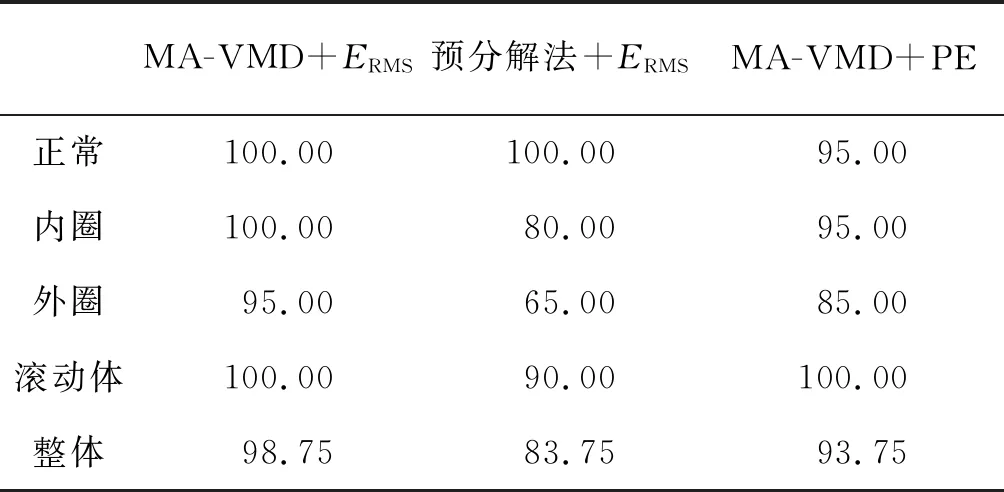
表2 3种方法分类准确率比较
6 结 论
基于最大幅值变分模态分解和均方根熵的滚动轴承故障诊断,本文 针对VMD模态个数的设定问题,将MA-VMD方法与预分解法进行对比,并同时结合ERMS进行分类识别,结果表明,本文方法可实现VMD参数K的最优选取,对故障特征的提取和分类处理起到关键作用。
针对特征提取问题,将本文所用ERMS与PE进行对比,并同时结合MA-VMD方法,通过实验对比,表明均方根熵相较于排列熵有更高的分类准确率,最终可验证本文所采用的基于MA-VMD和均方根熵的滚动轴承故障诊断方法是一种可行的滚动轴承故障识别分类方法。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
昆明医科大学学报(2022年3期)2022-04-19
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09
当代陕西(2019年19期)2019-11-23
智族GQ(2019年9期)2019-10-28
飞天(2019年6期)2019-07-08
英美文学研究论丛(2018年1期)2018-08-16
自动化学报(2017年2期)2017-04-04
新高考·高二数学(2015年2期)2015-05-27
新高考·高二数学(2014年7期)2014-09-18
