
改进VGG 网络的多聚焦图像的融合方法
2020-06-16 01:41陈清江汪泽百柴昱洲
应用光学 2020年3期
陈清江,汪泽百,柴昱洲
(1. 西安建筑科技大学 理学院,陕西 西安 710055;2. 中国空间技术研究院西安分院,陕西 西安 710100)
引言
图像融合是图像处理中的重要部分,能够协同利用同一场景的多种传感器图像信息,输出一幅更适合于人类视觉感知或计算机进一步处理与分析的融合图像。它可明显改善单一传感器的不足,提高结果图像的清晰度及信息包含量,有利于更为准确、可靠、全面地获取目标或场景信息。
在可见光图像中成像设备捕获目标图像,对于捕获目标部分的有效聚焦图像是清晰可见的,而非目标区域的其他物体则为模糊。因此,对于光学透镜捕捉的成像图很难做到所有物体处处聚焦,提出多种多焦点图像融合算法[1]。总的来说,这些方法可以分为两类:变换域方法和空间域方法[2],多尺度变换(MST)是最常用的变换域方法之一。传统的融合方法包括基于金字塔的图像融合[3]、基于剪切变换图像融合和基于非子采样轮廓变换(NSCT)[4]的图像融合算法等。最近提出的融合方法包括基于像素的融合方法,主要有引导滤波(DSIFT)[2]、基于多尺度加权梯度的图像融合算法(MWGF)[5]、基于低秩矩阵(LRR)[6]的多聚焦噪声图像融合算法、基于离散小波变换的多聚焦图像融合算法[7],随着深度学习的发展,结合深度学习解决多聚焦图像融合[8]的方法得到广泛推广,如基于卷积神经网络(CNN)的多聚焦图像融合[9-10]、基于全卷积网络的多聚焦图像融合[11-12]。对于一个简单的二分类问题,本文优先选择精度相对较高的VGGNet网络[13]进行修改。输入子块的多特征,保证了图像的分类精度。全图处理容易损失较多高频信息,于是本文只对左右图像的混合聚焦散焦部分进行处理,在信息熵、互信息等方面得到较好的融合效果。
1 网络结构模型
1.1 VGG16 模型介绍
VGGNet[13]是由牛津大学的K.Simonyan 和A.Zisserman 提出的卷积神经网络模型,该模型诠释了隐层深度对于预测精度的影响,训练时间和AlexNet 相比大大减少。该模型在ImageNet 中达到了92.7%的top5 测试精度,VGGNet 结构根据层数的不同分为不同的版本,常用的结构是VGG16和VGG19,在VGG16 中所有的卷积层都有相同的配置,卷积层中卷积核大小为 3×3,步长大小为1,最大池化层共5 个,其核大小都为 2×2,步长为2;全连接层共3 个,前两层共有4 096 个通道,第3 层共1 000 个标签类别;最后一层为Softmax 层;所有隐层后都带有ReLU 非线性激活函数,总体结构如图1 所示。

图 1 VGG16 网络模型Fig. 1 VGG16 network model
1.2 Crop-VGG 网络结构
本文只需要处理聚焦图和散焦图的简单二分类问题,并不需要过深的隐层,多个残余的隐层影响了训练速率,通过逐个隐层删除,部分隐层添加,最终设计为本文的Crop-VGG 网络,在保证精度的同时提高了训练速率。
如图2 所示,Crop-VGG 是基于VGG16 对二分类问题的更改,并不需要过深的网络层,于是裁剪了一部分网络,在保留原有分类效果的同时,提高分类速度。与原网络相比,Crop-VGG 卷积层卷积核大小、池化层大小、步长都与原VGG 网络保持一致,区别在于卷积层数由原来的13 变为8,由2-2-3-3-3 变为了2-3-3 结构,最大池化层由5 个变为3 个,卷积层中卷积核大小都为 3×3,步长为1,最大池化层核大小 2×2,步长为2;全连接层共3 层,前两层通道数由原来的4 096 变为2 048,输出类别变为2,每个隐层都跟有非线性激活函数ReLU,最后一层为Softmax 层。基于caffe 框架下,将预处理数据集网络训练,随着迭代次数增加,loss 的收敛速度有明显提升,随着迭代次数增加,当loss 值达到收敛后,精确率保持在0.985 以上(如图3)。

图 2 Crop-VGG 网络模型Fig. 2 Crop-VGG network model
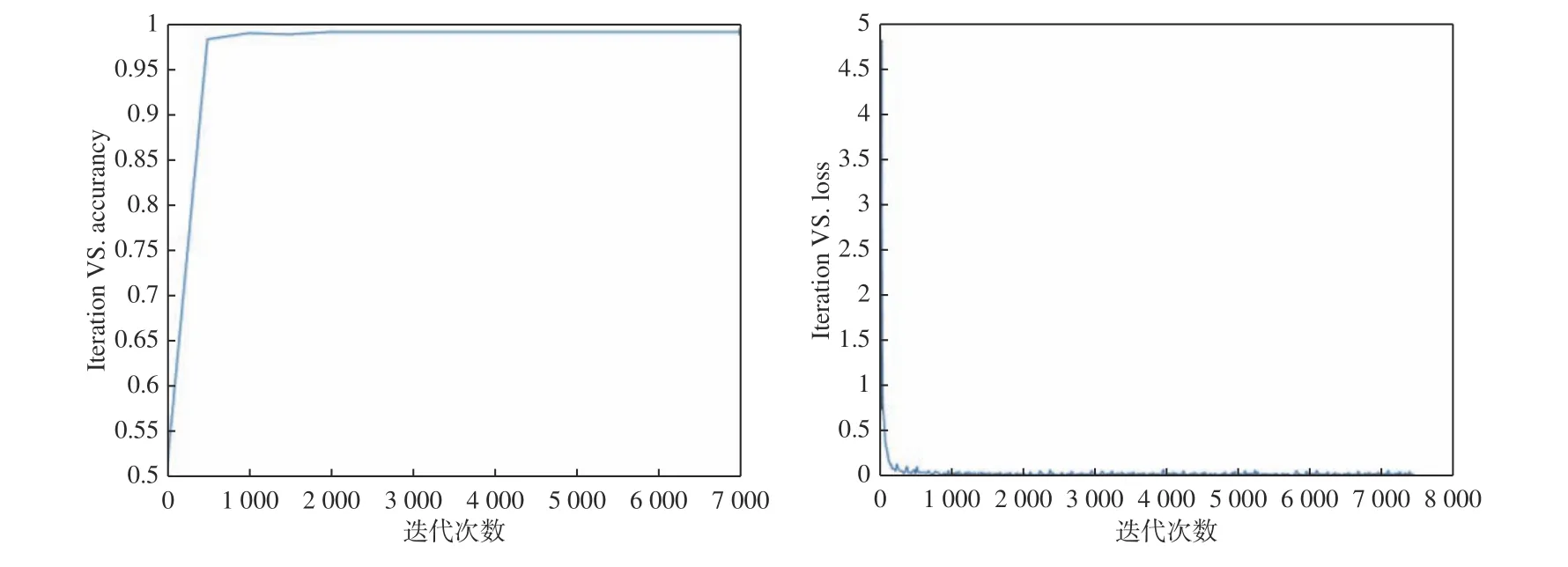
图 3 epoc 图与loss 图Fig. 3 Diagram of epoc and loss
2 使用网络进行统计特征分类
2.1 数据预处理
步骤1) 选取纹理多样的一组清晰图,使用点扩散(point spread function)方法进行模糊处理。因为点源在经过任何光学系统后都会由于衍射而形成一个扩大的像点,通过测量系统的点扩展函数,能够更准确地提取图像信息,这里使用点扩散函数更加符合光学散焦过程。对于分类训练,需要扩大清晰和模糊的区分度,于是设置扩散半径r=10,获取一组聚焦和散焦图像。
步骤2) 将两组图像分别分割为 32×32像素的小块。首先使用二维离散小波[14]变换对图像进行分解。设原始图像为C0=(c0mn),则
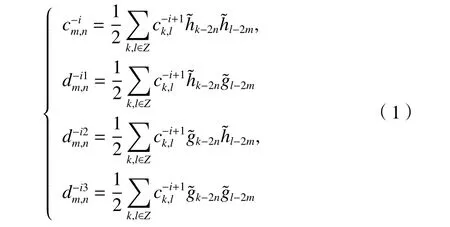

步骤3) 将所有对应位置的Sobel 算子处理后的图像与步骤2 的HL、LH、HH 拼接成一幅图像组作为输入训练数据输入目标网络中,完整步骤如图4 所示。

图 4 训练集预处理模型Fig. 4 Training set preprocessing model
2.2 分类训练
对于训练好的二分类网络模型逐块进行模糊评测[15],进行阈值为0.5 的分割,其中,聚焦区块概率接近于1,散焦区块概率接近于0。对于介于中间聚焦散焦混合区块做如下判别:

式中y 、 x、 c为分别为四角区块、四边区域方块、中间区域方块,它们是否为1 取决于周围方块 a的聚焦块数量,这种方法可以将图像中空洞区域块有效去除,如图5 所示。
2.3 基于统计特征的像素分割
通过分类训练后对目标图A 和目标图B 进行了分类处理,如图6 所示,依据形态学分割[16]为3 个权重矩阵,分别为 α 、 β 、 γ 。其中 α、 β为已确定的聚焦区域的权值矩阵,只需要对γ 矩阵的细节处理。 T1、 T2 是由两幅原聚焦图像通过 γ权值矩阵分割出来的聚焦散焦混合部分,即:

图 5 处理误判的区块的矫正矩阵Fig. 5 Correction matrix for handling misjudged blocks

分别对T1 和T2 进行点扩散函数 ∂的散焦处理, φ函数用来求目标像素点与 3×3区域邻近像素点方差,通过统计像素点之间的模糊变化关系,经过阈值分割后能够提高在边界部分像素点区分度,如(5)式所示:

由于只判断中间混合区域,因此本文方法实现时受全局误判点干扰较少,边界部分信息明确,生成初步边界区域明显的分割权值图像矩阵 τ1:

对 τ1中的空洞点再进行一次形态学空洞补全的修复处理,得到最终分割区域明显的 τ2权值矩阵。最终的融合图像 AB为
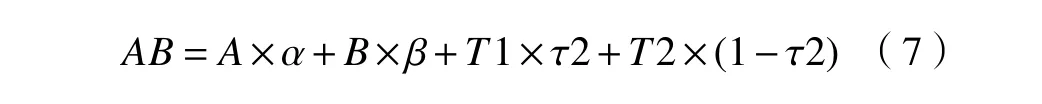

图 6 像素级形态融合Fig. 6 Pixel level morphological fusion
3 实验结果
在实验中,我们使用了几对输入图像作为测试图像,验证了该方法的可行性。将本文提出的多焦点图像融合算法与最新的多聚焦图像融合算法如MWGF[4]、DCTvarcv[17]、DSIFT[2]等进行了比较,下面介绍图像融合的详细讨论分析结果。
图7~图10 展示了图像融合视觉质量的主观评价,为了对比不同的多聚焦图像算法的融合效果,选取4 组多聚焦图像。Image A 与Image B 为需要融合的左右聚焦图,其他图像为每个算法对应的融合图像。例如,在图7 中图片整体清晰度较高,在图8 中,树木边缘参差的纹理特征比较其他算法接近于原始图像,除去边缘的其他细节部分完全保留原始图像信息,而在图9 中手背部分与图10 瓶子边界部分清晰程度较高。
表1~表5 为Vegetables、Tree、A globe、The bottle 4 类多聚焦融合图像在几种算法中的表现,通过数据结果可以看出本文算法在信息熵、平均梯度、图像清晰度、边缘信息保持度、互信息上的得分情况基本优于其他算法。这说明本文算法能够减少细节与边缘信息的损失,对于图像整体信息量保存较完整,边缘层次比较多,清晰度也明显高于其他算法。改进的VGG 网络能够更好地保存高频信息,抽选两组表的数据在各类算法的比较如图11 所示。

图 7 Vegetables 在不同算法的融合表现Fig. 7 Fusion performance of Vegetables in different algorithms

图 8 Tree 在不同算法的融合表现Fig. 8 Fusion performance of Tree in different algorithms

图 9 A globe 在不同算法的融合表现Fig. 9 Fusion performance of A globe in different algorithms

图 10 The bottle 在不同算法的融合表现Fig. 10 Fusion performance of The bottle in different algorithms

表 1 各类算法在信息熵的对比Table 1 Comparison of various algorithms in information entropy

表 2 各类算法在平均梯度的对比Table 2 Comparison of various algorithms in average gradient

表 3 各类算法在图像清晰度的对比Table 3 Comparison of various algorithms in image clarity

表 4 各类算法在边缘信息保持度的对比Table 4 Comparison of various algorithms in edge information retention

表 5 各类算法在互信息的对比Table 5 Comparison of various algorithms in mutual information
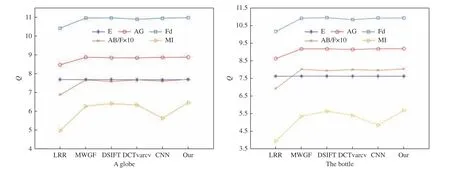
图 11 A globe 和The bottle 在各类算法的融合表现Fig. 11 Fusion performance of A globe and The bottle in different algorithms
4 结论
本文提出的结合深度学习与统计特征的方法解决复杂的实际问题是可行的,Crop-VGG 网络中能以较少运算速率保留更多的原始图像信息,同时结合统计特征的融合算法在各类指标上具有良好的表现,所以针对不同的问题复杂度设计相应的深度网络能更加便捷地处理问题。
猜你喜欢
浙江大学学报(理学版)(2022年4期)2022-07-25
复旦学报(自然科学版)(2022年1期)2022-06-16
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
人民珠江(2019年4期)2019-04-20
铁路计算机应用(2018年5期)2018-06-01
北京航空航天大学学报(2018年1期)2018-04-20
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
南都周刊(2015年4期)2015-09-10
