
基于数据仓库的高校人事管理决策支持系统设计
2020-07-08 07:30彭秦晋
晋中学院学报 2020年3期
彭秦晋
(晋中学院人事处,山西晋中030619)
21世纪初期,美国工程专家在数据库基础上构建出数据仓库的技术.随着计算机技术和网络技术的广泛应用,逐渐打破了传统的高校教育理念,促使高校的管理方式和管理决策都发生了天翻地覆的变化,而数据仓库的建设则为高校的信息化发展提供了帮助,成为促进高校发展、增强教学实力、提升教学水平的主要因素.如何满足基于数据仓库的人事信息化管理,通过数据分析,发现数据中的重要价值,辅助高校制定人才招聘长远规划、培养学科带头人等,这是当前人事管理的课题和新使命[1].
1 基于数据仓库技术的人事管理决策支持系统实现
决策支持系统一般由数据仓库、OLAP(On-Line Analysis Processing)、数据挖掘、分析模型等组成,通过分析模型、相关算法等支持管理者制定客观的、科学的、规范的、基于基础数据的决策.本系统提供信息浏览、教务分析、科研分析、薪酬分析四大统计数据功能和招聘决策分析、绩效决策分析两大类的决策分析,由于涉及到的内容较多,本文主要针对博士招聘决策支持系统的实现过程进行分析[2].
基于数据仓库技术的决策支持系统对从联机事务处理系统(OLTP)收集的大量数据进行查询,从而进行数据分析.因此,OLTP是决策支持系统的主要数据源泉,为其提供了大量的、可靠的历史性元数据.首先,数据仓库对OLTP数据进行清洗操作,将数据重新构建成面向主题的数据集市,为决策支持系统提供数据基础.各数据模型通过特定技术对元数据进行重新修改,转换为数据仓库所能识别和使用的数据,为分析作好准备.其次,多维数组存储的联机分析处理(OLAP)为用户提供了一个多角度的数据分析.它利用常规的方式分析数据,并挖掘数据中的隐含意义做出趋势分析[3].最后,通过数据分析工具Tableau Public、BI、EXCEL等,提供直观的分析结果[4].
如图1所示,一套完整的博士招聘决策支持系统由数据源的抽取、OLTP数据的清洗、数据仓库建立、OLAP的运用、BI(Business Intelligence)工具的终端使用五个步骤完成.
1.1 不同系统和不同格式的数据源的抽取
从数据源位置来看有内部信息和外部信息,内部信息有教职工基础信息、科研信息、教学计划、专业信息等,外部信息有外院校的专业信息、外院校博士研究生招生信息、外院校博士研究生就业情况等.从数据源格式来看,有FOXPRO、SQL、ACCESS等,分布在不同的人事管理系统(如干部任免系统,教务系统、科研系统等).
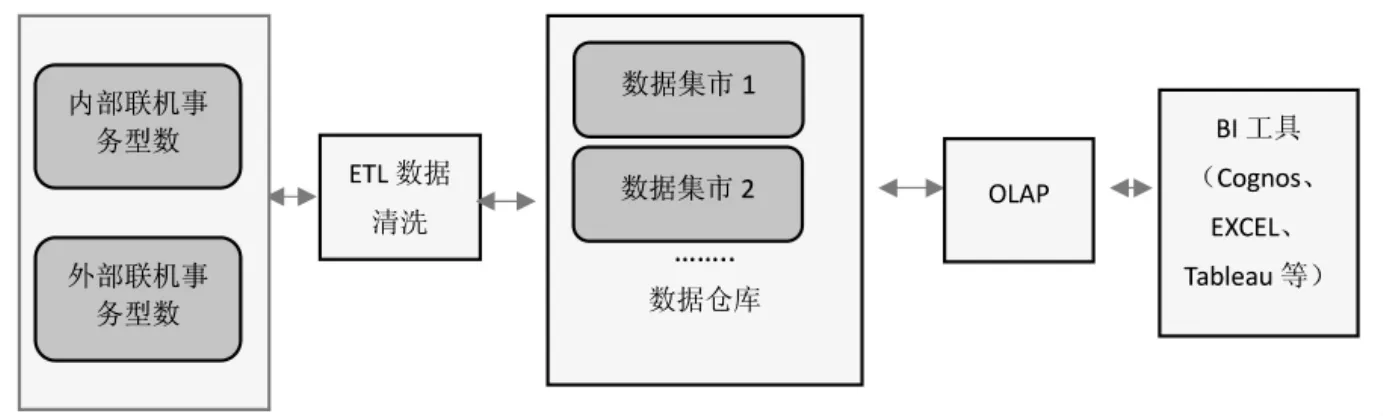
图1 博士招聘决策支持系统的数据仓库体系图
1.2 OLTP数据的清洗
ETL数据清洗就是将高校内部或者外部业务系统中不同编码规则的、分散的、重复的数据源端的联机事务处理数据,经过抽取(extract)、转换(transform)和加载(load)至数据仓库的过程.ETL是很重要的一环,本系统ETL数据清洗花费的时间约占整个项目过程的1/3.不完整的或者错误的数据通常需要过滤掉或者返还给业务部门进行修正.不规范的数据要进行统一规范和标准化(比如教师所学专业名称,有的用简写,有的用全称).各个业务系统中的数据会出现重复现象,重复的数据(维表中出现)需要整理导出再次让业务部门确认.
1.3 每个数据集市的形成
数据仓库是由多个数据集市集成在一起的.连接多个数据源来满足特定的部门或主题要求,最终形成部门或者主题级的数据仓库.建立数据仓库不是一次性完成的,是逐步进行的.数据集市一般包括某一特定领域的与之业务有关联的数据(如:财务、招生、就业、人事等不同部门,数据仓库是面向整体的,数据集市是面向某个部门或某个主题的(如:博士队伍集市、科研集市、教学集市等).
1.4 OLAP的运用
联机分析处理技术最初是由美国学者考拉于1993年提出的,其主要具备两个方面的特点:一个是在线性,简言之就是实现用户的即时沟通和互动过程;另一个是多思维分析性,就是在多种思维建立的基础上,使用者能够参与过程,并进行结果反馈,且对于使用者提出的分析需求利用分析运算法对数据进行从简到繁的探究分析,此过程也是联机分析处理的核心内容[5].联机分析处理系统具有较强的灵活性,多用于分析,使数据信息更加直观,更具有可视化,使用者对繁多数据的多样分析变得简单且高效.
OLAP 比较常用的操作有切片(slice)、切块(dice)、下钻(drill-down)、旋转(rotate)、上卷(roll up)等.主要是完成对科研维、职称维和时间维的建立和处理.OLAP模块可以完成各个部门、各个专业、各个博士的科研成果及在职时间等,并展示出分析结果.对多维数据集的查询通过MDX语句来完成.
1.5 BI工具的终端使用
BI就是商业智能(Business Intelligence),大众化的前端工具分为报表工具、分析工具、查询工具等,它们的操作不需要有数据分析、挖掘算法基础,只在屏幕上直观显示结果,易理解.根据部门职能的不同、要求的不同,有的需要提供分析报表,有的需要趋势或者预测分析.在实际操作过程中,一个完整的数据仓库系统需要借助多种工具来实现[6].管理者可以运用各种不同的工具,从多角度、多视角观察数据,并以图形、报表等多种形式展示,从而深入了解包含在数据中的信息和内涵.
2 人事管理决策支持系统实例应用
目前,博士化率不低于25%是师资评价中一项重要的指标,各大高校人事部门都在为如何能招聘到满足需求的博士犯愁,尤其对于文科类博士招聘更是难上加难.尽管大费周章地招聘到了博士,但有的博士甘愿冒着违约的风险去寻找新的岗位.这是高校人才招聘过程中存在的现实困境.下面通过基于数据仓库的决策支持系统,科学、合理地为管理者提供解决这一难题的决策支持[7].
2.1 分析主题的确定
了解需求找到主题,针对招聘需求,可以归纳出典型的主题域.在数据仓库中,主题域是由一组相关的表来具体实现的,这些表来源于不同的数据源.
2.2 星型数据仓库结构设计
最常见、最稳定的模式是星型模型.它由一个包含有大量数据的中心表和多个小的附属表组成,通常称之为事实表和维度表.事实表中除了数值指标外,就是和各个维表相关联的关键字;维度表则是由与事实表相关联的关键字和维度本身的一些属性值组成.星型数据仓库结构设计中,通常把某一主题的分散在不同业务系统中的数据进行重组后,在数据仓库中按这两类数据分类存储.
根据博士招聘主题需求,提出以下事实表和维度表的设计,见图2.
博士队伍事实表包括:课程代码、科研代码、学科代码、时间代码、职称代码、部门代码、地区代码、博士数量、在校时间.
维度表包括:课程维度表(课程代码、所授课程名、年课时量);科研维度表(科研代码、科研名称、类型、类别、申请时间、结题时间、科研经费);学科方向维度表(学科代码、学科名称);时间维度表(时间代码、年、月);职称维度表(职称代码、职称名、聘任时间);部门维度(部门代码、部门名、入职时间);地区维度(地区代码、所在国家、所在省、所在市).
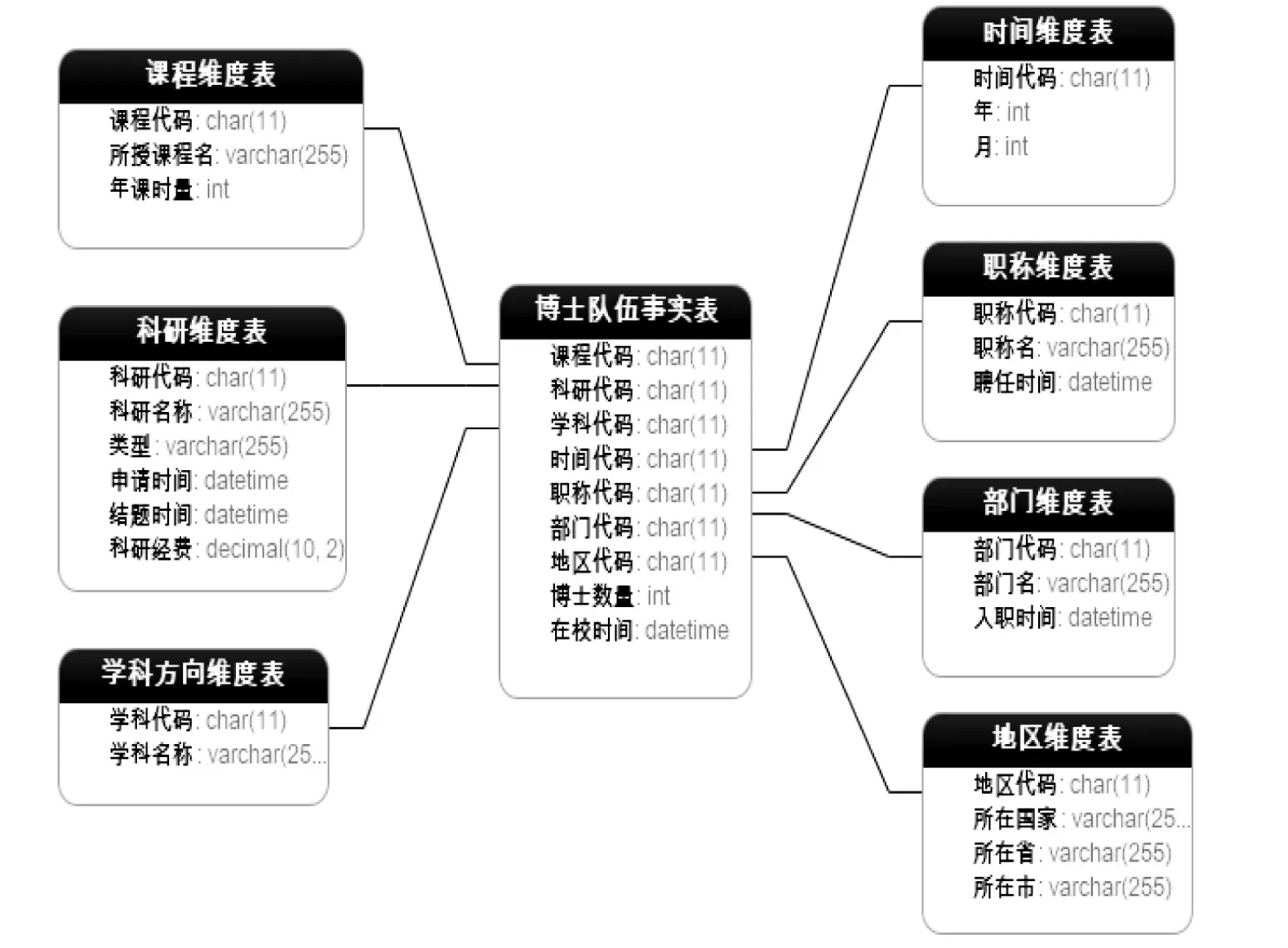
图2 博士队伍的星型模型
从图2可以看出,博士队伍数据集市是以博士队伍事实表为中心的,四周辐射多个维度表,事实表与维度表通过主键与外键链接,存在一对一、一对多和多对多等多种关系.根据部门博士队伍的信息,可以统计不同部门、不同学科的博士人数在不同职称等级、不同地区的组成比例以及科研经费数量等数据[8].
例如:某学校约500名教职工,只留下与博士相关的信息,分析近五年该学校的博士情况(见图3).
运用EXCEL中数据透视表分别统计不同学科类别、不同地区以及性别不同的情况,可以发现山西籍的理学女博士数量最多,山西籍的工学男博士数量次之.就地区来讲河北籍的博士数量较多.根据分析计算结果得出如下结论:(1)文史、艺术类女性博士较男性博士较容易来该校工作.(2)山西籍理学女博士更愿意来该校工作,博士招聘时可将更多注意力集中到籍贯、性别和学科类别上.上述结论可为管理层做出人才引进的工作方向提供支持.
利用聚类的关联分析法,分析博士数据集市,设置最小的置信度50%,根据相关条件得出置信度大于等于50%的组合.见表1.
由表1可知科研绩点数和教学超工作量数直接关系到博士能长时间服务于同一所院校,这一结论有助于学校管理者为今后更科学地制定、考核博士的科研及教学任务提供决策支持.

图3 数据透视分析结果

表1 置信度超过50%组合的统计表
3 结语
数据仓库技术是新时代衍生出来的新产物,有很多问题亟待解决,比如系统的更新升级、人资体系的日新月异等,不断增加的信息数据多样化,也在一定程度上加大了数据仓库运转的复杂性和繁琐性[9].高校应结合自身人事管理体系,充分考虑数据仓库的实施目标和运行程序,制定符合现代化社会发展的科学方案,探究与之相匹配的数据仓库,积极推进高校的人事管理工作.
猜你喜欢
中国现代医生(2022年21期)2022-08-22
电子乐园·下旬刊(2021年3期)2021-02-08
数字通信世界(2021年4期)2021-01-12
自然资源信息化(2019年4期)2019-03-29
铁道通信信号(2018年5期)2018-06-28
计算机与生活(2018年3期)2018-03-12
中国科技期刊研究(2017年2期)2017-05-14
山东工业技术(2016年15期)2016-12-01
中国教育信息化(2015年10期)2015-08-23
浙江大学学报(工学版)(2015年2期)2015-05-30
