
基于深度学习目标检测的可行驶区域分割
2020-07-09 21:26徐征宇朱宗晓周康田微
现代信息科技 2020年23期
关键词:目标检测
徐征宇 朱宗晓 周康 田微


摘 要:目前大多数的可行驶区域分割算法,是以网络结构复杂化为代价换取像素级的精确分割。为了降低训练出的网络结构的复杂度,较为轻量、快速地实现可行驶区域分割,对基于目标检测的可行驶区域分割方法进行了研究。该方法把可行驶区域的像素级标注转换为目标检测框标注,用目标检测算法实现可行驶区域分割。实验结果表明,目标检测方法也能较为准确地对可行驶区域进行分割。
关键词:目标检测;可行驶区域分割;矩形覆盖多边形
中图分类号:TP391.41 文献标识码:A 文章编号:2096-4706(2020)23-0106-03
Drivable Area Segmentation Based on Deep Learning Object Detection
XU Zhengyu,ZHU Zongxiao,ZHOU Kang,TIAN Wei
(Computer Science College of South-central University for Nationalities,Wuhan 430074,China)
Abstract:At present,most of segmentation algorithms for drivable area are pixel level accurate segmentation at the cost of complex network structure. In order to reduce the complexity of the trained network structure,and realize the segmentation of the drivable area quickly and with a little calculation,this paper studies the segmentation ways of drivable area based on object detection. In this method,the pixel level labeling of the drivable area is transformed into the target detection box labeling,and the drivable area is segmented through the target detection algorithm. The experimental results show that the target detection method can also segment the drivable area more accurately.
Keywords:target detection;drivable area segmentation;rectangle overlay polygon
0 引 言
随着计算机算力的不断增强和深度学习的快速发展,基于深度学习的图像分割可以达到像素级别的精确分割,即把每个像素点进行分类。但面向无人驾驶的行驶区域分割时,像素级的精确分割,本文认为是没有必要的。人类在驾驶汽车时,不可能关注到每一个点,绝大多数进入视野的细节会被忽略,除非这个细节能在可行驶区域和非可行驶区域的相互转换中发挥作用。基于人类在驾驶的过程中不可能关注到每一个点的特点,本文提出用目标检测的方法去实现可行驶区域分割,即用若干目标检测框去框出大致的可行驶区域,这样就不需要对每一个像素点进行分类,既能降低网络的复杂度,又能较快地实现可行驶区域的分割。
本文所研究的内容,其面向场景是无人驾驶的可靠环境感知。其感知内容主要包括两个方面:一方面是行驶道路上的目标检测,其包含车辆、行人及其他障碍物和交通灯、交通标志等检测;另一方面是可行驶区域分割。本文主要针对可行驶区域分割进行研究,采用基于深度学习目标检测的可行驶区域分割的设计思路,该研究是在田微老師和朱宗晓老师的指导下进行的,目前只是一个算法理论的实现,还没有应用到实际的场景中。本文采用的可行驶区域分割方法是用目标检测算法实现的,本人根据该思路,先实现像素级标注转换为目标检测框标注,该过程是一系列矩形框逼近覆盖不规则多边形的数学问题,需要编写相关代码,实现其转换,为了较为准确地转换标注,还根据BDD100K数据集的其他目标物的矩形框标注的长宽面积进行了统计分析,设计了两种标注转换方案。最后采用深度学习的目标检测算法,进行训练,得到训练模型,然后进行测试,保存相关的测试结果数据,再编写代码,对这些数据进行处理,从而合成我们所需要的可行驶区域。
1 相关理论
本文采用了两种基于深度学习的目标检测算法:Faster R-CNN和YOLOv5。Faster R-CNN是两阶段目标检测的代表算法。第一阶段,产生region proposal,第二阶段,对region proposal进行分类和位置修正。从最初的R-CNN,再到Fast R-CNN[1]的改进,最后发展为将特征抽取、候选区域提取、位置精修、分类都整合在一个网络中的Faster R-CNN[2],其综合性能有很大的提升。YOLOv5有四个网络模型,本文采用的是YOLOv5s,其网络结构分成了四个部分。输入端:采用了Mosaic数据增强和自适应锚框计算,前者丰富了检测目标物的背景,后者针对不同数据集,自动计算最合适的初始设定长宽的锚框;Backbone:使用CSPDarknet,从输入图像中提取丰富的信息特征;Neck:主要用于生成特征金字塔;Prediction:YOLOv5采用GIOU_Loss做Bounding box的损失函数,其对常用的目标检测算法都具体有相当的提升作用。
图像分割指根据灰度、彩色、空间纹理、几何形状等特征把图像划分成若干个互不相交的区域,使得这些特征在同一区域内表现出一致性或相似性,而在不同区域间表现出明显的不同[3]。传统的图像分割方法有基于阈值的分割方法、基于区域的图像分割方法[4]、基于边缘检测的分割方法等[5]。随着计算力的不断增强以及深度学习的快速发展,基于深度学习的分割方法取得了较于传统的分割方法更好的效果。He等在2017年提出的Mask R-CNN算法,实现了目标物的像素级分割[6]。
2 实验方案
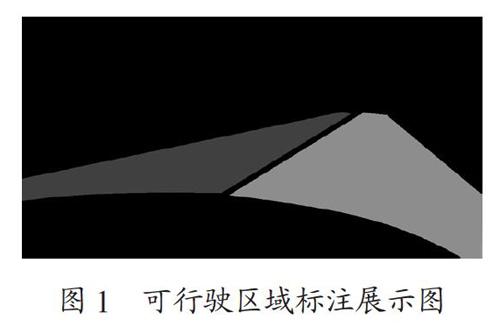
可行驶区域分割的研究,大多采用的是像素级的语义分割,本文使用的BDD100K数据集的标签文件亦是如此,如图1所示。其标签文件把可行驶区域分为了两类:直接可行驶区域和间接可行驶区域。直接可行驶区域标为红色,表示此路段是当前车辆驾驶时的优先选择,是行驶时最合理的路段区域。间接可行驶区域标为蓝色,表明当前车辆可以在此路段内行驶,但必须谨慎,因为此路段的优先级可能属于其他车辆。
为了用目标检测的方法实现可行驶区域的分割,首要的问题是如何把像素级标注转换为目标检测框的标注。对于该问题,采用微积分的思想,用若干小方框框住像素级的可行驶区域,尽可能地把可行驶区域的像素点框进来,使其标注准确。当转换成功后,投入到深度学习网络中训练测试,然后得到的也将会是一系列小方框框住的可行驶区域,再把这一系列小方框进行合并,重新合成我们需要的可行驶区域。
本文采用Faster R-CNN和YOLOv5两种目标检测算法,实现可行驶区域的分割。
2.1 区域像素级标注转换为目标检测框标注的方法
区域像素级标注转换为目标检测框标注,其基本思想就是用一系列的小矩形框去逼近覆盖不规则多边形区域,如图2所示。
首先确定所采矩形框为56。在多边形区域边界处找一些点,向周围的领域空间扩展到56的长度,然后以此为宽,再画此矩形的长,其长没有限制长度,只要不超过多边形另一边的边界即可。如此横向画一个矩形框,再纵向画一个矩形框,直到完全覆盖可行驶区域多边形。最后把所有画出来的矩形框坐标记录下来。再按照Faster R-CNN的数据集格式和YOLOv5的数据集格式进行相应的数据格式转换。
转换好的数据标签投入到神经网络训练之前,我们需要把这些转换好的数据标签与原始标签比较,判断是否准确。因此,我们还需要把这些转换好的目标检测框的数据集标签重新再合成区域,如图3所示。
再用mIOU的指标进行打分,分数越高,表明转换的目标检测框的标注越准确。只有转换的标注越准确,我们之后用目标检测方法实现的可行驶区域分割才能越准确。
为了提高可行驶区域分割的精确度,本文除了以上的第一种以宽为56,长不作限制的矩形框覆盖多边形的方案外,还设计了第二种多个小矩形框去覆盖多边形的方案,其基本思想与第一种方案一样,只是矩形框宽限制为32,长限制为512。第二种方案,因为划分得更加细致,其与原始标注的比较会更为准确,其具体的数据会在下文的实验结果中展示。
2.2 训练检测得到的一系列矩形框进行区域合成
可行驶区域原始像素级标注全部成功地转换成目标检测框标注后,再把这些目标检测框标注按照两类目标物:直接可行驶区域和间接可行驶区域,转换成Faster R-CNN的数据集格式和YOLOv5的数据集格式。分别投入两种深度学习的目标检测神经网络中进行训练测试,无论哪一种目标检测方法,最后的测试结果都会在直接可行驶区域和间接可行驶区域得到一系列检测的矩形方框,如图4所示。
再把这一系列小方框分别按照直接可行驶区域矩形框和间接可行驶区域矩形框进行红色和蓝色的填充,从而实现可行驶区域的合成,如图5所示。
3 实验结果与分析
3.1 实验设置
本实验采用两种基于深度学习的目标检测方法:Faster R-CNN和YOLOv5。分别对两种方案的原始区域像素级标注转换为目标检测框的标注进行训练测试。
两种标注转换方案分别是:第一种,大多数宽为56,长不作限制的矩形框区域标注;第二種,大多数宽为32,长为512的矩形框区域标注。
首先,对转换好的这两种方案的区域目标检测框的标注与原始标注进行比较,对比mIOU得分,看其标注得准不准,转换后的标注越准确,越有利于后续的训练检测。我们需要根据转换好的矩形框的坐标位置数据,按照区域合成的方法,进行区域合成,然后与原始标注比较并打分。对这两种区域标注转换的方案进行实验数据结果的对比分析。
再把这两种方案转换的区域标注,每一种也都分别用Faster R-CNN和YOLOv5进行训练测试,也就是总共进行四个实验。
最后再把这四个实验结果的一系列小方框的坐标位置数据,分别按照区域合成的方法进行合成,得到四个不同实验的区域合成结果,再与原始区域标注进行比较打分,使用的指标是IOU,然后对每个实验结果进行分析,两两进行比较。
3.2 实验结果与分析
本实验先对两种方案转化的目标检测框标注,与原始标注进行比较;再对四个实验的区域合成的结果,与原始标注进行比较,其评价指标为mIOU,如下所示:
(1)两种方案的原始区域像素级标注转换为目标检测框标注的准确性以及对比,如表1所示。
第一种方案相对于原始标注的准确度,使用mIOU进行评价,其值为82.9%,从数值看来准确度还是较为准确的。此种方案只限定了矩形框的宽为56,没限定矩形框的长,覆盖的多边形区域相对来说面积较大,总体数量也就较少,覆盖的精确度也就较低。第二种方案的矩形框的宽限定为32,长限定为512,与第一种方案相比,大多数矩形框面积较小,数量增多,总共多了2 258 230个矩形框,覆盖的精确度也相对较高,该方案的mIOU值为87.4%,相比第一种方案提升了4.5%。
(2)将这四种实验得到的一系列小方框进行区域合成,再把这四个结果按照mIOU指标,与原始像素级标注进行比较,其结果如表2所示。
表2展示了Faster R-CNN和YOLOv5两种目标检测算中分别在两种方案下的实验测试结果。在第一种方案下,可以看出Faster R-CNN的精确度更好,在Faster R-CNN中的mIOU值比YOLOv5的mIOU值高3.6%。但在第二种方案下,YOLOv5的效果更好一点,其mIOU值比Faster R-CNN高1.3%。Faster R-CNN在两种方案下的实验结果对比下,第二种方案确实能够提高可行驶区域分割评价指标mIOU值,提高了2.2%,可见第二种方案更有利于可行驶区域的分割。YOLOv5在两种方案下的实验结果对比下,也证明了第二种方案确实有效的提高了可行驶区域分割的准确率,其mIOU值相比第一种方案提高了7.1%,相比Faster R-CNN提升更明显。
4 结 论
本文提出了一种基于深度学习目标检测的可行驶区域分割方法。首先把BDD100K像素级区域标注转换为目标检测框标注。为了提高可行驶区域分割的精确度,设计了两种不同方案的标注转换。每一种方案再分别用Faster R-CNN和YOLOv5训练模型,将得到结果进行区域合成,并进行测试。结果表明,本文该出的第二种方案的标注转换,确实有效的提高了可行驶区域分割的精确度,文中四个实验的结果也表明了目标检测的方法能够较为准确地对可行驶区域进行识别分割。
参考文献:
[1] GIRSHICK R. Fast R-CNN [C]//2015 IEEE International Conference on Computer Vision(ICCV).Santiago:IEEE,2015:1440-1448.
[2] REN S Q,HE K M,GIRSHICK R,et al. Faster R-CNN:Towards Real-Time Object Detection with Region Proposal Networks [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(6):1137-1149.
[3] 黃鹏,郑淇,梁超.图像分割方法综述 [J].武汉大学学报(理学版),2020,66(6):519-531.
[4] 王媛媛.图像区域分割算法综述及比较 [J].产业与科技论坛,2019,18(13):54-55.
[5] 庞明明,安建成.融合模糊LBP和Canny边缘的图像分割 [J].计算机工程与设计,2019,40(12):3533-3537.
[6] HE K M,GKIOXARI G,PIOTR D,et al. Mask R-CNN [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,42(2):386-397.
作者简介:徐征宇(1995—),男,汉族,重庆人,硕士研究生在读,研究方向:计算机视觉;通讯作者:田微(1979—),男,汉族,湖北荆州人,教授,博士,研究方向:计算机系统集成。
猜你喜欢
科技创新与应用(2016年36期)2017-02-21
软件(2016年4期)2017-01-20
科教导刊·电子版(2016年28期)2017-01-10
科学与财富(2016年28期)2016-10-14
电脑知识与技术(2016年5期)2016-04-14
科技视界(2016年4期)2016-02-22
哈尔滨理工大学学报(2015年5期)2016-01-19
湖南大学学报·自然科学版(2015年10期)2015-11-30
现代电子技术(2015年20期)2015-10-26
现代电子技术(2015年14期)2015-07-22
