
基于表征重述的机器文本理解
2020-07-26 14:23付熙徐龚希章
软件导刊 2020年7期
关键词:机器翻译
付熙徐 龚希章


摘 要:传统机器翻译系统缺乏联系上下文形成认知的能力,仅根据对应单词的默认含义进行翻译,容易导致语义错误等问题。通过模拟人的表征重述认知过程,提出一种新的机器文本理解与翻译方法。该方法可通过较少的实例对文本进行理解和翻译,避免出现语义理解错误问题,且无需进行繁杂的语法标注。实验表明,该方法可通过引入习得的常识,使翻译出现歧义错误的概率降低到1%以下,并可标注出不符合常理而又无法找到更好解释的句子。
关键词:表征重述;文本理解;机器翻译
DOI:10. 11907/rjdk. 192447 开放科学(资源服务)标识码(OSID):
中图分类号:TP301文献标识码:A 文章编号:1672-7800(2020)007-0024-04
Machine Text Understanding Using Representational Redescription Process
FU Xi-xu,GONG Xi-zhang
(Institute of Information and Education Technology,Shanghai Ocean University,Shanghai 201306,China)
Abstract: Traditional machine translation methods often cause semantic errors by simple substitution. Because of lacking common sense, machines merely find corresponding words in target language and substitute them with default meanings. A novel machine text understanding and translation method is advanced by simulating humans representational redescription process. This method can understand and translate text correctly with fewer instances. Semantic errors can be avoided in this method. Complex syntactic label can be avoided too. According to the experiment result, this method can introduce common sense into the understanding process and get a semantic ambiguity error rate lower than 1%. Furthermore ridiculous translations can be labeled if no better translation can be found.
Key Words: representational redescription; text understanding; machine translation
0 引言
目前機器自动翻译和文本理解系统存在不能有效结合上下文、理解过于死板的问题,具体表现为对文本仅简单地进行词对词的语义翻译,不考虑相关背景和搭配。有不少研究提出了新的文本理解和知识发现方法[1-7],以及关于自然语言理解和机器翻译的评价标准[8]。这些方法从词法、语法等各个角度,利用神经网络等多种方法提出自然语言理解和自动翻译的方法,但没有从语言习得的角度建立语言知识模型,需要大量人工干预,也未能提出一个完整的语言结构、词义解决方案。机器学习方法被应用于机器翻译中,如基于统计的方法、对应特定文本理解任务的方法等[9-16]。然而这些方法通用性不佳,且需大量已标注的文本作为训练集。
语言认知是人类认知的一个重要部分,人类从幼年开始学习语言,很多概念的学习均伴随着语言交流[17]。语言与概念的联系十分紧密。缺失对概念的理解,语言翻译通常会出现错误。如“He killed a bat with a bat”,如果只考虑到词法,翻译成中文可以是“他杀了一只蝙蝠用一个球拍”,也可以是“他杀了一只蝙蝠用一只蝙蝠”等;考虑到语法,还可以翻译成“他用一个球拍杀死一只蝙蝠”或“他用一只蝙蝠杀死一只蝙蝠”;考虑到词典中解释的顺序,翻译成后者的可能性更大。然而,对于一个掌握了“球拍”、“蝙蝠”、“杀”、“用”等概念的人,这种翻译是荒谬的。
语言习得是表征重述理论研究的重要内容之一[18]。表征重述的几个阶段也可为语言概念的形成提供丰富的概念基础。目前基于表征重述过程建立了一些模型,部分模型已应用到机器人等领域[19-21]。本文以“kill”概念的形成和掌握为例,从认知角度讨论语言概念的形成,从概念认知与形成的角度讨论语言理解、翻译等问题。
1 表征重述与语言
1.1 水平表征特点
在语言认知的I阶段,儿童只能简单地重复习得语句,但无法掌握实例基础结构。当孩子习得“He killed a bat with a bat”这一语句时,能知道“kill”表示“杀死”这个行为,而第一个“bat”是指一只蝙蝠,第二个“bat”是指一个球拍。这些单词在儿童的意识中指代特定的物体和行为,如果换一个实例,比如“Mary killed a mouse with a stick”,儿童就无法理解。尽管儿童通常在掌握第一门语言后很长一段时间才显式地习得“动词”、“名词”、“介词”等概念,但儿童对物体、动作以及它们对应的语言元素早已清楚了解。
1.2 E1水平表征特点
在完成E1阶段的认知后,儿童对 “kill”这个概念的应用有了深刻理解,可以用“kill”进行造句等活动,可良好地掌握相关语法和词义,但会造出“He killed a bear with a bat”这种事实上不可能发生的句子。这是由于“kill”的概念虽可被熟练应用,但却不能通达于意识,无法用其在知识系统中其它概念解释工具和对象的对应关系。
1.3 E2水平表征特点
在E2水平,概念已通达于意识,儿童能知道“He killed a bear with a bat”是荒谬的,通常来说用球拍杀死熊是不现实的。但这个时候,他们仍然无法用另一种语言正确翻译“He killed a bear with a bat”这个句子。
1.4 E3水平表征特点
在E3阶段完成后,儿童能顺利把句子翻译成其它语言,前提是儿童对这种语言构成有所了解。在该阶段,儿童已完全掌握该概念,可用于语言报告。
2 表征重述学习模型
2.1 语言概念表征
在语言學中,名词是指代物体的实词,代词是名词的指代,动词是对名词的动作[18]。形容词被用来修饰名词,副词被用于修饰动词,介词用于对方法、地点等的表征。对于儿童来说,这些概念并不是很清晰,但对于具体词语尤其是名词和动词的使用却是很清楚的。可以认为动词是以名词或名词短语为参数的一个函数,副词是以动词为参数的函数。以概念为根节点可以生成一棵语法树。如“Mary killed a bat with a bat”,语法树如图1所示。
在图1的语法树中,只有名词和代词被作为底层参数,动词、冠词、介词均可作为函数。其中,冠词、介词、形容词、副词均可作为一元函数。这棵语法树可简化为一个字符串。如式(1)所示。
由于一元函数只接受一个参数,因此括号可以省略,如式(2)所示。
该式可完整地表征为一个概念的动词。
除概念表征外,同时语言表征规则也应存储于儿童记忆中,作为语言表达方法和依据。在进化过程中,以概念进化为主,而语言范式表征也跟随概念变化。
2.2 I水平表征与形成
I水平的表征仅仅是对一个实例的描述,是对该实例认知的附属物。对语言的认知可以表征成一个单词序列,儿童这时对概念相关的结构已初步构建。儿童已有概念结构,其内部对应表征如式(2)所示,这些结构可与实例中的语言相互转换。
在I水平形成过程中,句子本身作为I阶段表征的一部分存储在系统中,同时,儿童对句子的理解也形成了表征结构,作为I阶段表征的另一部分存储,在后续阶段中将作为进化主题。
根据语法树构建规则,对于一元函数单词只需将单词放置在参数之前即可,对于多元函数,只需将函数单词放在最前面,按函数规则组织字符串即可。形成表征结构的算法流程如图2所示。
如图2所示,首先找到动作词(表动作的词,不包括be动词和表时态的have等词),这是概念根节点;然后根据名词生成名词短语,将名词短语作为动词参数;最后,将函数作为修饰动词的单词或短语参数。
I水平虽然构建了表征基本结构,但因所有参数均仅是固定的单词,因此没有泛化能力,不能理解不同的句子。
2.3 E1水平表征与E1阶段进化
在E1阶段,概念中的名词或名词短语作为参数在进化过程中逐渐泛化,类和概念逐渐替换了概念表征中具体的词和短语,表征开始具有灵活性。这种泛化在思维与语言输出中同时存在。
在E1阶段,可使用系统中的知识使参数和方法更加泛化,本文系统使用的名词泛化结构如图3所示(由于对象较多,仅列出部分)。
在图3中,各种名词依据儿童已有的知识分类,而不仅是简单地分为名词。本文对各个分类使用不同的变量表示,如动物,可以用大写字母A表示(在这里,“动物”指活的动物)。介词按语义分类,如with和using均根据语义“用”分在一类,用大写字母U表示。通过进化和循环识别的方法,得到如式(3)所示的表征字符串。
如式(3)所示,该式表示kill可被任意多个副词修饰,该概念有3个参数,前两个是必须有的,而后一个则不一定存在。第一个参数是一个人(P),其构成形式是冠词+若干形容词+人。第二个参数是一只活着的生物(L),其构成形式是冠词+若干形容词+活物。最后一个参数表示使用的工具,其格式为一个表“使用”的词加上一个工具(T),而工具的表示形式是冠词+若干形容词+工具。
同时,对语言本身的进化也得出如式(4)所示的模式。
该模板指第一个参数及其修饰放在最前面,动词及其修饰放在第二位,第二个参数及其修饰放在第三位,最后是第三个参数及其修饰。如“Mary killed a dog with a knife”,“Mary”是第一个参数,“a dog”是第二个参数,“a knife”是第三个参数。
2.4 E2水平表征与E2阶段进化
在E2阶段,概念被作为一个整体考虑,达到 E2水平的表征后,可判断出“He killed a bear with a bat”是荒唐的。在E2阶段的进化中,通常认为没有经历过的、且经推导不可实现的事情是荒谬的。该水平可用激活概念图表示。如“Mary killed a bear with a bat”可用图4 表示。
如图4所示,虽然bat和bear单独看来均符合对参数的要求,但根据其详细分类,这个组合显然不恰当,熊是一只大动物,而球拍只能造成很小伤害,因此这个语句是荒谬的。
将每个语句中所有元素存入激活图中,存入时自动激活每个元素相关最底层的类。如“Bob killed a fly with a bat”中的“fly”只能激活“小动物”。反例和规则也可对激活概念图进行修正,如果出现反例,则降低对应记录和相关最底层的类激活权重,如出现冲突,则在实例层级中以反例为准。系统中的规则也可对联结进行修正。
2.5 E3水平与自动翻译
在E3水平,儿童可将概念以另一种形式表述,本文认为是指将英文翻译为中文的能力。E3阶段的学習包括中文语法、中英文语义和概念等的习得。中文“杀”的概念语法描述如式(5)所示。
根据该式即可找到概念对应的中文词汇并生成翻译结果。
3 实验与评价系统
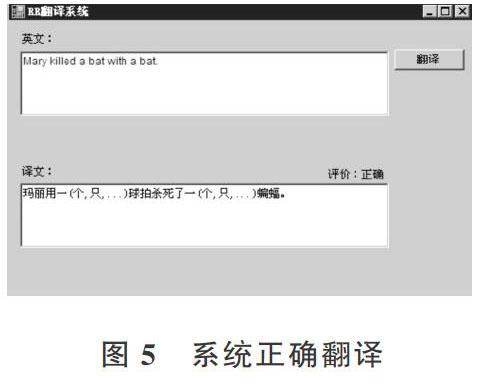
基于以上分析,本文编写了基于RR概念习得的自动翻译系统,系统包括一个学习程序、一个翻译程序和一个知识库。通过对150个包含“kill”的句子进行学习后(这些句子不包括文中提到的“bat”和“bear”等词汇),系统已能对相关语句作出正确翻译,如图5所示。
系统对不同位置的“bat”和语言顺序给出了正确翻译。这表明基于概念系统的翻译系统可正确处理语言结构和语义问题,可对不同位置的“bat”作出正确解释。
本文还设计了翻译评价系统供用户选择并进一步提升翻译系统效果。系统将翻译结果分成3类:第一类是“正确”,这类翻译既符合E1阶段的表征,又符合常识;第二类是符合E1阶段的表征,但不符合常理的结果,系统将其评价为“奇怪”;第三类是“错误”,即语句不符合概念系统中的基本描述,如“罗斯用蝙蝠杀死了蝙蝠”。如果语句有多个候选翻译,系统会显示评价最高的翻译。如果语句错误,如“She killed a desk”系统会提示错误,并给出错误翻译。
对于奇怪的翻译,系统给出提示并让用户进行评价,如图6所示。
如图6所示,当系统给出奇怪的翻译结果时,会显示一个按钮,如果用户点击“这是正确的”按钮,这个翻译对应的概念会作为正例更新系统中E2阶段的表征,在下次翻译时,会将类似翻译置为“正确”。
本文使用Wordnet作为基本词库[22],将包含1 200个句子的语料库作为训练集,用500个含有多义词的句子分别对基于词库的自动翻译方法与基于表征重述的文本理解方法(本文方法)进行测试,结果如图7所示。
从图7可看出,基于表征重述方法可消除翻译中的歧义,对大部分奇怪语义进行正确标识。实验中未出现标识错误的情况。
4 结语
为提升机器翻译系统认知能力,本文通过模拟人的表征重述认知过程,提出一种新的机器文本理解与翻译方法。实验证明,该方法只需通过较少的实例,即可建立支持正确翻译的概念系统,能自动选择符合常识的翻译。表征重述理论以概念表征为媒介,建立了不同语言互相转换的桥梁。本文方法无需对文本进行语法标注,这也是表征重述学习的优势之一。通过对文本理解的研究,对表征重述进行了更深层次的建模,也为机器翻译提供了一种更高效、准确的方法。在下一步的工作中,还可将该方法应用于更复杂的机器学习任务。
参考文献:
[1] 胡金铭,史晓东,苏劲松,等. 引入复述技术的统计机器翻译研究综述[J]. 智能系统学报,2013,8(3) :199-207.
[2] 李伯约·赛丹. 自然语言理解的心理学原理[M]. 上海:学林出版社,2007.
[3] 罗莎. 一种高效的自然语言理解语法分析算法[J]. 科技通报,2013,29(12):91-93.
[4] 熊德意,刘群,林守勋. 基于句法的统计机器翻译综述[J]. 中文信息学报,2013,22(2) :28-39.
[5] WANG B,ZHANGY Y, XU Q. Sentence-level combination of machine translation outputs with syntactically hybridized translations[J]. IEICE Transactions on Information and Systems,2014,E97D (1):164-167.
[6] PUSTEJOVSKY J, STUBBS A. Natural language annotation for mache learning[M]. New York: O Reilly,2012.
[7] LAWRY J. A framework for linguistic modeling[J]. Artificial Intelligence,2004(155):1-39.
[8] 李良友,贡正仙,周国栋. 机器翻译自动评价综述[J]. 中文信息学报,2014,28(3) :81-91.
[9] CHINEA-RIOS M,SANCHIS-TRILLES G,CASACUBER F. Discriminative ridge regression algorithm for adaptation in statistical machine translation[J]. Pattern Analysis and Applications. 2019,22(4) :1293-1305.
[10] GRAHAM N, TARO W. Optimization for statistical machine translation: a survey[J]. Computational Linguistics, 2016,42(1): 1-54.
[11] 刘庆峰,刘晨璇,王亚楠,等. 会议场景下融合外部词典知识的领域个性化机器翻译方法[J]. 中文信息学报,2019,33(10): 31-37.
[12] 徐健锋,许园,许元辰, 等. 基于语义理解和机器学习的混合的中文文本情感分类算法框架[J]. 计算机科学,2015, 42(6):61-66.
[13] 闫盈盈,黄瑞章,王瑞,等. 一种长文本辅助短文本的文本理解方法[J]. 山東大学学报(工学版), 2018, 48(3): 67-87.
[14] SANCHEZ FRANCO M J,CEPEDA-CARRION G,ROLDAN J L. Understanding relationship quality in hospitality services: a study based on text analytics and partial least squares[J]. INTERNET RESEARCH. 2019, 29(3): 478-503.
[15] CHATTERJEE A,GUPTE U, CHINNAKOTIA M. Understanding emotions in text using deep learning and big data[J]. Computers in Human Behavior, 2019(93): 309-317.
[16] RABIGER S, SPILIOPOULOU M, SAYGIN Y. How do annotators label short texts? Toward understanding the temporal dynamics of tweet labeling[J]. Information Sciences, 2018(457):29-47.
[17] MIROLLI M, PARISI D. Language as a cognitive tool[J]. Minds & Machines,2009(19):517-528.
[18] A. 卡米洛夫·史密斯. 超越模块性认知科学的发展观[M]. 缪小春,译. 上海:华东师范大学出版社,2001.
[19] 陈燕,危辉. 非限定的概念获取表征重述方法[J]. 计算机科学, 2006, 33(6):168-171
[20] CHRONOULA V. Oral counting sequences: a theoretical discussion and analysis through the lens of representational redescription[J]. Educational Studies in Mathematics, 2016, 93(2):175-193.
[21] STEPHANEL D. Open-ended learning: a conceptual framework based on representational redescription[J]. Frontiers in Neurorobotics, 2018(12):59.
[22] SIGMAN M, CECCHI G A. Global organization of the Wordnet lexicon[J]. Proceedings of the National Academy of Sciences of the United States of America,2002, 99(3):1742-1747.
(责任编辑:江 艳)
猜你喜欢
现代电子技术(2017年6期)2017-04-10
青春岁月(2017年1期)2017-03-14
读与写·下旬刊(2016年12期)2017-02-09
考试周刊(2017年2期)2017-01-19
考试周刊(2017年2期)2017-01-19
同济大学学报(社会科学)(2014年1期)2014-07-16
