
一种改进的航迹聚类方法
2020-08-07 14:39张勇张建伟韩云祥
现代计算机 2020年18期
张勇,张建伟,韩云祥
(1.四川大学空天科学与工程学院,成都610065;2.四川大学计算机学院,成都610065;3.四川大学视觉合成图形图像技术国家级重点实验室,成都610065)
0 引言
随着移动设备的广泛使用,大量的移动轨迹数据被存储记录,急剧增加的数据量迫切需要高效的轨迹处理算法,分析轨迹数据特征,用于监测和管理热点地区交通状况。在空中交通运输管理领域,研究航空器的运动轨迹,可用于改进现有进场飞行程序结构[1];同时便于管制员理解机场空域交通结构,协助其对进场航班进行排序,分析离群航迹产生原因降低潜在安全风险[2];分析航班进场时间的相关特征,分离不同进场飞行路径,预测航班到达时间[3]。航迹分析中的重要一步是对航空器通过不同进场路径产生的航迹簇进行合理分离,航迹聚类算法被广泛用于分析进场航班的交通流量特征[4]。
近年来有许多研究者提出了不同的航迹聚类方法[5-7],文献[8]提出采用主成份分析(PCA)的方法降低数据维度,并用基于模型和密度的聚类方法得到聚类航迹,主要考虑雷达覆盖区的入口点航迹的聚类。文献
[9]提出了一种处理时间序列的改进聚类算法,该算法能够降低传统聚类算法的时间复杂度,但是该算法聚类过程是依据第一次计算的序列距离,聚类簇之间使用最小距离衡量,无法准确刻画聚类簇之间的距离关系,抗噪声能力有待提高。文献[1]提出一种基于对应雷达轨迹点逆向比对方法的航迹间相似性测度模型,应用层次聚类法对航迹数据集进行聚类分析,改进了航迹间相似度的计算方法,处理小规模航迹数据效果较好,但是聚类过程复杂度较高不适用大规模数据。文献[10]利用CURA 算法实现航迹聚类,通过比较聚类集平均航迹和代表航迹分别与标准飞行程序的关系,建立了飞行程序轨迹表示模型。文献[11]等提出的基于航迹点法向距离的相似性度量算法,但该方法均未解决因飞行速度不同而引起的航迹点采样间隔不相同的问题。文献[12]提出了一种融合匈牙利算法的无监督层次聚类算法并将该算法与谱聚类算法进行比较得出该算法在时间复杂度表现上优于传统谱聚类算法。
通过以上相关算法的研究发现,其主要问题体现在两个方面:航迹间相似度的计算不够准确且时间复杂度较高;算法合并簇与更新距离矩阵都为单步进行,聚类过程中算法收敛速度慢,抗噪声能力差,航迹中离群航迹重复计算浪费了较多计算资源。本文提出采用快速DTW(Fast Dynamic Time Warping)算法[13]计算航迹距离,每次迭代后舍弃离群航迹,合并航迹簇采用并行计算的方式,相较于目前常用的航迹聚类算法,改进聚类算法效率提高了20%,加快了现有航迹数据的处理速度。
1 轨迹距离/相似度计算方法
航迹分类中的关键问题是如何选择航迹间的相似性度量方法,不同航迹之间航迹点数量不同,传统的欧氏距离计算方法对于采样点数不一样的两条航迹之间的衡量效果较差,需要通过插值等方法将轨迹点一一匹配,这样对于大规模航迹处理来说效率较低。本文采用快速DTW 算法取代欧氏距离计算方法和DTW 算法来对航迹距离进行计算,在计算航迹簇之间的距离上应用平均距离以取代最大最小距离,使其在时间复杂度与相似度衡量效果上表现更好。
相关符号及含义:
T:航迹集合nT:航迹总数量,即ti:某一条进场轨迹,
ni:编号为i的航空器飞行轨迹中轨迹点的总数
p(i,j):组 成 一 条 航 迹 的 单 个 航 迹点,
C: 聚 类 后 得 到 的 轨 迹簇
k:航迹聚类得到聚类簇的个数
Ci:第个聚类簇第个聚类簇内包含的航迹数目,每一条航迹的航迹簇
Cout:离群航迹构成的轨迹簇
nCout:离群航迹数量:第个聚类簇和第j个聚类簇之间的距离
α:航迹Ci与距离航迹Ci最近航迹之间的DTW距离
Dstop:聚类算法终止判定阈值
ndrop:离 群 航 迹 簇 的 判 定 阈 值 ,当
x表示航迹点p(i,j)的横坐标;y表示航迹点p(i,j)的纵坐标;z表示航迹点p(i,j)的高度;vh表示航空器在航迹点p(i,j)的水平速度;vv表示航空器在航迹点p(i,j)的垂直速度;φ表示航空器在航迹点p(i,j)的航向角;t表示航空器在航迹点p(i,j)所在位置距离机场所需要的时间。进场航空器的航迹集合为,每架进场航空器对应唯一航迹,航迹点组成完整航迹每条航迹点的数量由其进场路线以及航迹点的采样频率相关,对于采样点数过少,缺乏对航迹特征完整记录的航迹需要舍弃,本文采用的航迹数据在预处理阶段已经剔除残缺航迹。
1.1 聚类参数选取
由于交通管制或极端天气等原因航空器在进离场过程中会偏离既定线路产生离群航迹,这一部分航迹所占比例较小,对进离场航迹数据分析缺乏实际意义,需要在聚类过程中舍弃。对于判断航迹α是否为离群航迹主要参考两个指标:①航迹α与距离航迹α最近航迹之间的DTW 距离Dnearest( )α>Dstop,②航迹α属于航迹簇满足以上条件任何一条即可判断航迹α属于离群航迹。
由离群航迹定义可知,最终航迹聚类簇个数k与舍弃的离群航迹数量nCout取决于参数:Dstop、ndrop,减小Dstop,离群航迹数目nCout会增加而聚类簇数目k会减少,增大ndrop同样会使nCout增加。对于大量数据集的参数设定需要耗费大量的时间测试,才能得到最佳聚类模型。本文拟采用抽样的方法,在总航迹样本中随机选取10%作为测试航迹,将聚类结果可视化展示,通过航迹数据在二维空间中的分布图可以直观地获取航迹包含的聚类数目信息,由测试结果调节参数
Dstop,Dnearest。
1.2 航迹间距离/相似性
动态时间规整(DTW)是处理时间序列的一种常用技术。算法主要思想是改变航迹点对应匹配计算航迹距离的方法,通过扭曲时间来对某一航迹点重复采样,扩展匹配路径;通过迭代的方式从所有可能的变换路径中找出距离最短的匹配规则。
对于给定的两条航迹t1,t2,对应的DTW 计算公式(1):

其中DTW(i,j)为航迹t1的前个航迹点组成的航迹路径与航迹t2的前j个航迹点组成的路径的DTW距离,d(pi,dj)是指航迹t1的第个航迹点组成的航迹路径与航迹t2的第j个航迹点之间的欧氏距离。
DTW 相较于欧几里得距离无需要对数据进行插值去噪以及将航迹点数目匹配相等操作,能够计算采样数目不相等的航迹距离,但是有一个较为明显的缺点是其时间复杂度较高,对于大量数据的处理较为吃力。
为了克服传统DTW 时间复杂度过高的缺点,许多对DTW 改进方法被相继提出[13],其算法主要通过两种方式加速算法计算:①约束搜索空间范围,减少搜索次数;②细化搜索步长,确定搜索路径。本文采用快速DTW 算法计算航迹间距离,加快计算速度。
采用快速DTW 算法构造如下航迹相似度矩阵D表示航迹集合T中所有航迹相互之间的距离,式(2):

1.3 航迹簇之间的距离
由于合并层次聚类经常被使用,该方法需要度量簇与簇之间的距离,对于给定的聚类簇C1=常用的簇间距离度量方法如下:最小距离:定义簇间距离为两个簇间最近的两个点之间的距离,最大距离:定义簇间距离为两个簇间最远的两个航迹间的距离,平均距离:定义簇间距离为取自两个不同簇的所有点对间距离的平均值,式(3):

最大、最小距离度量比较极端,对噪声点和离群航迹较为敏感,平均距离是最大最小的折中,一定程度上可以克服离群点的影响。本文采用平均距离计算航迹簇之间的距离,用以克服离群航迹对聚类簇的影响。
2 航迹聚类算法
聚类就是将一组观测对象划分成不同的种类或簇,应用不同的聚类算法将相似的对象划为同一类,不相似的对象划为不同类。本文采用快速DTW 算法进行相似性度量后,应用剪枝及时剔除离群航迹,并行聚类加快收敛速度,实现航迹聚类过程的改进。
2.1 改进的层次聚类
在层次聚类算法中,主要分为凝聚的层次聚类和分裂的层次聚类,凝聚层次聚类是一种自底向上的聚类方法,该方法以单个对象为初始簇,逐步聚合与其距离最近的簇,直到某个聚类终止条件被满足。
假设聚类航迹集T航迹对象个数为nT,则其距离矩阵大小为nT×nT,则基于平均距离的凝聚层次聚类算法的基本过程如图1 所示:
(1)设每条航迹为单独为一簇,根据距离函数计算每个簇之间的距离D(Ci,Cj),得到初始化距离矩阵DT;
(2)查找距离最近的两个簇,并将它们合并为一个簇,此时簇的个数减1;
(3)根据距离函数重新计算新簇和旧簇之间的距离;
(4)重复(2)和(3)直到簇的个数达到预期设定值k。
由图1 可知,经典凝聚层次聚类算法在计算完距离矩阵后并没有对噪点进行处理,不仅浪费计算的时间与空间同时降低了聚类结果的准确度;每合并完一个簇,重新计算合并后的簇对象之间的距离更新距离矩阵,并在新距离矩阵中搜索最小距离,将对应的数据对象合并,单步合并操作,算法收敛速度慢,对于大型数据集的聚类,时间开销过高。
改进算法具体如图2 所示。
(1)输入航迹数据T,将每条航迹初始化为一个航迹簇,采用FastDTW 算法计算两两航迹簇之间的距离,得到初始距离矩阵D;
(2)计算每条航迹与其他航迹的最小距离α,由最小距离α及航迹簇内的航迹数量|Ci|判定航迹簇Ci后续操作:①加入队列Q,继续与其他簇合并;②该航迹簇为单独一类航迹,加入最终航迹聚类集合C;③该航迹簇内航迹属于离群航迹,将簇航迹加入离群航迹簇Cout。
(3)将队列内Q内航迹簇之间的距离按照升序排列。
(4)对队列Q内航迹簇按照合并规则进行合并。具体合并规则为:初始化每个航迹簇标志位置为0,flag=1,依次对队列Q内每个距离元素,判断其对应的两个航迹簇是否在此轮迭代中已合并到某个簇中,此时分为3 种情况:①两个航迹簇都没有发生过合并操作,即两个航迹簇标志位都不为0,则将这两个航迹簇合为一簇,同时将标志位设为flag,合并结束后flag+=1;②两个航迹簇有一个簇被合并到其他簇中,即其中一个航迹簇的标志位不为0,则将另外一个航迹簇合并到该簇中标志位置为该航迹簇的标志值;③两个航迹簇分别合并到了不同的簇中,即两个航迹簇的标志位都不为0,则将这两个簇合为一个簇,标志位统一。

图1 经典层次聚类算法流程
(5)判断合并的航迹簇数量是否大于1,若是,则转到步骤(6);若否,则合并后的航迹簇为单独一类航迹,将其加入最终航迹聚类集合C,返回航迹聚类结果:航迹聚类集合C、离群航迹集合Cout;
(6)将所有标志位相等的航迹簇合并为一簇,完成合并后,根据簇间距离计算公式,计算两两航迹簇之间的距离,更新距离矩阵D,回到步骤(2)。
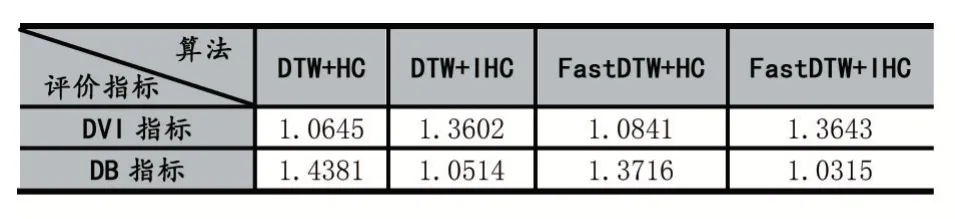
由以上算法描述得出剪枝操作体现如图3(a)所示:合并操作之前,求得该航迹与其他航迹的最近距离α,若该航迹簇与其他航迹簇距离较远且该航迹簇内航迹较少(nCi 并行操作体现如图3(b)所示:区别于一般聚类算法,单步合并距离最小的航迹簇,更新距离矩阵D。改进算法提出建立优先队列Q存储待聚类的航迹簇,对优先队列Q所对应的航迹簇同时进行合并簇操作,优先队列Q内航迹簇全部完成聚类后再依据航迹簇间距离计算公式更新距离矩阵,完成一次迭代。 通过剪枝与并行聚类加快了算法的收敛速度,降低整个聚类过程的时间复杂度。 图2 基于平均距离的改进层次聚类算法 图3 对于经典航迹聚类算法,假设待处理航迹数量为n,初始时航迹簇的个数即为n,由fastDTW 算法计算簇间距离公式,簇间初始距离个数为n×(n-1)/2,第一次查找距离最近的两个航迹簇Cr,Cs,,从n×(n-1)/2 个距离对象中搜索,需要进行次对比操作,复杂度为O(n2)。每次合并簇得得个数减1,新簇与原簇的距离根据簇间距离计算公式(3)重新计算。第二次合并簇,航迹簇的个数为n-1,需要从(n-1)×(n-2)/2 个距离中查找最小值,复杂度仍然是O(n2),依次类推,假设簇的个数为k。 合并簇比较大小的次数为通常情况下最终聚类得到的簇的个数k远远小于样本数n,则总比较次数为(n3-n)/6 次,更新距离矩阵时,计算次数总计(n+k-2)[(n-k-1)/2],总的复杂度为O(N3)。 本文改进的聚类算法,由fastDTW 算法计算航迹间距离,簇间初始距离个数为n×(n-1)/2,每次迭代分别对每个航迹簇求取最小距离,比较次数为n(n-1),经过剪枝操作后剩余航迹簇数目n',n'≤n;再对n'个航迹簇进行合并簇计算次数为n',合并后航迹簇个数为n'',n''≤n'/2,由式(3)更新距离矩阵。每次迭代总计算次数为考虑最差的收敛情况,即n'=n,则首次迭代计算次数为(3n2-n)/2,复杂度为O(n2)。第二次迭代计算次数为,依次类推,总的迭代次数为log2n,所以改进算法总计算次数为3n2-3,复杂度为O(n2)。 本文数据处理与算法实现过程采用Python 语言实现,其硬件平台为Windows10×64 位系统,内存为32.0GB,处理器为Intel Core i7-7700@3.6GHz CPU。 使用的是2019.6-2019.10 双流国际机场航班进港ADS-B 数据,其数据包含进场航空器的时间及经纬度坐标,在数据预处理阶段已将其经纬度坐标通过墨卡托公式转化为以机场为中心的机场坐标系,数据预处理阶段已经将采样点过少的残缺航迹剔除,每条航迹平均包含100 个采样点。 在聚类研究中,对聚类性能的评价存在大量指标,指标的评价主要是基于簇内及簇间相似度,为保证簇内相似度尽可能高,簇间相似度尽可能低,有以下两种度量标准: (1)紧凑度,用来衡量簇内样本点之间相似程度的指标。 (2)分离度,指不同簇的差异是否足够大。 上述两种度量标准在实际的聚类度量指标中,有很多量化指标对其进行有效性评价。如下两种度量: 戴维森堡丁指数(Davies-Bouldin Index,DB):计算的是任意两个类的类内平均距离(即CP 值)之和与两聚类中心距离的比值,求最大值。DB 越小意味着类内距离越小,同时类间距离越大,其计算为式(4): 邓恩指数(Dunn Validity Index,DVI):通过计算任意两个簇间的最短距离与任意簇内对象的最大距离。DVI 越大类间距离越大,类内距离越小,其计算为式(5)为: 实验对改进聚类算法的参数设置以及聚类最佳簇数进行了分析,对不同聚类参数的选取进行了调优,得出最佳聚类结果。对比测试了DTW 算法、快速DTW算法、传统层次聚类(HC)、改进层次聚类算法(IHC)的聚类结果,并从算法时间开销、聚类性能两个指标进行评价。 (1)不同算法运行时间对比 以下实验结果在上述硬件环境下进行测试,测试数据集为双流机场航班进场航迹,测试航迹数据数目:nT,航迹点数目:npoint,聚类结果可视图如图5 所示。 表1 算法时间对比 通过实际运行数据损耗时间比较可知,由表1 对比以上四种聚类算法,本文提出的FastDTW+IHC 聚类算法明显缩短了聚类算法运行时间,对于较大的数据集的聚类,显著提升了聚类效率。 图4 图5 不同进场航路航迹聚类二维平面图 (2)参数选取对聚类结果的影响 如图6 所示,当增大离群航迹数判定阈值ndrop,将会减少最终航迹聚类簇数目,增大离群航迹簇Cout内航迹数目;同理增大聚类终止阈值Dstop,亦会减少最终航迹聚类簇数目。 由上述结果可知,增大ndrop值时航迹聚类簇数目将会减少,当ndrop的值增大的一定值时,航迹簇的数目会维持在一个固定值,此时所得到的航迹簇数目为较为贴近真实航迹簇数目。对于航迹簇已知的聚类问题,增大ndrop值至航迹聚类簇数和已知条件一致。同理可调节聚类终止阈值Dstop。 (3)各类聚类算法性能指标 为验证各类算法聚类结果有效性,采用上文所提到的两种聚类性能评价指标,分别计算上述算法在最佳聚类簇数下得到的DB 指标值和DVI 指标值。表2所示为各算法在最佳聚类簇下得到的评价指标大小。 图6 表2 算法性能指标比较 由上述指标结果可以看出,本文改进的航迹聚类算法(FastDTW+IHC)DVI 值最大、DB 值最小,DTW+HC 算法得到的DVI 值最小、DB 值最大,表明本文算法取得的聚类效果最佳,DTW+IHC 算法得到的结果次之,DTW+HC 算法聚类效果最差。由以上得出快速DTW 算法相对于普通DTW 算法对于相似性的刻画更加准确,所以指标反映出来的结果更优;改进层次聚类算法在聚类过程中及时剔除了离群航迹,减少噪声干扰,所以比经典聚类算法在航迹聚类的准确度上表现更好。 本文提出的基于快速DTW 距离度量的并行剪枝层次聚类算法,通过在计算不同轨迹之间的相似度过程中采用快速DTW 算法取代计算效果较差的欧氏距离度量算法;合并簇与更新距离矩阵由单步运算改为批次运算,加快收敛速度;对于远离聚类中心的离群轨迹及时剪枝,减少不必要的合并簇与更新距离矩阵操作。通过处理大规模实际运行航迹数据,可视化聚类过程,相较于目前常用的层次聚类算法时间降低时间复杂度,该改进算法可应用于多种轨迹数据的聚类研究。

2.2 算法复杂度分析
3 实验结果分析
3.1 实验环境及数据来源
3.2 聚类性能评价指标
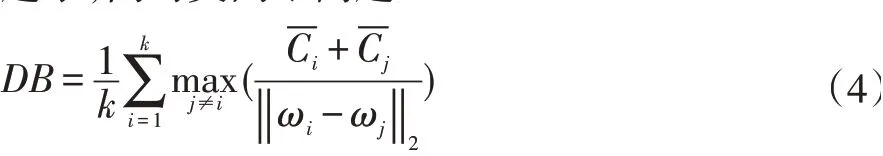
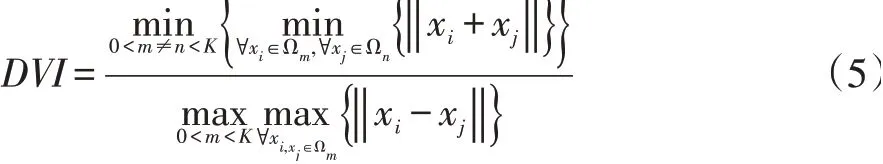
3.3 实验结果分析




4 结语
猜你喜欢
航空学报(2022年9期)2022-10-14
北京大学学报(自然科学版)(2022年4期)2022-08-18
北京航空航天大学学报(2022年7期)2022-08-06
舰船科学技术(2022年11期)2022-07-15
舰船科学技术(2022年10期)2022-06-17
计算技术与自动化(2022年1期)2022-04-15
社会科学战线(2022年2期)2022-03-16
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
意林(2019年11期)2019-06-30
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
