
手写汉字图像的特征矩阵提取
2020-08-07 14:40于万波李耀升
现代计算机 2020年18期
于万波,李耀升
(大连大学信息工程学院,大连116000)
0 引言
图像识别技术应用广泛,近些年成为研究热点[1-4]。而图像的特征提取与匹配则是图像识别的关键步骤,关于图像的特征提取,近年来涌现出大量的特征提取与识别算法,图像特征的种类也是十分的丰富;而各种语言的手写字识别,作为一种较为特别的图像识别,也成为了研究热点,尤其是以手写汉字做为研究对象进行的研究,如:Wang Yanwei 等人提出一种在分类前重新训练数据集的方法,训练集由位于分类边界附近的样本构成,并在HCL2000 和HCD 汉字数据库上进行检测,解决了对于自由笔迹,字符形状和外观样本的变异性较大,不能严格满足高斯分布,导致识别不准的问题[5]。Gao Xue 等人提出了一种新的用于手写汉字识别的局部线性判别分析(LDA)方法,解决了传统的LDA算法在用于无约束手写汉字识别时,容易出现类分离问题和多模式样本分布问题[6]。Bi Ning 等人将有效卷积神经网络(CNN)模型GoogLeNet 用于手写汉字识别,并进行了一些调整,实验结果具有很高的准确性[7]。Chen Guang 等人提出了一种新的基于非线性归一化的增强加权动态网格的特征提取方法,改善了手写汉字识别系统的性能,具有很好的识别效果[8]。关于手写汉字图像特征提取的方面,具有一定的研究意义与价值。
本文研究的是手写汉字图像的特征提取,以矩阵的形式表述图像特征,将从迭代和非迭代两个方面入手,首先以迭代法作为切入点,基于迭代理论,利用迭代函数系统的特性,构造相关动力系统,生成迭代序列,对这些迭代序列进行分析研究并构造图像特征矩阵,从中获取一定的规律并用于手写汉字图像的识别探究。另外通过构造三维矩阵序列图像,获取手写汉字图像的特征矩阵,并以此实现手写汉字图像的匹配与识别。实验探究使用的数据集为HCL2000 汉字库,使用MATLAB 实现实验仿真。
1 图像数据的获取及处理
依据HCL2000 汉字库的数据特性可知,HCL2000汉字数据图像按书写者以文件形式存放。每个HCL文件包含一个512 字节的文件头,记录了该文件的作者等相关信息。各手写汉字按区位码的顺序存放,每个汉字图像为64×64 的点阵,在存储过程中按比特存储,压缩为512 字节。所以,在获取图像数据的时候,需要对HCL 文件中的汉字数据进行解压,使其还原为64×64 的点阵。在这里,根据北京邮电大学模式识别实验室给出的HCL 文件读取方法,使用MATLAB 进行实现,从而读取出指定的手写汉字图像。每个图像的灰度值大约有40-60 个,图1、图2 所示为数据集中第8个人、第12 个人所书写的第31-60 个汉字。

图1 第8个人书写的第31-60个汉字

图2 第12个人书写的第31-60个汉字
由于图像的本质就是一个矩阵,所以直接用汉字图像矩阵代入corrcoef 函数计算相关系数,通过实验发现,直接计算出的相关系数不能很好的表述两幅图像的相关性;所以在此不能直接使用图像矩阵数据进行相关系数的计算。
接下来我们将尝试利用迭代函数系统进行手写汉字图像的特征矩阵的提取与识别检测。
2 基于迭代的特征矩阵提取与研究
2.1 迭代动力系统构造与分析
构造的如式(1)所示动力系统:
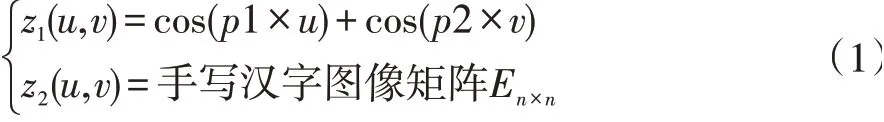
其中p1、p2 随机给定(p1=p2=0.01*rand)。
读取手写汉字数据,解压并存储在二维数组中;确定实验参数并进行迭代运算多次,保存、输出迭代轨迹序列矩阵T;
通过实验分析发现:由于手写汉字图像存在大面积的平坦区域,从而导致动力系统的混沌特性较差,系统容易收敛,所以当初值(u,v)比较少,迭代次数较多(m 较大)时得到的序列点较少,不能获得较好的迭代轨迹序列。
接下来,我们考虑对汉字图像进行一些相关处理,并对系统进行改进,以此来提高实验效果。
2.2 图像预处理
(1)给图像加斜面
根据图像的大小,初始化一个相同大小的斜面矩阵,加在目标图像矩阵上,使其整体倾斜,减小其字体边缘部分的像素差,效果如图3 所示。

图3 加斜面之后的汉字图像与原图像对比
使用加了斜面的图像矩阵进行迭代演算,获取迭代序列并记录保存,分析迭代序列数据,进行识别计算,其实验效果有了一定的提升。
(2)拉伸图像,使其增高
接着来尝试,将目标图像的字体拉伸,扩大其轮廓,使其字迹加粗,减小空白区域,并对字体部分进行加高处理(思路源自刻章)[9]。
通过循环,将原图像素点依次按照左、下、右、上的次序进行多次位移,将每次位移之后的图像依次叠加起来,从而起到拓宽图像字体并使其增高的效果,如图4 所示。

图4 移位叠加操后的图像与原图像对比
最后将叠加后的图像放大至256×256 大小,然后对图像矩阵进行归一化处理,并使其像素值保持在1到255 之间,使用处理后的图像与三角函数迭代式共同构造动力系统,进行下一步实验操作。
2.3 识别优化
通过实验发现,直接用三角函数表达式与图像函数构造动力系统来实验,效果并不是很好,用三角函数表达式作为迭代式,迭代赋值构造迭代矩阵T,用矩阵T 与图像构造动力系统,这样效果提升很多。然后我们考虑多个特征综合来进行识别。
选取多个人书写的同一个汉字,分别进行迭代实验,将每次的特征矩阵综合起来作为这一汉字的综合特征,然后与目标图像的特征矩阵进行相关系数的计算,发现实验效果有所提升。
在这里,我们选取数据集中前10 个人的第2、3、4个汉字作为样本数据,分别构造出这三个汉字的综合特征矩阵,并与第10 个人所书写的前六个汉字的特征矩阵进行相关系数的计算;实验发现,其同一个汉字的相关系数最高能达到0.35 左右,不同汉字的相关系数普遍在0.2 以内,这能较好的体现两幅汉字图像的相关性(例如给定阈值0.3,规定大于0.3 的为相同汉字,小于0.3 的为不同汉字)。
具体实验数据如表1 所示。
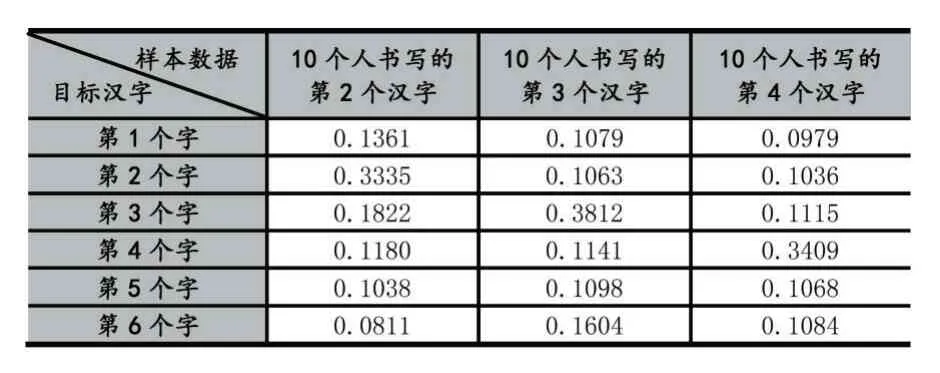
表1 多个汉字间的相关系数
接下来,我们尝试扩大样本数据,设计识别率计算算法,进行识别率相关探究。
2.4 识别率的计算及其分析
改进迭代方法,并设计识别率计算算法,提取多个人书写的多个汉字图像作为样本数据,同一组为不同人写的同一个汉字,获取样本数据的特征矩阵;确定每个汉字的训练情况,构造综合特征矩阵,并按数据集中汉字的存储顺序保存;使用样本数据中所有汉字的特征矩阵分别与每个字的综合特征矩阵计算相关系数,判断每个汉字所产生的多个相关系数中,最大值的位置是否与本汉字的组数一致,若一致则说明识别成功。
算法1 迭代提取图像特征
1)将式(2)做为迭代式,循环计算,得到迭代矩阵T;

2)确定样本数据量,依次读取样本中每个汉字图像,并对其进行加斜面、移位叠加操作;
3)利用迭代矩阵T 与汉字图像构成迭代动力系统,提取样本中每个汉字的特征矩阵T1,并按组别顺序保存(同一个汉字为一组,分组顺序与数据集中汉字排列顺序一致);
4)训练部分汉字:确定样本数据中的每种汉字的训练情况(选择多幅图像来构造这一汉字的综合特征矩阵),将准备训练的图像数据循环代入迭代动力系统(同步骤3),得到每个汉字的综合特征矩阵T2,按照汉字存储的顺序保存;
5)依次将样本中所有汉字的特征矩阵与这些汉字的综合特征矩阵进行相关系数的计算,每个汉字对应多个相关系数,若使相关系数最大的那个综和特征的位置与汉字的组数一致,则说明识别成功;
6)记录识别成功的汉字数目,与样本汉字总数对比,计算识别率。
我们先来提取30 个人书写的20 个汉字,共计600个汉字图像,每个汉字训练10 张图像(即用10 个人书写的同一汉字来构造综合特征矩阵)运行程序后,识别出421 个汉字,识别率为70.17%;每个汉字训练20张,可识别出477 张,识别率为79.5%;若每个汉字训练30 张(即全部训练),可识别出600 张,识别率为100%;为了保证实验结果的准确性,我们继续扩大样本数据进行实验。实验数据如表2 所示。
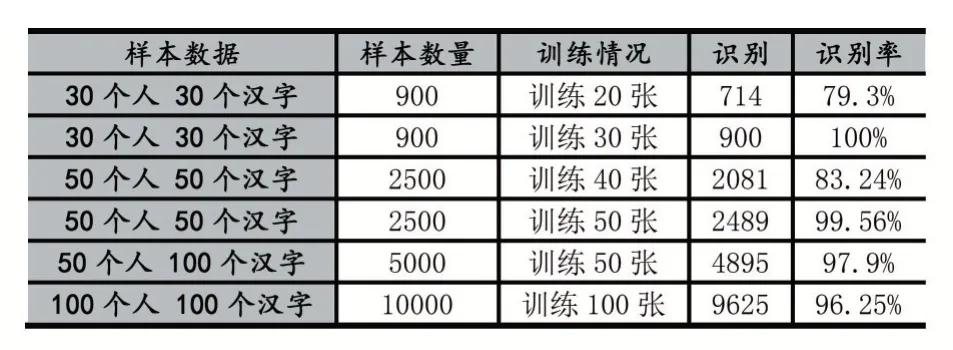
表2 扩大样本后的实验数据
由这些实验结果可以说明,基于迭代的手写汉字图像特征矩阵提取方法确实可行,所提取的特征矩阵能较好的表述图像之间的相关性。
3 基于三维矩阵的图像特征提取与识别
由于一个手写汉字图像的大小为64×64,所以在这里,我们使用64 个人书写的同一个汉字,来构成64×64×64 的三维矩阵作为样本数据,然后获取一个人书写的某一个汉字图像,并对其进行一些相关处理,改变其结构使其成为64×64×64 的三维矩阵,然后与样本中的矩阵进行相关性的计算,分析结果,进行手写汉字的识别探究。
3.1 构造三维特征矩阵计算相关系数
算法2 迭代提取三维特征矩阵
(1)获取64 个人所书写的同一个汉字的图像数据,并解压为64×64 大小的矩阵;
(2)将所得的64 个64×64 矩阵糅合为64×64×64的三维矩阵,作为样本数据并保存;
(3)获取一个人的一个汉字图像,并对其边缘裁剪64 次,得到64 个64×64 的矩阵,并将其糅合为64×64×64 的三维矩阵;
(4)计算两个三维矩阵的相关系数。
通过大量实验结果表明,同一个汉字的相关系数大约在0.15~0.3 左右,不同汉字的相关系数基本小于0.15,初步判断该算法可用于手写汉字图像识别的实际研究。
3.2 计算识别率
在上述算法2 的基础上,做出一些改进,在这里我们选取30 个汉字构造三维矩阵并按汉字排列顺序保存,作为样本数据,然后选取其中一个汉字图像作为目标,得到其三维矩阵,并与30 个样本矩阵进行相关系数的计算,若使相关系数最大的样本数据的位置与目标汉字的位置相同则说明识别成功。
算法3 利用三维特征矩阵进行识别
(1)读取64 个人书写的同一汉字数据,解压糅合为64×64×64 的矩阵;
(2)重复第1 步骤30 次来获取30 个汉字的数据,将每次得到的三阶矩阵存入64×64×64×30 大小的数组中去,作为样本数据;
(3)任意选择10 个人,依次获取其书写的样本中的30 的汉字数据,并进行相关处理;
(4)将所得的300 个汉字分别与样本数据中的30个汉字计算相关系数,每个目标汉字可得到30 个相关系数,若相关系数最大的对应的样本汉字在数据集中的位置与目标汉字所对应的位置相同,则说明识别成功;
(5)记录识别个数,计算识别率。
下面我们来分析实验过程,尝试提高识别率。
3.3 识别效果及分析
为提高实验效率,我们以30 个汉字作为样本数据,以10 个人书写的30 个汉字作为目标数据,来进行实验,分析探究,提高识别率。
在上节实验中,10 个人书写的30 个汉字,识别率为80.67%。
(1)裁剪目标数据
为了让目标汉字(64×64)与样本数据(64×64×64)能更好的比较,在之前的算法中,我们将所获取的目标汉字图像进行边缘裁剪,共裁剪64 次,将所得的64 个图像数据糅合为与样本同规格的数据来进行实验比较,在这里我们从这一角度出发,多次调整目标数据的裁剪参数,找到识别效果最好的参数,以此来提高识别率,并在此基础上对汉字图像进行一次预处理,对其进行移位叠加操作。
(2)对图像进行移位叠加
算法4 移位处理后提取特征
1)打开数据集文件,读取汉字数据;
2)将汉字数据解压为64×64 大小的矩阵;
3)初始化一个64×64 的矩阵temp,用来存放解压后的汉字数据;
4)初始化一个64×64 的矩阵tempN;
5)移位叠加,操作如下:
①将图像矩阵数据整体左移一位,赋给新初始化的矩阵(将temp 的2 到64 列赋给tempN 的1 到63 列);
②再将原图像矩阵依次下移、右移、上移一个点位,然后每次都行平移的矩阵赋给tempN(依次叠加);
③重复步骤1、2 多次,每次平移的点位加1。6)用叠加后的图像进行实验操作;
此时的识别率为85.33%;优化实验操作以及扩大样本后的实验结果如表3 所示。
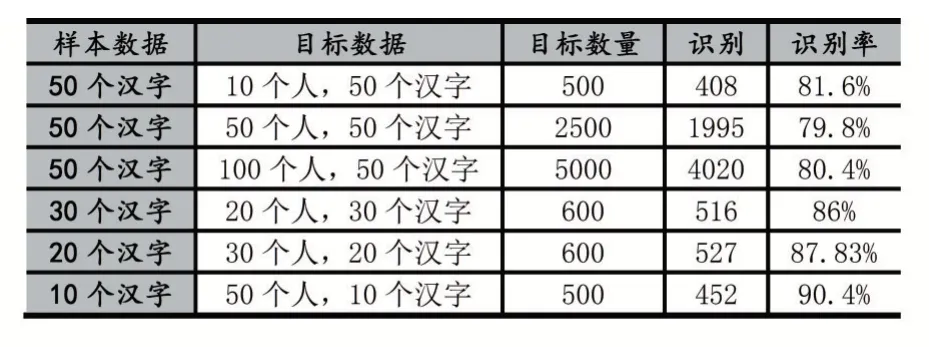
表3 多组样本的实验数据对比
这些实验结果说明,构造三维矩阵(序列图像)作为汉字图像的特征矩阵进行手写汉字识别的方法确实可行,并且取得了较为不错的实验结果。
4 结语
目前比较常见的脱机手写汉字识别主要是基于深度学习技术来进行的,而关于这方面的研究也涌现出大量的文献报道,本文所提出的特征提取与识别的方法,与其他方法相比,具有系统结构复杂度低,运算成本小,样本数据的获取成本低等优点。
大多基于深度学习的方法,在获取样本数据的时候,需要进行大量的训练才能达到满意的程度,系统结构较为复杂,运行成本较高;我们在实验探究过程中,通过迭代构造特征矩阵以及构造三维序列图像矩阵等方法来获取样本数据,一定程度上降低了系统结构的复杂程度和运算成本,提高了实验效率。
猜你喜欢
故事作文·低年级(2021年12期)2021-12-21
文苑·经典美文(2019年8期)2019-08-06
读与写·教育教学版(2017年10期)2017-11-10
中国高新技术企业(2017年5期)2017-05-05
软件(2016年6期)2017-02-06
物联网技术(2016年11期)2017-01-12
电脑知识与技术(2016年24期)2016-11-14
前卫文学(2016年3期)2016-07-01
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
