
基于大数据的高校毕业生就业系统的设计与实现
2020-09-10 07:22陆一鸣李雪竹
客联 2020年11期
陆一鸣 李雪竹

【摘 要】当今时代高等学校毕业生日趋增多,岗位需求增长缓慢,就业难度逐渐增加,同时高校应往届毕业生在所学专业和社会需求却并不对称,存在一定的错位现象。在此背景下,以大数据分析为主基础,通过对于毕业生就业各种方向的分析,设计实现一种较为全面的高校毕业生就业系统。系统主要以高校毕业生的需求分析和就业实际情况分析寻找相通处,并通过算法工具就行研究,增强对高校应往届毕业生在就业领域上的指导作用。
【關键词】数据处理分析;算法设计;就业领域
一、引言
近大部分高校应届毕业生更倾向较为发达城市的工作岗位,逐步使这些城市的人才趋于一个饱和的状态,导致部分地区城市的岗位富余且没有毕业生去应聘。在外工作数年后,有部分学生有返乡打算并付诸行动,使其与应届毕业生就业相碰撞,造成就业压力的加大。同时,目前部分选择先就业再择业,跨所学专业的就业和对相应工作的不了解,造成了一定程度的人力资源浪费。从目前来看,传统的就业理念不足以支撑现如今的就业形势。如何更好的就业,是否了解相关的就业形势,不同等级的院校毕业生情况等方向成了现如今研究的重中之重。高校毕业生就业系统从毕业生数据挖掘分析和社会需求同职业影响力相关联,找寻一个新的突破口。毕业生的实际工作生活状况和预想的状况的对比、数年后是否返乡就业则是最大的变化。现如今的就业系统大多以单位给出需求为主,无法实现智能化的就业选择,同时如何在保证用户的信息安全的状况下为用户提供最好的就业方向成了最为重要的技术难题。针对以上的问题,本文将在大数据分析下设计一种全新的高校毕业生就业的初步系统。
二、功能需求
系统以毕业生、用人单位、高校以及各地政府为主要方面。分别从就业意向、实际就业、就业同生活环境、就业率以及公务员、教师和“三支一扶”为主要抓手。其中用人单位、高校、政府为第三方,方便于毕业生的就业问题的实现。
(一)毕业生方面
毕业生作为系统的核心,通过用户注册,并对其一定的专业和意向评估,为毕业生进行用人单位的数据筛选。在初选用人单位时,可通过客服给予其初筛的用人单位和相似度极高的用人单位一定的了解。进行二次筛选时增加通过该系统就业后进入用人单位的个人反馈,增强毕业生对该单位的了解。最后向用人单位发送就业意向函,直接同用人单位联系。用人单位和个人可选择线上和线下两种签约模式,待合同签约成功后上传系统。待就业半年、一年、三年后填写相应的个人反馈。若为应届毕业生,系统反馈其就业信息给毕业生所在高校。
(二)用人单位方面
用人单位在系统上注册后可发布相应的人才需求并标注相关信息,如:薪资待遇、单位所在地、节假日安排等。用人单位可以通过相应的人才需要对有此意向的毕业生进行筛选,同时与毕业生进行直接的沟通交流。若被毕业生选中后,同毕业生进行线上或线下的就业交流,保障就业生的就业环境。同时为保障毕业生的基本权益,产生的就业协议会通过专业人员进行检查。
(三)高校方面
系统对于高校注册后开设查看毕业生就业方向和就业单位等权限,每年高校对各二级学院各专业的就业率以及平均薪资和跨专业人数进行更新,方便高校日后进行课程改革。高校对于毕业生有就业指导的意义,指导毕业生如何去选择用人单位。同时为了保障学生在实践和理论上可以完美的结合,开展实习实训,加强实践。另一方面,应届毕业生就业后半年或者一年后,高校应组织相关人员对就业毕业生进行就业反馈。
(四)各地政府方面
各地政府在系统注册后对其开放各不同学历的人才数量和就业方向等权限,充分把握本地区的人才分布情况和所缺人才的方向。同时增加与高校联合培养人才的信息掌控环节。
三、数据挖掘
数据挖掘目前有决策树、神经网络、云模型等,但是各自都有自己的局限性,打破这种局限性,在综合性能上得到提升,提高数据挖掘的效果成了重中之重。
(一)决策树方向
以概念学习系统为基础,对目标对象的特征进行判断和确定,基于不同的特征将数据库细分为多个特征子集,再由此作分枝,将其内部的元素一一映射,通过递归的方式,令全部的子集进入包含类型相同的数据,根据决策树的结果对数据完成分类。
(二)神经元网络方向
神经元按照一定规律排列,形成系统性的神经网络,使用既定的数据处理方式对数据处理,并将分析结果储存。本质上是在逼近原始数据与其特征之间非线性极强的映射关系。【1】直接使用确定的网络分类对神经网络实现过程进行跟踪和描述。
四、数据挖掘、数据库引用与数据处理过程
确定所要挖掘的数据,由于无法保障百分百的准确性,所以要对必要数据进行检测。其次就行预处理并且做数据转换,可加深分析同时转换数据为分析模型。随后提取模式,对已有的变量进行筛选后确定。对于不同的类型,使用方式不同,产生错误的概率降低。最后通过实际验证后构建相应的模型,明确检测的结果。以实际需求还对数据库进行设计,实现耦合度低、聚合性高;伴随数据库的数据逐渐增加,保证数据库的稳定运行;同时在数据库系统的数据安全性只少有三个方面:机密性、完整性、可用性。为保障云数据库的机密性,要进行数据加密或只加密处理而不处理。【2】
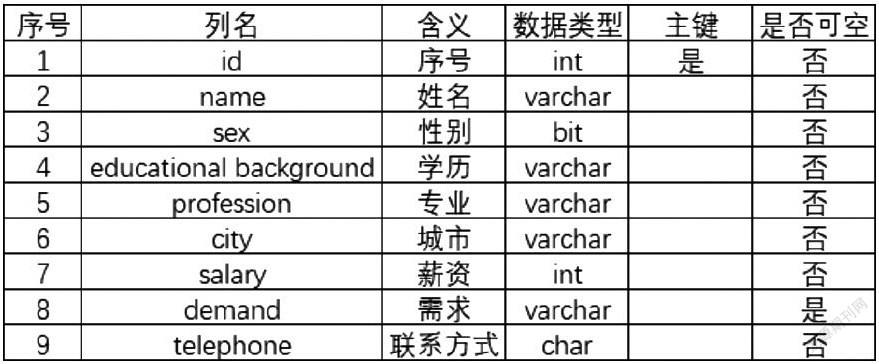
用户在使用数据库的时候各方面产生的问题可以解决,系统的各个功能模块要相互关联,保持一致性和完整性,并完善数据表的设计。将数据结构分为用户层、应用层、分析层、存储计算层以及数据整合层五个层级。在数据收集环节,结合标准Hadoop开源技术,对多种数据整合,进行统一的数据采集与汇总。在数据存储计算环节,在底层构建结构化数据与非结构化数据混合存储的数据存储区,并结合不同数据的特性,按主题进行数据切割、关联、打包,形成主题数据库。【3】在数据分析环节,形成了可量化的分析模型。部分信息存储的用户表设计:
并在允许的范围内对地区人力资源与社会保障部分进行访问,单独构建就业大学生的模型设计,对就业大学生的数据处理,对省内大学生和省外大学生的迁移的数据进行流程分析。主要以模型设计、数据处理流程分析、数据库表设计为主要方面。其中使用Haddop根据定义好的map和reduce,进行正则匹配,匹配成功则把结果通过reduce聚合起来返回,Hadoop把程序分布到N个结点并行操作。【4】以其中map阶段的输入数据处理(Mapper)的部分代码为例实现:
Public static class TokenizerMapper extends Reducer<Text,InWritable,Text,InWritable>
{private final static InWritable one = new InWriter(1);
Private Text word = new Text();
Public void map(Object key,Textvalue,Context,Context context)throws IOException,InterruptedException{
StringTokenizeritr = new StringTokenizer(value.toString());
While.set(itr.hasMoreTokens()){
word.set(itr.nextToken());
context.writer(word.one);}}
}
关于数据去重方面,主要将大文件分割成多个小文件,依次遍历每个小文件,读取其中存储的字符,构建Trie树,并在每个终止节点记录改结点代表的字符串。
在海量数据集中进行筛选时,找到相应的数据是系统的重中之重。所以使用Bloom Filter和hash函数。以存在性判定为例,依次遍历每个大文件中每条数据,遍历每条数据时,都将它插入Bloom Filter,如果已经存在,在另外的集合A中记录,如果不存在,则插入Bloom Filter,最后所得的集合A进行导出,即为所要查找到的集合。
五、结语
本文设计开发的高校毕业生就业系统,主要依附于大数据的数据处理,通过数据的处理筛选,为高校的应往屆毕业生提供就业指导方案,便于用户使用。此外,相较于传统的高校就业系统,添加了高校和各地政府的想切合,签约后向高校进行反馈,同时使本地政府明确当地的人才组成。增加了毕业生的入职反馈用来当做其他毕业生选择的参考方向,加强相关专业人士对合约的检查,保障毕业生的基本权益。
【参考文献】
[1]张蕾,章毅. 大数据分析的无线深度神经网络方法[J]. 计算机研究与发展, 2016, 01: 68-79.
[2]程学旗靳小龙,王元卓等.大数据系统和分析技术综述[J].软件学报,2014.09: 1889-1908.
[3]何培育.基于互联网金融的大数据应用模式及价值研究[J]. 中国流通经济, 2017, 05: 39-46.
[4]刘丁发,葛雪锋,邓春华. Oracl数据库应用与开发实战[M]. 上海:上海交通大学出版社,2017.
