
基于视频监控的手扶电梯乘客异常行为识别
2020-09-11 11:25杜启亮黄理广田联房黄迪臻靳守杰李淼
华南理工大学学报(自然科学版) 2020年8期
杜启亮 黄理广 田联房 黄迪臻 靳守杰 李淼
(1.华南理工大学 自动化科学与工程学院,广东 广州 510640;2.华南理工大学 自主系统与网络控制教育部重点实验室,广东 广州 510640;3.广州地铁集团有限公司,广东 广州 510335;4.日立电梯(广州)自动扶梯有限公司,广东 广州 510660)
手扶电梯通常安装在城市人流量密集的重要场合,给市民出行带来便利。但由于乘客搭乘扶梯时安全防范意识不够,导致扶梯上的安全事故层出不穷。因此,通过对手扶电梯的监控视频进行算法分析,自动检测出乘客搭乘扶梯时的异常行为,对加强城市安全建设有重要的意义。随着计算性能的提升和算法研究的日益成熟,深度学习给人们的生活带来了巨大的变化,其中包括视频监控领域[1]。
近年来,行人的行为识别研究得到了广泛的关注,成为视频理解中一个重要的组成部分。一般来说,行人的动作可以通过多种模式识别出来,如人体骨架[2]、时空信息[3- 4]、光流信息[5- 6]以及时间特征[7]等。文献[8]对视频帧的人提取轮廓,根据轮廓计算人体重心以及各枝干顶点,并将重心和顶点构成的矢量作为特征向量来判断异常行为,但只能用于简单的环境中。文献[9]使用历史运动图和能量图来表示人体运动,并使用模板匹配的方式来识别异常行为,但模板匹配能识别的异常行为较为单一,适用性不强。文献[10]使用光流特征来提取运动信息,进而定位感兴趣区域,然后使用方向梯度以及光流直方图提取出运动特征,最后使用支持向量机对异常行为进行分类,但光流提取过程计算量较大,因此不能实时处理。文献[11]先使用 Kinect提取骨架,然后使用隐马尔可夫模型对归一化后的骨架向量序列进行行为分类,但Kinect在室外容易受强自然光的影响,导致编码光被淹没,骨架提取效果较差;而且使用马尔可夫模型虽然可以对时序很好地建模,但并不能很好地利用人体部位的连接信息。在多种动作模式中,人体骨架在行人行为识别任务中往往能传达更多的信息。随着深度学习的发展,基于骨架建模的深度学习行为识别方法不断涌现,如使用循环神经网络[12- 13]、时域卷积神经网络[14- 15]来提取骨架信息并对行为进行端到端识别。尽管这些深度学习方法都强调了人体部位连接的重要性,但在建模过程中,都需要特定的人体运动专业领域知识,较为复杂。文献[16]使用Openpose[17]提取骨架,结合人脸检测进行相邻帧之间的行人跟踪,最后使用动态时间规整(DTW)的模板匹配对异常行为进行分类。由于骨架本身就有语义信息,可以很好地代表行人,而且骨架提取比文献[16]中的SVM人脸检测准确度要高,因此骨架相比人脸可以作为更好的特征用于行人跟踪。另外,文献[16]中的骨架提取方法是自下而上的,当两个人很靠近,关键点组合成骨架时会容易产生分配错误的问题,且模板匹配方法检测异常行为会出现模板难挑选、适用性不强的问题。因此,现有算法不能对复杂场景中乘客的异常行为进行准确、快速的识别。
本文基于文献[16]的骨架提取-行人跟踪-行为分析的系统设计框架,提出了一种基于手扶电梯智能视频监控的乘客异常行为识别方法:首先对扶梯场景乘客的骨架进行提取,然后利用骨架距离及匈牙利匹配算法对乘客骨架进行跟踪,最后使用图卷积神经网络结合滑动窗统计的方法对单帧乘客骨架进行行为分类和识别。
1 手扶电梯乘客异常行为识别算法
手扶扶梯监控摄像头的安装位置如图1所示。使用3.6 mm焦距的摄像头,从扶梯斜上方往下进行拍摄,以保证能够得到较清晰的成像。文中算法由3部分组成,包括乘客骨架提取、乘客跟踪和乘客行为分类,算法流程图如图2所示。
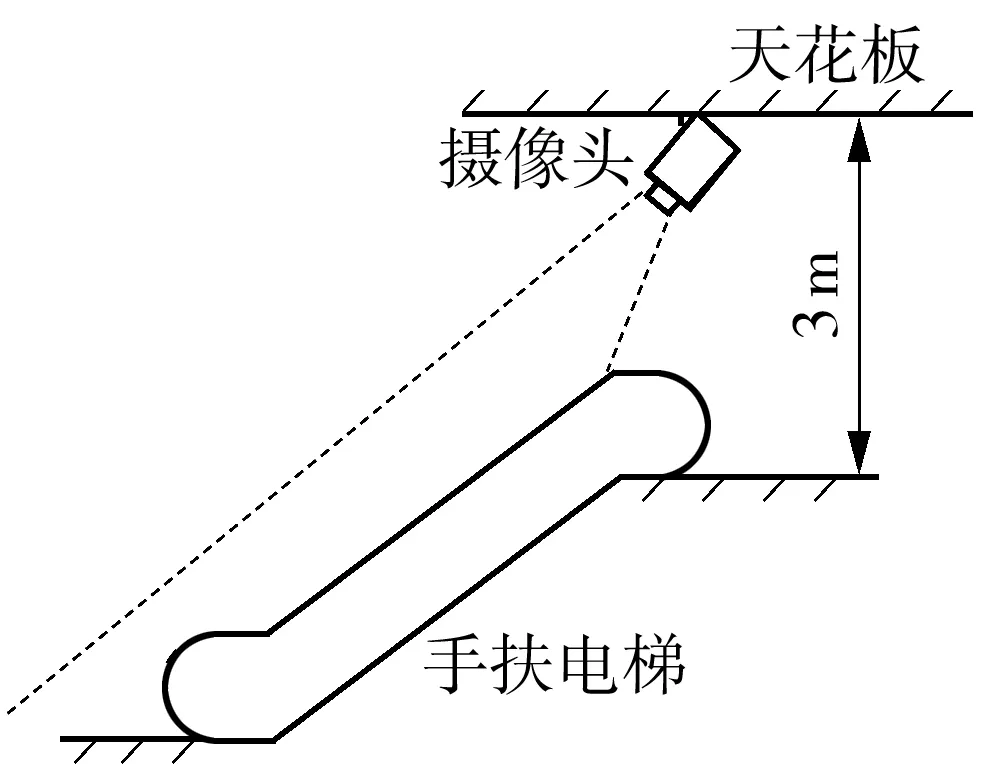
图1 摄像机安装位置示意图Fig.1 Schematic diagram of location of camera installation
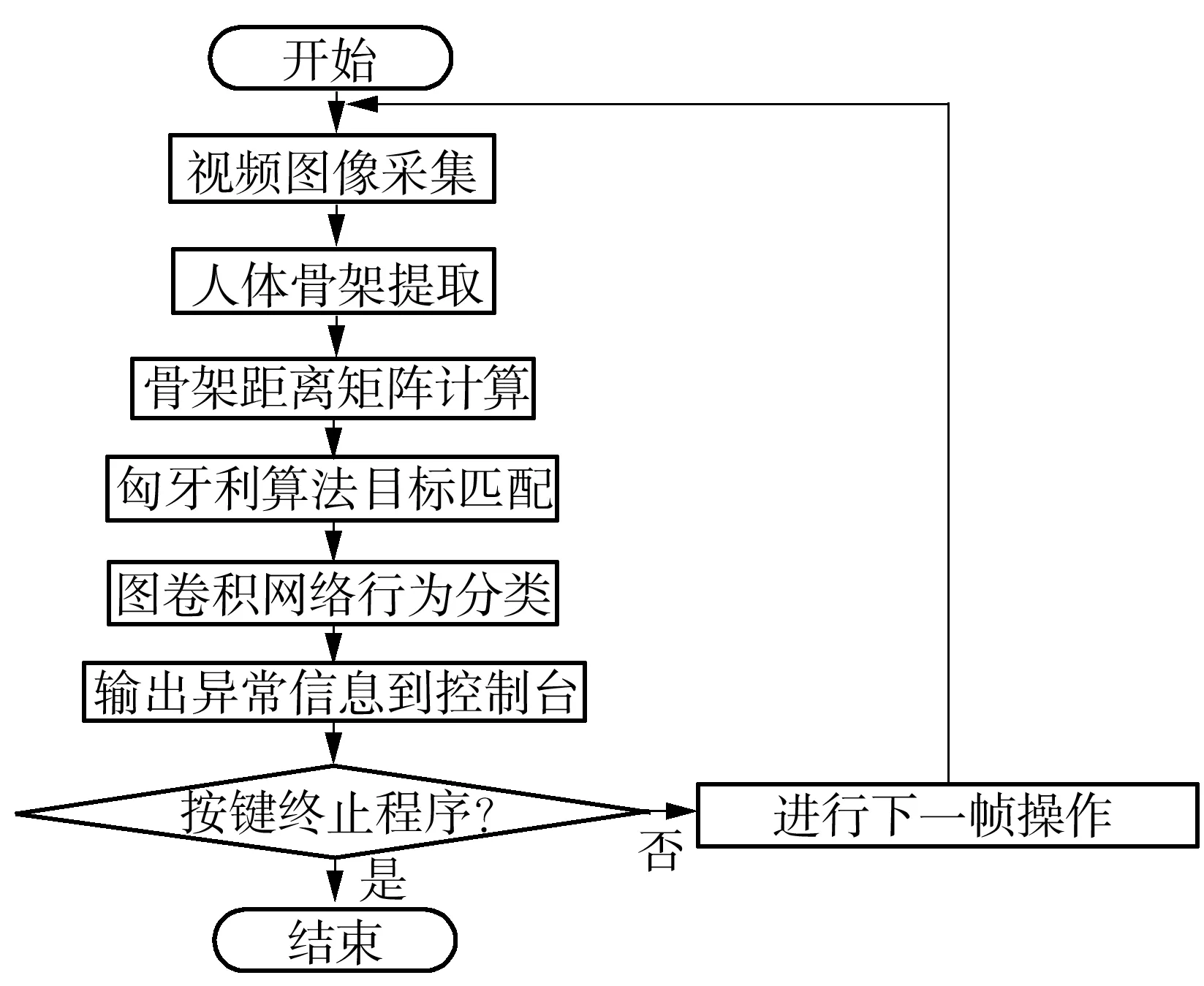
图2 文中算法流程图Fig.2 Flowchart of the proposed algorithm
乘客骨架提取是识别和定位出图像中所有乘客的关键点,并根据人体的骨骼关联性将其连接起来。人体骨架通常可以传递重要的运动信息,因此可以作为行为识别的主要依据。现有方法可以分为自上而下[18- 20]和自下而上[17,21- 22]的方法。自上而下的方法首先使用行人检测方法将图像中的行人检测出来,然后使用单人关键点提取方法对关键点进行定位;而自下而上的方法先从图像中检测出所有人体的关键点,然后基于各种数据关联技术将这些关键点连接起来形成骨架。其中自下而上的方法对于行人拥挤的情况存在关键点混淆的缺点,难以将个别关键点归到对应正确的人,这对后续使用关键点作为依据的乘客行为识别的影响较大。因此,本文使用自上而下的关键点提取方法,先使用YOLOv3[23]对图像中乘客的位置进行检测,再使用MobileNetv2[24]作为基网络,结合反卷积层对检测出来的乘客进行人体关键点提取,能较好地克服行人密集时关键点组合成骨架分配错误的缺点。
乘客跟踪的目的是为了保证相同的乘客在不同视频帧中具有相同的ID号,这是后续分析视频中乘客异常行为的基础。为了判别处于不同视频帧中的乘客是否属于同一个人,显然需要一种标准来定量衡量两个乘客的相似度。传统跟踪方法(如均值漂移方法等)通过提取图像的色彩、梯度特征(如直方图特征、HOG特征),并根据特征向量的距离来计算相似度,因此受图像噪声的影响较大。而深度学习方法往往通过一个孪生卷积网络来分别提取乘客的深度特征向量,并通过计算乘客深度特征向量的距离来计算乘客相似度,但这样的孪生网络将使跟踪部分显得冗余,徒增计算量。乘客骨架是通过神经网络来提取的,且不同乘客的骨架坐标和置信度有较大的区别,因此乘客骨架除了用于后续的行为识别外,还可用作衡量两个乘客相似度,且鲁棒性较高。但遮挡、光照不均匀等的干扰,会导致骨架提取结果缺少部分关键点,人体的完整骨架并不能完全提取得到,因此在计算两个骨架的相似度时,往往会由于维度丢失而难以计算。为此,本文提出了一种骨架距离计算方法,该方法考虑了两个骨架相同关键点的置信度和距离;并基于该骨架距离,采用匈牙利匹配算法来实现视频帧间的乘客骨架重识别,从而实现监控视频中的多人跟踪。
通过人体骨架提取及乘客跟踪,可得到视频中每个乘客的人体骨架序列,以用作乘客异常行为分类。由于乘客同种异常行为发生时各不相同,如摔倒行为中有的乘客在摔倒前会由于站立不稳而摇晃并做出多余的动作,有的乘客摔倒的过程慢,有的乘客摔倒得毫无征兆、触不及防,因此以异常行为的发生过程作为检测依据[14],会由于实际中异常行为的多样性而导致难以枚举出真实情况下异常行为发生的所有过程,使样本的收集极其困难。同时,对视频序列中异常行为的检测通常是以滑动窗的形式,如果以异常行为的发生过程作为检测依据,会使滑动窗较大,在滑动步长不变的情况下,会大大增加算法的计算量。为此,本文使用图卷积神经网络[25](GCN)作为行为识别神经网络对单帧骨架的异常行为进行分类,然后对同一个乘客进行滑动窗投票,如果多帧中有超过阈值的帧数分类为某种异常行为,则判断乘客发生了该类异常行为。
2 乘客骨架提取
本文使用YOLOv3、MobileNetv2与反卷积结合的自上而下的人体骨架提取方法进行乘客骨架的提取,具体流程图如图3所示。

图3 骨架提取流程图Fig.3 Flowchart of skeleton extraction
2.1 基于YOLOv3的乘客检测
首先使用YOLOv3对摄像头采集的图像进行行人检测。YOLOv3是单阶段的检测神经网络,相比Faster R-CNN、Mask R-CNN等网络具有检测速度快的特点,同时相比于YOLOv1、YOLOv2引入了多尺度,对离摄像头不同距离的行人均有较好的检测效果。基于YOLOv3的行人检测结果见图4。

图4 基于YOLOv3的行人检测结果Fig.4 Human detection result based on YOLOv3
2.2 基于MobileNetv2和反卷积的乘客关键点提取
用于行为识别的人体关键点共有14个,包括头、颈、左肩、右肩、左肘、右肘、左腕、右腕、左髋、右髋、左膝盖、右膝盖、左脚踝、右脚踝,人体骨架由关键点和相连骨骼组成,见图5(a)。
对检测出来的乘客进行关键点提取,关键点提取网络使用MobileNetv2作为基网络,该基网络使用了深度可分离卷积,可以避免传统卷积计算量庞大的问题,加快深度特征的提取速度。本文的关键点提取网络先使用基网络对原图像进行5次下采样,再使用反卷积层对提取出来的特征进行3次上采样,训练和推理的主要流程如图6所示。
在前向推理过程中,为了去除噪声干扰,将图像进行水平翻转后,与原图像一起输入到神经网络中,并对水平翻转图的输出热点特征图通道进行交换,使其与原图像的输出特征图的通道顺序保持一致;然后将原图像与左右翻转后的图像的输出热点特征图求和取平均,以达到滤除噪声的效果;最后找到输出热点特征图各个通道最大响应的位置,并将其位置乘以神经网络下采样倍数,即对应原图像人体关键点的坐标。人体骨架提取结果见图5(b)。
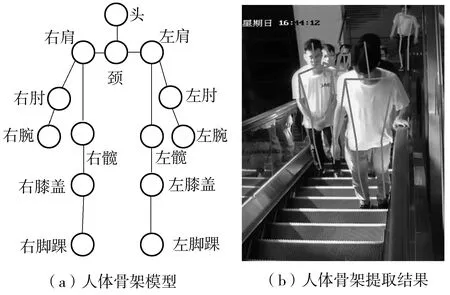
图5 人体骨架提取结果图Fig.5 Results of human skeleton extraction

图6 关键点提取网络结构Fig.6 Network structure of key points extraction
3 基于骨架距离和匈牙利匹配的乘客跟踪
为了对视频中的多个乘客进行跟踪,需要先计算相邻帧间乘客骨架的距离矩阵,在对距离矩阵进行滤波之后,再采用匈牙利匹配算法对矩阵进行求解并实现乘客重识别。另外,乘客的进入以及离开监控范围通过文献[26]的置信度规则进行管理,即为每个新进入监控范围的乘客分配一个置信度并初始化为0,在跟踪成功时置信度会升高,而在跟踪匹配不成功时,置信度会下降,在乘客离开监控范围时置信度会下降至0以下,此时将该乘客从跟踪列表中剔除,从而实现跟踪管理。
3.1 骨架距离矩阵的计算
视频监控中的乘客i,从进入监控到离开监控范围,都有其对应的上一时刻t-1的历史骨架H(t-1)i。H(t-1)在后续过程中计算骨架距离以及跟踪时起到重要的作用。在t=0时刻,使用提取出来的人体骨架N(0)对历史骨架进行初始化,即H(0)=N(0)。
设t时刻(t>0)提取出来的人体骨架N(t)有J个,用N(t)j表示第j个骨架;t时刻对应的历史骨架H(t-1)有I个骨架,用H(t-1)i表示第i个历史骨架;骨架距离矩阵D为J行、I列,其元素dji表示t时刻提取的第j个骨架到其第i个历史骨架的距离;定义两个骨架的距离为d。
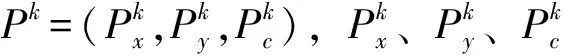
首先,计算两个骨架间相同关键点的欧式距离,若相同关键点的距离超过设定的最小距离阈值dth或相同关键点的置信度有一者小于设定的最小置信度阈值cth,则两个骨架间的距离增加1,即
(1)
式中:E(·)为求相同关键点的欧式距离;I(·)为条件判断函数,当括号中的条件满足时,I(·)=1,否则I(·)=0。因此,当两个骨架中相同关键点的距离越大,或两个骨架的置信度越小时,两骨架间的距离d(P1,P2)会越大,符合实际应用场景。
然后,采用以上骨架距离的计算方法,构建骨架距离矩阵D,其元素dji=d(N(t)j,H(t-1)i)。
3.2 骨架距离矩阵的滤波
由于距离矩阵D并没有考虑行人进入及离开监控范围的情况,因此需要对D进行滤波。
滤波规则如下:首先定义两个集合C、R,其中C表示历史骨架中离开监控范围的骨架,R表示新进入监控范围内的骨架;然后剔除D中整一行距离都大于距离阈值dmax的行,以及整一列距离都大于阈值dmax的列,并将被剔除的行号和列号分别加入到集合R、C中。
D中大于阈值dmax的行表示新提取骨架N(t)中与所有历史骨架距离都较大的骨架H(t-1),这些行可以代表新进入监控的骨架,在H(t-1)中找不到与其匹配的骨架,因此需要将其剔除,并加入到R中,待匹配完成后再进行操作。
D中大于阈值dmax的列表示历史骨架H(t-1)中与所有新提取骨架N(t)距离都较大的骨架,这些列可以表示历史骨架中离开监控范围的骨架,在N(t)中找不到与其匹配的骨架,因此需要将其剔除,并加入到C中,待匹配完成后再进行操作。
设距离矩阵D经过滤波后的矩阵为D′(其行、列数分别为J′和I′),即为后续用于匈牙利匹配的代价矩阵。
3.3 基于匈牙利算法的乘客ID号分配
匈牙利算法是一种在多项式时间内求解任务分配问题的组合优化算法,是二分图匹配中最常用的算法,算法的核心是寻找增广路径。匈牙利算法的基本理论如下:将代价矩阵的一行或者一列数据加上或者减去一个数,其最优任务分配求解问题不变,其中的代价矩阵使用滤波之后的骨架距离矩阵D′。乘客跟踪过程如下:
(1)使用匈牙利算法对矩阵D′进行求解,用匹配成功的新提取的人体骨架更新其配对的历史骨架,并根据文献[26]中的置信度规则增加匹配成功骨架的置信度。
(2)将匈牙利匹配中未匹配成功的骨架在距离矩阵D中对应的列号添加到集合C中,这样C中的元素代表历史轨迹骨架中离开监控范围的行人骨架,并根据文献[26]中的置信度规则减小这些骨架的置信度,在置信度减小至0以下时将该骨架从历史骨架集合C中剔除;若置信度仍大于0,则保留该骨架信息。
(3)将匈牙利匹配中未匹配成功的骨架在距离矩阵D中对应的行号添加到集合R中,这样R中的元素代表新进入监控范围内的行人骨架,因此需要把R中元素对应的骨架,作为新的骨架添加到历史骨架序列H(t-1)中。
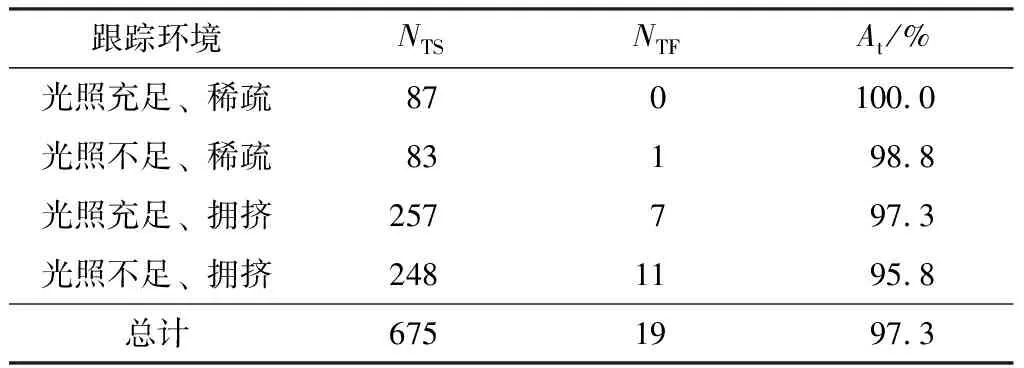
图7为匈牙利匹配示意图。对于后续的时刻,不断执行以上的骨架矩阵计算以及匈牙利匹配,即可实现乘客跟踪。图8为乘客跟踪实际效果图,用点序列代表乘客中心的轨迹。
4 基于GCN的乘客异常行为识别
本文异常行为识别算法的主要应用场景是地铁站、百货商场、办公楼等公共场所,通过对乘客的人体关键点坐标及置信度进行图卷积建模来实现乘客行为识别。
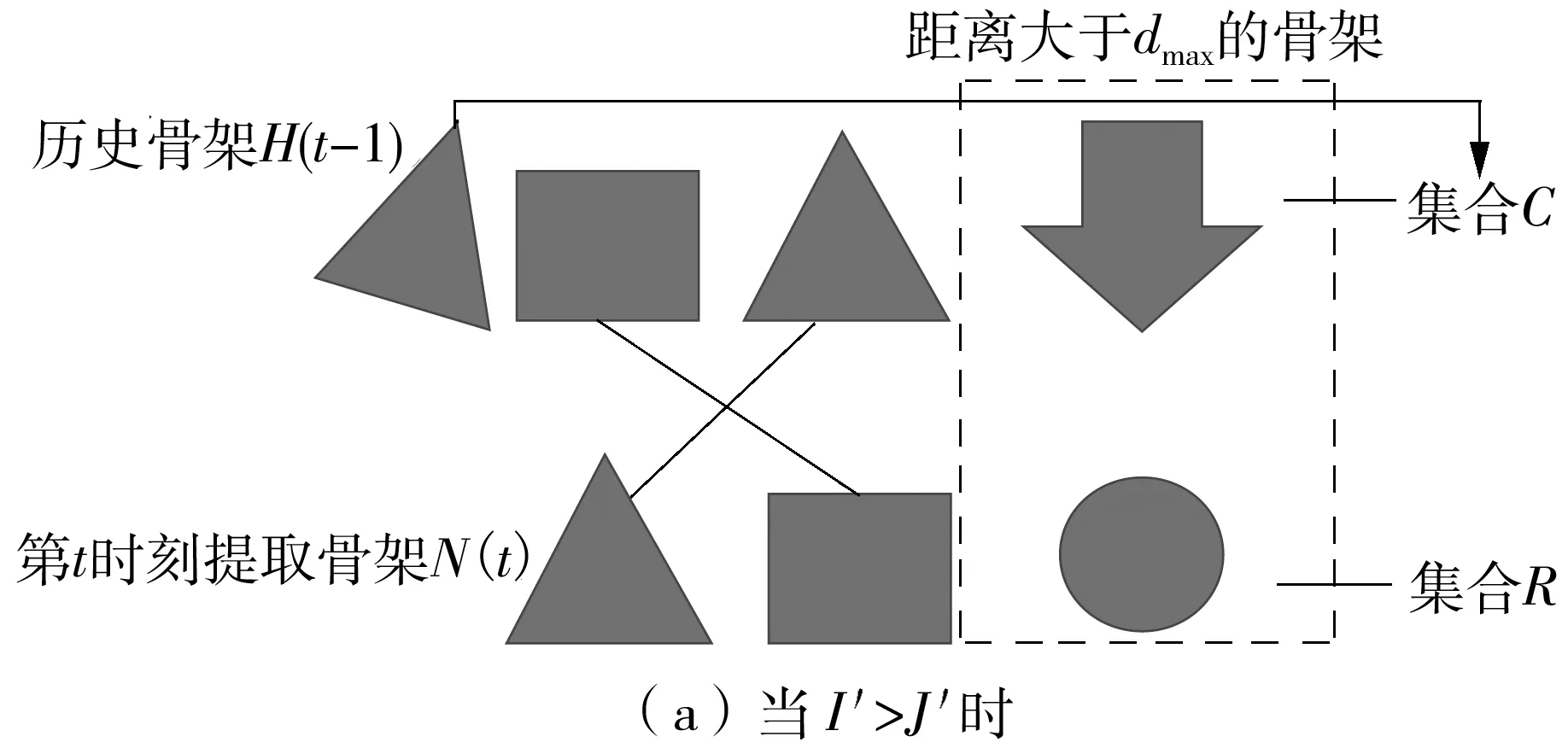
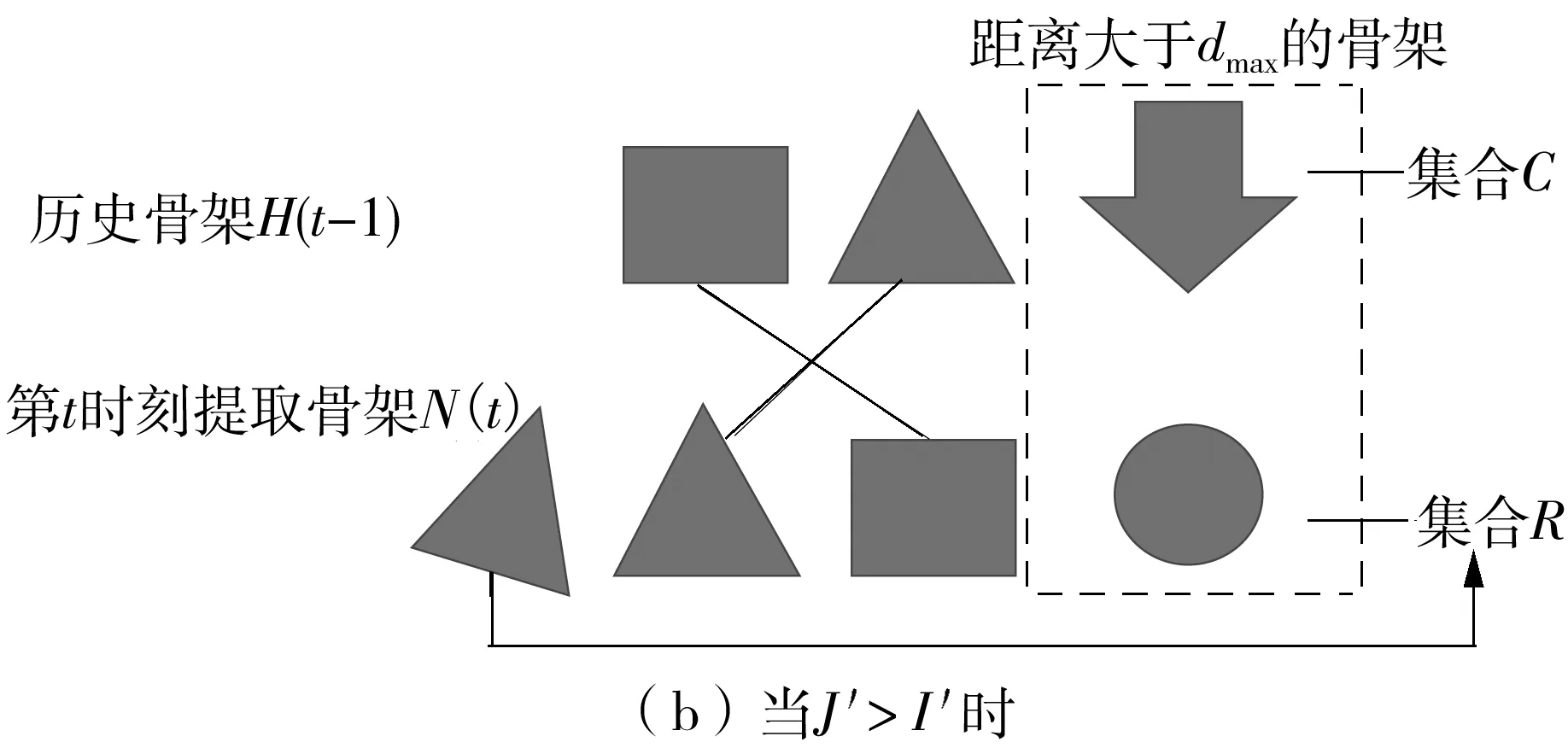
图7 匈牙利匹配算法示意图Fig.7 Schematic diagram of Hungarian assignment algorithm

图8 乘客跟踪结果及轨迹Fig.8 Results of passenger tracking and trajectories
4.1 传统卷积与图卷积
对一般欧式空间上的标准二维卷积操作,给定卷积核大小为K×K,输入特征图为fin,输入通道数为c,则输出特征图的每个通道上,位置x的输出值fout(x)可以表示为
(2)
式中:s:Z2×Z2→Z2为采样函数,枚举了所有在位置x的邻域;权重函数w:Z2→Rc将偏移量(h,w)映射到一个用于计算内积的c维向量。
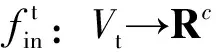
(3)
式中:Zi(vj)=|{vk|li(vk)=li(vj)}|,用于均衡不同部分邻域节点的权重;
li(vj)={
0,rj=ri
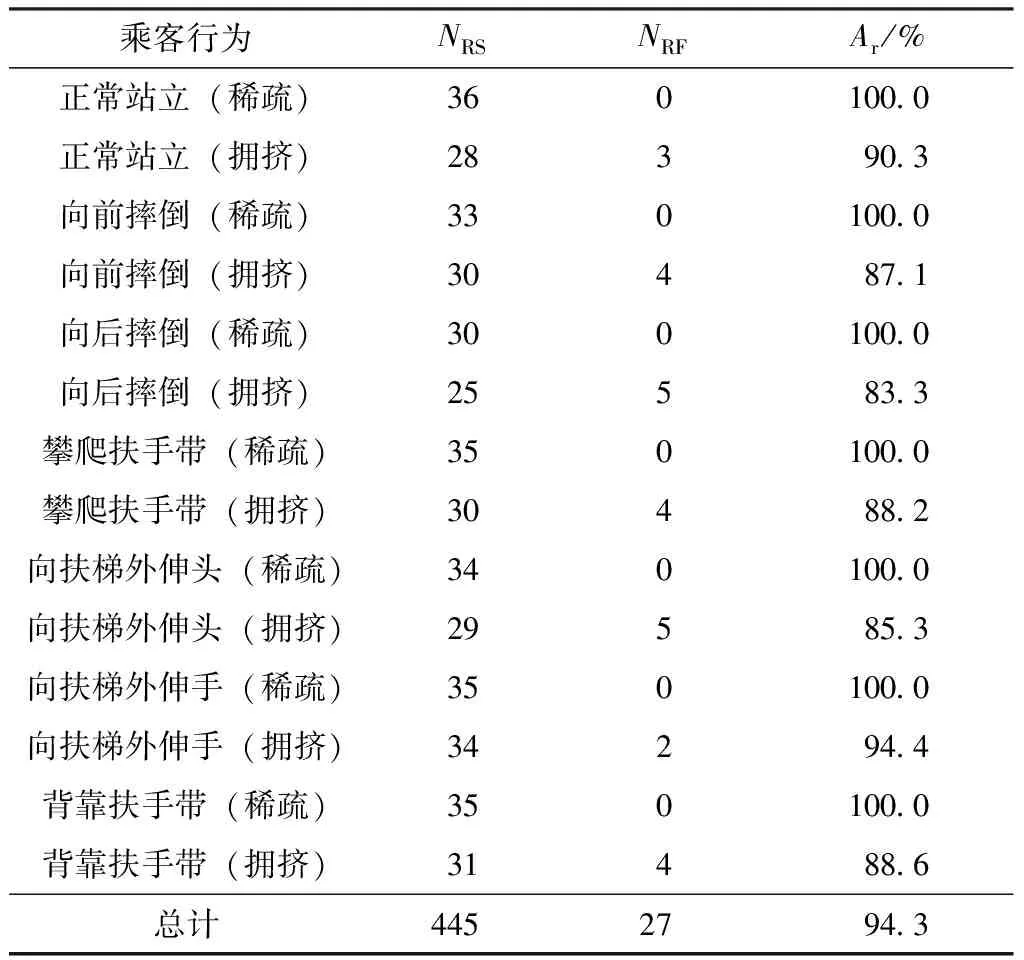
1,rj 2,rj>ri (4) ri为节点i到人体重心的距离。 上述的图卷积采样过程如图9所示。 图9 图卷积采样示意图Fig.9 Schematic diagram of graph convolution sampling 基于上述图卷积操作,可构建用于乘客行为识别的图卷积神经网络,其结构如图10所示,其中cn(n∈Z)表示通道数为n。 图10 行为识别神经网络的结构Fig.10 Structure of behavior recognition neural network 首先,将14个关键点的坐标及置信度通过人体骨骼连接成3通道的图作为输入骨架,输入骨架在经过3次图卷积及Relu激活函数后,提取得到128个通道的深度图特征;然后对每个通道进行全局平均池化,再通过1×1卷积将通道数降为7;最后通过Softmax层回归7种乘客行为发生的概率。 将乘客搭乘扶梯时发生的行为划分为正常站立、向前摔倒、向后摔倒、攀爬扶手带、向扶梯外伸头、向扶梯外伸手、背靠扶手带7类行为,其他行为可以归为上述7类行为之中。 对于t时刻,将检测出来的人体骨架坐标及置信度作为图10的输入骨架图,在经过图10的网络后,选取概率最大的行为作为输出,设t时刻第k个人的骨架在经过行为识别神经网络后决策出来的行为为Bt(k)。在实际应用中,由于存在光照、遮挡等干扰因素,个别帧骨架的提取会存在噪声,导致行为分类错误,因此如果将Bt(k)作为最终决策的行为进行输出,识别率会大大降低。由于乘客在扶梯上的行为往往会持续一段时间(十余帧至百余帧不等,这段时间内第k个乘客的行为决策结果B(k)中绝大部分为同一行为,但有噪声),因此本文使用滑动窗投票的方法,对每个乘客多帧的行为分类结果B(k)进行投票统计后,得到该乘客最终的行为决策结果,这样可以有效地减少由骨架噪声引起的分类错误。 预先设定滑动窗长度为T,对于序列长度|B(k)|≥T的所有乘客k,其行为决策如下:取其最近T次(即(t-T,t]区间)的行为进行投票分析,设7种行为的票数为d1-d7,d1+d2+…+d7=T,如果最大票数大于设定阈值Tth(Tth (5) 滑动窗投票方法通过略微牺牲检测时间来大大提高实际应用中行为的分类准确性,起到了低通滤波器的效果,可以滤除由个别帧中行为识别错误造成的高频噪声。当T=10、Tth=5时取得最优效果。乘客行为识别的部分结果如图11所示。 图11 乘客行为识别部分结果Fig.11 Partial results of passenger behavior recognition 本文使用的数据来源于真实地铁数据集和志愿者模拟的异常行为数据集。其中真实地铁视频数据均为乘客正常搭乘扶梯场景,视频数量较多,截取部分视频帧用于行人检测模型的迁移学习。而异常行为由志愿者在不同场景(隔空层、半户外)的扶梯上进行模拟。受摄像头拍摄角度及视角的影响,扶梯监控图像中较为完整的乘客最多人数为5。本文算法对遮挡严重的极端情况并不适用,如在人数过多的情况中,后面乘客被大面积遮挡,以及在2人场景中,前面的人比较大,完全遮挡住后面人等。这些情况将导致被遮挡的乘客漏检测或者关键点提取结果大部分缺失(前面没被遮挡的人影响不大)。因此,本文在志愿者模拟时,只考虑稀疏场景以及拥挤场景下遮挡情况不严重的情况。本文实验志愿者模拟的视频包括不同环境下的7类行为:正常站立、向前摔倒、向后摔倒、攀爬扶手带、向扶梯外伸头、向扶梯外伸手、背靠扶手带,环境变量为光照强度、乘客密集程度,如图12所示。对于异常行为数据集,首先将视频进行分段,共1 613段,每段涵盖了不同环境乘客行为发生的完整过程,长度为20~30 s不等;然后将短视频依据行为、环境变量,按约3∶1的比例划分为训练集和验证集,随后分别从中抽取关键行为帧作为图卷积神经网络的训练集和验证集,这样先划分视频数据集再截取图像的操作相比先截取图像再划分图像数据集,可以避免训练集和验证集中的样本图像来源于同一短视频,以保证训练出来的模型不会对验证集产生过拟合现象。硬件平台为联想工作站,i7-6700 3.4 GHz CPU、NVIDIA GTX 1080 GPU、64GB RAM,操作系统为Ubuntu 16.04,程序编写语言为Python3.6,处理速度达到15 f/s。 图12 部分实验场景Fig.12 Some experimental scenarios 由于使用自上而下的关键点提取方法,因此乘客骨架提取分为乘客检测及单人关键点提取两部分。 5.1.1 乘客检测实验及结果分析 乘客检测算法YOLOv3在COCO数据集预训练好的基础上进行扶梯行人数据集上的微调,其中扶梯行人数据集包括6 384幅训练图像、1 596幅验证图像,将图像归一化到608×608。将训练样本随机抽取进行7 980次迭代,每次迭代样本数为8,使用Adam优化器,学习率为10-4。在验证时,若检测框与真实标记框的IOU(交并比)大于0.5,则认为检测成功。置信度阈值和非极大值抑制阈值分别取为0.8、0.4。采用文献[27]中的精确率、召回率、调和均值F1(F1分数)作为乘客检测的性能指标。模型在验证集上的检测结果见表1。 表1 YOLOv3算法的乘客检测结果 表1表明,在不同光照环境、不同拥挤程度的条件下,YOLOv3算法都能对乘客进行准确稳定的检测,总F1达到97.5%。YOLOv3算法在各种场景下的检测精确率都达到97%以上,说明算法在各种场景下出现误检的情况较少。随着环境的不同,召回率有较大的变化,这说明YOLOv3的召回率受光照和拥挤程度的影响较大,其中光照不足环境下的召回率比光照充足环境下的下降了1.4%~1.6%,拥挤环境下的召回率比稀疏环境下的下降了0.6%~0.8%。究其原因,光照不足会导致图像亮度下降,从而导致模型辨识率下降,产生漏检;而拥挤环境下会发生遮挡,非极大值抑制会将被遮挡严重的乘客检测框滤除,从而产生漏检。环境较为恶劣(光照不足且拥挤)时,F1分数也在96%以上,说明算法在不同环境下具有鲁棒性,这为后续关键点精准提取提供了必要的条件。 5.1.2 单人关键点提取结果及分析 由于直接对检测框切割出来的行人进行关键点提取,会使得切割出来的行人不够完整,同时切割出来的图像中全局信息也会过少。此外,由于离摄像头的距离不同,检测框的大小也不同,因此在关键点提取网络的训练及推理前,需要对行人检测结果进行预处理和归一化。首先,将检测框向外扩张1.2倍,并以固定长宽比4∶3裁剪出行人,以保证图像不会发生较大的扭曲形变;然后将裁剪出来的行人缩放到固定尺寸,高度为384,宽度为288。 MobileNetv2关键点提取网络使用COCO2017数据集进行训练(包括了15万个标注行人)。迭代epoch数为400,每次迭代样本数为16,使用Adam优化器,初始学习率为5×10-4,学习率衰减系数为0.5,每隔60个epoch衰减一次学习率,使用L2正则化,正则化系数为10-5,使用均方误差(MSE)回归损失函数。 为了衡量关键点提取模型在扶梯场景下的推理效果,对扶梯场景各种环境下的乘客关键点进行手动标注,其中每种场景标注70幅图像。使用文献[28]的物体关键点相似度(OKS)中的AP50、AR50作为乘客关键点提取指标,结果如表2所示。 表2 乘客单人关键点提取结果Table 2 Single passenger key point extraction results 表2表明,MobileNetv2结合反卷积层的方法能够在不同环境下对提取乘客关键点有较好的效果,总F1分数达到91.6%。各种场景下的关键点提取精确率都达到92%以上,说明该方法在各种场景下出现定位不准的情况较少。召回率受光照和拥挤程度的影响较大,其中光照不足环境下的召回率比光照充足环境下的下降了1.5%~7.1%,拥挤环境下的召回率比稀疏环境下的下降了2.9%~8.5%。究其原因,主要有:①行人检测模型的影响,由于采用自上而下的关键点提取方法,因此检测模型的漏检会导致骨架漏检,光照不足及拥挤环境都会导致YOLOv3漏检率上升,从而导致关键点提取召回率下降;②恶劣环境对关键点提取模型本身产生一定的影响,光照恶劣及遮挡也会导致召回率的下降;③训练集和验证集的不匹配,由于关键点是在COCO数据集上训练的,而验证环境是在手动标注的电梯验证集上,因此训练集的环境背景、摄像头的拍摄角度、人工标注的误差分布等都和验证集不一致,从而导致召回率下降。在环境较为恶劣的情况下,F1分数也在88%以上,说明单人关键点提取方法能够在扶梯场景的不同环境下具有稳定性。 从乘客进入监控范围开始进行乘客跟踪,在乘客发生异常行为或者离开监控范围时停止乘客跟踪,假设乘客在这段时间连续出现的帧数为Np(Np>T,T为滑动窗长度)。首先做如下定义:对于某个长度为T的滑动窗,若乘客的标号都为同一ID,则这个滑动窗口跟踪成功;对于该乘客的所有Np-T+1个滑动窗口,如果有超过95%的滑动窗口跟踪成功,则该乘客跟踪成功(并计跟踪成功的乘客数为NTS),否则该乘客跟踪失败(并计跟踪失败的乘客数为NTF)。由此可以得到跟踪精度At=NTS/(NTS+NTF)。表3为乘客跟踪结果。 表3 乘客跟踪结果Table 3 Results of passenger tracking 从表3可知,使用骨架距离作为衡量标准以及采用匈牙利算法进行跟踪匹配,可以提高不同环境下对乘客的跟踪精度,总跟踪精度达到97.3%。进一步分析,在拥挤和光照不足的环境下,跟踪精度会降低。究其原因,拥挤情况下会发生乘客遮挡,导致部分图像的乘客骨架提取失败,进而导致跟踪精度降低;而光照不足会使图像清晰度下降,导致乘客检测以及关键点提取模型的召回率降低,从而导致跟踪精度降低。对比表2和表3发现,在骨架提取不精准的时候,跟踪精度也会很高,其原因可能是本文骨架距离的计算方法引入了相邻视频帧的先验乘客距离知识(即相同乘客在相邻帧的距离近,而不同乘客在相邻帧的距离远),从而有效地改善了跟踪过程因骨架提取精度不足引起的问题。即使是在光照不足和乘客拥挤的情况下,乘客跟踪精度也能保持在95%以上,这为乘客行为准确识别提供了必要条件。 本文采用图卷积神经网络对乘客行为进行分类。训练数据集包括5 150个骨架,验证集为1 966个骨架。将训练样本随机抽取进行20 000次迭代,每次迭代样本数为2 000,使用Adam优化器,学习率为10-3,正则化系数为10-3,使用交叉熵损失函数。最终的图卷积模型在训练集上的分类准确率为99.3%,在验证集上的分类准确率为92.2%。 在445个短视频验证集上验证本文的乘客行为识别算法,设乘客行为发生的时刻为第t帧,若在[t,t+T)帧内行为能被及时正确识别,则行为识别成功,否则行为识别失败。将被正确识别的短视频数记为NRS,识别错误的短视频数记为NRF,则识别准确率Ar=NRS/(NRS+NRF)。表4给出了乘客行为的识别结果,表5为乘客行为识别的混淆矩阵。 表4 乘客行为识别结果Table 4 Results of passenger behavior recognition 表5 乘客行为识别的混淆矩阵Table 5 Confusion matrix of passenger behavior recognition 从表4可知,在稀疏场景下乘客行为识别准确率达100%,而拥挤情况下识别精度降低。结合图11可知:在稀疏场景下,乘客骨架提取结果较为完整,不确定性较低,故此时训练集和验证集的骨架分布相似度较高且贴近真实稀疏场景的骨架提取情况,识别准确率高;在拥挤场景下,由于乘客互相遮挡,遮挡部位的不同及遮挡面积的不同,使不确定性提高,且样本的数量级别远远没有达到不确定性的数目,此时训练集和验证集的骨架分布并没有多到可以很好地拟合出真实拥挤情况的分布,故训练集和验证集的相似度较低,GCN在训练集上的拟合效果好,而在验证集上的识别准确率降低。 由表5可得,某些行为之间,如向扶手带外伸手与向扶手带外伸头、攀爬扶手带与背靠扶手带之间会产生误判,这是因为拥挤情况下部分遮挡导致关键点提取不完全,从而致使这些行为骨架在经过GCN提取后的高维行为特征发生了较大的空间位移,最终映射得到的分类结果也偏移到了错误类别中,导致识别结果错误。尽管如此,本文异常行为识别算法的最终识别准确率高达94.3%,GCN在验证集骨架中的分类准确率为92.2%,这说明通过图卷积的分类结果进行滑动窗投票统计后,可以在稍微牺牲算法响应的同时,降低噪声干扰,提高行为识别分类准确率。通过以上分析可知,本文算法对扶梯乘客的异常行为有良好的识别效果,对采集的手扶电梯监控视频具有较强的检测稳定性。 需要指出的是,乘客行为中一些与扶手带互动的行为,如向扶梯外伸头、向扶梯外伸手、背靠扶手带,虽然在本文中可以通过图卷积神经网络提取到的高级行为特征来得到较为准确的识别结果,但这仅说明本文算法能够较好地提取出能区分这些动作之间的特征,并没有考虑动作发生的位置,因此在实际应用中,为了得到与扶手带的行为交互结果,需要结合算法分类结果与已知的扶手带的位置做进一步判断。本文在进行性能分析时,假定乘客与扶手带的相对位置已经事先正确得到,故仅对乘客的行为分类结果进行分析。 在相同短视频数据集上,使用多分类支持向量机[29]、正态贝叶斯分类器[30]、光流法[31]、动态粒子流场[32]、行为序列匹配[16]和本文算法对乘客行为进行分类,结果如表6所示。从表中可知,与其他5种算法相比,本文提出的基于视频监控的行为识别算法在处理速度上更快且识别准确率更高。这是因为本文算法使用的GCN层数较浅,模型较为简单,且使用了GPU进行图卷积前向推理,因此处理速度比较快;同时,由于GCN使用人体关键点及其连接作为图输入,能够更好地对乘客动作进行描述,因此行为识别率较高;另外,滑动窗投票统计的方法也进一步提高了识别准确率。 表6 几种行为识别算法的性能比较 由于本文使用了文献[16]的骨架提取-行人跟踪-行为分析架构,因此将本文算法与文献[16]算法进行比较分析。相比文献[16]算法,本文算法有以下优点:①本文算法使用了自上而下的骨架提取方法,可以避免文献[16]中乘客骨架容易产生分配错误的问题,而且本文的骨架提取方法具有人数越少、处理速度越快的优势;②本文采用匈牙利匹配算法对相邻帧乘客进行匹配,避免了文献[16]中最小距离匹配会因运动偏移而导致的匹配错误问题;③本文使用骨架距离作为乘客相似度的衡量标准,骨架提取效果比文献[16]的人脸检测抗遮挡能力好,而且可以减少人脸检测算法额外的计算开销;④本文使用浅层GCN结合滑动窗投票的方法对乘客异常行为进行识别,相比文献[16]使用余弦相似度特征进行模版匹配,GCN通过学习可以得到更有利于动作识别的深度姿态特征,提高动作识别准确率。 为了解决现有方法在扶梯场景下不能实时准确识别乘客异常行为的问题,本文提出了一种基于视频监控的手扶电梯乘客异常行为识别算法。首先,采用YOLOv3检测图像中乘客的位置,并使用MobileNetv2结合反卷积的方法来提取乘客骨架;接着,使用以骨架距离为基准的匈牙利匹配算法对乘客进行跟踪;然后,使用GCN和滑动窗投票统计的方法对乘客的异常行为进行识别。实验结果表明,本文算法的处理速度达15 f/s,异常行为识别准确率为94.3%,可以快速、准确、稳定地处理扶梯监控视频。然而,本文算法依然有很大的限制,在拥挤场景下,扶梯乘客会发生严重的遮挡,骨架会发生部分缺失,从而导致缺失的骨架在输入图卷积网络后得到错误的行为识别结果,今后将针对多人场景下的部分遮挡问题(完全遮挡无解)增加训练样本和数据的多样性,以提高异常行为识别算法的性能。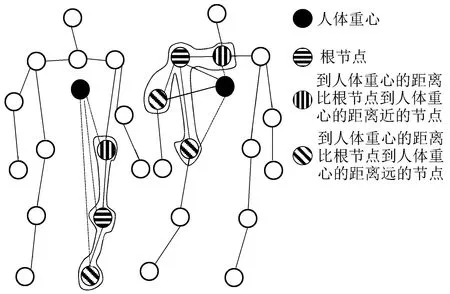
4.2 图卷积神经网络结构
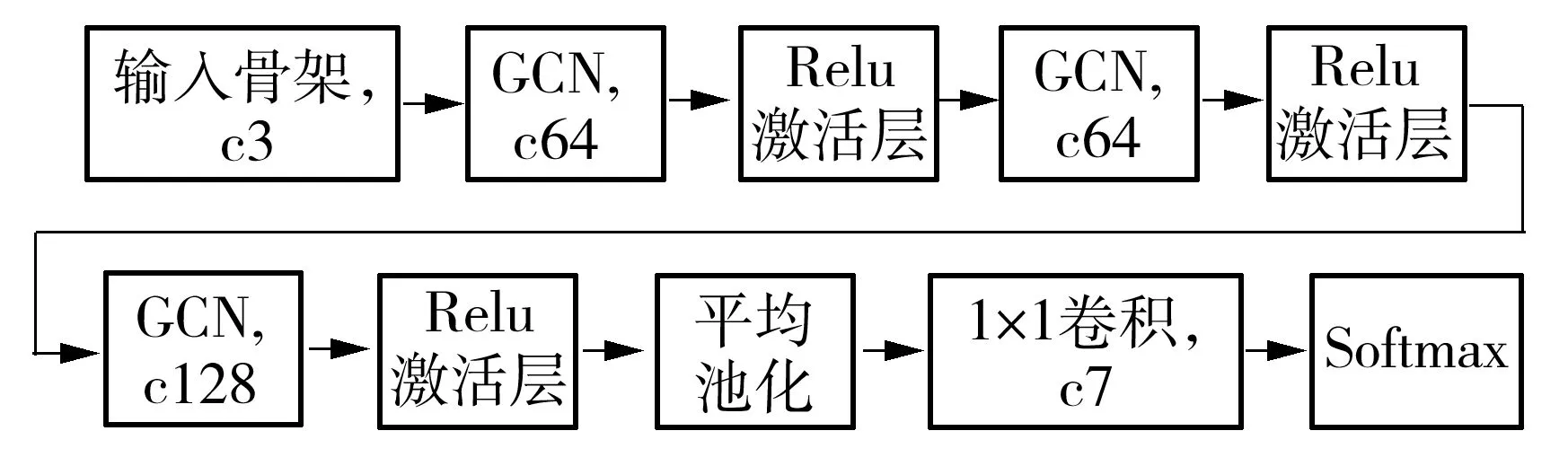
4.3 乘客异常行为识别
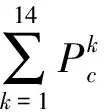

5 实验和结果分析

5.1 乘客骨架提取实验及结果分析
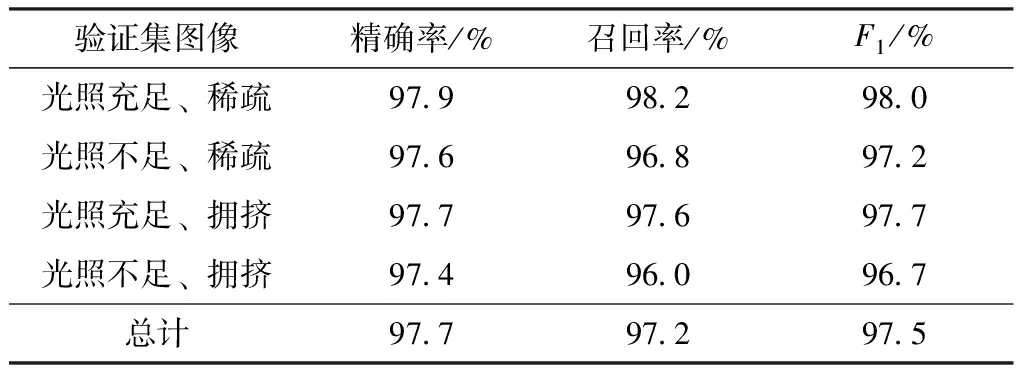
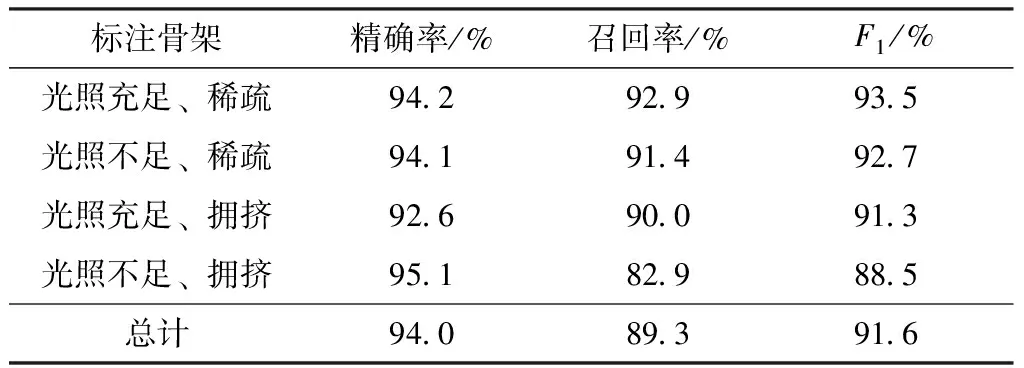
5.2 乘客跟踪结果及分析
5.3 乘客行为识别结果及分析

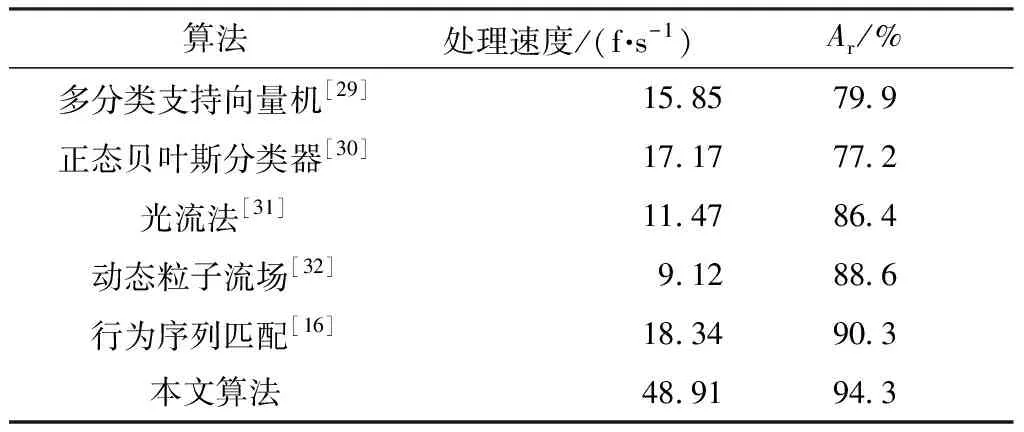
6 结语
猜你喜欢
电子技术与软件工程(2022年15期)2022-11-11小型微型计算机系统(2022年4期)2022-05-09建材发展导向(2022年3期)2022-04-19思维与智慧·上半月(2022年4期)2022-04-08今日农业(2021年8期)2021-11-28建材发展导向(2021年11期)2021-07-28小聪仔(幼儿版)(2020年12期)2020-02-01计算机应用(2018年5期)2018-07-25中国科技纵横(2016年20期)2016-12-28好孩子画报(2016年6期)2016-05-14
