
基于SVD填充和用户特征属性聚类的混合推荐算法
2020-09-28 07:05秦灿李旭东
电脑知识与技术 2020年16期
秦灿 李旭东


摘要:面对评分矩阵的数据量不断增加,解决数据稀疏问题并提高推荐准确率是关键,因此,本文提出基于SVD填充和用户特征属性聚类的混合推荐算法。首先利用SVD技术对评分矩阵拆分,并使用随机梯度下降法对空缺值填充;然后对用户特征属性聚类,以此缩小邻居节点的搜索范围;接着利用遗忘曲线思想改进用户的相似度公式,结合Jaccard系数和流行度思想改进项目的相似度公式;再将用户偏好和项目特征的维度加权融合;最后,将本文的SK-HCF算法和其他同类算法进行对比实验,并证明该算法的推荐准确率有明显提升。
关键词:推荐算法;协同过滤;奇异值分解;K均值聚类;遗忘曲线
中图分类号:TP301.6 文献标识码:A
文章编号:1009-3044(2020)16-0011-05
开放科学(资源服务)标识码(OSID):
Abstract: Facing the increasing amount of data in the scoring matrix, it is the key to solve the problem of sparse data and improve the accuracy of recommendation. Therefore, this paper proposes a hybrid recommendation algorithm based on SVD filling and user feature attribute clustering. Firstly, SVD technology is used to split the scoring matrix, and random gradient descent method is used to fill in the vacancy value; then cluster user feature attributes to narrow the search range of neighbor nodes; then use the forgetting curve idea to improve the user's similarity formula. Combine the Jaccard coefficient and popularity ideas to improve the similarity formula of the project; Afterwards the dimension of user preference and project characteristics is weighted; finally, compare the SK-HCF algorithm of this paper with other similar algorithms and prove that the recommendation of the algorithm is accurate The rate has improved significantly.
Key words: Recommendation algorithm; collaborative filtering; singular value decomposition; K-means clustering; Forgetting curve
1引言
近年來,随着互联网的信息量不断的增多,用户很难获取有价值的信息,学者们便推出了搜索引擎技术[1],但是,当用户需求不明确时,该技术将不能满足用户的需求。1992年高柏等人提出了名叫Tapestry的协同过滤推荐模型[2],并使用其推送新闻和筛选信息。推荐算法的原理是通过分析用户属性或项目属性的相似程度,为目标用户推荐,其可以解决信息过载问题[3],能极大地提高了用户体验。
数据稀疏是协同过滤算法的准确度降低的重要原因之一[4],因此学者们提出了矩阵填充[5]、降维[6]、聚类[7]等方法,以便提升推荐的准确度。
本文设计出基于SVD填充和用户特征属性聚类的混合推荐算法。首先采用SVD技术对评分矩阵进行分解,并利用随机梯度下降法对评分矩阵的空缺值进行填充;然后对用户的特征属性聚类,使邻居的搜索范围缩小;再利用遗忘函数作为时间权重改进用户的相似度公式,并结合Jaccard系数和流行度权重改进项目的相似度公式;最后以一定的权重结合基于用户和基于项目的维度,对未评分项做出预测评分,并按照相似度大小排序重新生成推荐列表。
2 相关工作
2.1 传统的协同过滤推荐算法
传统的协同过滤推荐算法包含基于用户的协同过滤算法[8-9]和基于项目的协同过滤算法[10],通过收集信息、相似度计算、生成推荐集合等步骤来预测评分[11]。
2.1.1基于用户的协同过滤推荐算法
User-CF算法是通过比较用户之间的相似程度来推测用户可能喜欢的项目集合[8]。最常见的计算方法是Pearson相关系数[12]。具体公式如下:
通过随机梯度下降法算法[14]把[SSE]的值训练到最小,最终目标使预测评分值无限靠近真实评分值。该算法是通过[x]点沿其负梯度方向搜索,计算[SSE]局部最优值,即当前的极小值,再更新预测值[Puv],如此反复,经过数次迭代,最后得到[SSE]的最小值,进而得到全局最优的[Puv]。
2.3 K-means聚类算法
由于传统的协同过滤算法缺少对用户类别的维度的计算,导致准确度提升困难,故采用K-means算法[15]对用户的特征属性进行聚类。具体过程如下:
(1)处理原始数据,创建用户特征属性集合。定义[u]为用户的特征属性的集合,设[u={a,s,o,p}],[a]表示年龄,[s]表示性别,[o]表示职业,[p]表示所在地,其中,年龄定义为数值型数据,性别转化为二元数据,即女为0,男为1,职业和所在地等信息定义为标称型数据,以一定形式进行编码,如省份可表示为“江苏=32,湖北=42”。如[u={50,1,20,32)]表示该用户是来自江苏50岁的男教师。
4.3实验数据分析
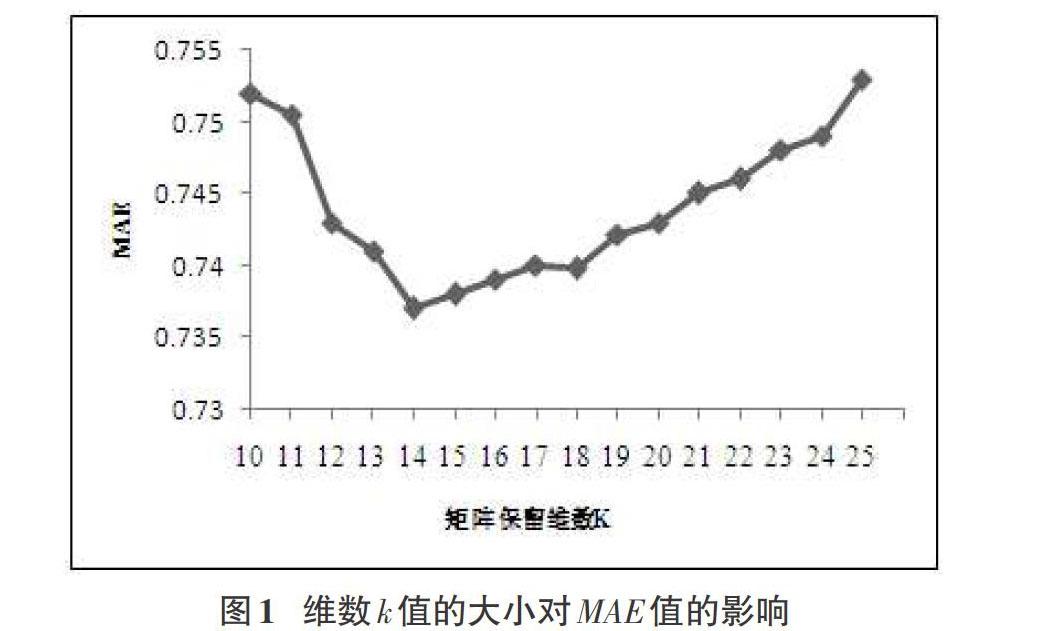
4.3.1 矩阵保留维数[k]值的分析
利用SVD技术对评分矩阵进行拆分并降维,并使用随机梯度下降法对其的空缺值进行填充。经降维处理后的矩阵维数[k]值对SK-HCF的算法精确度影响较大,如果[k]值过小,会损失部分评分数据;如果[k]值过大,可能失去降维的作用。一般[k]值的区间为[[10,25]],同时设置邻居数量为20。
观察图1的折线趋势可以发现,当[k]值取[[10,14]]时,[MAE]值出现下降的趋势,当[k]值取[[14,25]]时,[MAE]值出现逐渐上升的趋势,即当[k=14]时,[MAE]取最小值,推荐的精确度最高。
4.3.2聚类个数[c]值的分析
SK-HCF推荐的效果,不仅取决于矩阵维数[k]值的大小,也取决于聚类个数[c]的大小,因此,需要研究聚类个数对精确度的影响。首先设置[k=14],并设置邻居数量为20,然后令[c=5],每次增加5直到[c=40]并依次得出其分别对应的[MAE]值,以此探究聚类数对推荐准确度的影响情况。
从图2中可以看出,[X]轴表示聚类个数[c]值的大小,[Y]轴表示均方差[MAE]值大小。当[c]在区间[[5,25]]变化时,均方差[MAE]值呈下降趋势,当[c]在区间[[25,40]]变化时,均方差[MAE]值呈上升趋势,则当[c=25]时,为全局最优点,即得出的均方差[MAE]的值最低,推荐推荐精度最高。
4.3.3权重[a]值的分析
为使综合相似度[sim(x,y)]的计算准确性达到最优,需要确定公式(15)中的加权系数[α]的最优值,以使推荐的精确度最高。首先设置邻居数量为20,令[k=14],[c=25],然后令[α]的值从[0.1]开始每次增加[0.1],直到[α=0.9],并分别计算出对应的[MAE]值,以此确定权重[α]的最优值,如图3所示。
在图3中,[X]轴表示权重[α]的不同取值,[Y]轴表示各取值[α]分别对应的[MAE]值。根据观察可以得出,当[α=0.5]时,[MAE]的值最小,当赋予基于用户的维度和基于项目的维度各占50%的权重时,该推荐算法的精确度最高。
4.3.4预测评分的精确度测试
为了验证本文算法SK-HCF的性能,分别将User-CF、Item-CF、KM-CF、SVD-CF和本文提出的SK-HCF等5种算法在数据集Movielens上进行对比测试,同时设置邻居数目的区间为[[5,30]],间隔为5,并采用[MAE]值大小来衡量推荐的精确度,其值越小则说明精度越高。为了SK-HCF算法获得最大性能,这里设置算法的SK-HCF的各参数的值:[k=14],[c=25],[α=0.5]。
图4表示各算法在Movielens数据集上的[MAE]值对比结果。观察该图表即可发现:当邻居数增加,所有算法的[MAE]值出现减少的趋势。KM-CF算法相对于User-CF、Item-CF和SVD-CF,精确度有一定的提升;本文提出的SK-HCF算法,相对于图中的另外4个算法,精确度有明显提升。可以看出,用户的邻居数从5递增到30,[MAE]值先减后增,其中,当邻居数目为20时,[MAE]取最小值,预测的精确度最高。总之,本文算法SK-HCF和上述其他4种算法相比较,表现出有较高的精确度。
4.3.5准确率和召回率的测试
为了进一步验证SK-HCF算法的有效性,这里继续测试该算法TopN推荐效果,测试数据还是选择数据集Movielens。即测试User-CF、Item-CF、KM-CF、SVD-CF和本文提出的SK-HCF等5种算法的准确度和召回率。设置算法的SK-HCF的各参数的值:[k=14],[c=25],[α=0.5],同时设置邻居节点为30。
通过观察图5可以发现,User-CF和Item-CF算法表现出的准确率和召回率差距不明显,KM-CF和SVD-CF算法相对于传统的User-CF和Item-CF算法的推荐效果有一定的提升,而本文算法SK-HCF相对于图中的其他4种算法的准确率和召回率有明显的提升。
经过以上一系列的实验证明,本文提出的SK-HCF算法的推荐效果明显提升。
5结束语
SK-HCF算法能有效提高推荐的准确率。SK-HCF算法先利用SVD技术对评分矩阵拆分、降维,并使用随机梯度下降法对空缺值填充,对稀疏问题有一定的改善;然后通过聚类法把用户划分为不同的类别,能有效减少搜索范围;最后对用户和项目的计算维度进行加权融合,并结合兴趣遗忘的原理、Jaccard系数规则和流行项目的抑制规则等方法改良了相似度计算公式,提高了相似度的计算精度。通过一系列的实验表明,SK-HCF算法有效地提高推荐的精度和效果。然而,对于推荐系统而言,仅提高推荐的准确度还不够,下一步的研究将考虑结合人工智能和大数据技术,来提升推薦系统的智能性、友好性、实用性。
参考文献:
[1]Information Technology - Data Mining; Recent Research from Sichuan University Highlight Findings in Data Mining (Research on large data intelligent search engine based on multilayer perceptive botnet algorithm)[J]. Computers, Networks & Communications,2019.
猜你喜欢
课程教育研究·新教师教学(2016年1期)2017-04-10
计算机应用(2016年12期)2017-01-13
考试周刊(2016年37期)2016-05-30
