
一种基于SVM 的多类文本二叉树分类算法∗
2020-10-14 11:49宋晓婉黄树成
计算机与数字工程 2020年8期
宋晓婉 黄树成
(江苏科技大学计算机学院 镇江 212003)
1 引言
支持向量机(SVM)[1-2]是一种基于统计学习理论的用于解决两类分类问题的机器学习方法,由VAPNIK 和CORTES 于1995 年提出。支持向量机(SVM)在解决小样本、非线性及高维向量空间中有很好的性能。支持向量机的提出是为了解决两类分类问题,但是实际的应用中,更多的是对多类分类问题的解决,因此,如何运用支持向量机解决多类分类问题是当前支持向量机研究的方向之一。SVM解决多类分类问题的思路主要有以下两种:第一种是一次性求解[3],对多类分类问题通过一个公式求解;第二种是构造多个二值分类器,并根据不同的组合方式来解决不同的多类分类问题。常用的多类分类支持向量机算法有:“一对一”、“一对多”、“有向无环图”和“二叉树”[4]等。根据研究表明,第二种方法总体性能较优,能更好地解决多类分类问题。
“一对一”算法[5]是在两类样本间训练出一个两类分类器使其中一个类为正,另一个类为负。该算法训练速度快,但若某个子分类器存在误差,就会导致整个分类器出现过学习,并且存在随着类别的增加两类分类器的数量急剧上升及不可分区域的缺点。
“一对多”算法[6]是在所有类样本间训练出一个两类分类器使其中一个类样本为正,其余的类样本为负。该算法所需的两类分类器的数量较少,但由于在两类分类器的训练过程中会涉及到全部的类样本,因此分类速度较慢。
“二叉树”算法是每次将最容易分离出来的类首先分离出来,以此类推直到只剩下一个类为止。二叉树多类分类算法的分类速度会受到二叉树结构的影响,完全二叉树的分类速度较高,因此构造完全二叉树结构能大大提高二叉树多类分类算法的分类速度。同时,“二叉树”算法存在误差累计,因此应该先将最容易分离的类分离出来,减少误差的积累。
“有向无环图”算法[7-8]是在“一对一”算法的基础上提出的一种新的学习架构,它将多个“一对一”两类分类器组合成多元分类器。该算法具有冗余性,不同的DAG 结构会造成部分样本的分类路径的不同,从而对分类效果产生影响。
“二叉树”算法在多类分类中有着很好的扩展性,在多类分类算法中综合性能较优。但存在“误差累计”及对二叉树结构依赖的缺点,因此本文主要针对二叉树结构及分类顺序两个方面改进“二叉树”算法。
2 基于二叉树的SVM多类分类算法
2.1 二叉树SVM算法介绍
二叉树SVM 算法[9-10]主要思路:先将所有的类分成两个子类,再将这两个子类分别划分成两个次子类,以此类推,直到所有节点只包含一个类为止。二叉树多类分类算法的分类速度会受到二叉树结构的影响,完全二叉树的分类速度较高,因此构造完全二叉树结构能大大提高二叉树多类分类算法的分类速度。现有的二叉树多类分类算法只是随机的生成二叉树结构,所以,合理的构建二叉树结构是提高二叉树SVM算法分类速度的关键。
二叉树SVM 算法存在“误差累计”的缺点,上层节点的分类结果对整个算法分类性能有着极大的影响,有效的分类顺序是提高二叉树SVM 分类精确度的关键。常用的二叉树生成思路有以下两种:1)根据类中样本的分布情况进行划分,先将类中样本分布范围较广的类分离出来,主要通过计算各类的超球体的体积来衡量类样本分布情况,超球体体积越大,分布范围越广。2)根据两类间的距离进行相似度判断,一般利用欧氏距离来计算两类之间的距离,距离越小,相似度越大,应该最先分离出来。
2.2 相关定义

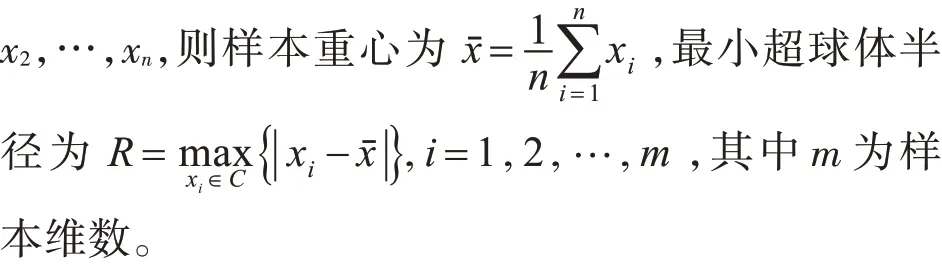
超球体SVM[12~13]主要思想:在非线性系统中,通过映射函数将低维空间的特征向量映射到高维空间进行类的划分。在高维空间中,以尽可能小的超球体半径包含更多的样本,考虑到散落在球面附近的样本,引入松弛变量§m,i,并计算覆盖样本的最小超球体的半径及球心。
定义2:欧氏距离[14]。也称欧几里得距离,主要用于计算两点之间的真实距离,m 维空间中点i和j的距离为
在判别两类之间的分离程度时,可以使用欧氏距离法、超球体SVM 或者两种方法的结合,但都不能准确地反映类的分布情况。单独使用欧氏距离法进行类的相似度的判断没有考虑类中样本的分布情况,单一使用超球体SVM 方法只是考虑类的样本的分布情况却忽略类间的相似度的判断。采用欧氏距离和超球体SVM 方法结合进行类的相似度判断在精确度上有了一定的提升,但是依然存在一定的问题。为了解决这一问题,本文对类内和类间相似方向进行了改进提出了类间相似度量数的概念。同时,提出了一种二叉树结构生成算法,使二叉树在总体上为偏二叉树,在局部为完全二叉树或者近似完全二叉树,从而提高二叉树分类效率及分类精度。
3 改进的二叉树SVM多类分类算法
3.1 相关定义
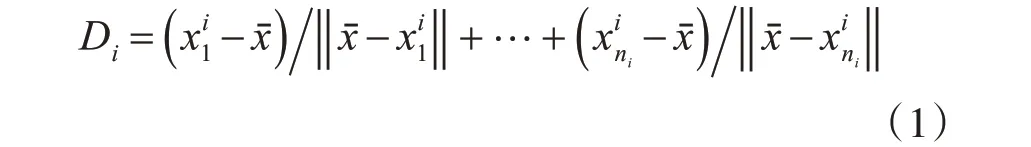
其中,xˉ是根据文献[15]中式(10)、(15)得到的每类样本所在最小超球体的中心。
定义4:类间相似度量数。假设类i 和类j 的最小超球体半径分别为ri和rj,那么类i 和类j 的类间相似度量数为
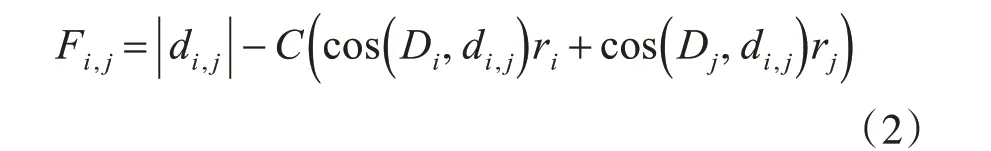
其中,|di,j|为从类i 中心向量到类j 中心向量的欧氏距离,C 为参数值,其值根据样本的分布情况进行调整,默认情况下取值1,Fi,j越大越不相似,应该最先分离出来。
对图1 中的两个图的情况进行观察可以发现:左图的类间距较小,但类之间的分布较远;而右图的类间距较大,但类之间的分布较近。采用距离或类间相似方向来进行两类之间的相似度判断,都不能达到比较好的效果,而采用本文提出的类间相似度量数能在类间距和类的分布情况两种因素上综合考虑,从而获得更有效的分类顺序,提高分类精确度。
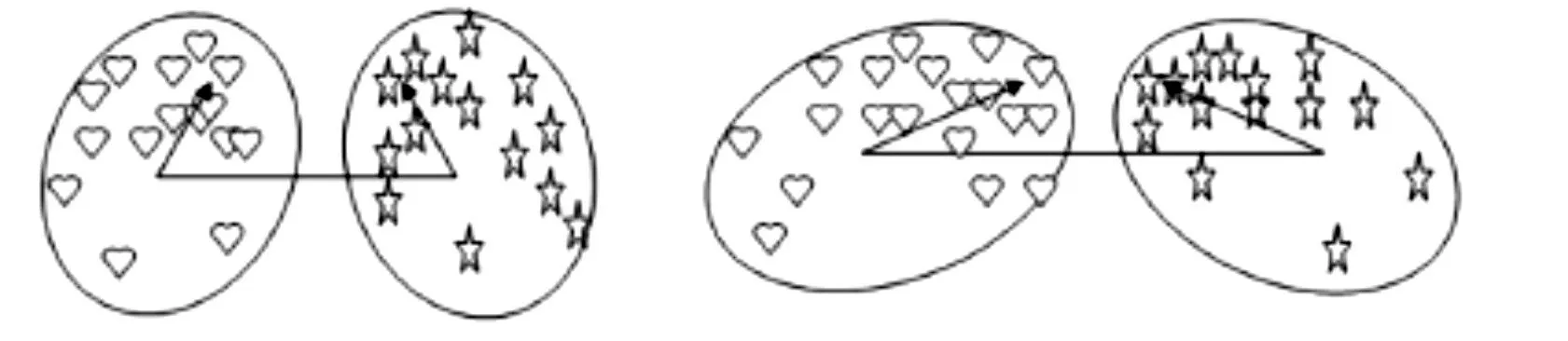
图1 左右两图表示两类间距离及类间相似方向
3.2 算法步骤
定义类平均类间相似度量数:
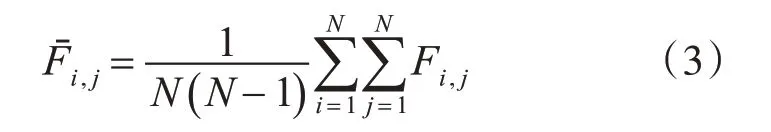
1)对于N 类问题,定义集合G、G1、G2、G3、G4和G5,NG、NG1、NG2、NG3、NG4、NG5(NG、NG1、NG2、NG3、NG4、NG5分别表示集合G、G1、G2、G3、G4和G5中的类编号的个数)。首先对所有类样本从编号1 到编号N 进行编号,并放到集合G 中。然后根据式(1)~(3)计算所有类样本的类间相似度量数Fi,j(i=1,2,…N,j=1,2,…N,i≠j)和Fˉi,j。
2)如若NG=2,那么把类编号较小的类作为左子树,类编号较大的类作为右子树,算法结束。
3)根据式(1)~(2)计算集合G中的每一个类到其他类的Fi,j,并统计每一个类的Fi,j小于 λFˉi,j的个数(λ根据样本分布情况进行值的调整,是一个大于零的参数),记作Sumi(i=1,2,…N)。
4)找出最大的Sumi,如果存在相同的Sumi,则选择类编号较小的类样本。如果Sumi=NG,则将集合G 中的所有类编号放到集合G3中,转5)。否则,将类编号i 放到集合G1中,并将满足Fi,j< λFˉi,j(j=1,2,…N,i ≠j)的类编号放到集合G1中作为二叉树的左子树,将剩下的类编号放到集合G2中作为二叉树的右子树,并将集合G1中的所有类编号放到集合G3中,转5)。
5)若NG3=2,那么把类编号较小的类作为左子树,类编号较大的类作为右子树,算法结束。
6)找出Fi,j值最小的两个类i 和j,并将它们按照类编号的大小放到集合G4中。在剩下的类中找出与集合G4中各类的Fi,j和最大的类标号,并将其放到集合G5中,令G3=G3-(G4∪G5)。若NG3=0 则转8)。
7)计算集合G3中的各类到集合G5的各类的Fi,j和,找出最小Fi,j和的类编号,并将其放到集合G5中,令G3=G3-(G4∪G5)。若NG3=0则转8)。否则,若NG3=1,计算集合G3中的类与集合G4和G5中各类的Fi,j和,将其放到Fi,j和较小的集合,比较NG4和NG5大小,若NG4>NG5,则将集合G4和G5中的类编号进行交换,转8)。否则,计算集合G3中的各类与集合G4中各类的Fi,j和,找出最小Fi,j和的类编号,并将其放到集合G4中,令G3=G3-(G4∪G5)。
8)重复7)。
9)集合G4和G5分别作为二叉树的左右子树,并将左子树进一步划分为两个次子类,令G3=G4,转5)。
10)对右子树划分为两个次子类,令G3=G5,转5)。
11)若NG2=1则算法结束,否则将集合G2中的类编号放到集合G中,转2)。
经过以上实验步骤,可以使更容易分离出来的类首先分离出来,提高分类精确度,同时使生成的二叉树结构根据样本数据分布情况的变化而变化,在总体上是一颗偏二叉树结构,局部是一颗完全或近似完全二叉树结构,具有较高的分类速度。
4 仿真实验
实验采用的数据集包括UCI 数据库中的Glass Identification 和Optdigits,以 及Statlog 数 据 库 中 的Satimage 和Letter,实验数据集信息见表1。算法采用Matlab 和VC++混合编程,并且是在LIBSVM 工具包的基础上进行修改的。实验采用RBF核函数,固定的最优参数(C,r)是经过网格搜索法得到的推广精度最高的C和r参数。为了证明本文所提出的算法具有较好的分类性能,选取一对多SVM(One-versus-rest,OVR)和一对一SVM(One-versus-one,OVO)在四个数据集上进行对比实验,实验结果见表2和表3。
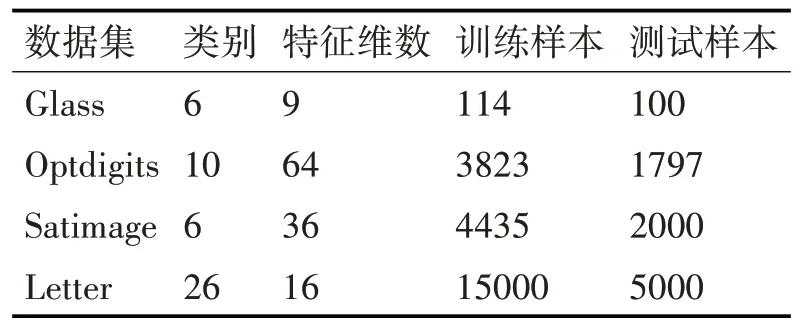
表1 数据集信息表
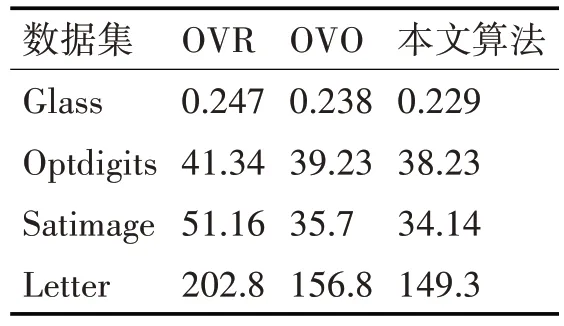
表2 分类速度比较表/s

表3 分类精度比较表/%
通过以上实验得出结论:在相同的测试条件下,不同的分类算法会得到不同的分类结果。由表2 可知,本文算法的分类速度较OVR 和OVO 算法快,原因是:二叉树多类分类算法构造的两类分类器较少,且在训练过程中所涉及的样本数量也逐渐减少。同时,本文算法使生成的二叉树结构总体上是一颗偏二叉树,局部是一颗完全或近似完全二叉树结构,大大减少所需计算的二值分类器数量,进一步提升分类速度。通过表3 可以看出,本文算法在分类精度方面也有了一定的提升,文中提出的类间相似度量数能更准确地将更容易分离出的类分离出来。
5 结语
本文介绍了当前支持向量机解决多类分类问题的一般思路及二叉树SVM 多类分类算法的原理,并分析现有二叉树SVM 存在的问题。并针对存在的问题提出了一种改进的二叉树SVM 多类分类算法,该算法能大大减少“误差累计”,提高分类精度。同时,使生成的二叉树总体上是一颗偏二叉树,局部是一颗完全或近似完全二叉树结构,提高分类速度。通过在四个数据集上进行实验,实验结果表明,本文算法在分类速度及精度上都有了一定的提升,具有一定的可行性。
猜你喜欢
现代电子技术(2022年15期)2022-07-28
新高考·高一数学(2022年3期)2022-04-28
电子产品世界(2022年4期)2022-04-21
数学大王·低年级(2021年4期)2021-04-27
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
计算机系统应用(2021年2期)2021-02-23
消费电子(2020年5期)2020-12-28
软件导刊(2017年4期)2017-06-20
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
