
任意初始位置机器人领航跟随型迭代学习编队
2020-10-19 04:41卜旭辉
计算机工程与应用 2020年20期
侯 锐,卜旭辉
河南理工大学 电气工程与自动化学院,河南 焦作 454000
1 引言
由于单个机器人在各方面能力的限制,很难独自完成某些工作任务,所以近年来多机器人系统协同工作成为行业研究的热点。多移动机器人协同编队在无人技术领域有着重要作用,例如联合作业、群体侦察、协作运输等领域,使得多移动机器人编队控制问题成为重要的研究方向。多移动机器人协同编队要求各个不同位置的移动机器人在执行任务时能够自主协作形成一个期望的编队队形,同时保持期望编队队形沿着指定的航迹工作。根据实际工作的需要,多移动机器人的编队队形可以是三角形、正方形,也可以是直线型等形状[1]。
从目前已有的文献来看,多移动机器人编队的控制方法主要有:虚拟结构法(Virtual-structure)、基于行为的方法(Behavior-based)、领航-跟随型方法(Leader-Follower)等[2]。虚拟结构法将整个编队视为一个单独的虚拟结构,同时控制整个虚拟结构进行期望运动,虽然能够很容易实现编队并且描绘出虚拟结构中各个移动机器人的轨迹,但是会导致系统的灵活性和适应性不足;基于行为的方法通过多移动机器人的行为描述实现编队和轨迹跟踪,但是难以用数学方法进行分析,因此很难获得精确的编队效果。而领导-跟随型编队控制效果准确稳定且分析简单,非常适用于小型多移动机器人编队控制。在领航-跟随型编队控制方法中,一般选择一个或多个领航者(Leader),其余均为跟随者(Follower)。编队过程中,领航者负责按照预先规划好的航迹进行工作,而其他跟随者利用领航者当前的信息调整自己的状态,通过跟随者的局部控制就能够实现与领航者保持一定距离和角度。文献[3]通过控制领航者与跟随者的相对距离和相对角度实现多移动机器人的编队。文献[4]将编队问题转化为轨迹跟踪问题,利用轨迹跟踪的控制方法实现自主形成编队队形,同时确保编队系统的稳定性。文献[5]将Backstepping-based方法应用于多移动机器人的编队,为各个移动机器人设计了控制律。文献[6]将滑模变结构控制用于多移动机器人的编队。文献[7]采用模糊控制建立模糊集合对移动机器人进行编队控制。
综上所述,对于多移动机器人领航-跟随型编队控制,大多采用滑模控制、基于Backstepping-based方法以及基于Lyapunov 的方法来设计控制器,虽然有大量的研究解决编队控制中编队形成和编队队形保持问题,但是上述方法均是在时间域上实现的渐进跟踪控制,控制精度较低,很难实现精确的编队效果。迭代学习控制(Iterative Learning Control,ILC)作为一种具有“学习”性质的算法,通过对被控系统进行控制尝试,能够通过多次学习,利用过去学习获得的信息,以输出信号与给定目标修正不理想的控制信号,提高系统的跟踪性能,高精度地跟踪期望目标[8]。迭代学习控制[9-13]已经成功应用于具有较强非线性耦合、难以建模以及高精度跟踪控制要求的系统上[14-16]。但传统的迭代学习控制在研究中,要求每次迭代的初始位置需要和期望轨迹的初始位置相同[17],即在初始时刻已经形成期望编队,这就限制了迭代学习控制在多机器人编队控制方面的应用。
基于此,本文设计了一种在任意初始位置条件下基于领航-跟随型的移动机器人迭代学习编队控制算法,运用控制算法自主调节跟随机器人的实时位姿,确保完成从任意初始位置到目标位置的多移动机器人编队运动。相较于以上算法,本文设计的控制算法能够实现:
(1)领航者和跟随者经过多次迭代学习,能够在期望航迹上进行工作。
(2)初始时刻在任意位置的跟随者经过多次迭代学习,能够和领航者一起形成期望的编队队形。不需要考虑编队初始时刻各个机器人之间的位置关系是否与期望队形相同。
2 问题描述
2.1 移动机器人运动学
考虑一组由多个移动机器人组成的队列,首先建立每个移动机器人的运动学模型[18],如图1所示,[x(t)y(t)θ(t)]为t时刻移动机器人的位姿向量,分别是移动机器人在二维坐标系中横坐标、纵坐标以及前进方向与横轴夹角。[v(t),w(t)] 表示移动机器人的角速度和线速度,即控制输入向量。
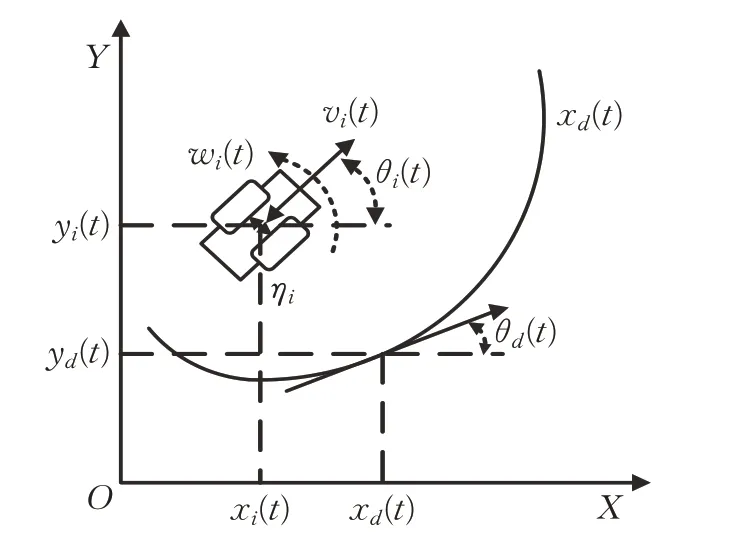
图1 移动机器人运动学模型
移动机器人的运动学模型可表示为:
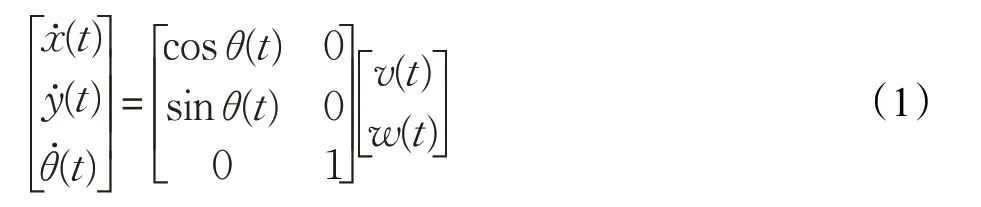
定义:

则运动学模型(1)可以表示为:

式中:
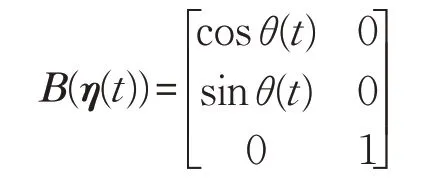
假设移动机器人的状态都是可测的。
2.2 领航-跟随型编队控制
本文采用领航-跟随型编队控制,选定一个移动机器人i(i=1)作为整个系统的领航者,而其余机器人全部作为跟随者j(j=1,2,…),建立领航-跟随型编队的运动学模型,如图2 所示,给出了多移动机器人三角形编队示意图。领航者保持期望航迹航行,跟随者跟踪编队轨迹,并利用领航者的信息调整自身的位姿状态。
利用视距法,计算出跟随者的期望位置:
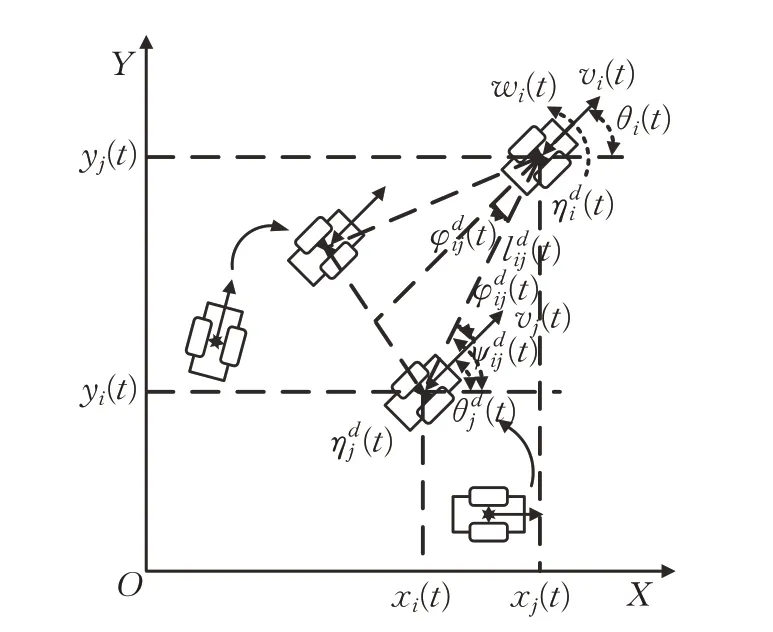
图2 领航-跟随型编队示意图

其中:
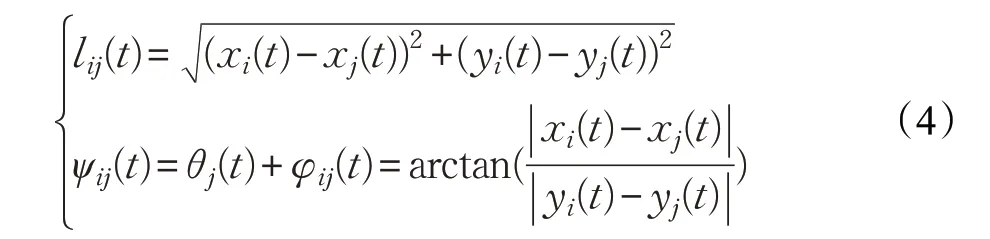
跟随者与编队期望位置之间的系统误差表示为:

式中ej(t)=[xe(t)ye(t)θe(t)]T,t∈[0,T]。
本文目的是设计合适的控制器,实现多移动机器人的编队问题,即为0或者一个极小值)。
3 控制器设计与收敛性分析
针对上述领航-跟随型编队控制中提出的问题,本章提出一种同时包含编队初始位置的学习控制律和编队形成的学习控制律。在学习过程中,假定一段时间范围[0,T]内,当前的迭代进行到k次,则跟随者j的运动学模型可由式(2)重新表示为:

式中:
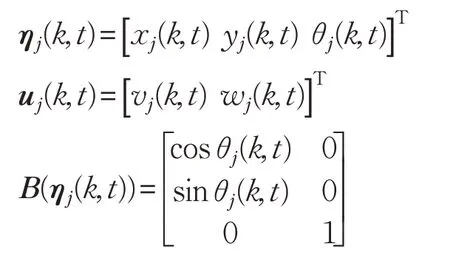
系统误差可由式(5)重新表示为:

根据移动机器人的运动学模型和实际编队特点,可以给出如下假设:
假设1矩阵B(ηj(k,t))对于ηj(k,t)满足全局Lipschitz条件,即存在常数bA,使得下式成立:
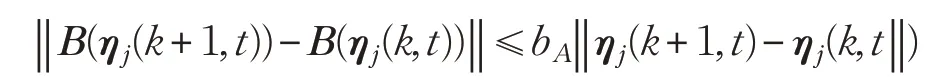
假设2矩阵B(ηj(k,t))有界,即其中bB为正常数。
假设3给定的期望位姿,存在控制输入满足,且期望控制输入满足为正常数。
注1由于矩阵函数B(ηj(k,t))中仅包含函数cosθj(k,t)、sinθj(k,t),因此,假设1的Lipschitz条件和假设2的有界性都是满足的。假设3 是多次迭代后系统实现学习跟踪的必须条件。
3.1 控制器设计
利用位姿误差对跟随者j分别设计如下速度分量学习控制器以及初始位置分量的学习控制器:
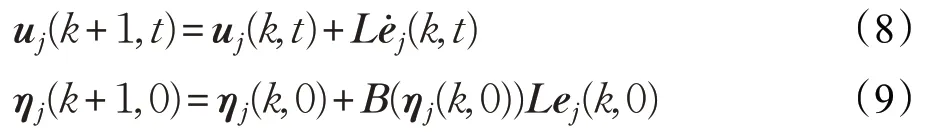
式中,t∈[0,T],k为迭代次数,L为学习增益矩阵。控制器(8)能够实现多次迭代学习后领航者和跟随者在期望航迹上进行工作。控制器(9)能够实现通过每次迭代调整跟随者j的初始位置。
3.2 收敛性分析
定义定义下列范数:
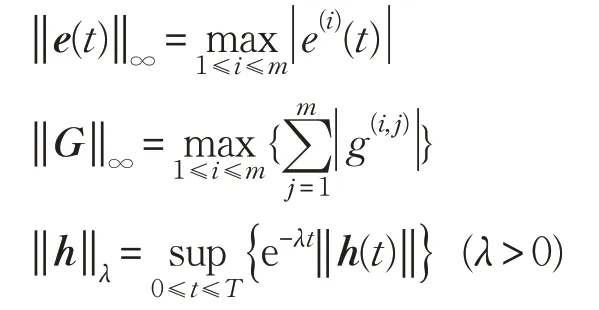
其中e(i)(t)是e(t)∈Rm中的第i个元素,g(i,j)是G∈Rm×m中的第i,j元素,可给出如下定理。
定理对于满足假设1~3的系统式(6),采用式(8)、(9)的控制算法时,当学习增益矩阵对所有的k、t均满足:
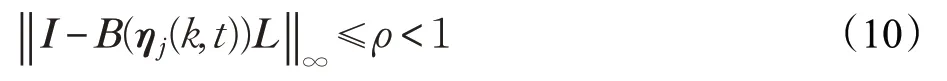
则系统的输出收敛于期望输出,即当k→∞时,有η(k,t)→ηd(k,t),t∈[0,T]。
证明由式(6)~(9)得:
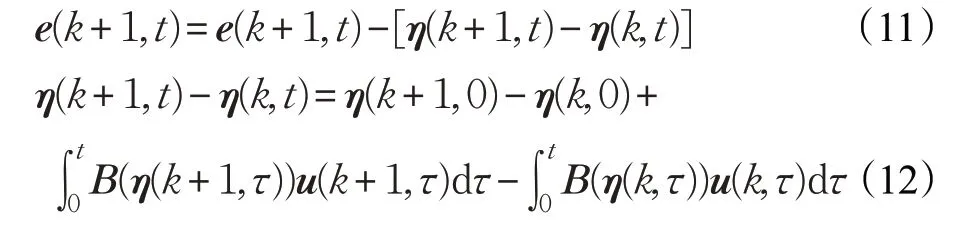
由假设2、假设3可得:
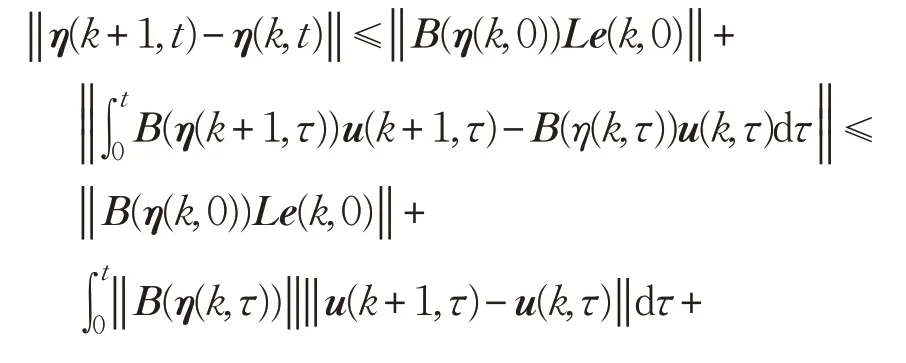
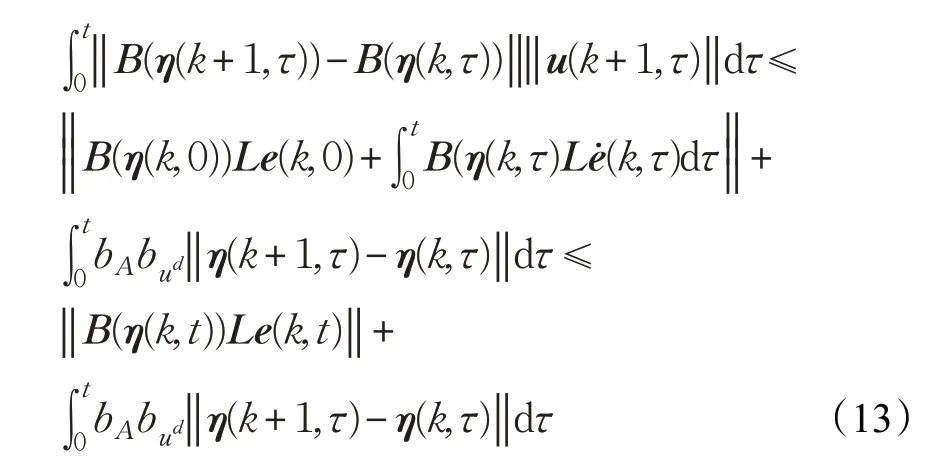
式(13)两边同时乘以 e-λt,并取范数,考虑假设1 中的Lipschitz条件得:
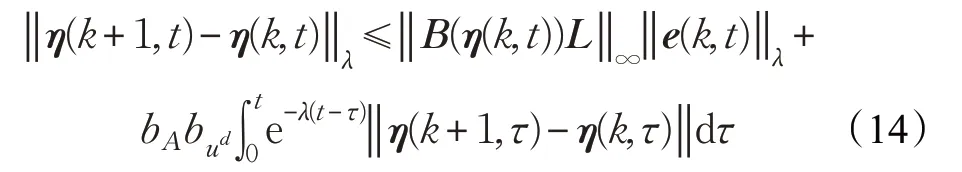
应用Bellman-Gromwall引理可得:
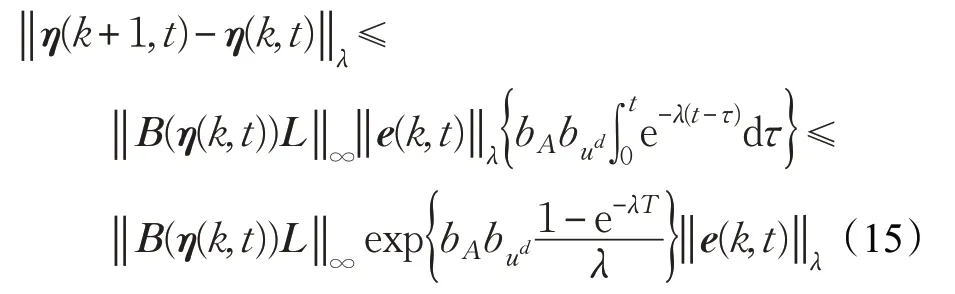
4 仿真研究
本章中,采用MATLAB 软件进行仿真,选取3 个移动机器人进行编队控制的仿真研究,分别作为领航者、跟随者1、跟随者2。采用本文设计的编队算法(8)、(9)进行编队,记录跟随者在不同初始位置情况下经过多次迭代后形成的编队轨迹,若最终领航者和跟随者能够实现在预定航迹上以期望队形工作,则证明本文设计的编队控制算法有效。

即在二维平面内领航者期望轨迹的初始位置(20,0)。
设跟随者1、跟随者2 在二维平面内的初始位置分别为(15,2),(23,-2),即初始状态:
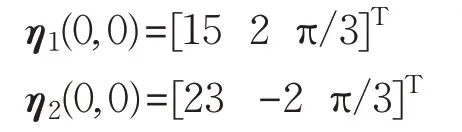
采用三角形编队,设期望编队队形相对位置的期望向量分别为:
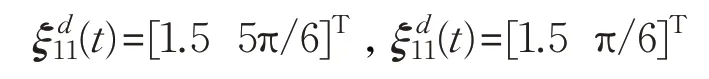
初始输入速度信息分别为:
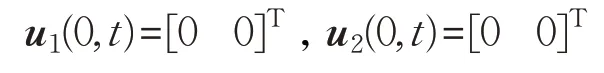
仿真过程中的采样时间取0.001 s。仿真中跟随者1和跟随者2控制器的学习增益矩阵分别为:

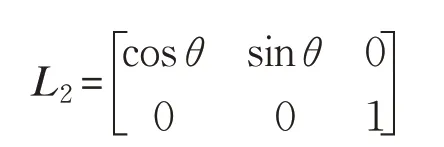
仿真结果如下,图3(a)~(c)分别给出了领航者与跟随者的期望编队效果、迭代20次和迭代150次的编队效果,其中x、y坐标均表示二维平面上的距离。可以看出,随着迭代次数的增加,领航者和跟随者能够实现较为理想的编队效果。图4(a)、(b)反映跟随者1 和跟随者2的位姿误差随迭代次数的变化情况,可以看出经过一定次数的迭代优化,各个跟随者的位姿跟踪误差逐渐收敛到0。
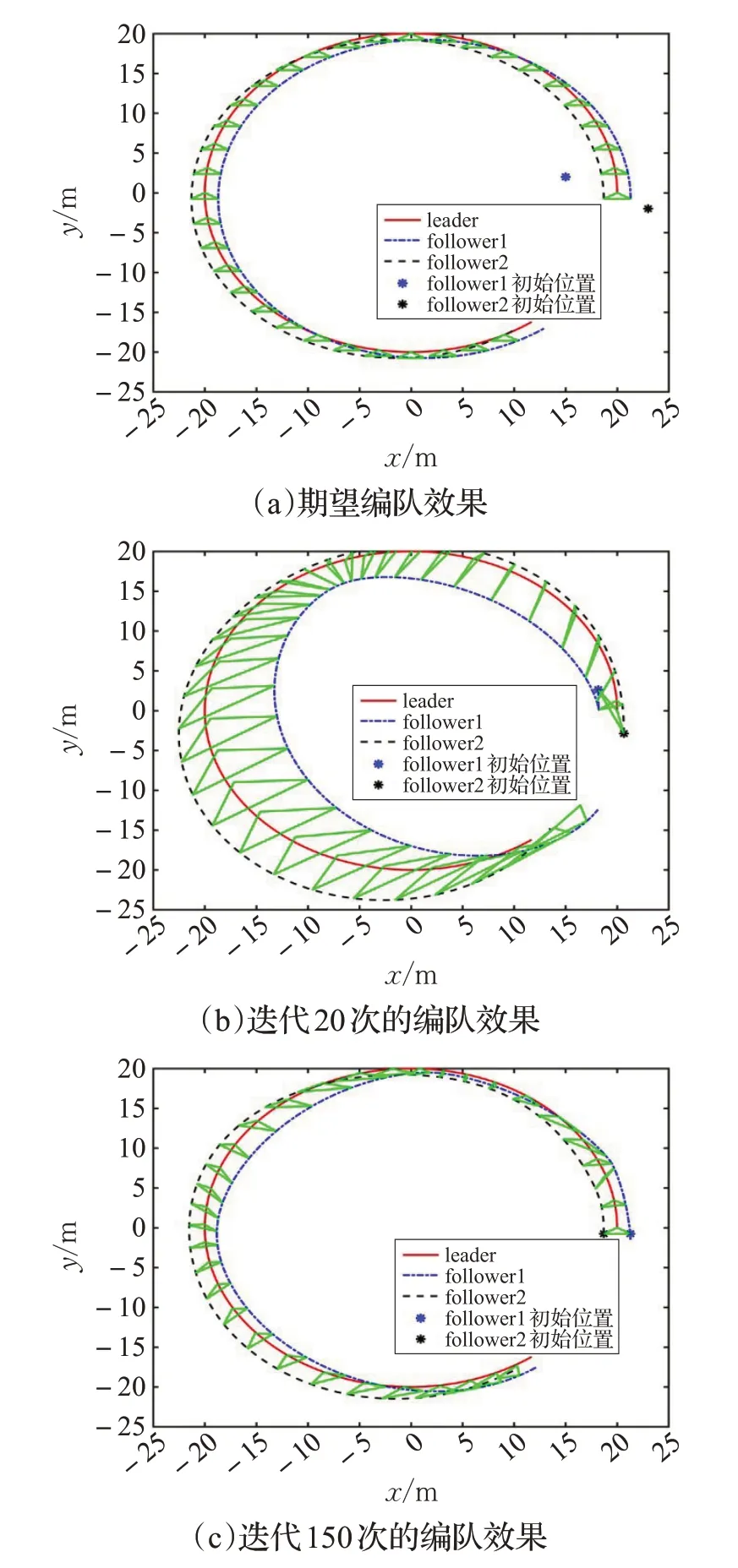
图3 编队效果
为了突出本文控制器不需要考虑机器人编队初始位置的优点,图5 给出了跟随者1 和跟随者2 初始位置在二维平面的变化。图6(a)、(b)分别为跟随者的初始位置在迭代轴上的变化。以上说明基于领航-跟随型的迭代学习编队算法,可以精确地实现编队效果。
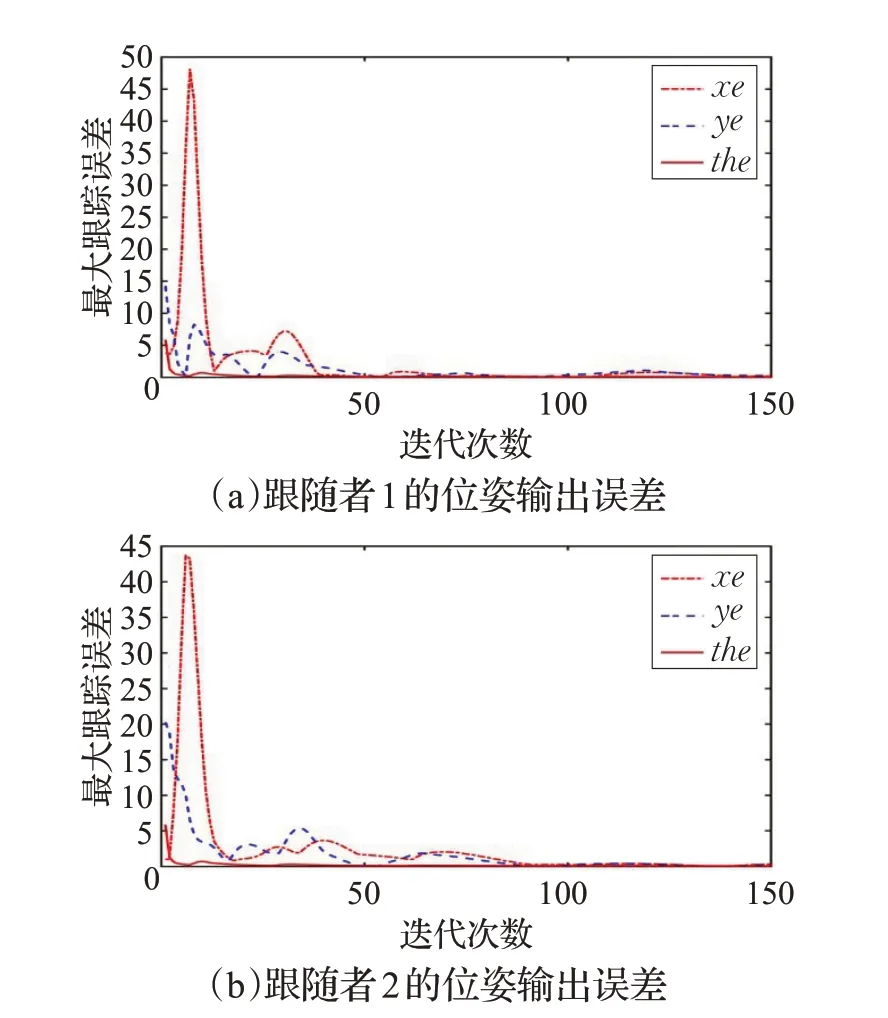
图4 各个跟随者输出的最大位姿误差对迭代次数的变化
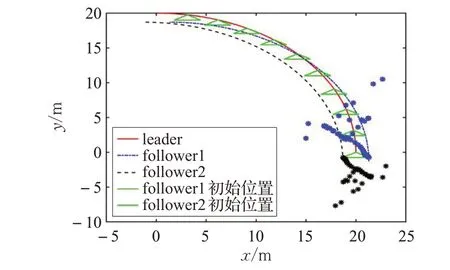
图5 跟随者初始位置在二维平面的迭代变化轨迹
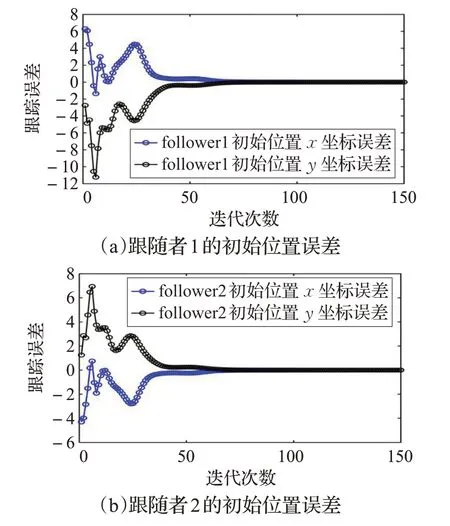
图6 跟随者初始位置误差在迭代轴上的变化
在实际应用中,很难要求移动机器人在编队的初始时刻就位于期望位置,而且每次对移动机器人重复定位操作往往会造成迭代初始位置相对期望位置的偏移。从图5和图6可以看出采用本文设计的控制器能够很好地规避这一编队难点。
为了验证跟随者任意初始位置对编队效果的影响,改变跟随者1、跟随者2的初始位置,假设初始状态分别为:
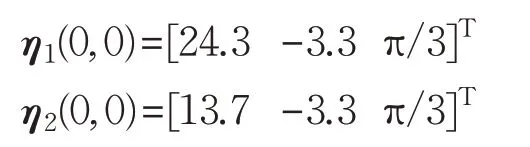
初始输入不变:
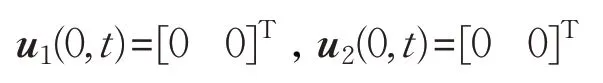
即在二维平面内的跟随者1和跟随者2的初始位置分别为(24.3,-3.3)和(13,7),与原先的初始位置完全不同,仍然选择三角形编队,期望编队队形相对位置的期望向量分别为,领航者与跟随者按照相同的航迹进行编队,仿真过程中的采样时间仍取0.001 s,采用与上述仿真相同的控制算法(8)、(9)。
仿真结果如图7,图(a)、(b)分别给出了在新的初始位置条件下编队的期望轨迹和迭代150次的编队效果,可以看出,改变跟随者的初始位置后,依然能够利用本文设计的控制算法进行编队。
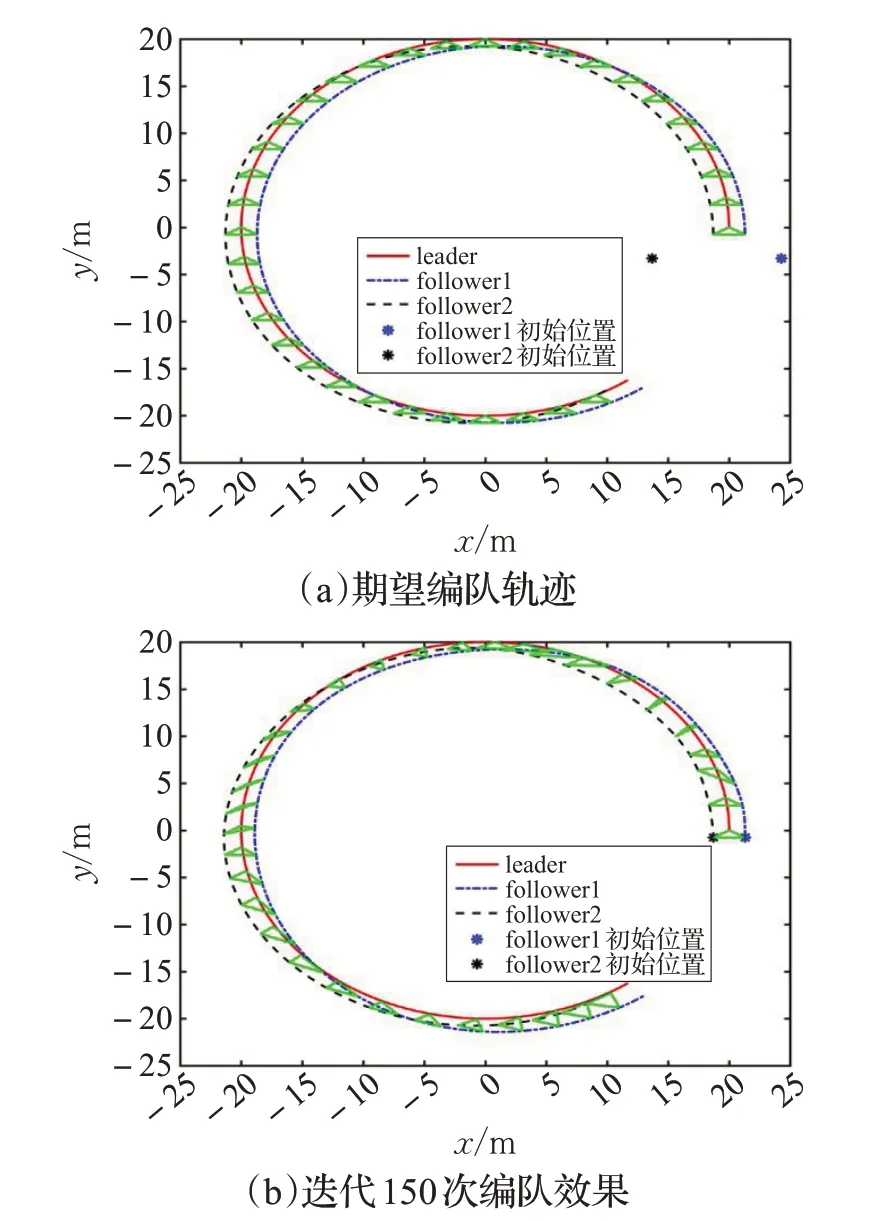
图7 跟随者不同初始位置时的编队效果
由以上仿真结果可以看出,利用本文设计的基于领航-跟随型迭代学习编队算法,能够有效地实现在任意初始位置条件下多移动机器人的编队运动。
5 结束语
针对多移动机器人编队运动中,以往的编队方法都是在时间域上的渐进跟踪控制,本文采用迭代学习控制算法来设计编队控制器,同时,为解决传统的迭代学习要求各个移动机器人的初始位置与期望轨迹初始位置相同这一要求,在算法中加入了对初始位置的学习,设计了一种在任意初始位置条件下基于领航-跟随型的移动机器人迭代学习编队控制算法,大大提高了迭代学习在编队控制应用中的实用性和普遍性。理论方面基于压缩映射方法给出了该算法的收敛性证明。并通过仿真验证了所提算法的有效性。在系统仿真实验中,发现编队迭代次数过多,但本文主要目的是通过将迭代学习控制应用在多移动机器人协同编队控制中,并验证算法的有效性,还未考虑迭代学习收敛速度的问题,迭代过程时间长短对实际工程的影响很大,这也是后续需要进一步研究的问题之一。
猜你喜欢
心声歌刊(2021年5期)2021-12-21
今日农业(2021年5期)2021-05-22
草原歌声(2020年3期)2021-01-18
能源(2019年9期)2019-12-06
能源(2019年12期)2019-02-11
舰船电子工程(2018年12期)2019-01-03
智能城市(2018年8期)2018-07-06
中国广播(2017年9期)2017-09-30
—— 瓮福集团PPA项目成为搅动市场的“鲶鱼”
当代贵州(2017年24期)2017-06-15
诗潮(2017年5期)2017-06-01
