
一种基于标签的电影组推荐方法
2020-10-21 11:19熊聪聪史艳翠
天津科技大学学报 2020年5期
熊聪聪,林 颖,史艳翠,冯 阔
(天津科技大学人工智能学院,天津 300457)
当今互联网发展迅速,同时互联网信息量以爆炸式的速度增长,而这种信息量对用户个人搜索而言异常困难,互联网用户需要花费大量时间去筛选符合条件的信息.推荐系统成为如何从众多信息中筛选出符合用户需要信息的方法之一.传统推荐系统通过分析个人行为推荐,而现在社交网络中,用户不仅不是孤立的而且极有可能还与其他用户存在大量的关系.在影视作品中,用户会自主地根据观看内容为电影标记符合内容的标签.标签作为电影最重要附属信息,同时也是用户对电影最直观的感受,因此标签可用于提取用户行为首选项.大多数用户有时会与朋友和家人一起观看电影,需要考虑群组成员观看的电影类型.
为了解决上述推荐问题,对群组推荐问题提出相关研究.目前,部分组推荐在用户评分预测中直接使用聚类方法对用户进行分类,这样用户的相似度仅依赖用户评分矩阵,而部分组推荐则是挖掘分组之前用户间的相似度信息[2].这样对于标签的信息量挖掘不足,标签只是作为评分矩阵的附加信息,起到较小的作用.例如,郑剑等[3]将标签信息加入到项目相似度的计算过程中,随后融入到矩阵分解.研究人员可以通过构建用户、项目、标签的三维张量,挖掘数据之间的潜在关系.例如,杨林等[4]利用标签惩罚机制和用户评分构建张量;曾辉等[5]则根据用户使用产品的活跃性以及用户之间相似性对用户聚类,构建用户、项目、标签之间的权重.这样能将标签与用户的联系建立起来,而不是作为权值添加进评分矩阵.
鉴于以上研究,本文提出了一种基于标签的电影组推荐方法.首先对标签信息与结合时间因素的评分矩阵分别计算用户相似度,融合二者相似度后,对用户聚类;然后在群组中找出高评分率的标签,建立用户、电影、标签的初始张量,运用梯度下降法[6]迭代求解近似张量;最后融合群组偏好,给出推荐列表.
1 相关工作
1.1 TF-IDF
TF(Term Frequency)表示词条 N在某一文本词条总数中的频率,IDF(Inverse Document Frequency)取包含 N词条的文件数在总文件中占比的对数.TF_IDF(词频-逆向文件频率)计算的是文本中所有词条的重要度权重.
1.2 张量基本知识
张量是对多维数组的线性分析总称,如一阶张量代表向量,二阶张量代表矩阵,高阶张量是多维数组的统称[7].本文是由用户、电影、标签 3种属性构建的张量,即张量R的维度大小由用户数IU、电影数IM、标签数IT组成.
不同推荐系统在构建张量方式上也不同.“0/1”表示形式即用户-产品-标签的三维张量值为0或1,用户使用一个产品并属于一个标签,则对应的张量值为1;否则,用户没有使用该产品也不属于该标签,则张量值为 0[8].多元权值张量通过构建用户-电影-标签之间的关系权值建立初始张量,而对没有看过的电影及标签张量值为0.
1.3 张量分解
本文采用的分解算法为tucker分解,该算法分解后得到张量各维度下的矩阵和1个核张量,3个矩阵包含各维度上的潜在特征[9].表示为

其中:axnl表示核张量 A 的元素;uix、mjn、tkl分别表示矩阵 U、M、T元素.如果为得到近似张量,即简单地使总的误差最小,那么可以将张量分解的逼近问题转化为一个无约束的优化问题,即梯度下降方法
其中 S表示所有非零元素合集.对目标函数 J对uim、mjn、tkl和 amnl求偏导,得到

再根据梯度下降方法,uix、mjn、tk和 axnl在每次迭代过程中的更新公式为

其中:更新公式中的求和项下标 j,k : (i,j,k)∈S、i,k : (i,j,k)∈S 、i,j:(i,j,k)∈S分 别 表 示 矩 阵X(i,:,:)、X(:,j,:)、X(:,:,k)所有非零元素索引.
2 算法设计
本文首先对标签信息与结合时间因素的评分矩阵分别计算用户相似度,融合二者相似度后,对用户聚类;然后挖掘群组成员中的观影信息,统计群组用户观看的高评分率电影,计算电影标签的好评率,建立“用户-电影-标签”的关系张量,并对其分解,得到近似张量;最后对群组偏好融合,得到群组推荐列表.
2.1 计算个人总体偏好
2.1.1 基于标签的用户相似度
电影标签是对每部电影的总结概述或是描述该电影所拥有的特点,以用户对电影标签的偏好代表用户对不同电影特征属性的偏好.通过各个用户观看过的标签在总标签的重要程度,以及用户对标签的观看占比计算用户对每个标签的偏好权重值,本文在TF-IDF基础上进行改进,TF-IDF作为一种统计方法,用于计算标签对于所有标签的是否有代表性[10].用户对标签的偏好表示为

其中:ftj,ui表示用户 ui观看的标签 tj个数;mt表示所有包含标签的电影数;mtj表示包含标签 tj的电影数.在所有标签中,用户观看的标签出现频率较低,可以更好地区别用户之间偏好,相较于高频率标签的出现更具有代表性.而同时标签出现在电影中的次数越少,对于电影的区分度则越高,标签更能区分用户的偏好.标签的重要性为

其中:t表示所有电影的标签出现次数;tj表示标签 tj在总标签中出现次数;n表示用户数;ntj表示观看过标签 tj的用户数.标签之间比率表示标签重要性,用户之间比率表示标签独特性.用户对标签的偏好权重为

用户基于标签信息的相似度公式为

其中:tij表示用户 ui和用户 uj均观看过的标签,分别表示用户对于标签偏好权重的均值.
2.1.2 基于评分矩阵的用户相似度
用户兴趣随时间的推移可能发生变化,在不同时间段会有不同需求.将以前的用户历史信息与现在的信息作为同等价值的信息处理,会使用户行为分析有偏差.用户最近时段的偏好,能够更准确地推断用户偏好.通过指数函数模拟遗忘函数,以此作为时间对用户偏好影响[11].

其中:Δt表示当前时间与评分时间差,时间计算单位为周;T0是半衰期常量;rui,mk表示用户 ui对电影 mk的评分.基于评分矩阵的用户相似度公式为

其中:mij表示用户 ui和用户 uj共同观看过电影,分别表示用户对于电影评分的均值.用户观看电影的数量差会对用户偏好相似预测产生偏差,需要修正因数量级造成的相似度变差.为此,加入用户参数λ修正数量级差造成的偏好相似.

其中:muij表示用户 ui与用户 uj观看相同的电影数;mui表示用户 ui观看的电影数;muj表示用户 uj观看的电影数.修正后的用户相似度为

2.1.3 计算用户总体偏好相似度
基于标签信息计算出的用户相似度,与基于评分矩阵计算出的用户相似度存在差异.标签传输的信息是对电影所属信息的总结,而电影能够传达的信息要远远多于标签信息所能概括的信息.用户在选择观看的电影时不仅仅会选择熟悉的电影类型,有时会挑选拥有熟悉标签的冷门电影类型.比如,用户在看完漫威电影后,需要看看其他类型的电影,也会选择主演们演绎的其他电影.因此,将标签信息计算出的相似度结合评分矩阵计算出的相似度作为用户总相似度作为用户之间的相似度,其计算式为

其中α用来权衡用户标签相似度影响大还是评分相似度影响大.
在计算出总体相似度后,通过用户之间的相似度划分群组,将拥有高相似偏好的用户集合到一起进行推荐.对于如何将用户分组,可以通过分析用户对其他用户的综合相似度,从而采用 K-means聚类方法,将拥有高相似度的用户聚类,得到用户群组[12].
2.2 电影好评率计算
用户分组后的群组中,用户之间偏好相似,直接建立群组的“0/1”初始张量,用户对电影和标签的喜好没有任何表现.通过加入权值的方式,考虑用户对各个维度下的元素喜好程度,同时也可以反映各维度元素之间的关系.直接将用户评分作为初始张量的权重,能够反映用户对电影的偏好.由于标签是对电影的某一方面总结,通过计算用户对电影的评分,以此隐式反映含有该标签的电影是否好看,从而作为标签的好评率.
由于在群组中,用户偏好相似,在张量创建初始可以为高评分率的电影添加一个相对较高的权重值,使得求解近似张量时好电影能够得到更好的推荐.群组评分权值

群组对于一个标签评价高低表明大多数观看人对标签的喜好程度,并以此给没有观看过该标签的用户进行推荐.而对于用户看过拥有该标签的电影,通过计算用户对标签的好评率,降低群组对标签的好评率权重,以此作为用户的权重,避免出现用户不喜欢的电影类型.用户标签好评率权值为

高评分的设定标准通过对比国内外各电影评分网站的评分标准,以及观众通过评分判定电影好坏的程度.国外的影评网烂番茄对于一部电影正面评价超过60%,会给出新鲜的评价,网站80%以上影评人给出超过 75%的评分值,电影达到坚定新鲜标准.同样是国外影评网的 IMDb,作为老牌影评网,十分制下 6~7分的电影属于正常范围,达到8分基本达到top250水平.与 IMDb相似的国内豆瓣影评网评分同样采取十分制,用户对于电影评分判定分水岭为 6分,达到该分数线的电影进入可观看行列,豆瓣top250 分值也在 8分左右.基于以上各大知名网站的比较,用户对于好电影的评价都在分值 6分以上,佳片的评分均达到 8分左右.但由于能达到 8分的电影在各网站相对于电影片库的数量均是占比较少,用户分组后能达到电影推荐条件的数量又需要减少.为提高推荐质量和数量取 6分电影与 8分电影的中位数,将 7分电影定为高评分的电影评价标准,即为五分制的3.5分.

在对用户、电影、标签张量权重中综合群体对标签电影的评分高低,结合各个用户对该电影标签的偏好,综合作为总权重,即

张量的3个维度构建出用户U、电影M、标签T的相互关系,由计算得到的综合权值确定对应张量维度上的元素值并构建初始三维张量.通过分解初始张量得到核张量与3个因子矩阵,之后采用梯度下降更新获得新初始核张量与因子矩阵,乘积后相似张量X,其中张量中的值为对于整体的基于标签的电影组推荐算法设计流程如下:
输入:用户、电影、评分、时间数据的四元组(U,M,R,Ti),用户、电影、标签三元组(U,M,T).
输出:近似张量X.
(1) (U,M,T)按公式(6)—(9)计算基于标签的用户相似度simtag;
(2) (U,M,R,Ti)按公式(10)—(13)计算基于评分矩阵的用户相似度simrating;
(3) 根据公式(14)融合 simtag和相似度 simrating的相似度得到融合相似度 s im(ui, uj);
(4) 根据融合相似度用 K-means分组用户,得到群组用户;
(5) 计算群组用户中标签好评率,按公式(15)—(17)计算;
(6) 按公式(18)建立初始张量权重值.
初始张量按公式(4)和(5)更新迭代张量,得到近似张量X.
2.3 偏好融合
通过近似张量可以得到用户对标签的选择概率,通过这个概率计算用户对每部电影的选择概率.确定群组成员对每部电影的选择概率后,为平衡成员对电影选择概率不同,需要融合用户对电影的偏好,以此满足组内成员的喜好.目前均值策略是组推荐应用较广泛的策略,均值策略采用组内成员对每部电影的选择概率均值作为组选择概率,而后为组内成员选取top_N作为推荐列表.
3 实 验
3.1 实验数据
本文使用 MovieLens数据集,包含用户对视频的评分,以及用户给视频标注的标签数据.通过对数据处理,得到 100004条数据,这些数据集中包含694个用户、9743个电影、1239个标签,每个用户对电影的评分范围为 0.5~5,用户的频分等级划分为十,评分区间间隔为0.5.
3.2 评价标准
本文使用 F值(F-Measure)、准确率(Precision)和召回率(Recall)作为算法的评价标准.在推荐系统中,F值作为评价推荐结果,F值越高推荐结果越好.

其中:Precision表示在推荐列表中得到的推荐结果与测试集中实际情况相同的物品数与所有的推荐物品数的比值,Recall指的是推荐列表中准确的结果占测试样本的比例.准确率和召回率的计算公式为

其中:test表示测试集中群组用户观看电影合集;top_N表示推荐的结果;N表示推荐的数目.在实验过程中,处理后的数据集将被划分成两部分:训练集和测试集.其中,训练集占80%,测试集占20%.
3.3 实验对比方法
本文实验选择的对比方法如下:
(1) method1,对原始评分矩阵聚类分组后的张量分解方法OR(Original Rating).
(2) method2,评分矩阵与标签信息相似聚类的张量分解方法 TIR(Tag Information and Rating).即本文提出用户总体偏好方法,通过标签相似聚类得到的用户群与通过评分矩阵相似聚类得到的用户群,同时通过调整α值,计算各不同比重下聚类得到的用户群推荐结果的差异.
(3) method3,在 method2方法上加入文献[4]中的PMUS(Penatly Mechanism and User Score)方法进行张量分解TIR_PMUS.
(4) method4,在 method2方法上加入本文提出的电影好评率FR(Favorable Rate)后的张量分解方法TIR_FR.
3.4 实验结果
3.4.1 相似度融合中参数α对推荐结果的影响
当参数α取值不同时,TIR推荐结果如图1所示.

图1 参数α 对推荐结果的影响Fig. 1 Effect of parameter α on recommendation results
从图1中得到只有标签信息计算的用户相似度,与通过评分矩阵计算的用户相似度得到的群组推荐结果.单独计算两种信息相似度后的推荐结果与融合相似度得到的群组推荐结果对比显示,评分矩阵得到的结果显示在所有比重中表现较好,排到所有比重的第三,而标签信息得到的结果推荐比评分矩阵结果差,排到第五.从图 1可看出,准确率、召回率和 F值均随推荐数增长而增加,推荐数目在 50时准确率、召回率和 F值达到最高点.综合 3种评价标准,α=0.2的推荐结果表现比其他比重推荐结果表现好.准确率在推荐数目为 4时居于所有比重的最高点,并且推荐数目增加一直是最佳推荐结果.召回率与 F值的表现同其他比重差值在 0.02中变化,在推荐数达到 5后居于所有比重最高点,并随推荐数增长,召回率与F值增加最快.
3.4.2 加入好评率后相似度融合中参数α对推荐结果的影响
method4在α=0.3时,准确率、召回率与 F值的结果均表现比其他比重优秀(图 2).由于推荐列表是与群组用户的合集进行对比,推荐列表相较测试集数量过于稀疏,使得准确率很高,同时召回率和 F值整体很小.
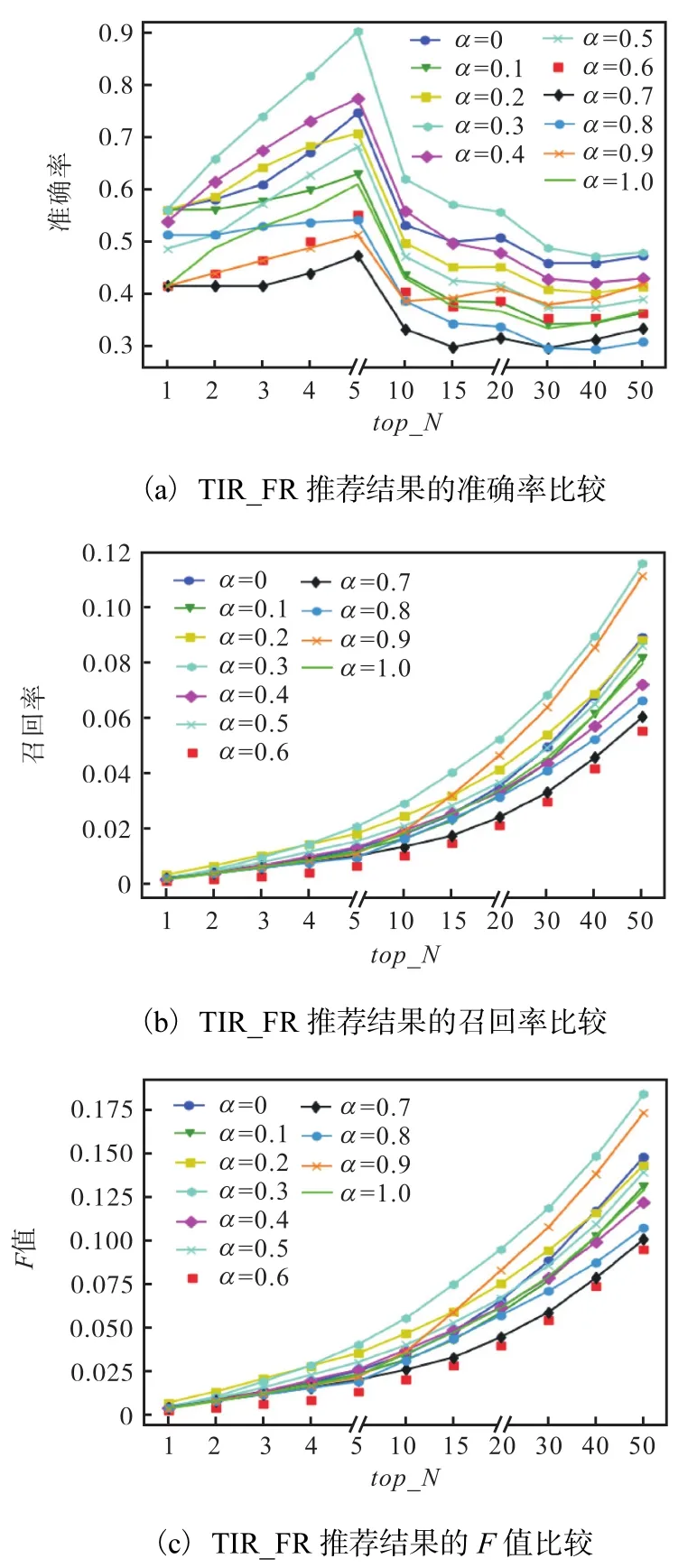
图2 加入好评率后参数α 对推荐结果的影响Fig. 2 Effect of α changes on results after adding favorable rate
由于好评率计算中以评分作为选择概率,并在此基础上计算组内成员对标签的好评率,将评分与标签好评率结合作为最终权重.这使得分组中评分信息与标签信息对推荐结果影响程度改变,造成 TIR和TIR_FR在不同α值下取得最佳推荐结果.
3.4.3 不同方法推荐结果的比较
图 3表示 4种方法在准确率、召回率和 F值上的比较.

图3 不同方法推荐结果的比较Fig. 3 Comparison of results by different recommendation methods
OR的准确率、召回率和F值增长速度相较于其他 3种较低,准确率基本持平.TIR在推荐数目小于4时,准确率低于 OR,但是在召回率和 F值的表现上要优于OR.TIR_PMUS与TIR_FR在各方面均优于其他两种方法,准确率在推荐数为 5时达到峰值,随后均在推荐数到10时急速下降.之后TIR_PMUS准确率能够在下降后缓慢增长,接近 0.5左右,但TIR_FR准确率一直在缓慢下降.TIR_FR在推荐数达到 50时,准确率与 TIR_PMUS表现结果相同,均达到 0.5.TIR_FR的召回率与 F值表现在推荐数达到40后被TIR_PMUS超过.加入标签后的推荐相对于只通过用户评分预测用户偏好电影,更相似度用户之间推荐效果更佳突出,通过标签信息构建的张量在比只在用户评分中构建张量能够得到更佳的结果.
4 结 语
本文针对电影推荐中标签信息的利用率低,提出一种基于标签的电影组推荐方法.针对现有组推荐技术大多是在随机分组或原始信息上聚类分组后推荐,现提出分组时尽可能提高组内成员相似度,通过评分矩阵与标签信息进行融合相似度,以此提高组内相似度.通过实验验证本方法对推荐准确率有所提高.本实验在使用张量进行用户-电影-标签信息隐形特征分析时,张量分解运行时间长,需要提高推荐速度.
猜你喜欢
科技信息·学术版(2022年8期)2022-02-25
井冈山大学学报(自然科学版)(2021年4期)2021-10-13
华南师范大学学报(自然科学版)(2021年3期)2021-07-03
小型微型计算机系统(2021年6期)2021-05-24
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
北华大学学报(自然科学版)(2020年6期)2021-01-05
健康体检与管理(2021年10期)2021-01-03
