
使用K近邻算法诊断乳腺癌
2020-10-21 12:24赵宇
大东方 2020年3期
赵宇

摘 要:随着信息技术的不断发展,医疗大数据的概念也逐渐被人类所熟知。通过对数据挖掘技术在乳腺癌各领域的研究现状(乳腺癌基因研究、乳腺癌早期辅助检查、力学药物靶点识别、乳腺癌新中医治疗方法)的分析,展望数据挖掘技术应用于乳腺癌领域的前景,为数据挖掘技术在乳腺癌疾病的研究提供新思路。
关键词:数据挖掘;乳腺癌
一、前言
乳腺癌已成为当前社会的重大公共卫生问题。全球乳腺癌发病率自20世纪70年代末开始一直呈上升趋势。美国8名妇女一生中就会有1人患乳腺癌。中国不是乳腺癌的高发国家,但不宜乐观,近年我国乳腺癌发病率的增长速度却高出高发国家1~2个百分点。
二、数据源
我们将使用来自UCI的乳腺癌诊断数据集,该乳腺癌数据包括569例乳腺细胞活检样本,每个样本包含32个变量。其中id变量是样本识别ID,diagnosis变量是目标变量(M代表恶性,B代表良性)。其他30个变量都是由10个数字化细胞核的10个不同特征的均值、标准差和最大值构成。这10个基本特征为:
三、数据探索和预处理
.3.1 数据的探索
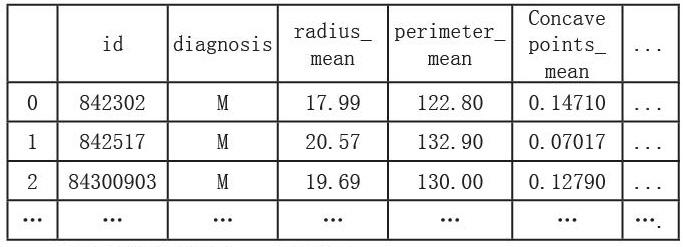
首先,搜集数据集如下图所示,由于数量问题,只显示其中部分,共计569个样本,32个变量。
将整个数据集导入SPSS软件中。
第一个变量为ID,无法为实际的模型构建提供有用的信息,所以需要将其删除。diagnosis变量是我们的目标变量,我们首先统计一下其取值分布。观察在我们的数据集中,恶性(M)和良性样本(B)的分布情况。在正式建模之前需要将其进行整数编码,将良性(B)编码为0,将恶性(M)编码为1。
通过统计我们的569个样本中,良性样本(B)和陰性样本分别有212个,占比分别为62.7%和37.3%。其中作为示例,我们主要选取所有变量中的三个:radius_mean,area_mean和smoothness_mean。
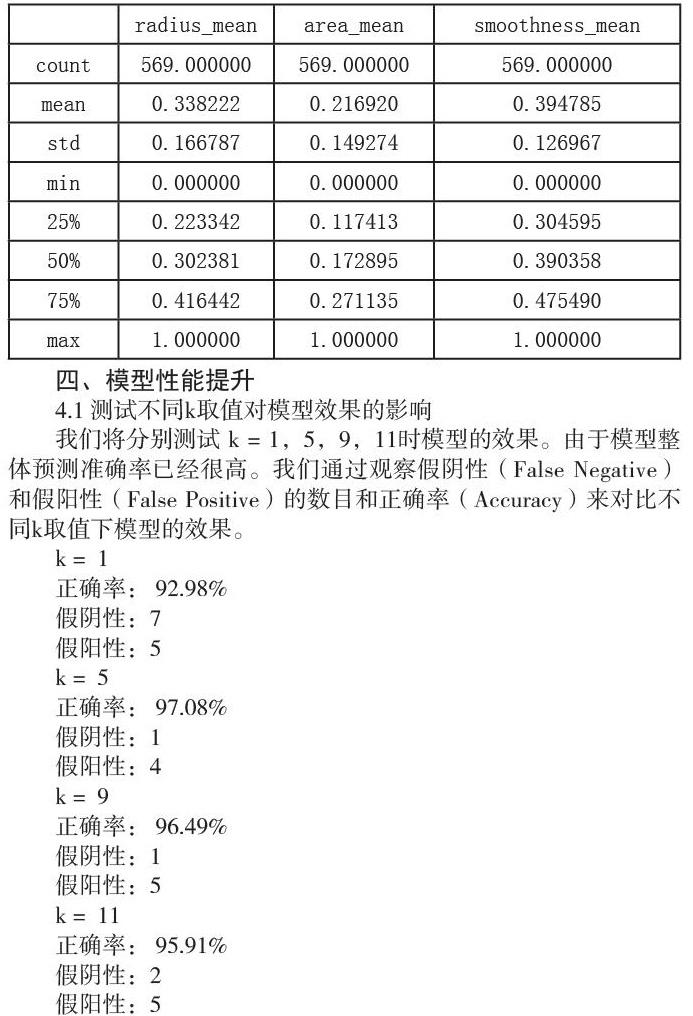
通过SPSS软件生成图形对三个变量进行分析:观察这三个变量的统计信息,发现它们的取值范围不大一致。radius_mean取值范围为6.981~28.110,area_mean取值范围为143.5~2501.0,smoothness_mean取值范围为0.05263~0.16340。不同变量的测量尺度不一致会影响K近邻算法中的样本距离计算。例如,如果上述三个变量直接参与距离计算,则area_mean变量将会对距离计算影响最大,从而会导致我们构建的分类模型过分依赖于area_mean变量。在应用K近邻等涉及距离计算的算法构建预测模型之前,需要对变量取值进行标准化。常见的标准化方法有min-max标准化和Z-score标准化等。
3.2数据的标准化:
为了将自变量进行min-max标准化,使用min_max_normalize函数。该函数输入为数值型向量x,对于x中的每一个取值,减去x的最小值,再除以x中数值的取值范围。结果如下可见所有的变量都已经正确地标准化到0和1之间:
四、模型性能提升
4.1 测试不同k取值对模型效果的影响
我们将分别测试 k = 1,5,9,11时模型的效果。由于模型整体预测准确率已经很高。我们通过观察假阴性(False Negative)和假阳性(False Positive)的数目和正确率(Accuracy)来对比不同k取值下模型的效果。
可见,当 k = 5 时,假阳性数量最少,且假阴性数量仅为1,正确率达到最高。当然,这也只是在171个测试样本上的结果。
参考文献
[1]MOURADC,LOPEZMA G.An evaluation of imagedescriptors combined with clinical data for breast cancer diagnosis [J].Intemational Joumal of computer Assisted Radiology and Surgery,2013,8(4):561-57.
[2]张旭东,孙圣力,王洪超.基于数据挖掘的触诊成像乳腺癌智能诊断模型和方法[J].大数据,2019,5(01):68-76.
[3]侯公楷.中医药防治乳腺癌进展[J].辽宁中医药大学学报,2016,18(05):249-253.
(作者单位:河北大学 生命科学学院)
猜你喜欢
医学食疗与健康(2022年3期)2022-04-23
医学食疗与健康(2022年2期)2022-04-23
中国典型病例大全(2022年7期)2022-04-22
健康体检与管理(2021年6期)2021-11-17
疯狂英语·读写版(2020年10期)2020-11-06
保健与生活(2019年7期)2019-07-31
计算机应用(2016年10期)2017-05-12
家教世界·创新阅读(2016年11期)2016-12-27
故事会(2016年15期)2016-08-23
少年博览·小学高年级(2016年6期)2016-06-17
