
面向电网的边缘算力优化与分布式数据存储处理模型研究
2020-10-23 01:55李宝树张凤佳沈杨杨
广东电力 2020年9期
李宝树,张凤佳,沈杨杨
(江苏电力信息技术有限公司,江苏 南京 210000)
随着我国经济的发展,各行各业对于电能的需求也日趋增大,电能产业的发展成为我国工业化发展的重要支柱。电网是将电力从供应方传送到用户的连通网络,通常由发电、输电、配电和用电4个阶段组成[1]。工业、生活用电量的增加,用电情景的复杂化使得电网运行复杂度逐步提高[2]。传统的电网系统多为集中调度计算平台,可以实现电网资源协同调度以及电网信息建设的集团化运作[3];但随着电网数据的迅速增长以及对数据处理实时性要求的增加,传统电网系统在数据存储和处理方面能力不足的问题也日益显露,信息交叠、信息资源浪费、兼容性差以及重复开发等问题严重制约了电网系统的工作效率,如何调整电网系统的架构成为亟待解决的问题之一[4-5]。
工业、生活用电量增加的同时,用户对电能质量也有了更高的要求,断电以及电压不稳定等问题会直接影响到工业生产活动和用户生活,因此供电安全、可靠和稳定的重要性不言而喻[6]。配电网的复杂性使输电线路经常会发生各种故障,如果故障不能及时消除,则会引发更大范围的停电,甚至导致系统崩溃。为了实现对电网系统中输电线路、变电站以及其他电力设备运行状态的实时监测,智能电网在网络边缘部署了大量的智能终端、传感设备。这些边缘设备产生了海量的数据,使得云计算能力无法与数据量相匹配[7];同时新型应用对数据处理的实时性提出了更高的要求,传统云计算模式很难有效应对[8]。
边缘计算是在靠近数据源头的网络边缘处,融合网络、计算、存储、应用的新网络架构与平台[9-10]。边缘计算通过将存储计算能力下放到靠近数据源头的网络边缘,减少了因网络堵塞与路由导致的高时延,做到对终端请求的快速响应与海量数据的实时处理;同时,通过对价值密度低的数据及时过滤、计算与处理,降低通信开销,减少云计算中心的压力。文献[11]将边缘计算应用到电力行业,对边缘计算在电力需求响应业务中的应用进行展望,并提出了基于边缘计算的家庭能源管理系统。文献[12-13]对边缘计算的典型应用场景进行介绍,包括能效管理、智能制造、预测性维护等,但在电网环境下以能耗为目标针对边缘算力进行分配与优化的研究却很少。
物联网、云存储以及边缘计算技术的出现为解决电网系统遇到的上述各种问题提供了可能[14]。本文以上述信息和计算技术为基础,提出一种面向电网的分布式数据存储处理模型,在模型基础之上,以电网边缘侧的终端设备和边缘服务器为边缘算力,建立了基于能耗的边缘层计算任务分配优化模型,并通过合适的算法对模型进行求解。以上模型与算法,解决了传统电网系统无法满足电力大数据的存储、计算效率低下、数据质量差的问题,实现对终端数据实时的监测与处理[15-17],绿色化使用电网边缘算力。
1 面向电网的分布式数据存储处理模型
图1给出了面向电网的分布式数据存储处理模型。

HDFS—Hadoop分布式文件系统,Hadoop distributed file system的缩写。图1 面向电网的分布式数据存储处理模型Fig.1 Power grid oriented distributed data storage and processing model
整个框架平台分为边缘计算层、数据存储层、平台层、应用决策层4部分。其中边缘计算层由电网系统采集终端的各种智能电表、传感器以及各种边缘网关与基站等组成,负责电网数据的采集与上传,对终端设备上传的数据进行解析转换,以及对终端设备任务进行边缘计算[18],并将数据传送给数据存储层。数据存储层主要是由Oracle数据库和基于HDFS的分布式存储系统构成,负责对采集到的电网数据进行存储,同时也是平台层的存储基础。平台层对采集到的基础数据进行各种业务逻辑计算,平台层部署了用户管理、权限管理、数据存储等基础的服务功能软件。应用决策层主要是由针对用户以及管理员的可视化界面和相关的应用程序构成;同时系统还有分析计算模块,用于对系统各部分提供必要的算法优化支撑。
1.1 边缘计算层
终端设备:电网系统中的数据主要来源于生产、营销、调度部门3个部分,部门下面有大量的监测设备、终端设备,用来采集与本部门业务相关的数据[19-20]。
边缘计算层还包括边缘控制器、边缘网关、边缘服务器、基站等。边缘控制器具有数据采集、数据处理与逻辑控制的功能。电网系统存在着大量的智能电表、传感器等终端设备,不同的终端设备连接方式、通信协议等存在差异,同时电网系统需要对各个部门不同类型的数据进行综合的分析挖掘;因此,为了实现各部门接入数据的互联互通,各部门接入的数据要先经过分析、处理才能接入平台。边缘网关可以实现异构终端设备的接入,屏蔽底层差异,同时还具有协议解析转换、数据采集等功能。边缘服务器是边缘计算的实施者,完成对终端设备发布任务的处理与计算,将计算结果及时返回给终端设备或者进一步上传至数据存储层及平台层。基站主要实现有线通信网络与无线终端之间的无线信号传输。
1.2 数据存储层
数据存储层主要由Oracle数据库和HDFS分布式存储系统构成。HDFS可进行海量数据的并行处理,具有高吞吐量的优势,适合存储大容量文件,但是它只能进行数据的顺序访问,具有高时延[21]特点。HBase能保证数据访问的实时性,同时也能像 HDFS那样具有比较高的数据吞吐量[22]。HBase是面向列数据存储的数据库,底层对数据的存储也是通过HDFS来实现,电网采集的数据按照编号放入HBase的数据表中,作为后续处理的基础。
电网大量使用了关系型数据库,数据是结构化的,其数据库表之间也存在大量的关联关系,直接使用NoSQL并不合适,因为NoSQL并不支持处理join查询[23]。关联关系在电网内部很常见,所以对于电网数据的关联查询操作也是很频繁的,本系统平台采用Oracle数据库与HDFS分布式存储相结合的方式,有效地进行多表关联等复杂的查询,弥补了HBase的NoSQL工具在这方面的不足;而关系型数据库里的结构化数据可以通过sqoop批量的迁移到Hadoop的HDFS中[24],也可以将HDFS数据存储至关系型数据库,实现两者数据的交互。
1.3 平台层
平台层面向应用决策层的应用提供应用开发、测试和运行过程中所需的基础服务。平台层以平台软件和服务为核心,部署了用户管理、权限管理、数据存储等基础的服务功能软件;开发人员可以根据平台层提供的编程模型与API开发电网系统的应用,以对电网采集到的数据进行分析处理。
1.4 应用决策层
应用决策层主要是由针对用户以及管理员的可视化界面和相关的应用程序构成,可通过web页面对监测和分析结果以图形化的形式展现给用户。该层主要实现数据质量监测、负荷监测、停电管理、异动管理等功能,通过监测了解电网的运营情况,提前预防或及时处理输电线路的异常运行状态。应用决策层使用了浏览器作为应用的最终载体,系统通过结构化查询语言(structured query language, SQL)向Oracle数据库请求查询,查询结果通过条形图、饼图、折线图、表格等多种形式进行了数据展示,系统界面如图2所示。

图2 电网监测运营应用界面图Fig.2 Grid monitoring operation application interface
2 边缘计算在电网中的应用
为了实现对电网系统运行状态的实时监测,在网络边缘部署了大量的智能终端与传感设备。终端设备收集电网各个方面的数据,包括环境数据、电气信息、运行信息等。终端设备产生的海量数据中有的信息密度较低,所有的数据均由云计算中心进行处理会造成云计算中心高负荷,通信时耗增大,同时有些数据处理时延苛刻,云计算也不能满足这些数据分析、处理、响应的实时性要求;因此,边缘计算模式应运而生,如图3所示。边缘计算利用边缘计算节点有限的计算资源与通信资源,通过合理地分配任务与资源,实现终端数据的本地化处理,提高了电网的通信性能,降低通信时耗和云中心计算负载[25-26]。

图3 边缘计算模型Fig.3 Edge computing model
2.1 算法与模型
2.1.1 边缘层计算任务分配优化模型
为了绿色化使用电网边缘算力,提升数据处理效率,本文以电网边缘侧的终端设备和服务器为基础,建立了基于改进的能耗的边缘层计算任务分配优化模型,并采用双层优化(bilevel optimization approach for joint offloading decision and resource allocation,BiJOR)算法[27]分析计算和求解该模型。
在基于能耗的边缘层计算任务分配优化模型中,设电网中终端设备的集合为N={1,2,…,n};设备i的任务定义为Ui,Ui={Ci,Di,Bi,Ti,max},其中Ci为任务的计算量,Di为任务的输入数据量,Bi为任务的输出数据量,Ti,max为任务允许的最大时延。任务可以分配到本地设备、其他终端设备以及边缘服务器上面执行,共有n+1种执行模式M={0,1,2,…,n},其中边缘服务器可以接收多个终端的任务,终端设备只能接收1个任务,任务计算时间
(1)
式中rij为设备j为任务i所分配的计算资源。
任务计算能耗[28]
(2)
式中k为能耗系数,它与移动设备自身硬件电路结构有关。
数据传输速率
∀i∈N,j∈M{i}.
(3)
式中:W为带宽;w为背景噪声功率;ohj=1表示第h个任务分配到第j个设备上执行;Pt,i为第i个任务的传输功率;Hij为设备i与设备j之间的信道增益。
数据传输时间
(4)
数据传输能耗
Et,ij=Ebt,ij+Ezt,ij,
(5)
(6)
式中:Ebt,ij为任务分配到边缘服务器时的传输能耗;Ezt,ij为任务分配到其他终端设备时的传输能耗;Pr,i、Pr,j分别为第i、j个设备的接收功率。
优化目标为最小化任务计算与传输能耗,即
(7)
约束条件:

(8)

(9)
(10)
条件4:rij>0,∀oij=1(i∈N且j∈M).
(11)
条件5:rij=0,∀oij=0(i∈N且j∈M).
(12)

(13)
式(7)—(13)中:oij=1表示第i个任务分配到第j个设备上执行;rj,max为第j个设备最大可分配资源;Tij为第i个任务分配到第j个设备上的执行时间。
2.1.2 求解算法
由于优化问题模型中计算与通信资源分配依赖于卸载决策的制订,而卸载决策的优劣又随着资源分配的好坏而改变,只考虑其中之一就破坏了两者之间强烈的依赖关系,对解质量造成极大的干扰。文献[27]采用了BiJOR方法,将问题转化为1个二层优化问题。二层优化问题是在保证下层优化问题最优的前提下,对上层优化问题进行求解。文献[27]将卸载决策视为上层优化问题,目的是最小化所有用户的总能耗,利用蚁群算法对问题进行求解;计算资源分配被认为是下层优化问题,目的是最小化所有用户的计算能耗,并采用了单调优化方法进行求解。在双层优化方法BiJOR基础之上,为更好地适配本文问题,本文拟采用动态参数变化法,利用模拟退火算法[29]中的Metropolis准则,提出M-BiJOR算法,对边缘计算任务卸载与资源分配联合优化。算法利用种群的迭代次数动态更新个体维度取值方法的判断概率,一定程度上避免陷入局部最优,提高局部开发与全局勘探的能力。
个体维度取值的判断概率
(14)
T=TinitβG.
(15)
式中:α>0为常量;T为温度;Tinit为初始种群温度;βG为第G次迭代的温度衰减系数,且0<βG≤1。
此外,任务i分配给设备j执行规则
(16)
式中:p为随机概率值且0≤p≤1;J为针对任务i根据约束条件式(10)及式(13),在所有执行模式M中获得的可行设备集合中的随机值。
M-BiJOR与移动边缘计算(mobile edge computing,MEC)问题之间的映射见表1。

表1 M-BiJOR与MEC问题的映射Tab.1 Mapping of M-BiJOR and MEC problems
M-BiJOR算法流程如图4所示,主要步骤如下:
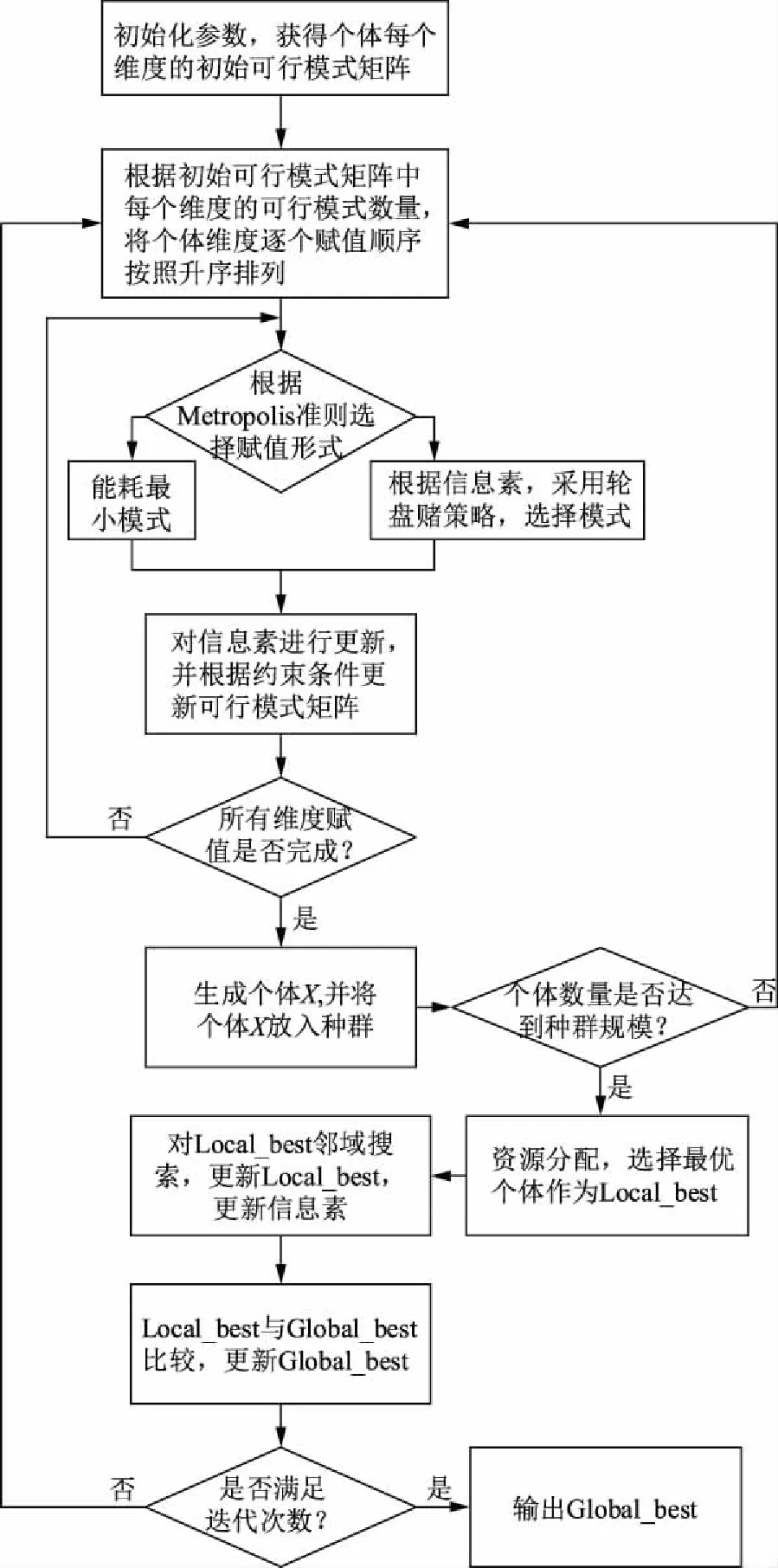
图4 M-BiJOR算法流程图Fig.4 M-BiJOR algorithm flow chart
步骤1:初始化参数,根据约束条件式(10)及式(13)获得个体每个维度的可行模式矩阵。
步骤2:根据可行模式矩阵,通过可行模式数量将个体维度升序排列进行优先级赋值,采用Metropolis准则动态更新每个维度赋值时选择能耗最小的模式或者随机模式,生成个体X的方法判断如式(14)的概率,温度越低时赋值方式偏向选择能耗最小的模式;此外,并采用蚁群算法中的信息素机制对个体X的生成起到一定的反馈作用,再次返回步骤2,直至生成设定数量的个体数成为1个种群为止。
步骤3:生成种群后根据式(3)进行资源分配,根据式(7)计算种群中每个个体的适应度值,选择适应度值最小的个体为局部最优解Local_best。
步骤4:对Local_best进行邻域搜索,若找到更优个体则将其作为Local_best,并再次更新信息素,加深最优个体对后续种群个体生成的影响。
步骤5:在全局最优解Global_best与Local_best中选择适应度值较小的个体,更新Global_best。
步骤6:返回步骤2进行下一次的迭代直至满足迭代次数为止,输出当前最优解Global_best及其适应度值。
2.2 仿真与分析
在仿真过程中,本文所有的实验均在MATLAB R2018b中实现,使用的是1台运行在2.20 GHz(处理器)和8 GB RAM下的i7-8750 CPU的个人计算机。为了在电网边缘侧验证算法性能,在仿真过程中,任务与算法参数设置见表2,采用蚁群系统-综合学习粒子群(ant colony system-comprehensive learning particle swarm optimization, ACS-CLPSO)算法[30-31]、自适应邻域搜索(adaptive neighborhood search, ANS)算法[32]作为对比算法,其参数设置与原文献一致。

表2 任务与算法参数表Tab.2 Task and algorithm parameters
实验结果如图5、6所示。
由图5(a)可知:M-BiJOR在能耗优化方面的表现普遍优于ACS-CLPSO和ANS,并且随着终端设备数量的增加,M-BiJOR与ACS-CLPSO和ANS的能耗差距增大,说明M-BiJOR在电网边缘侧终端设备数量增加时,其优化效果更加显著。由图5(b)可知:ANS在算法运行速度方面要普遍优于M-BiJOR,但能耗优化方面M-BiJOR效果更好,故在边缘计算卸载方案求解速度优先时,可选择ANS求解算法,而当想要更好的求解效果时,可选择M-BiJOR求解算法。
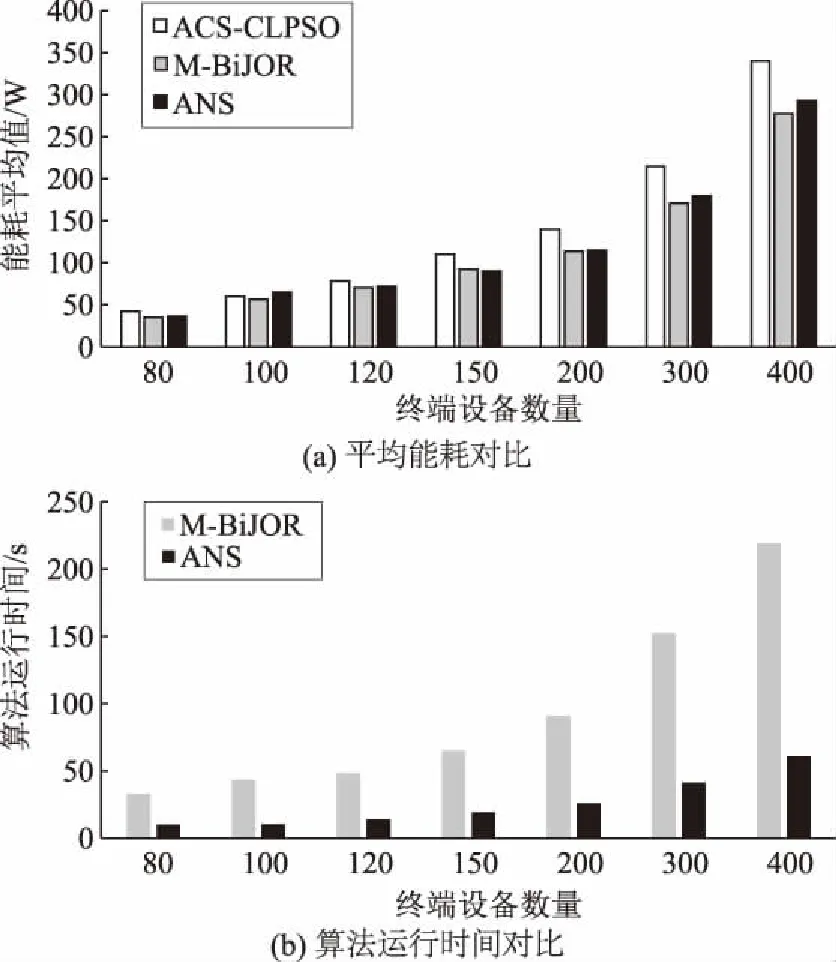
图5 不同算法平均能耗、运行时间对比Fig.5 Comparisons of average energy consumption and running time of different algorithms
图 6所示分别描述了终端设备数为200和400时平均能耗随算法进化迭代次数的变化,由图6可知,无论是小规模(n=200)还是大规模(n=400)

图6 n取不同值时不同算法平均能耗进化过程Fig.6 Evolution process of average energy consumption with different n values
的边缘算力分配任务,M-BiJOR均在初始阶段获得优于ACS-CLPSO和ANS的解,这有助于在电网系统中短时间内获得高质量的解决方案。在解决大规模问题时,随着算法的运行,与ACS-CLPSO迅速陷入局部最优解相比,M-BiJOR具备一定的持续收敛能力,从而进一步提升了解的质量;此外,得益于M-BiJOR采用的双层混合优化机制,M-BiJOR在更早的算法代数时就可获得远优于ACS-CLPSO的解。这一现象表明,针对此优化问题,类似于ACS-CLPSO这种双层都采用智能优化算法的方案,其求解效果尚不能满足电网需求。
以电网系统终端有80个和400个终端设备任务时的情况为例进行对比,采用M-BiJOR与ANS算法进行求解,得到的解见表3、4。
表3算法的解对应于实际电网系统中80个和400个终端设备任务时的分配方案,其中0代表将设备任务分配到边缘服务器上执行,其他的非0元素i代表将此任务分配给终端设备i执行。由表3、4所示可知:在任务数量较少的情况下2种算法得到的解对应的能耗差距相对较小,随着任务数增加,M-BiJOR算法求解的方案系统能耗更少,而ANS在算法执行时间上更具优势。

表3 M-BiJOR与ANS算法的解(n=80)Tab.3 Solution of M-BiJOR and ANS algorithms(n=80)

表4 M-BiJOR与ANS算法的解(n=400)Tab.4 Solution of M-BiJOR and ANS algorithms(n=400)
综上所述,M-BiJOR在求解效果上要普遍好于ANS与ACS-CLPSO,而ANS在算法运行时间方面比M-BiJOR与ACS-CLPSO更具优势;所以在分布式电网数据存储处理平台的分析计算模块中配置M-BiJOR与ANS算法作为核心解决方案,可根据需要来对不同算法进行选择。
2.3 系统交互界面展示
应用决策层会基于平台层开发相对应的异动管理模块用于显示监测到的全网异动情况,对各地市的异动故障进行统计分析,并对收到的异动进行审核,进而对审核通过的异动进行整改。系统界面如图7所示。

图7 异动管理模块系统界面图Fig.7 Change management module system interface
3 结束语
本文构建了一种面向电网的分布式数据存储处理模型,根据HDFS分布式存储数据吞吐量大、可靠性高、成本低等特点对海量的电网数据进行采集与存储,利用HBase对海量数据进行实时的、随机的读写访问,满足电网数据实时性处理要求;同时基于MapReduce分布式计算模型对电网数据进行并行分析计算,解决传统集中式电网平台无法满足电力大数据存储、分析处理效率低下、数据质量差的问题。分析计算模块以电网边缘侧的终端设备和服务器为基础,利用边缘层计算任务分配优化模型与M-BiJOR算法对边缘计算任务卸载与资源分配进行优化,更加绿色化使用边缘算力。
猜你喜欢
昆钢科技(2022年2期)2022-07-08
当代水产(2021年10期)2022-01-12
通信技术(2021年9期)2021-10-03
建材发展导向(2021年23期)2021-03-08
铁道通信信号(2019年4期)2019-10-10
华人时刊(2018年15期)2018-11-10
科技创新导报(2016年26期)2017-03-13
通信产业报(2016年44期)2017-03-13
铁道通信信号(2016年3期)2016-06-01
雕塑(1999年2期)1999-06-28
