
一种双线性分段二分网格搜索SVM 最优参数方法∗
2020-11-02 09:00施皓晨肖海鹏周建江
计算机与数字工程 2020年9期
施皓晨 肖海鹏 周建江
(南京航空航天大学电子信息工程学院 南京 211106)
1 引言
支持向量机(Support Vector Machine,SVM)采用结构风险最小化原则,根据有限训练样本信息,在模型的学习能力和复杂性之间寻求最佳折衷[1],以获得良好的推广性能和较好的分类精确性。其核心思想是通过引入核函数,将在输入空间的线性不可分样本映射到高维特征空间,达到线性可分或近似线性可分[2]。
SVM 参数选择将直接影响分类器性能的优劣。目前,参数选择还只能凭借经验、实验进行搜索寻优,因此,如何选择最佳参数已成为研究SVM的一个重要分支[3]。常用的SVM 模型参数优选方法有双线性法[4],网格搜索法及其改进算法[5],双线性网格搜索法[6]等。双线性法是通过分析以RBF核的SVM 的渐近行为,指出学习精度高的核参数和惩罚因子组合(C,γ)集中出现在“好区”中的直线logγ=logC͂-logC,由此提出了一种双线性搜索最佳参数方法。它的优点是训练量小,缺点是对线性SVM 最佳参数C 的准确性依赖度很大。网格搜索法则是将C 和γ分别取M 和N 个值,对M×N个(C,γ)组合分别进行训练计算其正确率,选取M×N 个组合中正确率最高的作为SVM 模型的最佳参数。网格搜索法及其改进算法学习精度比较高,但是训练量很大。双线性网格搜索法结合了双线性法训练量小和网格搜索法学习精度高的优点,先利用双线性法得到最佳参数,然后再用网格搜索法在最佳参数附近进行网格搜索,获取SVM 模型的最佳参数。
在双线性网格搜索法基础上,利用分段二分思想(Segmented Dichotomy,SD),本文提出了一种快速寻优的双线性分段二分网格搜索法,在搜索段间分段地采用二分法,迭代求解出每段SVM 的最高正确率,已得到所对应的最佳参数;最后,找出所有最佳搜索段的SVM 最高正确率的最大值,其对应的最佳参数即为SVM模型的最终优化参数。
2 SVM模型最佳参数(C,γ)优化方案
2.1 RBF核参数对分类器的影响
SVM 模型有两个非常重要的参数:惩罚因子C与核参数γ。其中,惩罚因子是对误差的宽容度。核参数是SVM 选择RBF 函数作为核后,该函数自带的一个参数。
惩罚因子C 可在确定的特征子空间中调节分类器置信范围和经验风险的比例,以使分类器的推广能力达到最好[9]。它的选取一般由具体问题而定,不同特征子空间中最优化的C 不同。在确定的特征子空间中,C 值小表示对经验误差的惩罚小,分类器的复杂度小而经验风险值较大;C 取无穷大时则所有的约束条件都必须满足,这意味着训练样本必须要准确地分类。
惩罚因子C对SVM 性能的影响反映在:当C较小时错误率比较高;当C 增加时错误率急剧降低;继续增大C 时错误率的变化不明显,且当C 增加到一定值后,错误率不再变化。这就意味着,惩罚因子C 越高,越不能容忍出现误差,容易过拟合。C越小,容易欠拟合。C 过大或过小,SVM 分类的泛化能力变差。进而,SVM的复杂度达到特征子空间允许的最大值,所以,在这个区域中就可以通过核参数γ的变化来得到SVM的最优推广能力。
表4报告了城乡居民不同收入分位点下的断点回归结果。可以发现,扩招政策对城乡内部不同收入群体的影响差别显著。其中,城镇内部居民50%以下低收入组的教育收益率为5.4%,50%以上高收入组的教育收益率为4.1%,即扩招政策促使城镇内部教育收益率变动趋势趋同,但会使城镇内部高低收入群体的收入和教育出现分化,进而形成“马太效应”。同时,高校扩招政策会使农村内部居民不同收入群体的教育产生分化,对收入及教育回报率的影响为正但不显著。
通常情况下,在使用RBF 核来建立SVM 模型时,参数C 和γ的选择并没有一定的先验知识,必须做某种类型的模型进行参数搜索,使得分类器能正确地预测未知数据(即测试集数据)。采用交叉验证方法来提高预测精度是一种常用的做法。k折交叉验证是将训练数据集合分成k 个大小相同的子集。其中一个子集用于测试,其余k-1 个子集用于对分类器进行训练。这样,整个训练集中的每一个子集被预测一次,交叉验证的正确率是k 次正确分类数据百分比的平均值[8]。它可以防止过拟合的问题,具有一定的合理推广能力。
2.2 双线性分段二分网格搜索方法
本文所提出的SVM 模型参数优化性能将主要受到以下三个参数的影响:1)取样间隔值;2)C 的迭代精度;3)正确率迭代精度。在VC++和Matlab平台上,选用标准的UCI 数据库[7]中的Glass 数据集,采用控制变量法,从学习精度和训练量两方面分析这三个参数对算法可靠性的影响。实验结果如图1~4所示。
1)利用分段二分法搜索出线性SVM 最佳参数;
线性SVM 最佳参数[11]的准确性直接影响双线性法和双线性网格搜索法的学习精度,而搜索最佳参数过程中的训练量也直接影响算法的整体训练量,所以线性SVM 最佳参数的求解在学习精度和训练量两方面都对基于RBF 核的支持向量机最佳参数的选择起着决定性影响。
用传统二分法[12]搜索线性SVM 最佳参数时,设定C 的初始搜索范围,然后将搜索范围的中间值代入线性SVM 中计算错误率,反复迭代,达到预定的精度范围则停止搜索。但是由于错误率随C 的增大只是在整体上呈现降低的趋势,并不是随着C的增大而绝对单调递减。因此,简单的传统二分法很容易使得最佳参数的求解陷入局部最大值。
考虑到C 对错误率的影响特点,将利用分段的二分法来快速精确搜索线性SVM 最佳参数。首先,在C 的初始搜索范围内,每隔固定取样值求出线性SVM 的交叉验证正确率。由于错误率随着C的增大在整体上呈现降低的趋势,线性SVM 的最佳参数应该在最低错误率对应的C 值附近。而且,当固定取样值取值较小时,在这个固定取样值范围内错误率随着C 的增大绝对单调递减。所以,在最低错误率(即最高交叉验证正确率)对应的C 值附近,采用分段二分法搜索技术来寻找SVM 模型的最佳参数。具体步骤如下:
γ隐含地决定了数据映射到新的特征空间后的分布,γ越大,支持向量越少,γ值越小,支持向量越多。支持向量的个数又将影响训练与预测的速度。核参数γ的改变,实际上改变映射函数从而改变样本数据子空间分布的复杂程度,即线性分类面的最大VC 维[8],也就线性决定了线性分类面能达到的最小经验误差[10]。核参数γ对SVM 性能的影响表现在:γ在特定的范围内存在最小错误率。所以,通过对参数组合(C,γ) 的变化,可以得到SVM的最优性能。
1)对C 的初始搜索范围进行采样。设定C 的初始搜索范围和取样间隔值。在初始搜索范围内以取样间隔值对C 取样,形成若干个取样点,分别在这些取样点上计算线性SVM 的正确率。对于不同数据集,C的初始搜索范围和取样间隔值可变。
2)寻找满足一定条件的最高正确率对应的惩罚因子C。设定正确率迭代精度。找到1)中的最高正确率,在所有正确率中寻找与最高正确率的绝对差值小于正确率迭代精度的正确率,保存这些正确率及最高正确率对应的C 值。对于不同数据集,正确率迭代精度的取值可变。
3)形成用于搜索线性SVM 最佳参数的搜索段。将2)中C值中的最小值减去取样间隔值,记为Cmin ;将C 值中的最大值加上取样间隔值,记为Cmax 。这样C 的初始搜索范围就被缩小为Cmin,2)中的C值和Cmax 之间的若干搜索段。
4)二分法搜索各搜索段的线性SVM 最佳参数。在搜索段间分段采用二分法迭代求解每段线性SVM 的最高正确率以得到相应的最佳参数͂。设定C 的迭代精度,如果当前C 的搜索范围宽度不大于C 的迭代精度,则表示已经达到预定的精度,不需要在该搜索段进行更细致的二分。对于不同数据集,C的迭代精度取值可变。
5)从所有搜索段中寻找线性SVM 最佳参数。找出所有搜索段的线性SVM 最高正确率的最大值,其对应的最佳参数͂记为线性SVM 最佳参数。这样,就实现了在整个初始搜索范围内对线性SVM最佳参数的快速搜索,能避免陷入局部极大值的问题。
2.2.2 双线性分段二分网格搜索法求解RBF 核的最佳参数
结合双线性网格搜索法学习精度高和训练量小特点,利用分段二分法能快速、精确地求解最佳参数的优点,提出双线性分段二分网格搜索法。具体实现步骤如下:
信访评议制度是地方信访工作改革的重要成果,是信访工作机制创新的有益探索。目前海宁市出台了《海宁市信访评议团公开评议特殊疑难信访事项办法》(下称《办法》)和《海宁市信访评议员聘任管理办法》两个规范性文件对信访评议工作的开展进行规范,但由于法律对于信访评议制度并未予以确认,导致其缺乏效力,信访评议与法律间的有效衔接有待加强。
3)在2)中得到的最优参数(C,γ)旁的正负22范围内,以20.25为步长进行更精细的网格搜索,记录最高正确率对应的(C,γ),这就是基于RBF 核的SVM的最佳参数。
2)对于RBF 核的SVM,分别将1)中得到的,0.5代入直线方程logγ=log-logC中的C͂i,用满足方程的(C,γ)来训练SVM,根据得到的正确率,搜索到最优参数(C,γ);
3 实验结果与分析
2.2.1 分段二分法搜索线性SVM最佳参数
图1 表示的是在正确率迭代精度和C 的迭代精度固定的情况下,学习精度和取样间隔值之间的关系曲线。图1中正确率迭代精度固定为0.2,C 的迭代精度固定为300次。当取样间隔值为500次时学习精度为75.7%;当取样间隔值为1000次和2000次时学习精度为75.2%;当取样间隔值为3000次增加到4000 次时,学习精度从74.8%下降到74.3%。可见,当取样间隔值最小时学习精度最高,取样间隔值增加时学习精度在整体上呈现阶梯降低的趋势。
图2 表示的是在取样间隔值和正确率迭代精度固定的情况下,学习精度和C 的迭代精度之间的关系曲线。图2 中取样间隔值固定为2000,正确率迭代精度固定为0.2,C 的迭代精度从50 次开始取值。当C 的迭代精度在50 次~400 次的范围内,学习精度保持在75.2%;当C 的迭代精度增大到450 次时,学习精度下降为74.3%,之后学习精度趋于稳定。可见,当C 的迭代精度较小时学习精度比较高,且在一定范围内保持不变;当C 的迭代精度再增大时学习精度急剧降低;当C 的迭代精度增大到一定值后,它的变化几乎不影响SVM的学习精度。
图3 表示的是在取样间隔值和C 的迭代精度固定的情况下,学习精度和正确率迭代精度之间的关系曲线。图3 中取样间隔值取样间隔值固定为2000 次,C 的迭代精度固定为300 次。当正确率迭代精度为0.1 时学习精度为73.8%;当正确率迭代精度为4 时学习精度为76.2%;当正确率迭代精度在[0.1,4]之间变化时,学习精度阶梯增长。可见,当正确率迭代精度在一定范围内学习精度保持不变,随着正确率迭代精度的增长,学习精度在整体上呈现阶梯增长的趋势。
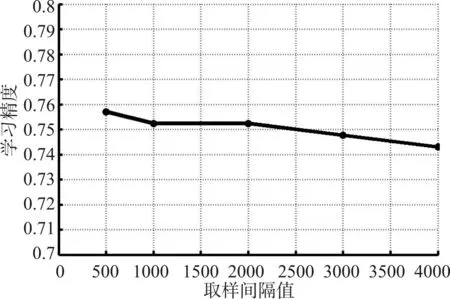
图1 固定正确率迭代精度和C的迭代精度不变,学习精度和取样间隔值的关系曲线

图2 固定取样间隔值和正确率迭代精度不变,学习精度和C的迭代精度的关系曲线

图3 固定取样间隔值和C的迭代精度不变,学习精度和正确率迭代精度的关系曲线

图4 固定正确率迭代精度不变,不同取样间隔值情况下训练量和C的迭代精度的关系曲线
图4 表示的是在正确率迭代精度固定的情况下,不同取样间隔值条件下训练量和C 的迭代精度之间的关系曲线。图4 中正确率迭代精度固定为0.2。对于同一取样间隔值,如取样间隔值固定为2000次时,训练量在整体上随着C的迭代精度的增长而减小;对于同一C 的迭代精度,如C 的迭代精度固定为500 次时,随取样间隔值从500 次增加到3000次,训练量从343次下降到319次。
分析图1~4 结果,我们不难发现,取样间隔值、C 的迭代精度和正确率迭代精度这三个参数要使得学习精度越高时,所造成的代价就是需要的训练量越大。所以,这两者不能在两方面同时实现对SVM 最优性能的要求。不过,我们也发现,Glass数据集使用本文提出的搜索方法能获得的最低学习精度为74.3%,最高训练量为346 次。而后期的比较实验,我们发现,使用双线性网格搜索法获得的学习精度为72.4%,训练量为382次。所以,利用分段二分法搜索线性SVM 最佳参数,不论如何设定取样间隔值、C 的迭代精度和正确率迭代精度,本文提出的搜索方法始终能在更小的训练量条件下,获得比传统的双线性网格搜索法更高的学习精度。
西风带又称暴风圈,位于副热带高气压带与副极地低气压带之间,即大约在南、北半球的35°~65°纬度,该地区的空气运动主要是自西向东,在对流层中上部和平流层下部[1-2]。常年西风不断,气旋频繁,平时最小风力大约7~8级,大多时候达到10~12级,船只航行极为危险,故又称为“魔鬼西风带”。西风带在南半球更为明显,为南极设置一道天然屏障,且是船只赴南极必经的最危险海域。
为了进一步验证本文提出的搜索方法优越性,针对UCI 数据库的Glass、PID、Vowel、Wine、Wdbc数据集,分别用双线性法、网格搜索法、双线性网格搜索法和本文提出的双线性分段二分网格搜索法搜索SVM 模型的最优参数,从学习精度和训练量两方面来对表1 和表2 的实验结果进行分析比较。其中,使用双线性法、双线性网格搜索法和本文方法搜索线性SVM最佳参数时,设置C的搜索范围为[0.1,1500];使用网格搜索法、双线性网格搜索法和双线性分段二分网格搜索法时,以20.25为步长对基于RBF核的SVM最优参数进行搜索。
陡河水库1976年震后修复时只把土坝恢复到41.0 m高程,未能按设计44.0 m高程实施,防洪标准偏低,1978年被水电部列为全国43座重点病险水库之一。1989年提高保坝标准建设,土坝加高3 m。首先对1970年震后修建的坝体回填质量在不同的断面钻孔取样进行物理力学试验,其结果满足设计要求。因此加高前仅将表层土清除,选与原坝料相同的土料进行坝体加高填筑。土方施工基本机械化,在土方填筑碾压后采用核子密度仪进行质检。经检验,土坝碾压干容重控制点1 159个,干容重皆远超过设计干容重1.75 t/m3的要求。
3.3.4推进厕所革命 支持长江经济带11个省(市)推进农村户用卫生厕所改造、加强农村公共卫生厕所建设、配套搞好农村厕所粪污处理。
表1 中列出使用四种搜索法得到的学习精度的实验比较结果。双线性分段二分网格搜索法与双线性法、网格搜索法、双线性网格搜索法相比,五个数据集获得的学习精度相对于其他三种方法均有不同程度的提高。其中,Glass 数据集的学习精度相对于双线网格搜索法提高了3%。
表2 中列出使用四种搜索法得到的训练量的实验比较结果。以PID 数据集为例,表中的333 代表使用双线性分段二分网格搜索法总的训练量,21代表使用分段二分法搜索线性SVM 最佳参数的训练量,40+272=312 代表使用局部双线性网格搜索法的训练量。可以看出,双线性分段二分网格搜索法在获得比网格搜索法和双线性网格搜索法更优学习精度的前提下,训练量有明显的减少。双线性分段二分网格搜索法的训练量比双线性网格搜索法平均下降了15%以上。

表1 学习精度比较结果

表2 训练量比较结果(训练SVM的个数)
从表1 和表2 可看出,提出的双线性分段二分网格搜索法与双线性网格搜索法相比,对于各种不同复杂程度的数据集,在训练量更小的情况下均能获得更高的学习精度。由于双线性网格搜索法本身综合了双线性法和网格搜索法的优点,训练量介于两者之问,学习精度几乎达到了网格搜索法的精度。因此,可以得出,通过双线性分段二分网格搜索法找到的最优参数使得SVM 具有更优性能,该方法相对于传统的三种搜索方法具有更好的性能,在实际模式识别应用中是有效性的。
即使在这样的情况下,扬州仍在坚守着,一天过去,伤亡过半,两天过去,妇女也走上战场。而有的人家知道抵抗无益,却又不愿投降,害怕女性被玷污,甚至出现了举家女性投井这种惨烈的事。四处是鲜血、尸体,但是扬州城内却没有出现抢掠,秩序井然有条。我被眼前的场景惊呆了,也不知道自己该何去何从。
(1) 构建判断矩阵。计算单排序时,不同因素之间的判断比较可简单量化为两两因素之间模糊对比,量化方法引入1~9标度法,并写成矩阵的形式,其标度及含义如表1所示。
融资方面,绍兴城投直面困难,克服困难.吸取2012年的成功经验,不断拓宽融资渠道,转变融资思路,更加注重政策性银行融资与直接融资.例如,抓好二期城投债的发行,积极申报发行中期票据、短期融资券、定向私募债券等,积极争取保障性住房贷款政策,积极争取资产注入,扩大资产规模等.
4 结语
SVM 参数选择将直接影响到分类器性能好坏。通过常用的双线性法、网格搜索法、双线性网格搜索法和本文提出的双线性分段二分网格搜索法搜索SVM 的最佳参数的对比实验,验证了本文提出的搜索方法针对不同复杂程度的数据集的SVM参数优化是有效的,能为机器学习提供一定的帮助。
继续深化农业种植结构调整。在对接河南省委、省政府“四优四化”要求的基础上,继续调整农业种植结构,扩大新增特色种植,大力发展新型产业。深化与河南省农科院、华大基因研究院等研究机构合作,强化优质小麦、谷子、花生等农作物新品种选育。
利用分段二分法搜索线性SVM 最佳参数时,如何根据实际数据集特点自适应设定最合适的取样间隔值等参数,目前仍处于试验阶段,需要在更广泛的数据集上展开应用研究。
猜你喜欢
理科爱好者(教育教学版)(2022年1期)2022-04-14
中学生数理化(高中版.高考理化)(2021年3期)2021-05-21
新课程·上旬(2019年1期)2019-03-18
教师·中(2017年3期)2017-04-20
体育时空(2017年2期)2017-03-28
体育时空·上半月(2017年2期)2017-03-09
未来英才(2016年13期)2017-01-13
体育时空(2016年9期)2016-11-10
试题与研究·教学论坛(2016年27期)2016-08-11
教学研究与管理(2014年4期)2014-05-16
