
基于全局上下文的特定舞蹈动作识别方法研究
2020-11-13 03:38毕雪超
微型电脑应用 2020年10期
毕雪超
摘要:为了提升机器视觉中特定舞蹈动作识别的性能,设计了基于全局上下文的特定舞蹈动作识别方法。该方法基于Hourglass结构,通过连接高低分辨率的特征图,将具备全局信息的深层特征图上采样与浅层特征融合,使得每一个阶段的高分辨率特征图均具有低分辨率的特征图表示,从而得到信息更丰富的高分辨率特征图表示,最终回归人体姿态热力图。在Balletto舞蹈视频数据库中的测试结果表明,相比基于CPN和基于Hourglass的算法,所提算法的AP值提高2.4%,AR提升了1.6%。
关键词:Hourglass;残差模块;向上连接;全局上下文信息;多尺度特征融合
中图分类号:TP391.9
文献标志码:A
ASpecificDanceActionRecognitionMethodBasedonGlobalContext
BIXuechao
(YouthLeagueCommittee,XianVocationalandTechnicalCollegeof
AeronauticsandAstronautics,Xian710089,China)
Abstract:Toimprovetheperformanceofspecificdanceactionrecognitioninmachinevision,aspecificdanceactionrecognitionmethodbasedonglobalcontextisdesigned.ThismethodisbasedonHourglassstructure.Byconnectingthehighresolutionandlowresolutionfeaturemaps,thedeepfeaturemapwithglobalinformationissampledandfusedwiththeshallowfeaturemap,sothatthehighresolutionfeaturemapofeachstagehasthelowresolutionfeaturemaprepresentation,soastoobtainthehighresolutionfeaturemaprepresentationwithmoreinformation,andfinallyreturntothehumanposturethermalmap.ThetestresultsinBallettodatasetshowthatcomparedwiththealgorithmsbasedonCPNorHourglass,theAPscoreandARscoreoftheproposedalgorithmareincreasedby2.4%and1.6%,respectively.
Keywords:Hourglass;residualmodule;upwardconnection;globalcontextinformation;multiscalefeaturefusion
0引言
特定舞蹈动作识别是人体姿态估计技术的一个重要应用领域[13],通过舞蹈动作识别技术可以帮助舞蹈演员纠正错误姿势,有助于智能化舞蹈辅助训练[4]。PfisterT等人[5]将人体姿态估计视为检测问题,通过回归人体姿态关键点的热力图来进行人体姿态估计。之后,采用人体各部件响应图来表达各部件之间空间约束的人体姿态估计方法被提出[6]。NewellA等人[7]提出了基于Hourglass的人体姿态估计算法,该算法可以获取多尺度特征同时具有更加简洁的结构。Openpose[8]实时检测多人2D姿态方法的主要原理是通过部分亲和域去学习将身体部位和对应个体关联。为了提升算法对于复杂关键点的检测性能,文献[9]采用一個全局网络检测简单关键点,然后通过RefineNet检测复杂关键点进行姿态估计,这种网络结构被称为CPN。本文基于Hourglass结构[10],设计了基于全局上下文信息的舞蹈动作识别算法,用于学习特定的复杂舞蹈动作识别。
1基于全局上下文的舞蹈动作识别
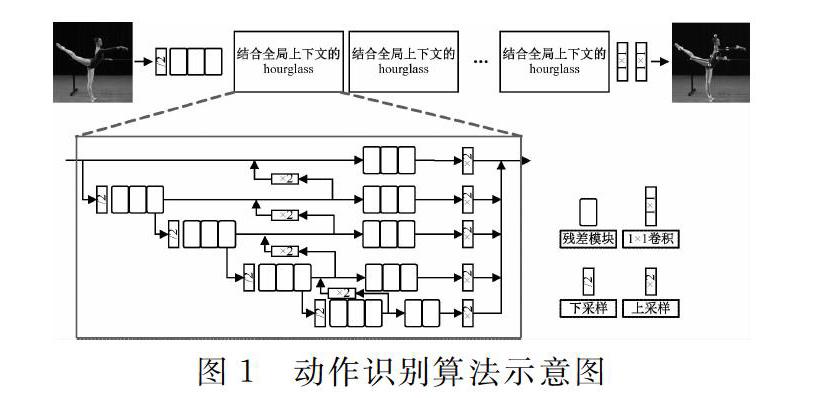
本文提出了一种结合全局上下文信息的架构,能够在整个过程中结合全局上下文信息并维护高分辨率的表示,结构如图1所示。
算法采用256×256的图片输入,首先进行下采样和三个残差模块;然后,经过若干个结合全局上下文信息的Hourglass结构;最后,通过两个连续的1×1卷积得到舞者的骨架关键点图。
1.1基于Hourglass的网络结构
基于Hourglass的模型通过串联高低分辨率的特征图,具有更优的对称性,可以融合多尺度特征[1112]。因此,本文采用基于Hourglass的模型作为基本网络来进行姿态估计。该模型通过将高分辨率到低分辨率的子网络串联起来,每个子网络形成一个阶段,由一系列卷积组成。相邻子网络之间存在一个下采样层,将分辨率减半,如式(1)。
f11→f22→…→fs-1,r-1→fs,r(1)
Hourglass主要由残差模块构成,如图2所示[13]。
残差模块一般由两条分支组成:第一分支主要为了增加深度与提取特征,通过两个1×1的卷积层和一个3×3的卷积层组成;第二分支核与常规残差模块不同,为了控制输入通道数和输出通道数。本文的残差模块通过输入通道数和输出通道数进行控制,可以对任意尺度图像进行操作。
与其他人体姿态估计的网络结构类似,Hourglass同样是从高分辨率特征图下采样至低分辨率,然后再上采样回到原来的分辨率,但Hourglass具有更加对称的容量分布,一阶结构如图3所示。
其包含两条支路、一条原分辨率特征图支路和一条降采样后的低分辨率特征图支路。原分辨率支路包含3个残差模块,用于高分辨率特征提取。该支路只改变特征图深度,不改变特征图尺度。第二条支路则先通过一个Maxpooling进行下采样,然后经历5个残差块,再上采样回前一个尺度并与第一支路的特征图进行融合。
1.2结合全局上下文的网络结构
舞蹈动作通常具有复杂且大幅度的变化,识别舞蹈动作姿态需要深度学习模型在提取特征时,抓住每个尺度信息的需求[14]。人的朝向、四肢的排列、相邻关节的关系均是需要从全局上下文信息进行推理识别,并对局部信息进行准确定位。为了使网络具备更优的全局上下文信息,本文对网络进行改进,设计了结合全局上下文的Hourglass,结构如图4所示。
基于Hourglass的网络是有序地从高分辨率到低分辨率连接各子网络进行构建。其中,每个Stage的每个子网络均包含多个卷积序列,且在邻近的子网络间会有下采样层,从而将特征分辨率减半。
本文将一个高分辨率的子网络作为第一个Stage。每次下采样后均将特征图从高分辨率到低分辨率逐一添加到子网络中,连接各个多分辨率特征,如式(2)。
f1,1←f1,1
fs,r+1←fs,r+fs+1,r+1,s≤r
fs,r+1←fs-1,r,s=r+1
r=1,2,3,4(2)
结合全局上下文的Hourglass通过图5给出的连接模块将低分辨率特征图融合到高分辨率特征图中,使得每一个尺度的特征图均包含其前层特征及额外的低分辨率特征。如图5所示。
其中,这些低分辨率特征图具有更加宽阔的感受野,包含全局上下文信息。
1.3模型训练
本文方法的输出仅采用模型输出的高分辨率特征表示来回归Heatmaps。Loss函数采用均方差误差,并对预测的Heatmaps和GroundTruthHeatmaps进行计算[15],而后者是通过以关键点GroundTruth坐标(x,y)为中心,采用1像素标准差的2DGaussian生成。
2试验和分析
算法在Balletto舞蹈视频数据库上进行测试,选取7000张作为训练集,其余图片作为测试集。
2.1评价指标
本文采用基于ObjectKeypointSimilarity(OKS)的评价指标对各关键点进行评估[16]。OKS的计算,如式(3)。
OKS=∑iexp-d2p22S2pσ2iδ
(vi>0)∑iδ(vi>0)(3)
本文对于模型准确度采用了AP、AP50、AP75、APM、APL、AR等几个指标,其中AP取值为OKS从0.50~0.95等10个位置的平均AP,AP50表示OKS为0.50时的AP;AP75表示OKS为0.75时的AP;APM表示中尺度目标的AP;APL表示大尺度目标的AP;AR表示平均召回率。此外,本文还对模型大小进行了分析,主要采用参数大小和浮点型运算量(FLOPs)进行分析。
2.2数据库评估
算法准确度分析结果,如表1所示。
本文方法从零开始训练,输入图像尺度为256×256,获得了70.3分。相比基于CPN的算法提高了2.5%,比基于Hourglass的算法提高了2.4%。这表明本文通过全局上下文信息及特定舞蹈动作提升识别准确度的方法有效。全局上下文信息有助于模型学习识别舞者各关键点的特征,从AP50和AP75也可以看出,本文方法相比其他两种算法提高了1%~2%。但对于不同尺度的舞者,该方法并未获取更优的准确度。在对于大尺度的舞者姿态识别时,本文方法的准确度略低于基于CPN的算法。但在中尺度的舞者图像中,该算法仍获得了1%的提高。大尺度的目标包含更丰富的信息,对于舞者动作识别更加简单,这使得3种方法的准确度差别较小。此外,本文方法的AR值比其他算法提高1.3%。
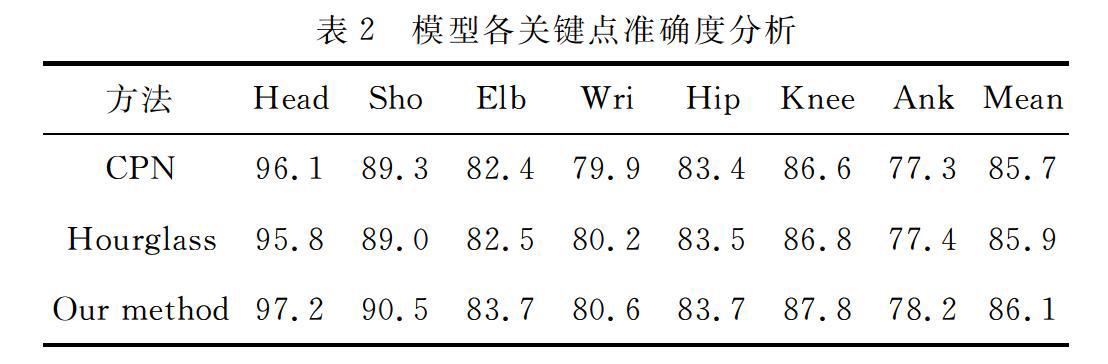
对物质姿态估计的PCK指標评估结果,如表2所示。
从表2中可知,本文方法的PCK分数达到了86.1%,优于其他算法,对于难度较大的一些关键点,本算法也获得了有效提升。
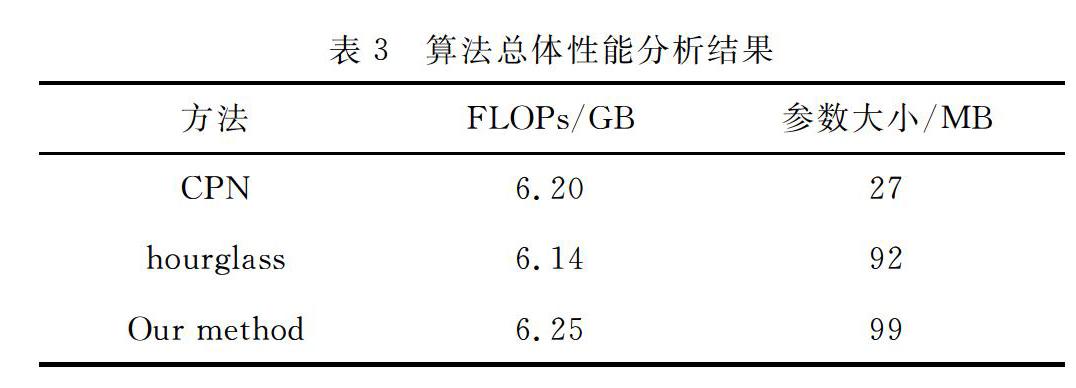
与其他算法的模型大小分析,如表3所示。
文中方法的FLOPs为6.25GB,略高于其他算法,而且参数量也略大于其他算法,说明该方法在提升准确度的同时也增加了运算代价。
本文算法对特定舞蹈动作识别的部分效果图进行展示,如图6所示。
该算法成功将大部分舞蹈动作的关键点进行识别。对于第一列第一幅图、第三列第二幅图中遮挡隐藏的关键点,本文算法可以成功检测。在第一列第二幅图、第三列第二幅图中舞者两腿出现交叉,但本算法能够准确检测出左右腿的关键点。另外,对于第二列第二幅图、第二列第三幅图和第四列第三幅图中舞者的一些大幅度动作,算法也可以成功检测出人体关键点。但对于第一列第三幅图,算法并未成功检测出左脚踝关节。经分析认为,该图中舞者动作尺度变化复杂,左腿几乎与左手重叠,这给人体关键点识别带来了困难。
3总结
为了获得更丰富的全局上下文信息,提升模型对舞者处于遮挡、交叉和大幅度动作的关键点检测性能,本文通过将低分辨率特征图上采样与高分辨率特征图结合的方式设计了一种特定舞蹈动作识别算法。测试结果表明,该算法具有比基于CPN和Hourglass的算法更好的检测精度。但该算法在对于一些剧烈的动作识别中仍存有不足,在后续的研究中将针对剧烈尺度变化的舞蹈动作识别算法进行改进。
参考文献
[1]邓益侬,罗健欣,金凤林.基于深度学习的人体姿态估计方法综述[J].计算机工程与应用,2019,55(19):2242.
[2]DangQ,YinJ,WangB,etal.Deeplearningbased2Dhumanposeestimation:Asurvey[J].TsinghuaScience&Technology,2019,24(6):663676.
[3]邢占伟.基于多特征融合的舞蹈动作识别方法研究[D].沈阳:辽宁大学,2017.
[4]任文.基于姿態估计的运动辅助训练系统研究[J].电子设计工程,2019,27(18):149152.
[5]PfisterT,CharlesJ,ZissermanA,etal.FlowingConvNetsforhumanposeestimationinvideos[C].InternationalConferenceonComputerVision,Boston,2015:19131921.
[6]WeiS,RamakrishnaV,KanadeT,etal.Convolutionalposemachines[C].ComputerVisionandPatternRecognition,Chicago,2016June2730:47244732.
[7]NewellA,YangK,DengJ,etal.StackedHourglassnetworksforhumanposeestimation[C].Amsterdam:EuropeanConferenceonComputerVision,Paris,2016October1114:483499.
[8]CaoZ,SimonT,WeiS,etal.RealtimeMultiPerson2Dposeestimationusingpartaffinityfields[C].ComputerVisionandPatternRecognition,Beijing,2016June2730:32103222.
[9]ChenY,WangZ,PengY,etal.CascadedpyramidnetworkforMultiPersonposeestimation[C].ComputerVisionandPatternRecognition,Shanghai,2017July2126:356363.
[10]YangW,LiS,OuyangW,etal.Learningfeaturepyramidsforhumanposeestimation[C].InternationalConferenceonComputerVision,Guangzhou,2017October2229:12901299.
[11]许政.基于深度学习的人体骨架点检测[D].济南:济南大学,2019.
[12]于景华,王庆,陈洪.基于动作评价算法的体感舞蹈交互系统[J].计算机与现代化,2018(6):6471.
[13]于华,智敏.基于卷积神经网络的人体动作识别[J].计算机工程与设计,2019,40(4):11611166.
[14]桑海峰,田秋洋.面向人机交互的快速人体动作识别系统[J].计算机工程与应用,2019,55(6):101107.
[15]马悦,张玉梅.一种基于模糊综合评价的人体动作识别方法[J].信息技术,2018(3):2733.
[16]陈甜甜,姚璜,魏艳涛,等.基于融合特征的人体动作识别[J].计算机工程与设计,2019,40(5):13941400.
(收稿日期:2020.03.11)
