
基于改进模糊均值聚类的汉语言学习用户学习行为模式研究
2020-11-13 03:38年晴
微型电脑应用 2020年10期
年晴

摘要:为了实现汉语言在线学习用户学习行为聚类分析,针对FCM聚类结果易受其初始聚类中心选择的影响,提出一种基于IHSFCM的汉语言学习用户学习行为聚类分析。选择参与维度、专注维度、规律维度、交互维度和学习成绩等作为学习行为的分析指标,学习者层次分为5个等级,分别为优秀、良好、中、合格和差。与HSFCM、SVM和决策树对比发现,文中算法IHSFCM具有更高的聚类准确率和更快的收敛速度以及更低的适应度,为学习者层次划分和优化课程学习提供了新的方法。
关键词:在线学习;汉语言;学习行为;模糊均值聚类;和声搜索算法
中图分类号:TP391
文献标志码:A
StudyontheLearningBehaviorModelofChineseLanguage
LearnersBasedonImprovedFuzzyCmeansClustering
NIANQing
(
SchoolofHumanitiesManagement,ShanxiUniversityofTraditionalChineseMedicine,Xian712046,China
)
Abstract:InordertoanalyzethelearningbehaviorofChineselanguageonlinelearners,duetoFCMclusteringresultsareeasilyaffectedbytheinitialclustercenterselection,thispaperpresentsaclusteringanalysisofChineselanguagelearningbehaviorbasedonIHSFCM.Participationdimension,attentiondimension,regularitydimension,interactiondimensionandlearningachievementareselectedastheanalysisindexesoflearningbehavior.Thelearners'levelisdividedinto5grades,i.e.,excellent,good,medium,qualifiedandpoor.ComparedwithHSFCM,SVManddecisiontree,theIHSFCMhashigherclusteringaccuracy,fasterconvergencespeedandlowerfitness.Itprovidesanewmethodforlearnerstodivideandoptimizecourselearning.
Keywords:onlinelearning;Chineselanguage;learningbehavior;fuzzyCmeansclustering;harmonysearchalgorithm
0引言
隨着我国经济的快速发展和综合国力的不断上升,对外交流和对外贸易的深度和规模不断加深和扩大以及网络教学和在线课程的飞速发展,汉语言学习的人数和规模不断增加和扩大,积累了大量的学习数据,如何利用这些学习数据挖掘出学习数据的内在价值更好地服务于汉语言的教与学,引起了广泛关注和研究[12]。因此研究汉语言学习用户的学习行为对优化课程教学和完善课程评估具有重要意义。
模糊C均值(FuzzyCmean,FCM)聚类[3]是运用隶属度确定每个数据样本类别的方法,具有效率高、计算量小的优点,然而FCM聚类结果易受其初始聚类中心选择的影响,本文将和声搜索算法(HarmonySearch,HS)应用于FCM初始聚类中心的选择,提出一种基于IHSFCM的汉语言学习用户学习行为聚类分析。研究结果表明,IHSFCM具有更快的收敛速度和更低的适应度,效果较HSFCM更优,为汉语言课程学习优化提供科学决策的依据。
1改进的HS算法
(1)随机位置更新
若HS算法中最差和最好和声分别为xworst以及xbest,将xworst视为基向量,则较优和声通过学习xbest调节出来,本文提出一种基于随机位置更新的方法如式(1)—式(2)。
xnewi=xri+rand×(xd-xri)
(1)
xd=F×xbesti-xri,r∈(1,2,…,HMS)
(2)
若xr
(2)反向学习
为扩大HS算法的搜索空间,将反向学习[45]引入HS算法,反向学习策略如式(3)。
xnewi=
xUi+xLi-xri,rand≤0.5
xri,其他
(3)
(3)小概率变异
HS算法中的小概率变异操作如式(4)。
xnewi=xLi+rand×(xUi-xLi)
(4)
如果rand≤Pm,则进行小概率变异,取Pm=0.005。
(4)修正音调微调概率
音调微调概率PAR可设计如式(5)。
PARt+1=PARmax-PARminT·t+PARmin
(5)
式(5)中,PARmax、PARmin为音调微调概率的最大值和最小值;PARt+1为第t+1次的音调微调概率。
改进HS算法流程,如图1所示。
2基于IHSFCM聚类
2.1学习行为分析指标
为实现汉语言学习用户学习行为的分析,在参考文献[68]基础上,选择参与维度、专注维度、规律维度、交互维度和学习成绩等作为评价指标,详细评价指标,如表1所示。
2.2FCM聚类
假设样本数据x={x1,x2,…,xn},样本数据为n个,每个元素包含d个属性。FCM聚类数目为C(2≤C≤n),聚类中心W={w1,w2,…,wC}。由于FCM模糊聚类的每个元素类别不能被严格划分到具体的某一类别之中,所以令μik为第k个元素属于第i类的隶属度,其中
∑Ci=1μik=1,μik∈[0,1]。
FCM模糊均值聚类的目标函数定义为:
minJm(U,W)=∑nk=1
∑Ci=1μbikd2ik
(6)
式中,b为指数权重,文中取b=2;U为隶属度矩阵;dik=||xk-wi||表示元素xk与类中心wi二者之间的欧式距离。FCM模糊均值聚类的中心思想就是不断调整(U,W)使得目标函数Jm(U,W)最小。FCM模糊均值聚类的迭代步骤为:
Step1:设定聚类数目C(2≤C≤n)和指数权重b,并随机初始化聚类中心矩阵W(0),令迭代次数l=0;
Step2:计算隶属度矩阵U;
u(l)ik=
1/∑Cj=1(dik/djk)2b-1,dik>0
1,dik=0
(7)
Step3:修正聚类中心W;
w(l+1)i=∑nk=1(μ(l)ik)bxk∑nk=1(μ(l)ik)b
(8)
Step4:对于给定阈值ε>0,若J(l)m-J(l-1)m≤ε,则FCM算法结束,此时对应的最优聚类中心W(l)=w(l)1,w(l)2,…,w(l)C;反之,l=l+1,返回Step2。
2.3IHSFCM聚类
IHSFCM聚类思想:先随机产生几组聚类中心点,运用IHS算法的思想变化区域中心点计算适应度,淘汰适应度低的中心点和产生新的中心点,重新迭代计算,如此反复,直到满足结束条件为止,算法流程图,如图2所示。
基于IHSFCM的汉语言在线学习用户学习行为聚类分析算法可以具体详细地描述为:
Step1:读取汉语言在线学习用户学习行为分析指标数据;
Step2:初始化HS算法参数:创作的次数T、声记忆库的个数HMS、音调微调的概率PAR、音调微调的带宽bw以及和声记忆库保留的概率HMCR;
Step3:初始化和声记忆库;
Step4:生成新和声;
Step4:更新和声记忆库:根据适应度函数(6)评价Step3中的新解,若比HM中的函数值最差的一个好,则更新至HM中;
Step5:重复Step3和Step4,直到满足终止条件,输出FCM最优聚类中心,并将FCM最优聚类中心带入FCM模型进行汉语言在线学习用户学习行为聚类。
3实证分析
3.1数据来源
为了验证本文算法的有效性,选择网易公开课《汉语言文字学类课程导论》在线课程学习数据为研究对象[1213],将学习者层次分为5个等级,分别为优秀、良好、中、合格和差,不同学习者类型数据分布,如表2所示。
3.2评价指标
为了说明汉语言在线学习用户学习行为聚类分析的效果,评价指标选择聚类
准确率T和误判率F。
(1)准确率T:如果学习者类型被正确聚类的数量为A,而学习者类型的实际数量为B,则学习者类型聚类的准确率如式(9)。
T=AB×100%
(9)
(2)误判率F:如果学习者类型是第i类的实际数量为H,而将第i类学习者类型误判为第j类学习者类型的数量为G,则学习者类型判断的误判率如式(10)。
Fij=GH×100%
(10)
3.3实验结果
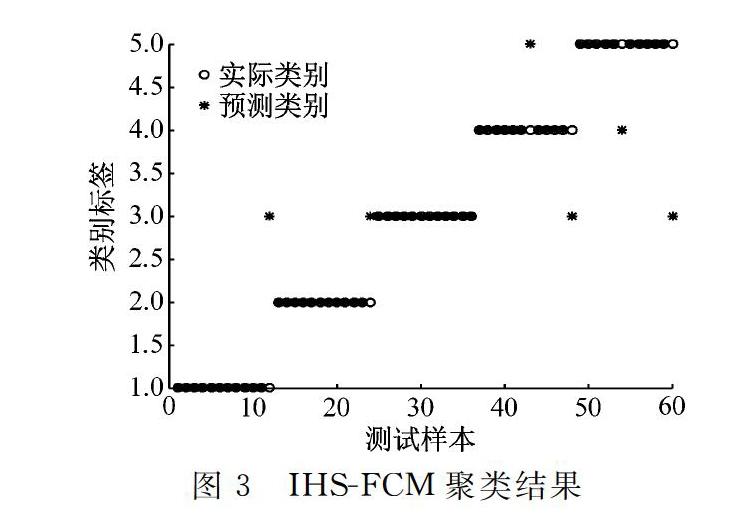
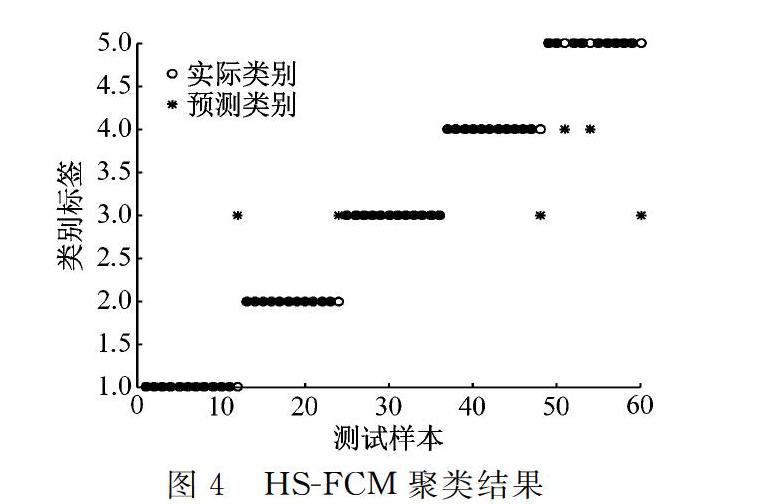
为了验证汉语言在线学习用户学习行为聚类算法的效果,将本文算法IHSFCM和HSFCM[14]、SVM[15]和决策树[1617]进行对比,如表3和图3图7所示。
IHS算法参数设置为:种群规模为10,最大迭代次数为100,聚类结果如表3所示。IHSFCM和HSFCM收敛曲线
对比如图7所示,由图7可知,IHSFCM具有更快的收敛速度和更低的适应度,效果较HSFCM更优。
图3图7中,“*”表示学习者层次的预测类别,“○”表示学习者层次的实际类别,通过对比展示可以直观地显示学习者层次聚类结果和实际学习者层次类别,其中1、2、3、4、5分别表示学习者层次为优秀、良好、中、合格和差。当“*”和“○”重合时,学习者层次的预测类别和实际类别一致,说明聚类正确;当“*”和“○”不重合时,学习者层次的预测类别和实际类别不一致,此时学习者层次聚类错误。由表3和图3图6可知,IHSFCM的聚类准确率和误判率分别为99.42%和0.58%,优于HSFCM的96.27%和3.73%,SVM的96.40%和3.55%和決策树的92.30%和2.70%。与HSFCM、SVM和决策树对比发现,本文算法IHSFCM具有更高的聚类准确率,为学习者层次划分和优化课程学习提供了新的方法。
4总结
为了实现汉语言在线学习用户学习行为聚类分析,针对FCM聚类结果易受其初始聚类中心选择的影响,提出一种基于IHSFCM的汉语言学习用户学习行为聚类分析。研究结果表明,IHSFCM具有更快的收敛速度和更低的适应度,效果较HSFCM更优,为汉语言课程学习优化提供科学决策的依据。然而,由于本文学习行为分析指标可能考虑不够全面,导致聚类效果存在适应性较差的缺点,后续将考虑更多因素的在线学习行为聚类分析,从而提高学习行为分析模型的准确性和适用性。
参考文献
[1]
胡艺龄,顾小清,赵春.在线学习行为分析建模及挖掘[J].开放教育研究,2014,20(2):102110.
[2]范洁,杨岳湘,温璞.C4.5算法在在线学习行为评估系统中的应用[J].计算机工程与设计,2016(6):946948.
[3]王法玉,姜妍.基于自组织神经网络和模糊聚类的校园无线网用户学习兴趣度行为分析[J].计算机应用研究,2018,35(1):1115.
[4]刘思远.一种新的多目标改进和声搜索优化算法[J].计算机工程与应用,2010,46(34):2730.
[5]陈春,汪沨,刘蓓,等.基于基本环矩阵与改进和声搜索算法的配电网重构[J].电力系统自动化,2014,38(6):5560.
[6]李爽,王增贤,喻忱,等.在线学习行为投入分析框架与测量指标研究——基于LMS数据的学习分析[J].开放教育研究,2016,22(2):7990.
[7]曹建芳,郝耀军.基于并行AdaboostBP网络的大规模在线学习行为评价[J].计算机应用与软件,2017,34(7):267272.
[8]陈志雄.基于蓝墨云班课的语文在线学习行为数据分析——中职语文混合式学习在线学习行为的数据挖掘与学习分析[J].现代职业教育,2018(11):2426.
[9]李小娟,梁中锋,赵楠.在线学习行为对混合学习绩效的影响研究[J].现代教育技术,2017(2):8086.
[10]吴林静,劳传媛,刘清堂,等.网络学习空间中的在线学习行为分析模型及应用研究[J].现代教育技术,2018,28(6):4754.
[11]刘冰,李彦敏.SPOC学习者在线学习行为特征分析——基于互动视角[J].集美大学学报(教育科学版),2019,20(1):3338.
[12]陈鹏宇,冯晓英,孙洪涛,等.在线学习环境中学习行为对知识建构的影响[J].中国电化教育,2015(8):5963.
[13]宗阳,陈麗,郑勤华,等.基于在线学习行为数据的远程学习者学业情绪分析研究——以Moodle平台为例[J].开放学习研究,2017(6):1120.
[14]宗阳,郑勤华,陈丽.中国MOOCs学习者价值研究——基于RFM模型的在线学习行为分析[J].现代远距离教育,2016(2):2128.
[15]孔丽丽,马志强,易玉何,等.在线学习行为影响因素模型研究——基于行为科学理论的评述[J].开放学习研究,2017,22(5):4653.
[16]王士霞.基于决策树的在线学习行为分析[J].河南科技学院学报(自然科学版),2015,43(5):6770.
[17]顾倩颐.基于在线学习行为的个性化学习需求智能挖掘技术研究[J].软件导刊,2015,14(12):1214.
(收稿日期:2020.03.24)
猜你喜欢
海风(2022年2期)2022-06-09
语文建设(2020年10期)2020-11-06
中国远程教育(2016年11期)2016-12-27
中国教育技术装备(2016年20期)2016-12-12
新教育时代·教师版(2016年31期)2016-12-07
中小企业管理与科技·下旬刊(2016年10期)2016-11-18
价值工程(2016年29期)2016-11-14
电脑知识与技术(2016年24期)2016-11-14
大学教育(2016年9期)2016-10-09
青年文学家(2016年5期)2016-04-27
