
基于校园卡学生消费行为的分析与研究
2020-11-13 03:38张亮
微型电脑应用 2020年10期
关键词:数据挖掘


摘要:以校园一考通系统为依托,对学生消费数据记录开展分析和研究。首先对学生基础消费进行数据处理,通过数据清洗和集成,完成归约,然后再利用Kmeans算法对学生消费行为聚类分析,分析系统内数据的隐含特征规律,为今后的贫困生资助管理工作中进行数据分析与辅助决策有一定的指导意义。
关键词:数据挖掘;Kmeans算法;消费记录;校园卡
中图分类号:TP301
文献标志码:A
ResearchandAnalysisofStudentConsumingBehavior
BasedonCampusCardsofStudents
ZHANGLiang
(
NetworkInformationCenter,ChinaUniversityofPetroleum(EastChina),Qingdao266500,China
)
Abstract:Thepaperresearchesstudentconsumptiondatabasedoncampuscards.Consumptionrecordsarepreprocessed,includingdatacleaning,dataintegrationandtransformation,datareduction.ThroughtheKmeanscluster,studentconsumptionbehaviorsareanalyzed,andthehiddencharacteristicsofdatainthesystemarediscovered.Thepaperhasimportantguidingsignificancefordataanalysisandauxiliarydecisionmakingofthesepoorstudents.
Keywords:datamining;Kmeansalgorithm;consumptionrecords;campuscard
0引言
隨着大型数据库的技术成熟以及普及应用,数据挖掘是当前学术界的热点话题。近年来,基于卡片应用的校园一卡通[13](以下简称校园卡)系统的得到快速的发展,并广泛应用于各大高校,生成了的大量的信息数据,用户的用卡痕迹通过这些数据被记录下来,用户的行为习惯可以通过分析这些数据被反映出来。
在各高校,国家每年通过勤工俭学岗位、贫困生补助等方式,为困难学生提供大量的助学金、贷款和工作岗位。由于认定涉及到多方面的无法衡量的因素,学校仅仅通过学生提交的相关贫困证明等非量化方式进行判定,贫困生的鉴别在各高校都是一个难题。如果鉴别不准确,会造成国家资助工作不到位,教育资源分配出现偏差。通过数据分析算法,对大学生校内消费记录进行整理、分类、预测,从而整体反应学生在校消费情况,形成量化的评判标准,为今后的贫困生资助管理工作提供可靠的数据支持,辅助完成贫困生的相关工作。
1校园卡消费数据预处理
在进行数据挖掘或者数据分析之前,需要对“脏数据”数据进行数据预处理,一般采用数据清理、数据集成、数据变换、数据规约等方式[46],已获得更高的挖掘效率和更好的挖掘效果。
1.1数据清洗
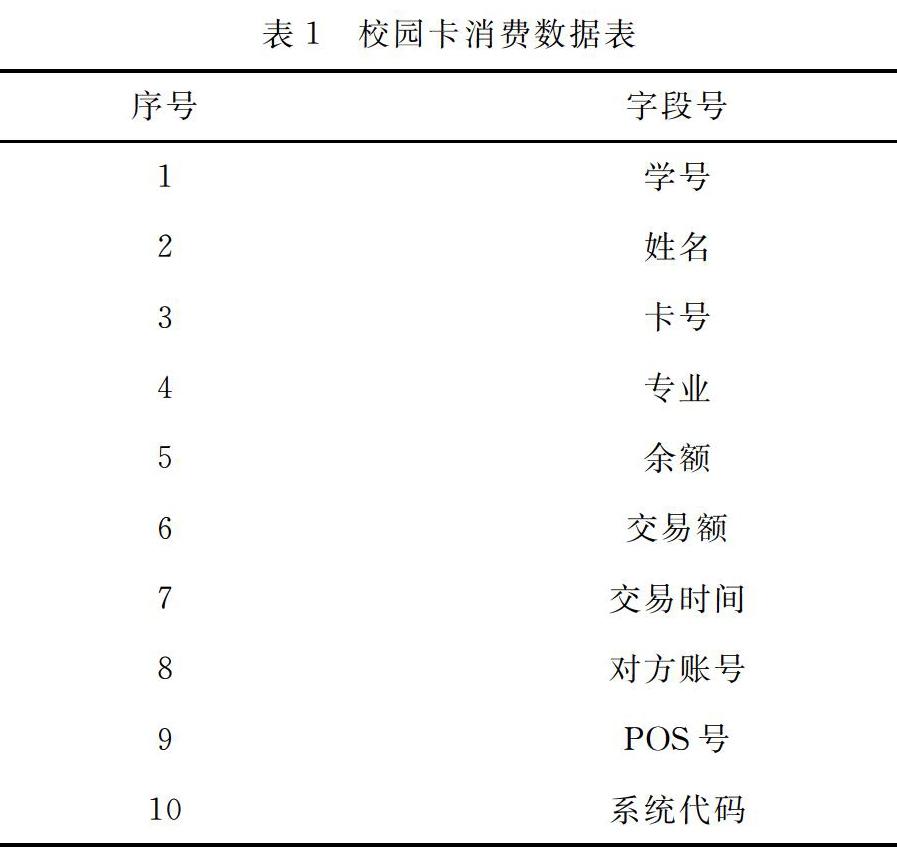
最初获得的原始数据往往存在很多冗余、含噪声、不一致或者不完整的数据,也就是常说的“脏数据”,因此需要对数据进行清洗。数据预处理主要去处可忽略的字段、忽略空缺记录、可处理噪声的数据、可删除的数据等。由于部分校园卡用户,如教职工、研究生等,消费时具有很强的随机性和离散型,因此,本文选取计算机科学与技术专业在校本科生2017年6月1日2019年6月1日两年的校园卡消费流水记录作为样本。结合校园卡系统的后台数据库表导出校园卡消费数据表,表中包含的字段有学号、姓名、卡号、专业、余额、交易额、交易时间、对方帐号、POS号,系统代码。为了保护隐私,对部分属性做了脱敏和隐私处理。
通过对数据进行分析,由于一些学生休学、退学、服兵役、开出等原因,这些数据的清理对不会对整体造成影响。经过预处理,一共得到227538条有效数据。
1.2数据集成和变换
预处理后的数据不一定适合数据挖掘的使用,因此需要对数据进行集成和变换,以便能够直接为数据挖掘所使用。本文研究数据主要涉及教务系统数据库和校园卡消费流水数据库,因此需要将两个数据库中提取出的数据项整合到一起,组成新的数据集环境,并经过详细对比和筛选解决数据不一致和数据冗余等问题。
本文对数据变换主要侧重对消费总金额进行离散化处理,把来自不同源的数据统一为标准格式,进行数据泛化,将不同的消费记录对应相当的等级。例如将消费记录日期格式转换成数值型的日期格式。
1.3数据归约
数据归约是指将数据库中的海量数据进行归约,本文是对校园卡的消费数据进行数据归约。通过分析,数据存储表中很多属性与本文的研究没有关联,可以通过删除与挖掘目标不相关的属性减少数据量,还有一些属性可以被少量属性替代。数据归约前后的对比,如表1、表2所示。
2核心算法
2.1基于Kmeans的聚类分析
Kmeans聚类算法一种动态硬聚类算法,是一种基于静态数据对象间相似度的,以实现类间独立、类内紧凑的目的。本节将使用Kmeans算法进行聚类分析[78],聚类结果受到随机选取初始聚类中心点的影响,有可能导致出现局部最小的情况,因此本文通过加权两个数据点间的欧式距离,来衡量数据点的相似性,初始聚类中心通过目标价值函数的大小排序得到,聚类算法的具体过程如下:
(1)聚类初始中心数据点有系统随机选择选定
数目k′(k′>k)个;
(2)读取并各自计算数据集中的其余数据点与k′个初始聚类中心的赋权欧式距离,按照距离的不同从大的开始排列,把距离最小值点分割到相应类别;
(3)对k′个类别的赋权目标价值函数值δi进行计算,δi值按照越来越大的层级排序,取前k个δi值对应的聚类中心归纳为初始聚类中心;
(4)依据最小相似度的原则,将每个对象与这k个对象进行相似度的比较,并分别分配到以这k个对象为中心所代表的类中;
(5)采用算法选取非中心点Orand;
(6)用Orand作为Ok替换,形成总代价S;
(7)对于每个类,假如,S<0,用Ok被Orand代替,该类的中心在进行重新计算;
(8)依照步骤(4)(5)的迭代N次,若收敛或中心点数据一致无波动,结束过程;
(9)聚类算法结束,获得最终模型,明确聚类中心。
开始时规定准则函数、迭代次数,考虑算法的成本,迭代次数等于5。为了判断函数收敛性,确定准则函数为均方差方法,作以下规定如式(1)。
E=∑ki=1∑x∈Cix-x2
(1)
其中误差总和做平均即是E,x是已知的对象。x是类Ci的平均值。
3数据分析
本文将利用Kmeans算法对消费总金额进行聚集[910],通过5次的迭代聚类3个簇的聚类结果,如图1所示。
依据消费金额以年为单位将学生聚集为三类,即高消费、中等消费、低消费,此时得到的聚类中心为586.32、372.75、203.65。
根据聚类效果图绘制圆饼图,如图2所示。
依据Kmeans算法分析的结果,可以将所有样本分成三簇,具体分布如表3所示。
根据对计算机科学与技术专业2016级本科生校园卡聚类情况进行分析,可以得出處于低消费水平的学生占29%。
依据校园卡的学生消费水平的分析情况,学院老师可以了解一些低消费水平学生的情况,在发放助学贷款、助学金或者申请勤工俭学等助学岗位时给予优选考虑。
4总结
本文完成了计算机科学与技术专业本科生的刷卡消费数据进行挖掘的初步探索,首先对校园卡中的消费记录进行预处理,包括数据清洗、数据集成和变换、数据归约,然后再利用Kmeans算法对学生消费行为聚类分析,分析系统内数据的隐含特征规律,依据学生的消费水平为学院贫困生量化评定与资助、贫困等级的界限划分提供科学的、可靠的数据支持。
参考文献
[1]
刘志宏,喻晓旭.基于数据挖掘的校园一卡通消费行为分析[J].信息记录材料,2018,19(12):8990.
[2]陈锋.基于校园一卡通系统的高校用户就餐消费行为分析与数据挖掘[J].中国教育信息化,2014(9):4749.
[3]ADutt,MAIsmail,THerawan.Asystematicreviewoneducationdatamining[J].IEEEAccess,2017,5(99):1599116005.
[4]纪系禹,韩秋明,李微,等.数据挖掘技术应用实例[M].北京:机械工业出版社,2009.
[5]胡秀.数据挖掘中数据预处理的研究[J].赤峰学院学报(自然科学版),2015,31(3):56.
[6]于琦.Web日志挖掘中的数据预处理研究[J].河南科技,2018(7):1820.
[7]陈艳红.高校信息系统中的数据挖掘与学生行为预警分析研究[D].武汉:湖北民族大学,2019:2930.
[8]张亮,赵娜.高校新生社团推荐系统的开发及设计[J].计算技术与自动化,2016,35(2):8184.
[9]郭鹏.基于校园一卡通数据的学生消费行为与成绩的关联性研究[D].西安:西北农林科技大学,2019:3134.
[10]张四海,李珊珊.校园一卡通消费行为数据分析与研究[J].北京联合大学学报,2019,33(1):4749.
(收稿日期:2020.01.20)
猜你喜欢
中国教育信息化·高教职教(2022年4期)2022-05-13
西部交通科技(2021年9期)2021-01-11
商情(2018年25期)2018-07-08
电子技术与软件工程(2018年1期)2018-03-22
速读·下旬(2016年8期)2017-05-09
电子技术与软件工程(2016年24期)2017-02-23
哈尔滨理工大学学报(2016年2期)2016-09-12
中国信息化·学术版(2013年1期)2013-05-28
国外科技新书评介(2009年12期)2009-05-31
新媒体研究(2009年3期)2009-03-30
