
基于Hadoop云计算平台的构建
2020-12-25 03:16倪星宇
微型电脑应用 2020年12期
倪星宇
(上海交通大学 电子信息与电气工程学院, 上海 200240)
0 引言
在智能化生产的时代,企业急需寻求合适的分布式解决方案[1]来应对不断扩大和更新的业务,管理日趋复杂的异构环境,实现各种设备、网络环境等之间的集成。在工业生产中,如汽轮机厂、核电厂等,在大数据环境下,分布式架构还可用于故障诊断、远程运维、远程配置等。
云计算[2]是分布式计算的一种发展,现在企业推出了如阿里云、腾讯云等商业云平台,而Hadoop是Apache的一个开源分布式框架,为了承接智能算法的实现,以此为基础设计一个云计算平台。
1 Hadoop
Hadoop[3-5]是一个能够对大量数据进行分布式处理的开源软件框架,主要由HDFS、MapReduce等组件组成,这两个组件是最重要的也是最基础的。
HDFS:高容错性的分布式文件系统。采用主/从结构,可以被广泛的部署于廉价的PC之上,用于存储海量数据。
MapReduce:执行框架。是分布式并行数据处理的编程模型,用来执行上层MapReduce程序。
2 云计算平台的构建
2.1 服务器配置
实验环境为一个分布式集群,所有的服务器均使用的是Ubuntu16.04系统,一共三台计算机,主机名分别为master,slaver1,slaver2。在构建集群之前,由于Hadoop需要JDK作为支持,在系统安装完毕之后,需要安装最新版本的JDK,输入sudo gedit/etc/profile配置所有的用户环境变量,更改环境变量之后,输入source/etc/profile 使得命令(环境变量)立即生效。重启计算机,终端下java -version检查Java环境搭建情况,如图1所示。

图1 JDK信息
2.1.1 配置hosts文件
输入ifconfig可以查询各服务器的IP地址,输入sudo gedit /etc/hosts,将三台服务器的IP地址和主机名添加进去(三台服务器都需要配置)。
配置hosts文件是为了服务器之间可以进行通信,可以ping通,如图2所示。

图2 hosts文件
2.1.2 配置ssh及master免密登录
安装ssh(输入sudo apt-get install ssh),包括openssh-server和openssh-client(三台服务器都需要安装)。
在master上操作如下。
输入ssh-keygen -t rsa安装完成,生成id_rsa(密钥)和id_rsa.pub(公钥)两个文件;
将id_rsa.pub添加到authorized_keys(输入cp id_rsa.pub authorized_keys),authorized_keys存放所有公钥,这时就可以免密访问localhost (ssh localhost)。
在slaver1上操作如下。
将在master主机上生成的id_rsa.pub通过命令
scp hadoop@master: ~/.ssh/id_rsa.pub ~/.ssh/slaver1_rsa.pub
复制到slaver1主机上,并命名为slaver1_rsa.pub。
对slaver2进行相同的复制命令。
从master得到的密钥加入到认证,对slaver2主机进行相同的操作。
cat ~/.ssh/slaver1_rsa.pub >> ~/.ssh/authorized_keys
现在就可以在master上对slaver1和slaver2进行免密登录,如图3所示。

图3 master免密登录验证
2.2 Hadoop安装及配置
使用的Hadoop版本的是hadoop-2.7.7,这里只需要将master主机的Hadoop配置好,再复制到另外两台slaver上即可。在这之前需要做的准备是修改profile文件,配置好环境变量,需要在三台服务器上操作,不可使用复制命令,需单独操作,如图4所示。

图4 profile文件
2.2.1 配置slaves文件
slaves文件保存的是集群中slave的主机名,需进行修改,如图5所示。

图5 slaves文件
2.2.2 配置hadoop-env.sh
hadoop-env.sh:添加Java安装的地址即可,如图6所示。

图6 hadoop-env.sh文件
2.2.3 配置core-site.xml
core-site.xml文件中fs.default.name将master主机设置为namenode,hadoop.tmp.dir配置了Hadoop的一个临时目录,用来存储每一次运行的job的信息,如图7所示。

图7 core-site.xml文件
2.2.4 配置hdfs-site.xml
文件中dfs.replication 是设置文件副本数的,集群有两个datanode,因此此处设置副本数为2,如图8所示。
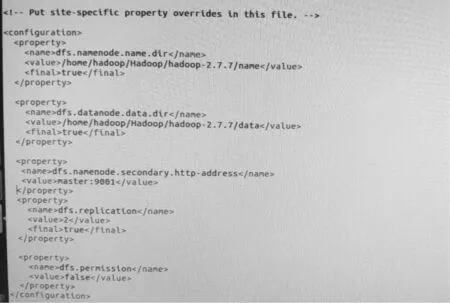
图8 hdfs-site.xml文件
2.2.5 配置mapred-site.xml
设置master主机在9001端口执行jobtracker,如图9所示。
2.2.6 Hadoop启动验证
通过命令
scp -r /home/hadoop/Hadoop/hadoop-2.7.7 hadoop@slaver1:/home/hadoop/Hadoop
scp -r /home/hadoop/Hadoop/hadoop-2.7.7 hadoop@slaver2:/home/hadoop/Hadoop
拷贝到两台slaver的相同路径中。
在master节点上输入hadoop namenode -format,格式化NameNode。
在sbin目录下,source start-all.sh启动,在三台计算机上执行jps,如图10所示。
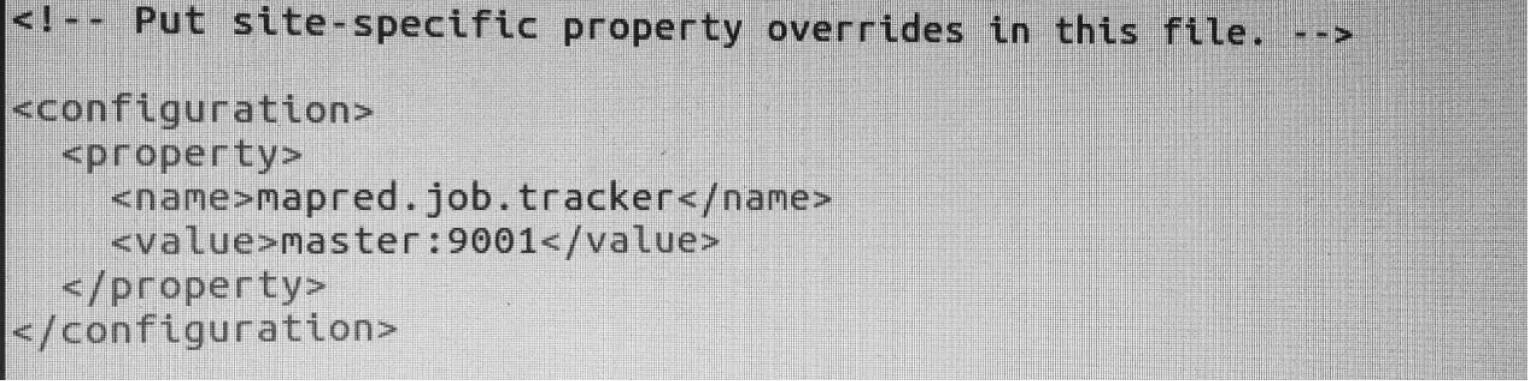
图9 mapred-site.xml文件
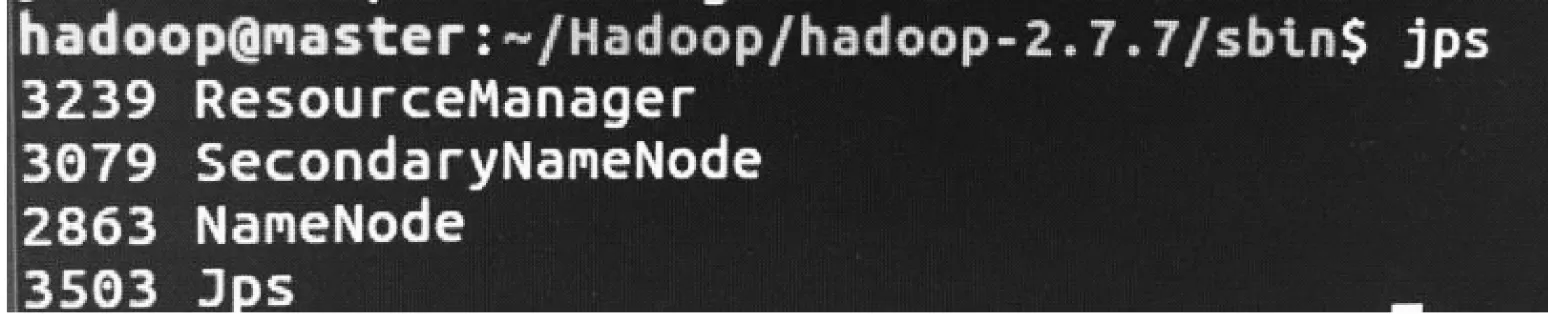
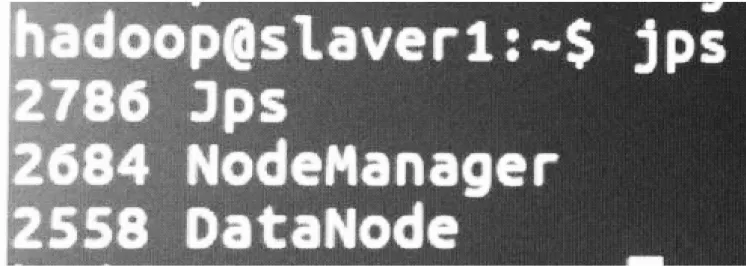

图10 启动Hadoop
则表示Hadoop启动成功。
3 总结
现在企业对大数据处理会首选Hadoop开源分布式框架,通过上述构建过程,完成了以Hadoop为基础,部署最基础的云计算平台。在此基础上,后期会对Hadoop中的Yarn进行资源管理配置,加入一些如TF架构、数据库等,将此云计算平台应用到工业生产中,承担相关智能算法的实现,为工业智能化生产提供一个平台。
猜你喜欢
娃娃乐园·综合智能(2022年3期)2022-04-19
电脑爱好者(2020年10期)2020-07-28
网络安全和信息化(2019年1期)2019-12-22
电脑爱好者(2019年16期)2019-10-30
创新作文(1-2年级)(2019年3期)2019-09-03
软件和集成电路(2019年7期)2019-08-30
军营文化天地(2018年2期)2018-04-20
电脑爱好者(2016年22期)2016-12-16
办公自动化(2016年18期)2016-08-20
办公自动化(2016年18期)2016-08-20
