
迎战未来 英特尔架构日和HotChip技术信息解读(上)
2020-12-25 06:34张平
微型计算机 2020年18期
张平

虽然英特尔近年来在工艺更新上进展缓慢,并因此给竞争对手带来了喘息和应变的时机,但英特尔也在想办法解决问题。在2020年8月的架构日和9月的HotChip会议上,英特尔带来了大量关于全新架构和全新工艺的消息,似乎预示着那个一直引领业界科技创新、永攀技术高峰的巨人正在逐渐回归。
在2020年8月11日的架构日线上会议上,英特尔向观众展示了其在10nm工艺和全新架构产品上的努力。随后在HotChips年会上,英特尔又针对之前发布的技术进行了一些新的讲述和更新。那么,这两次重要发布会的内容都有哪些看点呢?
由于架构日和HotChips上展示的技术细节和产品信息内容过多,因此本文对其进行了整理,将分为上、下两篇向读者介绍。其中上篇的内容主要包含英特尔在10nmSuperFin工艺和封装技术方面的内容,下篇则会详细介绍英特尔在最新的Tiger Lake、XeGPU以及3DNAND和3DXPoint方面的最新内容,敬请期待。
六大技术环追赶摩尔定律
在2020年的架构日中,英特尔先是展示了企业发展的目标,那就是"通过创造改变世界的技术来丰富地球上每个人的生活”,发展愿景则是“成为可信赖的性能领导者并充分释放数据的潜力”。这一个目标和一个愿景,贯穿了整个英特尔架构日会议的始终。
英特尔认为目前人类与数据的核心矛盾是人类生产数据的速度远远超过了处理数据的速度。数据显示,到2025年人类将每年生产175ZB数据,但是处理速度是远远赶不上的,这就带来了巨大的市场机会。另外,英特尔用一张2018年架构日的老幻灯片重新提及了摩尔定律和摩尔指数。整个摩尔定律被英特尔分解为三个指数,其中人们最熟悉的部分是晶体管密度指数,1980年~2016年里晶体管密度指数的增长都维持在1.7~2的水平。另一个数值是每美元性能或者每瓦特性能,这个数据增长在1980年~1996年维持在1.7的指数值,但是在1996年~2016年下降到了1.3,显然是增长放缓了。另一个放缓的指数是频率,在1996年之前,频率增长指数为1.2,1996年以后平均只有1.1了,并且在2012年后甚至接近水平,增长幅度变得更低。
在摩尔定律部分内容放缓的情况下,英特尔构建了一个拥有六大技术环的技术支柱来增强未来的数据计算性能。其中最核心的是处理器和封装技術,从内到外排在第二环的是XPU的架构设计,包括CPU、GPU、FPGA、AI加速单元等各种类型的产品。第三环则是内存技术,第四环是互联技术,第五环是安全技术,最后一环是软件。这六环环环相扣,从内到外,构建了英特尔未来产业发展的基本格局。
在六大技术环的基础上,英特尔细分到每个模块来介绍自己在全新技术和研发上的成绩和新品。本刊将重点集中在新的工艺、封装技术、CPU和GPU架构以及路线图等内容上。
SuperFin:史上最大的同代工艺内部性能提升
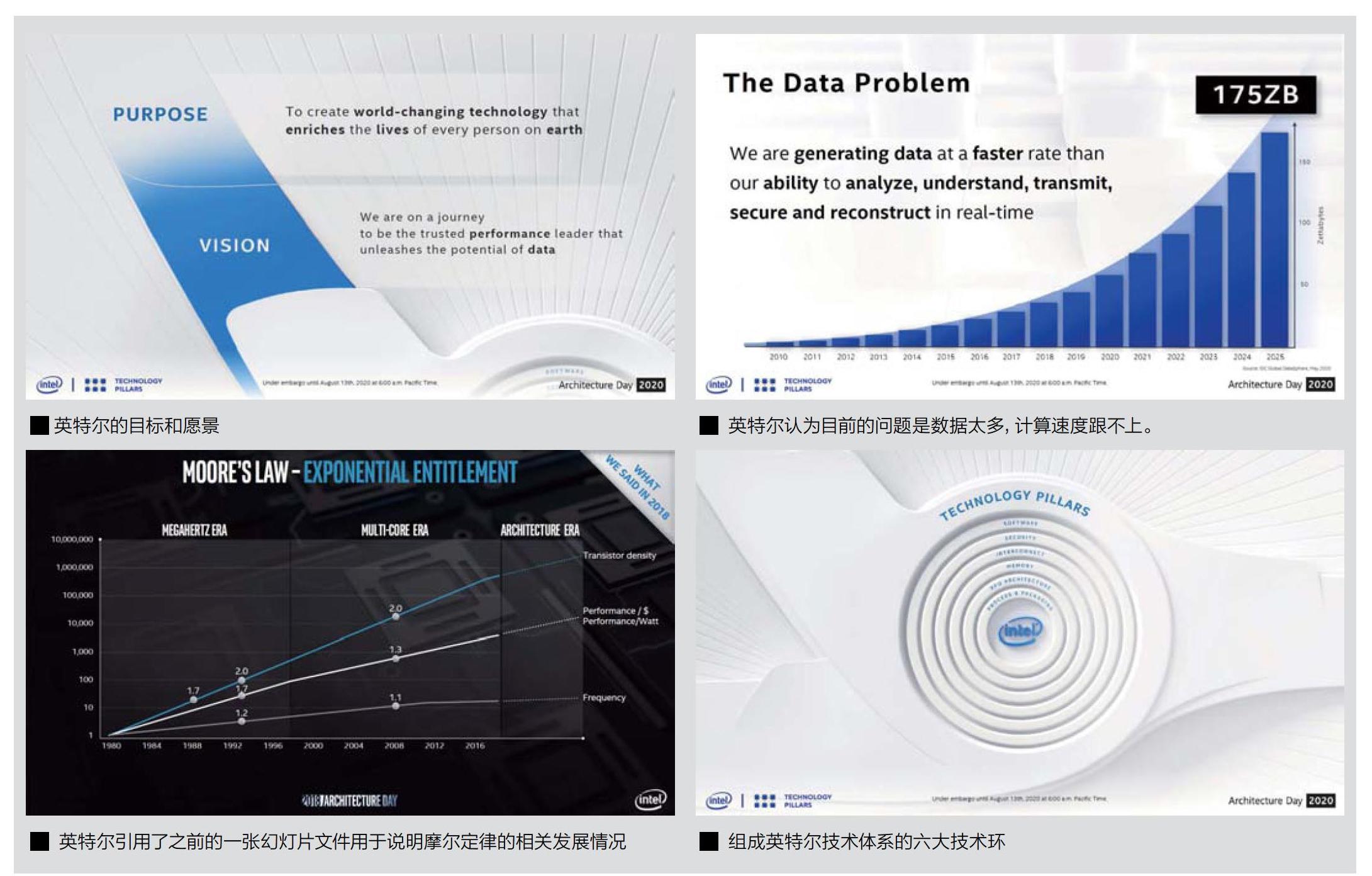
英特尔深知,晶体管、封装和设计的协同发展对摩尔定律的未来至关重要。回顾历史来看,英特尔在90nm时代发明了应变硅,在45nm时代推出了高介电常数K金属门(High-KMetalGate).又在22nm时代首次引入了FinFET,直引领着整个行业。
但是这样革命性的创新步伐在14nm时代似乎不再明显,从英特尔2014年末发布14nm制程产品到现在,都没有一个明确的革命性新技术或者新材料提出。但是这并不意味着英特尔14nm工艺就没有太大改进,从早期的Broadwell的14nm工艺开始一直到现在,每一代的改进叠加起来,大约为14nm工艺带来了20%的性能提升。不过由于都属于14nm工艺,因此英特尔也没有特别为每一代工艺赋予正式名称,而是直接不断地在14nm后添加“+”,以至于到今天,英特尔使用的是已经是14nm+++工艺。
众所周知的,出现这种情况的原因是英特尔10nm工艺严重延期,现在来看,英特尔的10nm工艺不但良率和性能都未达预期,甚至还不如现有的14nm工艺,因此持续保持着低产量。在这种情况下,英特尔继续改进着10nm工艺,并且不断带来性能升级的版本。不过和14nm时代一样,英特尔之前称呼这些改进版本的工艺的方法依旧是在名称后面加上“+”,这给消费者和英特尔内部员工带来了许多困惑——甚至部分英特尔工程师都无法确定哪一代”+”对应了什么技术和产品。
在这种情况下,英特尔需要重新审视自己的产品命名或者技术路线。现在,英特尔就“重新定义"10nm时代的FinFET技术,英特尔宣称新的FinFET设计的性能提升超越了过往所有同代次制程内部的性能变化幅度,在很大程度上重新定义了整个制程,因此英特尔将其称为SuperFin。
在22nm工艺时代首次推出的FinFET,主要是为了解决传统平面MOS在晶体管工艺制程缩小至22nm后出现的短沟道效应。在这种效应的影响下,MOSFET的源极和漏极之间会由于导电沟道过于窄小而产生的各种不利的变化,影响栅极对其的控制并带来发热增加、频率难以提升等各种问题。在这种情况下,英特尔在业内率先转向FinFET,通过将漏极和源极"站立"起来形成鳍片,并让栅极通过“夹住”漏极和源极的方式来增大接触面积,从而在很大程度上避免了短沟道效应的存在,并将半导体工艺制程继续向前推进了一大步。在FinFET被成功应用后,从22nm开始,到后期的20nm、14nm乃至现在的10nm、7nm,FinFET都是个绕不开的话题。
为了进一步解释何为“重新定义”、何为“SuperFin",英特尔提出了三个技术特性。首先是SuperFin更宽的栅极鳍片距离带来更高的驱动电流,这个变化对某些高性能处理器非常重要,虽然表面上看起来栅极鳍片距离变宽会减少晶体管密度,但实际上宽栅极鳍片距离带来的高驱动电流反而会减少高性能单元库中所需要的缓冲器数量,从而实现更高的晶体管密度。其次是源极和漏极晶体管结构的外延生长得到了增强,这最终增加了内部应变并同时降低了电阻,从而允许更多电流通过沟道,提高了晶体管性能。第三则是增强的源极/漏极架构和改进的栅极工艺,带来更高的沟道迁移率,从而使电荷载流子能够更快地移动,提高了晶体管的性能。
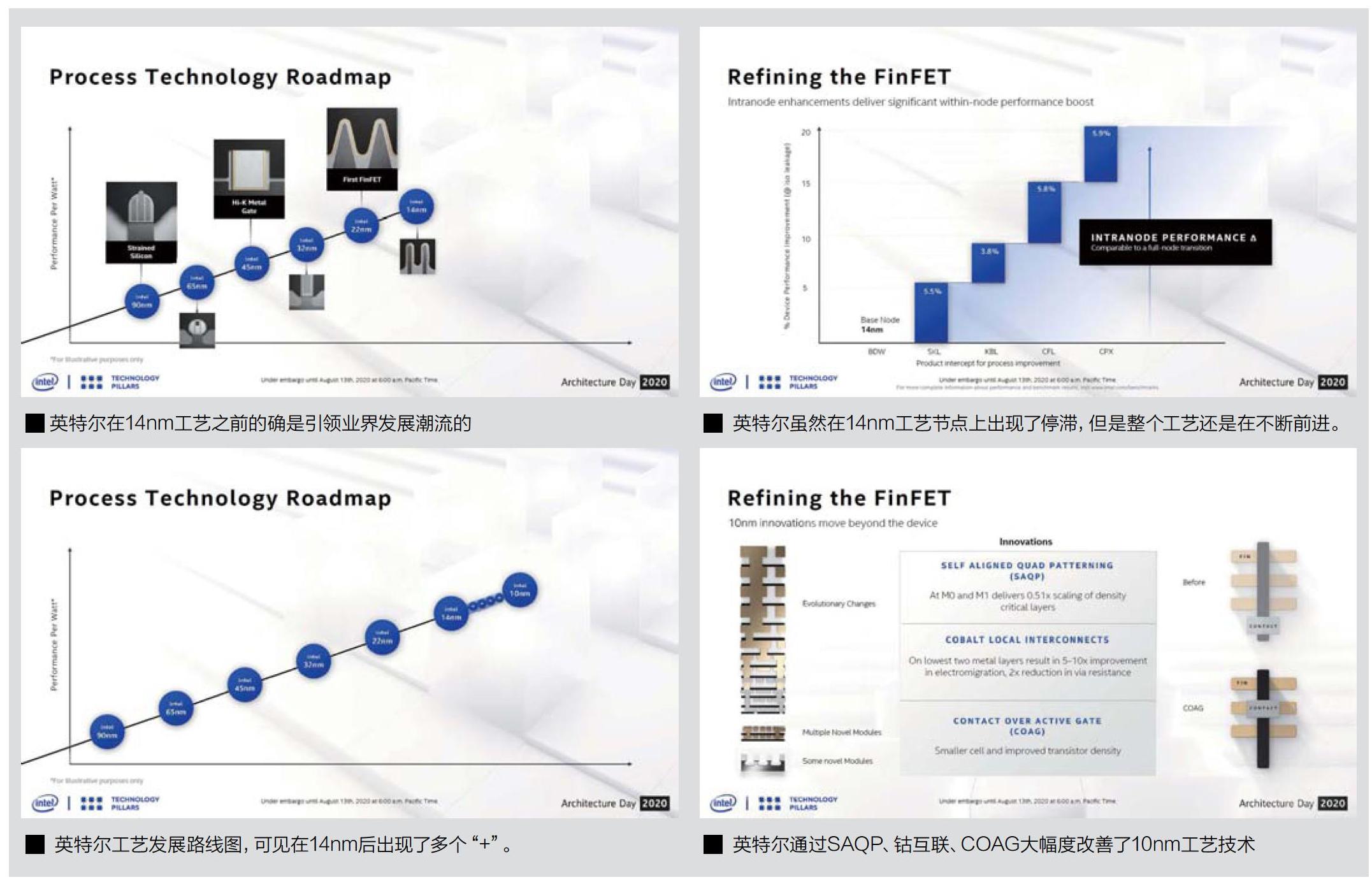
在发布会上英特尔还特别宣布了两个重要的技术,其中一个被称为SuperMIM电容器。所谓MIM是指电容器的基本构成形式,那就是"金屬一绝缘层一金属”,英特尔采用了一种全新的设计,使得自家的SuperMIM相比传统标准类型的电容器,在相同的占位面积内容值增加了5倍。容值增加的另一重含义是电压值的降低,这会带来最终产品晶体管性能的大幅度提升。英特尔特别指出,这种设计是一种全新的方案,其基本原理在于通过在厚度小于0.1nm的薄层中沉积全新的高介电质材料后,在两种或者多种材料之间形成了超晶格,然后带来了这一突破性的设计。另一个是材料学上的突破,被称为“新型薄隔板”(NovelThinBarrier,简称为NTB),使用在较低的堆栈层中,NTB材料不但更薄,同时还能够使得上下层之间的金属过孔的面积增大,从而降低金属过孔在电流通过时的电阻,增强了不同层的互联性能。数据显示NTB材料能够减少30%电阻,从而降低了发热、驱动电压等。
在整个半导体工艺中,英特尔还带来了三个重要的进步。第一个是SAQP,也就是自对齐四轴图形技术,这个技术为M0和M1层提供了0.51倍的密度临界层。第二个则是钴互联技术,主要目的是通过使用平均自由程只有11.8nm~7.7nm的钴材料替代平均自由程高达40nm的铜材料,避免线路尺寸微缩至40nm以下后电流将金属原子冲离原来的位置从而引发电阻加大甚至导线断线等情况。当然由于钴的电阻值更高,因此并未全面使用在所有的金属层中,目前仅用于M0和M1两个层,这两个金属层的局部互联导线非常窄,仅为36nm。英特尔宣称采用新材料后,通孔电阻降低了2倍、这些层的电子迁移率提高了5~10倍。第三个技术是COAG也就是有功栅极上触点,这是一种栅极触点堆叠在晶体管栅极上方而不是在其侧面的一种工艺,COAG技术可以有效地提高晶体管密度。
这样一来,包括SuperMIM、NTB、更宽的栅极鳍片距离、增强的源极和漏极晶体管结构的外延生长、增强的源极和漏极架构和改进的栅极工艺以及SAQP、钴互联和COAG,这八大技术的联合使用,为10nmSuperFin带来了基于之前10nm工艺大约17%~18%的性能提升,而之前14nm时每一次工艺内的迭代,往往只能实现大约6%左右的性能提升。
在10nmSuperFin之后,英特尔也没有停止脚步。在技术日上,英特尔还介绍了新的增强版SuperFin技术,新的技术会带来额外的性能提升、内部互联的创新设计和为数据中心优化的方案,但是目前没有提供更多的技术细节。不过一些消息称,英特尔已经在规划使用增强版SuperFin的产品了,目前确认的有三款,分别是Xe-HP、Xe-HPC以及SapphireRapids。
3D封装:需要什么,就封装什么
在芯片产品制造技术发展过程中,人们一直更为关心制程工艺而对封装工艺关注不多。这可能是因为之前制程工艺能够带来更为显著的性能提升和成本节约,从而成为业内追逐的焦点。但是在目前的市场情况下,选择更好的封装工艺、带来更符合市场需求的产品,显然成为一股新的潮流。在架构日的技术介绍中,英特尔也展示了其创新的封装技术进展。
英特尔在之前的产品中曾多次尝试过2.5D封装,比如之前颇受市场关注的KabyLakeG,就是将CPU、AMDGPU和HBM显存封装在一起。在FPGA市场上,英特尔也已推出了AgilexFPGX,在一个基板上封装了包括10nm工艺的FPGA芯片、HBM芯片和各种不同的I0控制芯片等。
随着市场需求和技术发展,英特尔也加入了CHIPS联盟,大力促进ADVANCEDINTERFACEBUS(高级互联总线AIB)这样的业界统一物理连接规范的应用,并且参与了AIB2.0的标准制定,具体的内容包括每连接线带宽、触电密度、电压和能耗等,参数相比AIB1.0均有大幅度提升。
当然,英特尔如此努力推广全新的封装规范肯定是有的放矢,那就是3D封装或者更先进封装技术可能会随着S0C市场的发展而逐渐开始成为主流封装形式。
Foveros技术就是英特尔在3D封装上的典型尝试,其每平方毫米面积下有超过1000个I0触点,当然这还只是个开始,比如英特尔已经展示过在Lakefield芯片上的3D封装,其层数高达4层,从上到下分别是内存、10nm计算核心、22nm的I0或SoC芯片、基板,全部通过TSV或者面对面封装技术完成。
面对未来封装技术发展,英特尔提出了新的要求:典型的三个数据包括封装点距由现在的50um缩小至10um,每平方毫米触点数量由现在的400个提升至高达10000个,另外还加入了HybridBonding技术,根据情况使用TSV等技术连接触点,减少芯片连接至封装层的复杂程度同时降低厚度等。
新的技术会带来更好的能源效率和连接密度,但是英特尔认为,在可伸缩性方面还可以使用新的封装技术开拓出一个全新的维度——那就是Co-EMIB混合封装。
这个技术将根据实际需要同时使用横向的嵌入式桥连2D封装和纵向的Foveros3D封装技术,并在基板上形成多区块、多区域的连接综合体,这样将允许不同类型和尺寸的芯片在基板上形成高密度的连接,甚至中间层的芯片在合适的条件下都可以形成纵向连接,这大大拓展了半导体芯片封装的界限。
实现Co-EMIB封装的关键
技术被称为Omni-DirectionalInterconnect(全方位互联,ODI),ODI可以使得芯片在没有传统基板支持的情况下,不但可以上下互联,还能够左右互联,从而大幅度减少芯片厚度,但是又带来了更小的TSV穿孔面积、更直接的电源连接以及更高带宽的连接方案。借助这些技术,未来芯片将呈现怎样的形态,令人充满遐想。
好了,截至这里,本文上篇内容就暂时告一段落。下一期本刊还将继续和大家一起了解英特尔全新的CPU和GPU架构以及在存储设备、AI方面的新进展。
猜你喜欢
真空与低温(2022年2期)2022-03-30
大自然探索(2021年7期)2021-09-26
中国电子报(2019年54期)2019-10-24
电子制作(2019年11期)2019-07-04
制造技术与机床(2017年10期)2017-11-28
制造技术与机床(2017年2期)2017-05-04
电子器件(2015年5期)2015-12-29
电源技术(2015年7期)2015-08-22
微特电机(2015年1期)2015-07-09
电子设计工程(2014年18期)2014-02-27
