
基于华为云的数据挖掘和展示系统研究
2021-01-12 03:55杨杰
无线互联科技 2020年24期
杨 杰
(山西职业技术学院,山西 太原 030006)
0 引言
大数据时代的来临,促使各行各业的数据量爆发式增长,数据类型也呈现出多类型、动态化等特点。通过分析海量数据、提取有效数据并展示对于企业发展具有重要指导作用。华为云由于具有良好的数据处理能力和可操作性,成为服务终端的主要应用媒介之一。本文依托华为云的优势,通过分析海量数据、挖掘提取有效数据并系统展示出来,旨在提高数据处理能力,实现数据的可视化,为用户提供数据处理、展示的一体化平台[1]。
1 数据挖掘以及华为云服务器概述
1.1 数据挖掘概念
数据挖掘是基于量化、不全面、离散的数据中,通过采集其中的内在联系点,挖掘内在的关系网、从而形成潜在的评估思路,进而指导现场作业。所挖掘的数据不仅包括结构数据也包括非结构数据。如图像、文本以及网络中的异性数据。所挖掘的方法和思路不仅涉及数理也包括统计分析,主要应用于信息数据维护、管理和优化甚至过程控制[2]。
数据挖掘是基于量化的数据来对行业和领域做出预测分析。其基本的目的是在所在的数据库中找到数据之间的内在联系点和关系网。主要有以下几类功能。
概念分析:主要包括对某类事物和对象内在联系的描述,并对其特征点进行概况分析。
关联分析:数据关联是通过发现数据之间发展的内在规律,从而描述数据之间某些属性同时出现的模式。如数据之间存在多个对应的数据关系或者具有一定的规律性,则称此过程为关联。关联分析就是基于既定的数据结构中不断地发展其内在的项集模式知识(又称关联规则)[3]。
分类与预测:基于关联分析的基础上,对重要的数据集合进行整合和预测评估,此类方法的主要对象是离散的数据点。
聚类分析:通过对内在联系的数据点进行分类、重组,促使各个单一的数据个体联系在一起,从而达到数据单元“物以类聚”的目的。
偏差检测分析:偏差检测就是从数据已有或期望值中找出关键测度显著变化的那些数据对象。进行偏差检测时,主要采用的方法是,比较不同观测结果和不同参照值之间存在的差别。
1.2 华为云服务器
华为云服务器作为知名的数据处理端,使用者根据自身的情况可向华为云的供应商采购相应类型的服务器,因为云服务器通常会虚拟化服务器中的资源数据、计算和储存,所以使用起来,与通常的物理服务器基本没有差别。
华为云服务器一般突出自主选择性,购买者可根据自身情况向供应商购买不同大小、内存、宽带等配置的服务器。购买者对自己的服务配置不满意,可以随时随地的对服务器进行升级。此外服务器还提供全面的服务,在购买完对应的服务器后,用户可以自主下载所需要的软件,并提供病毒检测以及漏洞修复等功能。由于其CVM部署在云端极大地降低了物理媒介、基础设施的经济成本,为企业省下大量资金;最后云服务器克服了传统的物流服务器在系统配置中由于人为干预而造成的失误,云服务器提供“重装系统”,仅仅需要数秒钟就可以实现系统的重新配置,极大提高了用户的时效性,云服务器具有便携的网络连接服务,在云端可将任何数据信息发布至对应的网络端,使用者可随时随地查看发布信息[4]。
2 基于华为云的数据挖掘
2.1 开发环境
本文借助华为云服务器,配置为1核,内存匹配为1G,宽带为11Mbps,磁盘容量为20G,此外在云服务器上安装安全组件端口和ICMP协议。
云服务器上本文适用python3.6.0安装包,安装结束后配置对应的环境变量,最后再进行python模块安装。
2.2 数据库
爬虫和API接口技术所获取的源数据存放至MySQL数据库中,该数据库涵盖了全国各个省市的数据信息,主要包括了城市名称、所属省份、时间和温度等数据信息,每隔一小时要更新一次数据。
2.3 系统测试
在Windows系统下构建网站并进行检验,通过Apache部署后校核云服务器的效果。首先需建立一个Django项目,其次让 httpd.conf文件监听 8091端口并设置对应的储存目标,输入对应的账号、密码后保存信息登陆。
在Django模块下匹配 request.py文件并在云服务器发布,然后利用网页工具打开获得同样的界面,具体如图1所示,为了区别服务器和云服务器的差别,Windows使用不同的浏览器来进行访问[5]。
首先在互联网上借助爬虫技术和接口技术获得源数据,数据获取后保存至云服务器端,方便系统的存取,在数据处理和展示模块中利用python来进行数据的预测,最后通过 Tableau 和 R 语言集成对全国每个省会城市进行可视化展示。
在项目中该业务运行成功后,就会上传该项目到云服务器,这样,用户就能够在终端通过输入IP地址以及端口信息来查看系统的相关内容。
3 系统展示
将Django 项目按照前文的项目的规划应用至云服务器中,在客户端数据登录链接,具体如图2所示。进入MySQL数据库有Django生成对应的数据表并保存至数据库中,方便随时调用[6]。
本文选用成都市的气候数据分布情况为例,得到气候数据分布图,可记录温度、湿度以及空气质量指数等,数据每隔15分钟更新一次,不仅可以筛选时间,还可以筛选城市以及湿度和空气质量指数等。当在筛选器中选择成都、2017年12月23日时,就会显示成都市当时的气候分布情况。
4 结语
大数据时代有效的数据对于任何企业、机构的发展都至关重要,目前市场上大部分的系统功能都是独立的,无法实现数据分析、挖掘以及展示一体化。本文为适应时代发展,平台发展需求,将数据分析、挖掘以及展示进行集成化。首先基于API 和网络爬虫技术获得原始数据,根据数据挖掘算法对数据进行处理分析,最后将有价值的数据以可视化界面展示处理,实现数据的可视化并选用成都市的气候数据分布情况为例,得到气候数据分布图,可记录温度、湿度以及空气质量指数等并进行了数据化展示,验证了系统的可行性,为后续的平台的进一步数据指导提供良好的交互性。
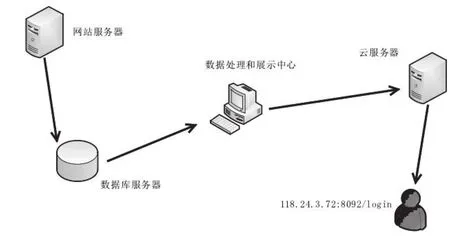
图1 项目流程

图2 客户端数据登录链接
猜你喜欢
心理学报(2022年4期)2022-04-12
作品(2021年8期)2021-09-08
水泵技术(2021年3期)2021-08-14
汽车观察(2021年11期)2021-04-24
意林·全彩Color(2019年8期)2019-09-23
电力与能源(2017年6期)2017-05-14
信息通信技术(2015年6期)2015-12-26
中国惯性技术学报(2015年1期)2015-12-19
电子设计工程(2014年18期)2014-02-27
测绘科学与工程(2013年3期)2013-03-11
