
结合目标局部和全局特征的CV遥感图像分割模型
2021-01-12 06:12李晓慧汪西莉
图学学报 2020年6期
李晓慧,汪西莉
结合目标局部和全局特征的CV遥感图像分割模型
李晓慧1,汪西莉2
(1. 青海民族大学计算机学院,青海 西宁 810007; 2. 陕西师范大学计算机科学学院,陕西 西安 710119)
随着遥感卫星技术的发展,高分辨率遥感影像不断涌现。从含有较多信息、背景复杂的遥感影像中自动提取目标成为一个亟待解决的难题。传统的图像分割方法主要依赖图像光谱、纹理等底层特征,容易受到图像中遮挡和阴影等的干扰。为此,针对特定的目标类型,提出结合目标局部和全局特征的CV (Chan Vest)遥感图像目标分割模型,首先,采用深度学习生成模型——卷积受限玻尔兹曼机建模表征目标全局形状特征,以及重建目标形状;其次,利用Canny算子提取目标边缘信息,经过符号距离变换得到综合了局部边缘和全局形状信息的约束项;最终,以CV模型为图像目标分割模型,增加新的约束项得到结合目标局部和全局特征的CV遥感图像分割模型。在遥感小数据集Levir-oil drum、Levir-ship和Levir-airplane上的实验结果表明:该模型不仅可以克服CV模型对噪声敏感的缺点,且在训练数据有限、目标尺寸较小、遮挡及背景复杂的情况下依然能完整、精确地分割出目标。
图像分割;形状先验;卷积受限玻尔兹曼机;深度学习;Chan Vest模型
随着遥感技术的发展,高分辨率的遥感影像不断涌现,从影像中自动提取目标引起了众多学者的广泛研究。与普通光学图像相比,遥感图像的场景、目标分布等都更为复杂,针对遥感影像复杂背景下的小目标分割[1-2]更为困难。在采用分割提取目标的方法中,基于水平集的CV (Chan Vest)[3]图像分割方法最大的优势在其处理拓扑变化的能力。但面对复杂的遥感图像时,仅依靠图像颜色、纹理等底层信息,当图像中存在目标部分被遮挡、目标与背景杂糅等情况时,往往得不到正确的分割结果。因此,在基于水平集的CV模型中引入与目标相关的形状先验信息,有利于辅助模型分割出完整的目标。但如何准确且灵活地表示目标形状是困难的。形状建模的方法主要分为3种:①基于映射的统计形状建模方法[4-6],即通过映射得到形状的特征向量表达形状特征空间,如主成分分析和核主成分分析。然而对于复杂的形状,此类方法不能灵活地表达。②基于标记点统计特征的形状建模方法[7-9],即通过标记目标轮廓中的关键点,对其统计建模来表达全局形状特征。这些标记点都是手工标记的,通过统计的方法建模形状,建模过程较为复杂且不适合复杂形状。③基于深度学习的形状建模方法[10-12],用深度生成式模型从大量的目标形状样本中学习其结构并建模表示形状,模型不仅可以自动提取训练集的目标形状特征,而且可以灵活地表示形状及生成形状。
考虑到在采用深度学习模型获取目标形状的过程中,图像归一化的操作可能造成目标形状细节特征的丢失,本文在重建的目标形状基础上,采用Canny[13]算子从原图中提取目标边缘信息,结合局部边缘和全局形状构造目标形状约束项,提出了一种结合目标局部和全局特征的CV图像分割模型,即采用深度学习的卷积受限玻尔兹曼机模型(convolutional restricted Boltzmann machine,CRBM)[14]来提取目标全局形状特征,并结合Canny算子提取的原图像的边缘信息,经过符号距离变换得到含有边缘约束的目标形状,以此为先验信息引入到CV模型中指导曲线演化,得到正确的分割结果。模型在训练数据有限、背景复杂、形态各异、尺度变化较大且成像面积小于2 000像素的遥感影像目标提取中取得了理想的分割结果。
1 CV模型
CV模型是由Chan和Vest提出的图像分割模型。该模型将图像分割表达为能量函数最小化问题,用表示待分割的灰度图像,(,)的值表示中任意像素点(,)的灰度值。演化曲线将划分成2个部分,1和2分别表示演化曲线内部和外部的灰度信息的均值。()和()的值分别表示演化曲线的长度以及演化曲线内部的区域面积。1,2,,是各项的系数,则CV模型的能量泛函为

其中,前2项使得演化曲线不断向目标轮廓标靠近,合称为保真项;第3项用于约束演化曲线,确保获得的曲线足够短,称为长度约束项;第4项用于约束演化曲线,避免曲线振荡,称为面积项。只有当保真项的值为零,即演化曲线在目标边界上时能量函数才能达到最小,实现对图的分割。
将式(1)中演化曲线表示为水平集函数(,),令(,)表示图像中任意点(,)与演化曲线的最小欧式距离值。且设定当(,)在图像的内部时水平集函数(,)>0,当(,)恰好在目标边界上时,(,)=0 (即是初始化水平集),否则水平集函数(,)<0,则式(1)改写为

其中,海氏(Heaviside)函数,()和狄拉克(Dirac)函数()分别为

根据变分原理,使用欧拉-拉格朗日(Euler- Lagrange)方法推导出水平集函数的演化方程为
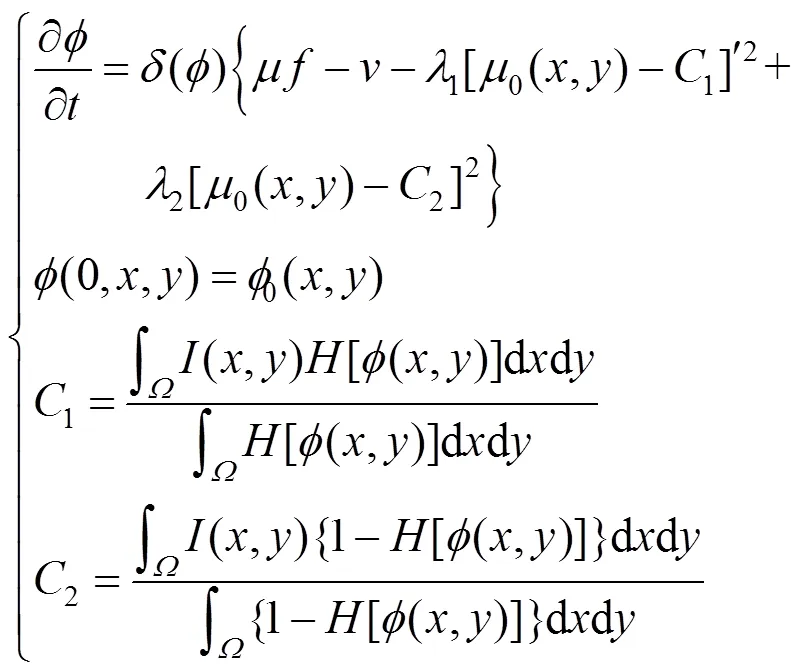
其中,为演化曲线的曲率,通过迭代水平集函数的演化方程使得CV模型的能量函数值最小,得到分割结果。
2 深度生成形状模型
2.1 卷积受限玻尔兹曼机
为了在CV分割模型中引入有效的目标形状先验知识,本文采用2层的卷积受限波尔兹曼机深度学习模型来建模和获取目标的全局形状特征。该模型是在RBM的基础上,引入卷积神经网络(convolutional neural network,CNN)[15]中“卷积权值共享”思想衍生的生成模型。如图1所示,CRBM模型是包含一个输入层和一个隐层的2层模型,由于CRBM模型中卷积操作增加了局部感受野和权值共享的特点,且CRBM的输入是二维的,使得模型能够较好地获取输入数据的二维空间结构信息和图像的局部信息。
图1 CRBM模型结构图

故此,该模型的联合概率分布为




2.2 卷积受限玻尔兹曼机模型训练
模型结构确定后,利用训练样本训练模型,其目的是确定模型的参数。本文训练CRBM模型时以二值图像作为输入,0表示背景,1表示目标,即模型中所有的节点状态均为二值变量。
CRBM模型采用对比散度算法(contrast divergence,CD)[16]训练模型,以训练集中的样本作为模型的初始状态,并将训练集中的样本记为={0,1,···,x},模型初始值记为0,用训练样本初始化模型可视层单元的状态,即令0=0。首先根据式(8)确定隐层单元的状态,即由(|)求得;其次根据式(7)重构输入层单元的状态,即由(|)求得。不断重复上述步骤次,得到0对应的重构结果v。使用梯度下降法更新CRBM模型参数,故此,基于CD算法的参数的梯度更新公式为
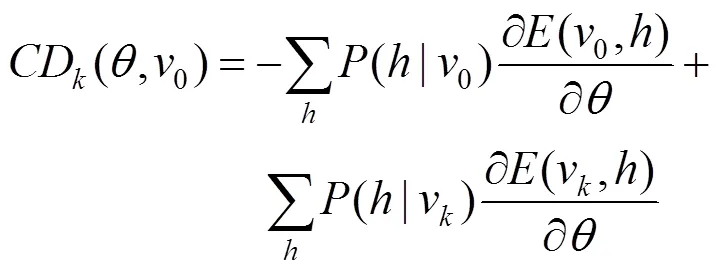
其中,=1,该算法的伪代码如下:
输入:训练样本={0,1,···,x}卷积核的个数,卷积核的大小N×N。输入层大小N,隐层中特征图的大小N。
输出:权重矩阵w,输入层的偏置,隐层的偏置b。
初始化:令输入层的单元状态0=0,w,和b的初始值随机初始化。
更新参数:
2.3 卷积受限玻尔兹曼机模型生成形状
在确定模型参数之后,采用多步吉布斯采样的[17]方法从模型中生成形状。其核心思想是通过模拟的联合概率分布直接推导出条件分布,多次反复直到采样得到的样本与模型所定义的概率分布的样本非常接近。CRBM模型的采样过程如图2所示,为了生成近似服从CRBM模型所定义的样本,本文实验采用二值图像初始化模型输入层的单元状态,并执行Gibbs采样得到输入层单元的状态(即生成样本)。由于CRBM的输入是二维的,使得模型能够更好地获取输入样本的二维空间结构信息和图像的局部信息,从而使得模型的生成形状更加接近真实的形状数据。

图2 CRBM模型采样过程图
3 结合目标局部和全局特征的CV遥感图像分割模型(CLG-CV)
3.1 边缘信息
边缘信息作为图像最基本特征之一,是图像分割依赖的重要特征。Canny算子用一阶导数的极大值表示边缘,可以很好地描述图像目标的外部形状和空间结构的轮廓特性。图3中的3行分别表示Levir数据集[18]中Levir-oil drum001,Levir-ship001和Levir-airplane001提取边缘信息的距离变换示例,图3(a)为原始图像,图3(b)为原始图像边缘提取结果图,将图3(b)距离变换得到图3(c),其表示边缘形状的距离函数图,即令边缘像素点的值为1,其他像素取其与最近边缘像素点之间的欧式距离min(,)。由此边缘距离函数可定义为

图3 距离变换示例图

3.2 形状约束项
为了融合深度学习模型中的生成形状和图像边缘信息,本文将深度学习模型中的生成形状(图4(a))用距离函数表示模型生成形状的结果(图4(b)),使得形状边界处像素点的值为1,其他像素取其与最近边界点之间的欧式距离mindist (,)<1。由此生成形状距离函数定义为

图4 距离变换示例图((a) 生成形状;(b) 生成形状距离函数;(c) 结合边缘和深度学习的目标形状;(d) 结合边缘和深度学习的目标形状的符号距离函数;(e) Ground-truth)
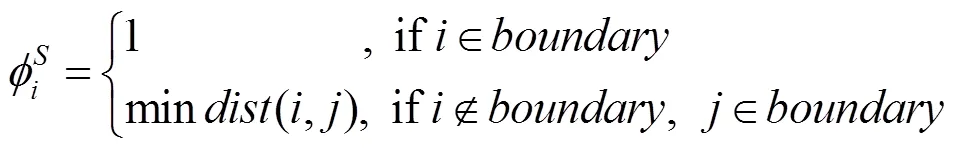
将生成形状距离函数与边缘距离函数作点乘运算,即将图4(b)以及图3(c)中对应位置像素的欧式距离值做乘运算,将运算结果作为输出图像相应位置像素的欧式距离值,最终得到结合边缘和深度学习的目标形状(图4(c))。该方法不仅有效地去除了由Canny算子提取的边缘信息中虚假目标边界,而且也改善了深度学习生成模型-CRBM生成形状时,目标边缘细节丢失的情况。并将结合边缘和深度学习的目标形状表示为符号函数(特殊的水平集函数)[19](图4(d)),即设定边界上像素点的值为0,其他像素取与最近边界上像素点之间的最小欧式距离。为方便描述,用符号距离函数表示结合边缘和深度学习的目标形状,用水平集距离函数表示演化曲线,通过定义得到新的形状约束项为

3.3 CLG-CV模型
本文提出的CLG-CV模型在传统的CV模型的能量函数中做了以下改进:首先舍弃了面积项对演化曲线的约束;其次融合边缘和卷积受限玻尔兹曼机的目标形状信息,定义新的形状约束项E,对演化曲线加以约束;最后结合CV模型的能量项E和形状约束能量项E得到新的能量泛函。故CLG-CV模型的能量函数为

其中,为形状先验项系数。通过对式(11)对应的欧拉-拉格朗日方程进行求解,可得到演化方程

最后通过迭代水平集函数的演化方程使得CV模型的能量函数值达到最小,曲线停止演化,得到最终的分割结果。
3.4 分割算法步骤
本文主要针对少于2 000像素的小目标遥感图像来提取目标,其分割任务更具有挑战性。所提模型通过施加包含全局和局部的目标特征的约束,使分割得到的目标在完整性和边缘细节保留方面都体现得更好,在复杂背景下也能得到正确的分割结果。分割算法步骤如下:
步骤1.粗分割,给定待分割灰度图像,建立CV模型对应的能量函数E(),将其最小化,得到粗分割结果*;
步骤2.训练CRBM模型,把一批已归一化至32×32大小的ground truth图作为训练集,送入到CRBM模型中训练;
步骤3. 生成形状,将*归一化至32×32大小,并将其作为模型的输入,经过采样得到重建结果,将扩大至待分割图像大小,由式(11)计算生成形状距离函数;
步骤4.边缘提取,用Canny算子提取原图像的边缘信息,并进行距离变换,由式(10)计算边缘距离函数;
步骤5. 定义形状约束项,将步骤3中得到的与步骤4中得到的做点乘运算得到融合边缘信息和深度学习的目标形状,并将其表示成符号距离函数,由式(12)得到形状约束项E;
步骤6. CLG-CV图像分割,结合形状约束项E和能量项E,由式(13)得到新的能量函数,求解对应欧拉-拉格朗日方程,使能量函数达到最小值,得到最终的分割结果。
4 数据集、实验参数配置、对比方法和评价指标
4.1 数据集
Levir数据集来源于Google Earth,包含RGB图像、标记图像(含有检测框的图像) 2类图像,每幅彩色图像的尺寸均为800×600,空间分辨率0.2 m。该数据集中的目标为油桶、飞机、舰船3类,目标面积小于2 000像素。从标记图像中随机选择500张图像作为实验对象。
采用3阶段方法制作新的小目标遥感数据集。第1阶段,将所有标记图像按照标记信息裁剪图像,得到仅含一个特定类别的图像2 485幅。其中油桶651幅,船舰492幅,飞机1 342幅。第2阶段,将第1阶段中所有图像,按类别制作为Levir-oil drum、Levir-ship和Levir-airplane 3个数据集。第3阶段,从Levir-oil drum数据集中选取600幅图像作为训练集,51幅图像作为测试集。从Levir-ship数据集中选取400幅图像作为训练集,92幅图像作为测试集。从Levir-airplane数据集中选取1 000幅图像作为训练集,342幅飞机图像作为测试集。数据集中的部分图像如图5所示。
表1列出了Levir-oil drum,Levir-ship和Levir- airplane 3个数据集中的目标尺寸分析,表明该数据集在图像分割方面具有较大的挑战。


表1 Levir数据集图像中目标尺寸分析表
4.2 实验参数配置
电脑配置为Intel(R)Xeon(R) CPU E5-2690,2.6 GHz,256 GB RAM,实验环境为Windows10系统下安装的Matlab R2016a。CV模型分割实验中,使用数据集中的灰度图像。设定初始演化曲线是通过位于图像中心的矩形表示,步长D=0.1,1与2取值均为1,迭代次数为100。在Canny算子提取边缘实验中,直接调用Matlab中的Canny函数,不需单独为不同的数据集设置参数。
参考文献[20]并结合实际设置模型参数。针对Levir数据集中的油桶类,CRBM的参数设置如下:卷积核的大小为3×3,卷积核个数为20,学习率为0.01,迭代次数为1 500。针对Levir数据集中的船舰类,CRBM的参数设置如下:卷积核的大小为4×4,卷积核个数为20,学习率为0.01,迭代次数为2 000。针对Levir数据集中的飞机类,CRBM的参数设置如下:卷积核的大小为3×3,卷积核个数为20,学习率为0.005,迭代次数为3 000。
4.3 对比方法
为了验证本文CLG-CV模型的分割性能,分别与CV分割模型和CG-CV分割模型进行实验对比。
3种分割模型,其中CV模型的分割原理最简单,该方法通过统计中心区域与局部邻域灰度特性对比度值,寻找遥感影像中的目标区域信息,然后在通过空间关系剔除疑似的噪声点,使得演化曲线向着目标轮廓不断逼近,最终得到正确的分割结果。优点是对灰度均匀的图像能自动提取出完整的目标,缺点是针对复杂的遥感影像中目标背景区与目标区杂糅在一起的情况,很难取得较好的分割结果。
CG-CV分割模型,是以传统CV模型为基础的衍生模型,首先,采用深度学习生成模型–卷积受限玻尔兹曼机建模表征目标全局形状特征,以及重建目标形状。其次,利用重建目标形状,做符号距离变换,得到结合目标全局形状信息的约束项。最终,以CV模型为图像目标分割模型,增加新的约束项得到结合目标全局特征的CG-CV遥感图像分割模型。该模型是在传统的CV模型的能量函数中做了以下改进:首先舍弃了面积项对演化曲线的约束。其次通过卷积受限波尔兹曼机生成形状,并定义新的形状约束项E。最后结合CV模型的能量项E和形状约束能量项E得到新的能量泛函。由此新的CG-CV模型的能量函数为

该模型优点是克服了传统CV分割模型对噪声敏感的缺点,即在采用深度学习模型CRBM获取目标形状的过程中,图像归一化的操作造成目标形状细节特征的丢失。
4.4 评价指标
本文采用全局精度(global accuracy,Global acc)和交并比(intersection over union,IOU) 2种评价标准来定量评价分割结果的正确性和完整性,其分别定义为

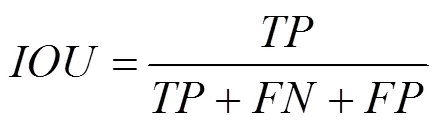
其中,为目标正确分类的像素数目;为背景正确分类的像素数目;为目标分为背景的像素数目;为背景分为目标的像素数目。
5 实验结果及分析
5.1 Levir数据集生成形状实验
分别使用Levir-oil drum,Levir-ship和Levir- airplane数据集来训练CRBM模型。通过度量生成的形状图像与原始形状图像之间的欧式距离差异,来定量地分析CRBM模型对不同形状的建模效果差异,该值越小表明模型生成的形状越接近真实的形状。CRBM模型在不同数据集上的训练时间以及平均欧氏距离度量值见表2。通过对比3个数据集在CRBM的训练时间可以发现,Levir-ship数据集的训练时间最短,主要是由于其训练样本的数量最少。针对不同的数据集在CRBM模型上的生成形状不论是训练集还是测试集的平均欧氏距离都较小,这是由于CRBM中的卷积操作能够很好地提取输入样本的的局部信息,从而使得生成形状的结果更接近真实的形状。

表2 模型训练时间及生成形状结果的平均欧氏距离度量
图6分别展示了Levir-oil drum,Levir-ship和Levir-airplane数据集的测试集中的5幅图像生成形状结果(图6(I)a1,图6(II)a2,图6(III)a3)。模型生成形状的时间都在0.25 s左右。由图6(I)b1,图6(II)b2,图6(III) b3可见,在生成形状的效果方面,油桶的生成形状结果最好,重构出来的形状能很好地保留目标油桶的形状特征,符合真实形状。从Levir-ship数据集中的生成形状结果可以看出,对于包含多个目标舰船的图像,CRBM模型依然能够很好地建模形状。这是CRBM模型中的“卷积操作”使得模型能够很好地提取输入样本的全局特征,灵活地表示形状及生成形状。从Levir-airplane数据集中的生成形状结果可以看到,由于目标飞机的形态结构较为复杂,使得CRBM生成的飞机形状与真实的飞机形状仍有较大的差异,如图6(III)b3-3,6(III)b3-5的所示,生成的飞机形状丢失较多机翼和发动机的细节特征。

图6 不同数据集的生成形状结果((a1)~(a3)输入图像;(b1~(b3))CRBM生成形状结果)
5.2 Levir数据集分割实验
图7(I)~7(III)分别展示了Levir-oil drum,Levir-ship和Levir-airplane等3个数据集的训练集和测试集中的5幅图像分割结果图。图8(I)~图8(III)分别对应图7(I)~图7(III)中不同模型在上述3个数据集的训练集和测试集中的5幅图像分割结果评价。其中Global acc和IOU分别衡量了分割的完整性和正确性,其值越高越好。由图7(I)可见Levir-oil drum数据集中,存在原始图像是目标油桶被周围目标背景阴影遮挡的情况(图7(I)a1-4、图7(I)a1-5)、原始图像是目标油桶图像较复杂的情况(图7(I)a1-3、图7(I)a2-6、图7(I)a2-7)、以及原始图像的尺寸小于32×32的情况(图7(I)a1-1、图7(I)a1-2、7(I)a2-10)。Levir-ship数据集中目标船舰个数不同、形态各异,且目标舰船周围都存在一定的背景影响。例如图7(II)a1-1、图7(II)a1-3、图7(II)a1-5、图7(II)a2-8是原始图像中目标舰船与背景海面相近且原始图像尺寸均小于32×32的情况。图7(II)a1-4是原始图像中目标舰船的个数为2个的情况。第图7(II)a2-6、图7(II)a2-7、图7(II)a2-10是原始图像中目标船舰较小的情况。相较于传统的CV模型,由于CG-CV模型和CLG-CV模型引入先验知识指导分割,使得CG-CV模型和CLG-CV模型能有效地克服目标与背景杂糅、目标遮挡等噪声干扰的影响,提升了模型的分割精度。并且所提模型CLG-CV在每一幅图上的度量指标能够达到最高,分割的结果更符合实际,效果更好。这是由于在CLG-CV模型中将边缘信息引入模型的形状约束项中,加强了目标形状的边缘细节特征,能更好地约束演化曲线向目标轮廓不断逼近,得到正确的分割结果。
在Levir-airplane数据集中,由于原始图像目标飞机的形态较油桶及舰船更为复杂,且原始图像中飞机周围都存在背景环境的影响。如图7(III)a1-1是目标飞机被云层遮挡的情况。可以看出无论是训练集还是测试集,虽然CLG-CV模型在每副图像的性能评价值最高。这是由于在模型中将边缘信息引入模型的形状约束项中,加强了目标形状的边缘细节特征,能更好地约束演化曲线向目标轮廓不断逼近,得到正确的分割结果。但与标记图相比仍有一定的差距,丢失了大量尾翼和飞机发动机的细节信息。这是由于建模目标形状以及生成目标时,模型的输入尺寸为32×32,在图像缩放的过程中丢失了细节信息。从而使得分割效果较差。
为了验证所提模型的分割性能,表3给出了CV,CG-CV以及CLG-CV模型在Levir数据集的测试上的分割性能评价结果。相较于CV模型,CLG-CV模型在Levir-oil drum,Levir-ship和Levir-airplane 3个数据集上的平均Global acc值分别提高至98.654%,97.936%以及96.628%。在Levir-oil drum,Levir-ship和Levir-airplane 3个数据集的测试集上的平均IOU值分别提高至95.328%,94.140%以及92.425%。
5.3 其他图像分割实验
为了验证所提模型CLG-CV的推广性,从网上选取与训练集中图像在背景、位置、数目、上均有差异的256×256大小的图像,送入模型进行测试(图9)。

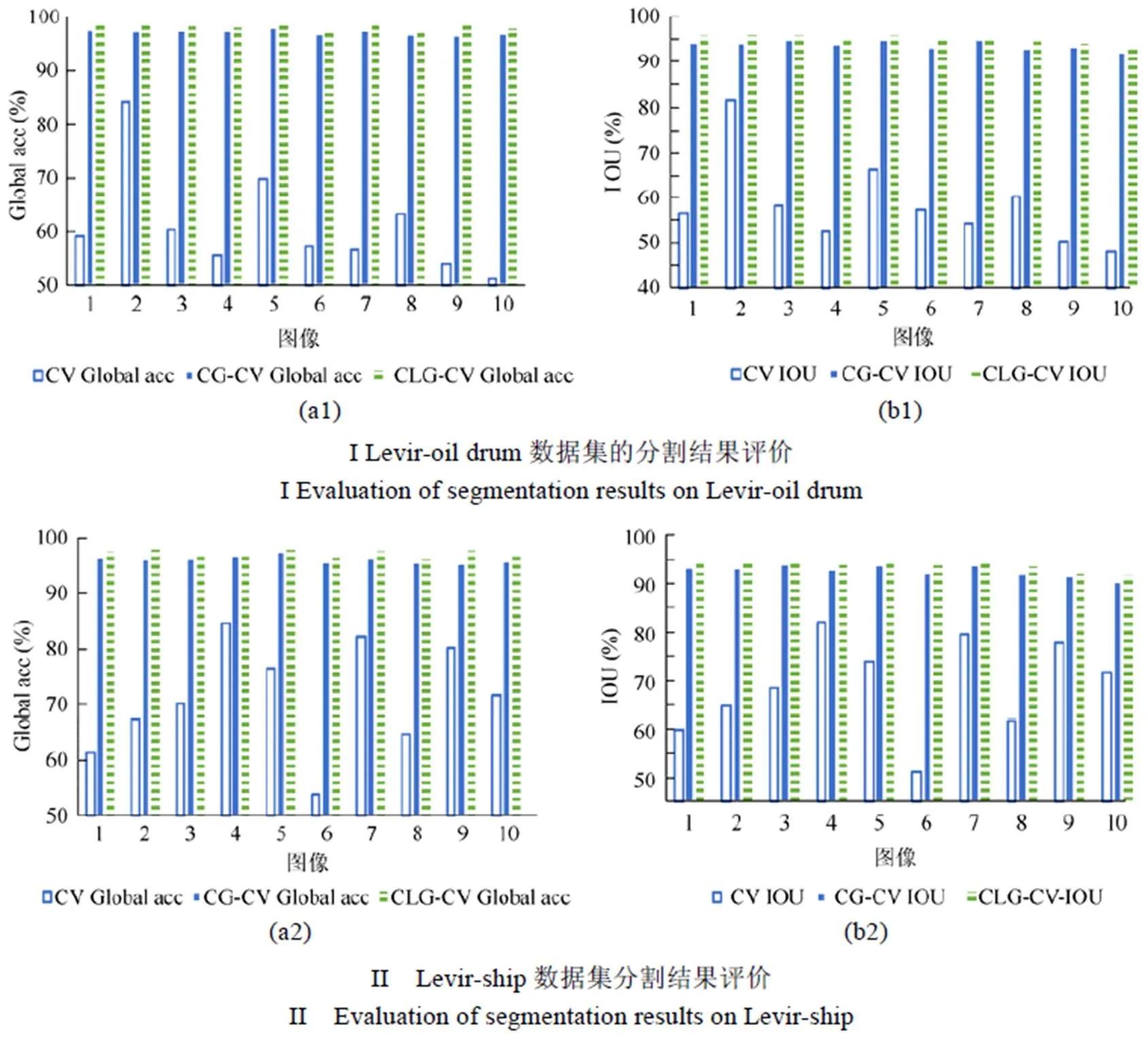

表3 不同模型在Levir测试集上的分割结果评价

图9 其他图像上的分割结果图
6 结 论
为解决遥感影像复杂背景下,远距离成像的小目标分割问题,提出结合目标局部和全局特征的CV遥感图像分割(CLG-CV)。在小目标遥感数据上的实验结果表明,相较于只结合卷积受限玻尔兹曼机CG-CV模型,CLG-CV模型的分割效果最佳。这是由于CLG-CV在采用生成式模型获取目标形状信息的同时,将原图像的边缘信息引入模型的形状约束项中,通过“点乘”的方式减少了边缘信息中虚假目标边界,弥补了深度学习生成模型的形状时,丢失的目标边缘细节特征。通过图像分割实验结果表明,与传统CV模型和CG-CV模型分割方法相比,本文模型在小目标以及其他尺寸较大的遥感影像分割应用中也依然能取得较好的分割结果。
[1] 王好贤, 董衡, 周志权. 红外单帧图像弱小目标检测技术综述[J]. 激光与光电子学进展, 2019, 56(8): 080001. WANG H X, DONG H, ZHOU Z Q. Review on dim small target detection technologies in infrared single frame images[J]. Laster & Optoelectronics Progress, 2019, 56(8): 080001 (in Chinese).
[2] 姚红革, 王诚, 喻钧, 等. 复杂卫星图像中的小目标船舶识别[J]. 遥感学报, 2020, 24(2): 116-125.YAO H G, WANG C, YU J.Recognition of small-target ships in complex satellite images[J]. Journal of Remote Sensing, 2020, 24(2): 116-125 (in Chinese).
[3] CHAN T F, SANDBERG B Y, VESE L A.Active contours without edges for vector-valued images[J].Journal of Visual Communication and Image Representation,2000,11(2):130-141.
[4] SCHÖLKOPFB,SMOLA A, MÜLLER K-R. Nonlinear component analysis as a kernel eigenvalue problem[J]. Neural Computation, 1996, 10(5): 1299-1319.
[5] 杨建功, 汪西莉, 李虎. 融合Kernel PCA 形状先验信息的变分图像分割模型[J]. 中国图象图形学报, 2015, 20(8): 1035-1041. YANG J G, WANG X L, LI H. Variational image segmentation incorporating Kernel PCA-based shape priors[J]. Journal of Image and Graphics, 2015, 20(8): 1035-1041 (in Chinese).
[6] 田杰, 韩冬, 胡秋霞, 等. 基于PCA和高斯混合模型的小麦病害彩色图像分割[J]. 农业机械学报, 2014, 45(7): 267-271. TIAN J, HAN D, HU Q X, et al. Segmentation of w heat rust lesion image using PCA and Gussian mix model[J]. Transactions of the Chinese Society for Agricultural Machinery, 2014, 45(7): 267-271 (in Chinese).
[7] AMBERG B, VETTER T. Optimal landmark detection using shape models and branch and bound[C]//2011 IEEE International Conference on Computer Vision (ICCV). New York: IEEE Press, 2011: 455-462.
[8] 王雷, 王升, 汪丛, 等. 基于析取正态水平集的彩色图像分割[J]. 传感器与微系统, 2020, 39(6): 127-130. WANG L, WANG S, WANG C, et al. Color image segmentation based on disjunctive normal level set[J]. Transducer and Microsystem Technologies, 2020, 39(6): 127-130 (in Chinese).
[9] 雷晓亮, 于晓升, 迟剑宁, 等. 基于稀疏形状先验的脑肿瘤图像分割[J]. 中国图象图形学报, 2019, 24(12): 2222-2232. LEI X L, YU X S, CHI J N, et al. Brain tumor segmentation based on prior sparse shapes[J]. Journal of Image and Graphics, 2019, 24(12): 2222-2232 (in Chinese).
[10] 张娟, 汪西莉, 杨建功. 基于深度学习的形状建模方法[J]. 计算机学报, 2018, 41(1): 132-144. ZHANG J, WANG X L, YANG J G. Shape modeling method based on deep learning[J]. Chinese Journal of Computers, 2018, 41(1): 132-144 (in Chinese).
[11] DOU F Z, DIAO W H, SUN X, et al. Aircraft reconstruction in high-resolution SAR images using deep shape prior[J]. International of Geo-Information, 2017, 12(6): 214-232.
[12] YUKA K, MATVEY S, TSUHAN C. In the shadows, shape priors shine: using occlusion to improve multi-region segmentation[C]//2016 IEEE Computer Society Conference on computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2016: 392-401.
[13] CANNT J. A computational approach to edge detection[J]. IEEE Transactions on Pattern Analysis and Machine, 1986, 8(6): 679-698.
[14] NOROUZI M, RANJBAR M, MORI G.Stacks of convolutional restricted boltzmann machines for shift-invariant feature learning[C]//2009 IEEEComputer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2009:2735-2742.
[15] FUKUSHIMA K, MIYAKE S, ITO T. Neocognitron: a self-organizing neural network model for a mechanism of visual pattern recognition[J].IEEE Transactions on Systems Man and Cybernetics,1970,13(5):826-834.
[16] HINTON G E. Training products of experts by minimizing contrastive divergence[J]. Neural computation, 2002, 14(8): 1771-1800.
[17] WALSH B. Markov chain monte carlo and gibbs sampling[J]. Notes, 2004, 91(8): 497-537.
[18] Zou Z, Shi Z. Random access memories: a new paradigm for target detection in high resolution aerial remote sensing images[J]. IEEE Transactions on Image Processing, 2018, 27(3): 1100-1111.
[19] CHAN T F, SANDBERG B Y, VESE L A. Active contours without edges for vector-valued images[J]. Journal of Visual Communication and Image Representation, 2000, 11(2): 130-141.
[20] 李晓慧, 汪西莉. 结合卷积受限玻尔兹曼机的CV分割模型[J]. 激光与光电子学进展, 2020, 57(4): 041018. LI X H, WANG X L. CV image segmentation model combinig convolutional restricted Boltzman machine[J]. Laster & Optoelectronics Progress, 2020, 57(4): 041018 (in Chinese).
CV image segmentation model combining with local and global features of the target
LI Xiao-hui1, WANGXi-li2
(1. School of Computer Science, Qinghai Nationalities University, Xining Qinghai 810007, China; 2. School of Computer Science, Shaanxi Normal University, Xi’an Shaanxi 710119, China)
With the development of the remote sensing satellite technology, high-resolution remote sensing images are on an increasing trend. The automatic target extraction from remote sensing images containing other information and complex background urgently needs to be realized. The traditional image segmentation method mainly depended on such underlying features as image spectrum and texture, and in image segmentation tasks, was likely to be impacted by the interference of shadow and occlusion in the image, complicating the segmentation and leading to unsatisfactory results. For this reason, according to the specific target type, a CV (Chan Vest) image segmentation model combined with local and global features of the target was proposed. Firstly, the deep learning generation model-CRBM (convolution restricted Boltzmann machine) was employed to represent the global shape features of the target and to reconstruct the shape of the target. Secondly, the edge information of the target was extracted by Canny operator, and a new shape constraint term integrating the local edge and global shape information was obtained by symbolic distance transformation. Finally, the CV model served as the image target segmentation model, and new constraints were added to gain the CV remote sensing image segmentation model integrating the local and global features of the target. The experimental results on the remote sensing dataset Levir-oil drum, Levir-ship and Levir-airplane show that the proposed model can not only overcome the noise sensitivity of the CV model, but also segment the target completely and accurately in the case of limited training data, small target size, occlusion and complex background.
image segmentation; shape prior; convolutional restricted Boltzmann machine; deep learning; Chan Vest model
TP 391
10.11996/JG.j.2095-302X.2020060905
A
2095-302X(2020)06-0905-12
2020-07-15;
2020-08-12
15 July,2020;
12 August,2020
国家自然科学基金项目(41471280,61701290,61701289)
National Natural Science Foundation of China (41471280, 61701290, 61701289)
李晓慧(1992-),女,青海西宁人,教师,硕士。主要研究方向为机器学习、图像处理。E-mail:lixiaohuihxl@163.com
LI Xiao-hui (1992-), female, master student. Her main research interests cover machine learning and image processing. E-mail:lixiaohuihxl@163.com
汪西莉(1969-),女,陕西西安人,教授,博士。主要研究方向为智能信息处理、模式识别、图像处理。E-mail:wangxili@snnu.edu.cn
WANG Xi-li (1969-), female, professor, Ph.D. Her main research interests cover intelligent information processing, machine learning and image processing. E-mail:wangxili@snnu.edu.cn
猜你喜欢
小学阅读指南·低年级版(2017年1期)2017-03-13
通信产业报(2016年44期)2017-03-13
小天使·五年级语数英综合(2016年12期)2016-12-09
小朋友·聪明学堂(2015年7期)2015-11-30
人生十六七(2015年6期)2015-02-28
计算机辅助工程(2012年5期)2012-11-21
中学生英语·中考指导版(2008年6期)2008-12-19
雕塑(1999年2期)1999-06-28
雕塑(1996年2期)1996-07-13
雕塑(1996年4期)1996-07-12
