
一种适应大数据处理要求的深层学习模型
2021-01-15 08:21徐承俊朱国宾
计算机应用与软件 2021年1期
徐承俊 朱国宾
(武汉大学遥感信息工程学院 湖北 武汉 430079)
0 引 言
大数据在带来丰富信息和宝贵资源的同时,也给处理数据、分析数据等工作带来了巨大的压力和严峻的挑战。如何高效开发和利用大数据,挖掘其背后隐藏的有价值的信息,利用大数据更好地把握和预测未来各领域发展趋势,更好地为人类服务,是数据挖掘和机器学习领域的核心问题之一。深度学习是目前应用最广泛的学习方法和框架之一,其模型框架使用监督/非监督学习,已成功应用于新型数据驱动态势感知[1]、基于大数据医疗保健治疗[2]、信息服务[3]和工业大数据应用[4]等领域。小米、阿里巴巴和新浪等IT巨头都已经加大对大数据的投入、采集、分析和研发,推出各种个性化服务,如:阿里基于大数据深度学习框架为用户推荐爆款商品、道路路况拥堵、新闻推送等[5];百度也推出了地图匹配和搜索、联想输入等;微软的语音同步翻译与IBM人工智能也都使用了深度学习框架[6]。虽然深度学习在上述领域已表现出巨大优势,也取得了很好进展,但仍旧存在不足,主要表现为以下几个方面:
(1) 数据信息缺失等不完整性。大数据中含噪声数据,如属性、参数缺失等。目前模型针对标准数据集,而面对实时数据时稍显不足。
(2) 大数据的海量性。模型训练中数据量大、类型多,数据结构复杂度高,普遍采用云存储、云计算,但会导致数据安全等问题。
(3) 数据的动态性。目前使用的深度学习框架基本是静态模型,执行过程中不能更改,故无法满足实时动态变化需求。
(4) 数据的异构性。大部分现有模型基于向量空间表示,适用于处理一维或者二维数据,很难处理高维异构数据,存在局限性。
为了有效克服上述问题,本文分析大数据特征并针对上述问题中的动态性和异构性提出以下解决方法:(1) 设计递增式迭代深层学习模型,主要针对数据结构和参数进行更新,提高模型对新进数据的拓展适应性,满足大数据变化要求;(2) 数据结构采用张量表示,将数据表示从一维、二维向量空间扩展到高维张量空间,构建更深层次模型。
1 递增式迭代深层学习模型
大数据变化快、数据量大,需要及时进行处理,以获取最新信息。所以要求算法、模型能适应此要求。递增式迭代深层学习模型即在原模型基础上,保留原训练参数忽略原结果,只对新进数据更新模型参数或结构,学习新特征,即在保存原模型参数、知识结构的同时具备学习新特征的能力。
机器学习中传统模型训练是将整个训练集同时送入模型进行训练,此过程中无法对模型参数或结构进行动态更新,无法满足实时性要求,存在局限性。
为了克服上述问题,本节提出一种支持大数据实时更新的深层计算模型,主要是对模型参数或结构更新。在参数更新方法中,借鉴一阶微分思想,不采用传统迭代的方式进行求解,避免了原数据集的再次训练,从而提升参数更新速度,使得新模型能快速学习新数据特征。训练时若增加模型节点,则将获取的新参数与原参数有机结合后赋值于新模型的新初始值,这样在原有模型参数基础上,加快计算速度,使其更快收敛。
1.1 问题概述
实现支持递增迭代式更新的深层计算模型需要将多个此计算模型进行合理叠加,组建支持递增更新的更深层次计算模型。在接收新进数据后,其目标是保存原模型参数,不再重新训练原数据集,引入新进数据时更新模型的参数与结构,学习新数据特征,即此模型既要完成保留原模型参数,又要实现对新数据进行训练学习。该模型需要满足下面三个原则:
(1) 拓展适应原则。改进的新模型具有对新进数据集特征学习的能力,能适应大数据实时变化。
(2) 兼顾原则。新模型既保留原模型参数,又训练新数据参数等。
(3) 递增原则。在接收新数据时,保留原数据特征参数等信息,不再训练原始数据集,仅训练新进数据。
实现上述功能有多种方式和方法,本节主要讨论以下两种方式:
(1) 结构更新。大数据更新快、数据量大,主要通过增加隐藏层神经元数目对模型结构、参数进行更新。传统机器学习中,数据结构表示是向量,可以直接增加若干个隐藏层神经元,但是递增式迭代深度学习模型处理的数据结构是张量,要根据其结构和类型确定增加的神经元数目。
(2) 参数更新。当新进数据特征变化不明显,可以通过对原模型参数更新,实现模型更新。
1.2 结构更新的递增式迭代深层学习模型
结构更新即增加隐藏层神经元数目实现对原模型修改。一个具有m个输入变量和n个隐藏层神经元的自动编码机,其原始模型结构如图1所示,其中“+1”表示新增加的1个神经元。
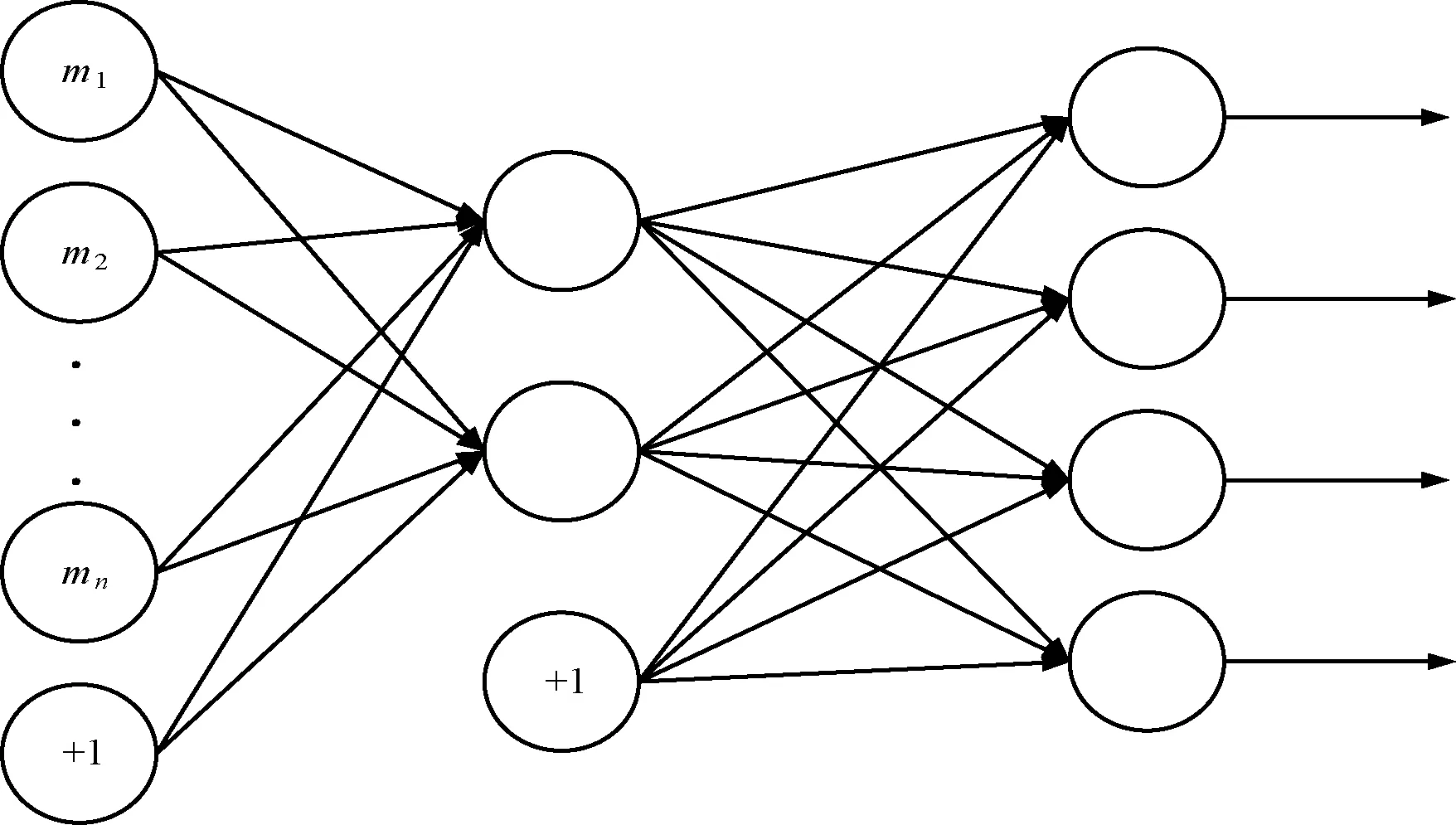
图1 原始模型结构
设模型参数η={k(1),t(1),k(2),t(2)},表示如下:
k(1)∈Rm×nt(1)∈Rmk(2)∈Rm×nt(2)∈Rn
(1)
增加1个隐藏神经元后的新结构如图2所示,调整参数,以适应新进数据学习。权重k(1)、k(2)分别增加1行1列,k(1)∈R(m+1)×n,k(2)∈Rm×(n+1),t也增加1个分量t(1)∈Rm+1。
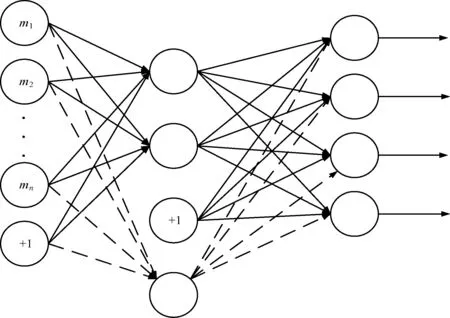
图2 改进后的模型结构
增加隐藏层神经元并赋值新增参数为0。当前参数η={k(1),t(1),k(2),t(2)},增加p个隐藏神经元后的初始参数表示如下:

(2)
新模型参数η={k(1)′,t(1)′,k(2)′,t(2)′},使用反向传播方法求模型的最终参数。然后考虑将模型扩展到高维空间,设计基于增加隐藏层神经元的模型结构更新算法。一般只需增加若干个神经元,而对于高维模型,则需要考虑高维模型的结构特征。
如果一个输入变量为g∈RS1×S2,隐藏层l∈RU1×U2,设η′={k(1),t(1),k(2),t(2)},表示为:
k(1)∈Rυ×m×n(υ=U1×U2)t(1)∈RU1×U2k(2)∈Rϖ×m×n(ϖ=S1×S2)t(2)∈RS1×S2
(3)
式中:υ、ϖ表示神经元作用域范围。
若隐藏层增加U1个神经元后其结构为l′∈RU1×(U2+1),对应的参数为η′={k(1)′,t(1)′,k(2)′,t(2)′},表示为:
k(1)′∈Rυ′×S1×S2(υ′=U1×(U2+1))t(1)′∈RU1×(U2+1)k(2)′∈Rϖ′×U1×(U2+1)(ϖ=S1×S2)t(2)′∈RS1×S2
(4)
式中:υ′表示新增U1个神经元作用域范围。
增加U2个神经元后的隐藏层结构l′∈R(U1+1)×U2,其参数为η″={k(1)″,t(1)″,k(2)″,t(2)″},表示为:
k(1)″∈Rυ″×S1×S2(υ″=(U1+1)×U2)t(1)″∈R(U1+1)×U2k(2)″∈Rϖ′×(U1+1)×U2(ϖ=S1×S2)t(2)″∈RS1×S2
(5)
式中:υ″表示新增U2个神经元作用域范围。
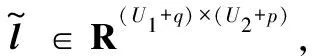
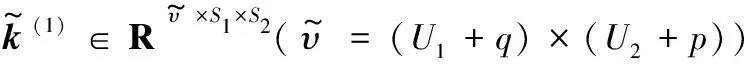
(6)
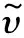
输入变量g∈RS1×S2×…×SN模型一般形式,隐藏层结构l′∈RU1×U2×…×UN,参数η={k(1),t(1),k(2),t(2)}表示为:
k(1)∈Rχ×S1×S2×…×SNχ=U1×U2×…×UNt(1)∈RU1×U2×…×UNk(2)∈Rδ×U1×U2×…×UNδ=S1×S2×…×SNt(1)∈RS1×S2×…×SN
(7)
(U2+p2)×…×(UN+pN)
ϖ=S1×S2×…×SN
(8)
结构更新得到新模型后,将新模型中参数的新增分量初始值赋为0,应用算法1计算新模型最终的参数。
算法1反向传播算法
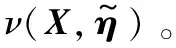
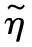
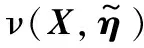
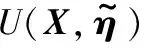
Step5采用梯度下降算法取合适步长进一步更新模型参数,找出最优解。
Step6重复Step2-Step5直到模型收敛。
根据原模型训练结果得到参数,加上新进数据参数不断调整,并与原模型参数有机结合作为新模型初始参数值,因此新模型在原有参数基础上训练,其收敛速度更快,更好地满足数据变化需求。
1.3 模型实施
支持递增更新的深层学习模型有两个阶段:预先训练与局部微调。第一阶段,通过参数或结构更新采用自下而上递增迭代的方式完成各分支模块的训练,将训练后的多个递增式模型叠加,组成更深层次模型。第二阶段,使用有标签数据对参数进行调整训练,通过前向传播和反向传播算法相结合使用,计算获得最后参数。
1.4 参数更新的深层学习模型
参数更新方法不同于1.2节中的结构更新,不需要对模型结构调整与修改,只需要根据新进数据特征将原参数η更新为η+Δη,使其能够适应学习新数据特征,参数更新的模型参数η={k(1),t(1),k(2),t(2)},数据结构由低维向量扩展成高维张量组成。t(a)(a=1,2)与k(a)(a=1,2)由N维、N+1维张量表示,借鉴一阶近似导数思路,在不改变结构的基础上调整参数来满足数据处理实时性要求。
(9)
Δanew=ν(a,η+Δη)-a表示计算模型从η更新到η+Δη的新误差。其中:η为原参数,η+Δη为新参数,ρ表示学习效率,a为与I同阶的一个参数。
同理,定义保持性误差函数:
(10)
式中:γ表示误差因子,在本文中取值为0.3。
兼顾保持性与拓展适应性,其代价函数U(a,η+Δη)表示为:
U(a,η+Δη)=Uadaption+Upreservation
(11)
参数更新模型的方法是找寻使得式(11)最小值来求解递增Δη,对其进行泰勒公式应用展开求解:
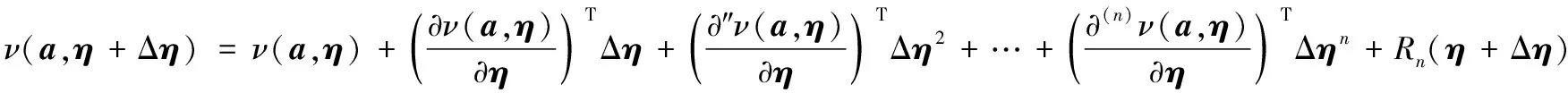
得到代价表示函数U(a,η+Δη)近似为:
根据求导法则,令导数等于0后并对Δη求导,得近似值,如下:
进一步继续求解,得到:
(12)
式中:Δη和η表示参数张量的变化量和张量,类似线性梯度下降算法;Δa表示模型输出值与a的差值。
算法2参数更新算法
Step1根据前向传播方法计算递增式迭代深度学习模型输出值ν(a,η)。
Step2求解递增式迭代深层学习模型的输出与x的差值Δη。
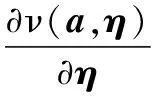
Step4应用式(12)计算新模型参数的Δη递增值,将模型参数更新为η+Δη。
根据算法2,当新进数据进入模型并完成加载后,模型可完成对其训练、学习,完成参数更新等操作,且无须对原始数据重复训练,只对新进数据训练,具有很高的拓展适应性,能提高计算性能。
2 基于张量表示的深度计算模型
不同于传统数据,大数据包含大量非结构化、半结构化和结构化数据。传统机器学习模型和算法是基于结构化数据,而大数据中通常包含视频、语音和图像等半结构化、非结构化数据,约占总数据的80%以上[7]。
当前模型主要是对单一数据结构的特征学习,2010年Ngiam等提出多模深度学习模型,能够学习语音与图像特征。2012年Srivastava等提出多模深度玻尔兹曼机,能够学习文本与图像特征。虽然上述模型能解决部分问题,但依旧存在模型学习效率低等问题。根本原因是其数据结构是采用向量表示,表达高维数据时信息易丢失。
本文针对上述问题,提出一种应用张量对异构数据进行表示的方法。将向量表示扩展到张量表示,构建基于张量空间模型,并且使用张量距离替代欧氏距离构造误差函数,减少误差和损失。设计基于张量的高阶反向传播算法求解参数,然后将多个高阶模型进行叠加,构建更深层次模型。主要思路如下:
(1) 异构数据采用张量的表示方法,使该模型能够学习各类异构数据,并将高维模型进行叠加,组成更深层次模型,实现多层学习。
(2) 使用张量距离而不是传统欧氏距离构建误差函数。
(3) 设计基于张量的反向传播算法。
因此,本文从以下几个方面解决张量的深度学习模型的关键问题:
(1) 传统模型是以向量、矩阵表达和计算的,如何使用张量来描述,使得数据更加准确是第一个关键问题。
(2) 传统欧氏距离在张量表示的高维空间受理论知识限制,导致数据特征表示不准确,故采用张量距离表示误差函数。
(3) 反向传播算法大都基于向量表示空间设计的,无法用于张量表示,所以需要设计基于张量空间的反向传播算法以适应新模型。
2.1 张量的数据表示
1890年沃尔德马尔·福格特提出张量[8-10],本文中使用的一些定义及运算[11-12]如下:
定义1张量:令G1,G2,…,GN是维数为H1,H2,…,HN的N个有限维的欧氏空间,设N个向量u1∈V1,u2∈V2,…,uN∈VN,定义V1×V2×…×VN的多线性映射u1∘u2∘…∘uN为:
(u1∘u2∘…∘uN)(a1,a2,…,aN)=
(13)
式中:
定义2张量的n阶展开:令A∈RH1×H2×…×HN为一个N阶张量,其n阶展开为Hn×(H1H2…Hn-1Hn…HN)矩阵,用A(n)表示,第(in,j)个元素为Ai1 i2 …iN。
特别地,一个N阶张量A∈RH1×H2×…×HN可以展开成一个向量a。
定义3张量的外积:对于一个N阶张量A∈RH1×H2×…×HN和M阶张量B∈RU1×U2×…×UM。外积产生一个(M+N)阶张量C∈RH1×H2×…×HN×U1×U2×…×UM,其元素Ch1,h2,…,hN,u1,u2,…,uM被定义为:
Ci1,i2,…,iN,j1,j2,…,jM=si1,i2,…,iN·tj1,j2,…,jM
(14)
式中:s、t分别表示张量A、B中的元素。
定义4张量的多点积:对于两个N阶张量A,B∈RH1×H2×…×HN,A和B的多点积产生一个张量C,且:
(15)
一幅彩色图像用一个3阶张量表示,一个视频文件用一个4阶张量表示。例如,彩色图像用ZSW×SH×SC,其中SC、SW、SH分别表示该图像颜色通道、宽度和高度。一幅256×256像素的彩色图像表示为Z256×256×3,通常转换成灰度图像:
G=0.299R+0.587G+0.114R
(16)
对于一个视频文件ZSW×SH×SC×SA,SC、SW、SH分别表示图像颜色通道、宽度和高度,SA表示视频的维度。如一个15秒的MP4视频文件,设每秒20帧,每一帧由一幅图片组成,则该视频表示为R256×256×3×300。
2.2 高维自动学习编码机模型
定义5张量的多点乘积⊙:对于N+1阶张量k∈Zυ×S1×S2×…×SN和N阶张量g∈ZS1×S2×…×SN,其中k具有α个N阶子张量,每个子张量kϖ∈ZS1×S2×…×SN。k和X的多点乘积得到N阶张量l∈ZU1×U2×…×UN(U1×U2×…×UN=υ),l=w⊙X。
与传统模型不同,新模型每一层是一个张量,而不是一个向量,其他相同。设g∈ZS1×S2×…×SN,l∈ZU1×U2×…×UN表示输出层和隐藏层变量。将输入变量X经过fθ映射到隐藏层l:
l=fθ(k(1)⊙a+t(1))
(17)
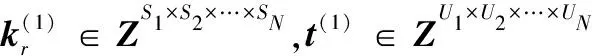
同时,解析函数gθ将隐藏层映射回重构函数Y:
Y=hk,t(a)=gθ(k(2)⊙l+t(2))
(18)
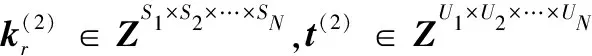
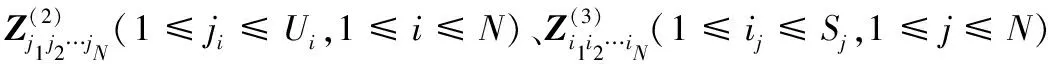
(19)
(20)
(21)
(22)
式中:w为权重;b为偏移量。
文献[13]使用张量距离重构误差函数,对于两个张量X∈RI1×I2×…×IN、Y∈RI1×I2×…×IN,x和y分别表示张量X和Y按向量展开后形式,则张量距离表示为:
(23)
式中,glm是稀疏;G是矩阵的系数,反映高阶数据不同坐标内在的联系;xl、xm、yl、ym分别表示张量X和Y对应的元素。
(24)
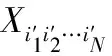
‖pl-pm‖2=
(25)
设训练集{(X(1),Y(1)),(X(2),Y(2)),…,(X(m),Y(m))}中包含m个训练集,对于任何一个实例(X,Y),将其展开对应向量(x,y),其重构误差函数:
(26)
式中:递增式迭代深度学习模型参数θ={W(1),b(1),W(2),b(2)},在自动学习编码模型中令X=Y。对于整个训练集,基于张量距离的递增式迭代深度计算模型重构误差函数为:
(27)
式中:第一项表示平均误差;第二项是一个规范化项,主要是防止过度拟合。
2.3 高维反向传播
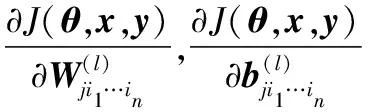
(1) 前向传播计算,计算z(2)、z(3)、a(2)、a(3);
(2) 对于输出层每个神经元i,计算残差:
(3) 对于隐藏层每个神经元,也计算残差:
(4) 对于隐藏层和输出层每个神经元,计算残差:
(5) 当l=1,2时,计算偏导数:
2.4 深度学习模型
构造更深层次计算模型将多个高维模型叠加,其训练主要有:预先训练与局部微调。训练过程可用于异构数据监督特征学习,如图3所示。
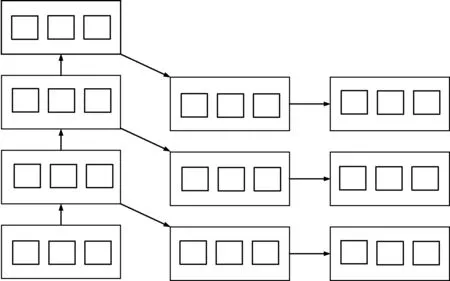
图3 训练模型图
完成预训练后,可以根据每个数据对象的类标签,进行有监督学习,对模型进行局部参数微调,获得最后模型参数,如图4所示。向量是1阶特殊张量,此模型可以作为深度学习模型的扩展。
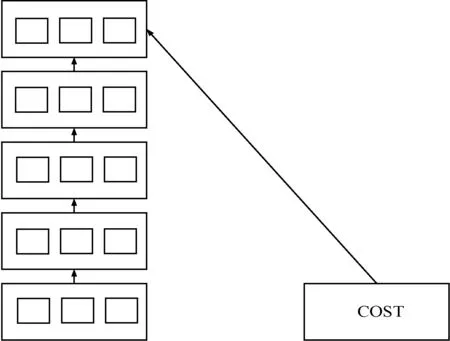
图4 参数调整模型图
3 实验与分析
数据集选择ImageNet中STL-10,其中包含500幅训练图像和800幅测试图像,总共有10个分类[14],并且包含100 000幅未被标记的图像,可用来进行无监督训练。
数据集中每幅图像用一个3阶张量表示,因为训练集与测试集变化不大,参数的更新很小,所以只需通过参数更新就能实现模型对新数据特征学习。为进一步验证本文提出的模型有效性,将STL-10数据集进行如下设计:
(1)T0:训练数据集含500幅图像;
(2)T1:测试数据集随机抽取300幅图像作为新增训练集;
(3)T2:测试数据集中剩余图像作为测试集。
根据以上数据集训练如下参数:
(1)η(TAE):根据T0运行基本的模型,得到模型参数η;
(2) ITAE-1:以上一步得到的η为初始参数,执行T1近似一阶导,支持递增更新深层模型,获取更新参数ITAE-1;
(3) TAE-2:在T0+T1运行更新前模型,获取参数TAE-2;
(4) TAE-3:在数据集T2运行更新前模型,获得参数TAE-3。
实验以T2为测试数据集,计算均方误差(MSE)验证以上参数对T2测试数据集分类的正确性。主要目标是验证以上参数是否能对新数据有适应能力,MSE越小说明适应能力越强。实验10次,结果如图5所示。
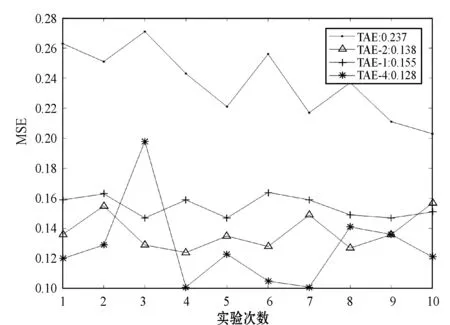
图5 STL-10实验结果
均方误差(平均结果)统计如表1所示。
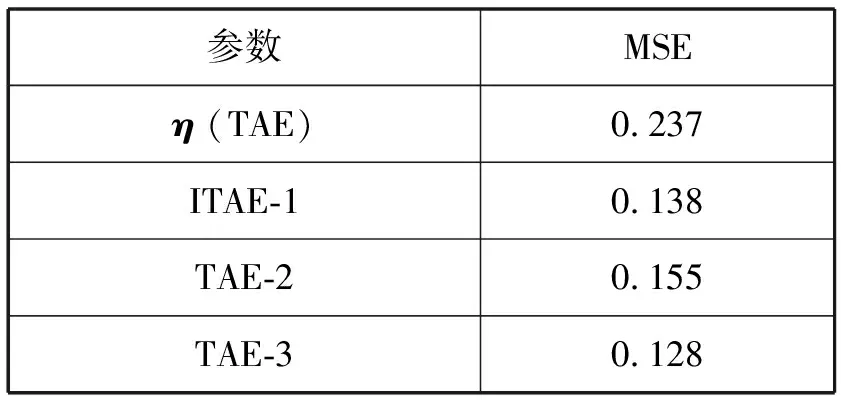
表1 MSE统计结果(适应性)
可以看出,以η为参数对T2进行分类,得到MSE的值最大,因为原始计算模型是静态的,参数确定好之后,无法更新,很难学习到新的数据特征。而本文模型能实现对参数更新,进而对新数据进行学习。
以T0为测试数据集,计算MSE验证以上参数对T0测试数据集分类的正确性。主要目标是验证以上参数是否具有保持原数据的能力,MSE越小说明适应能力越强。实验10次,结果如图6所示。
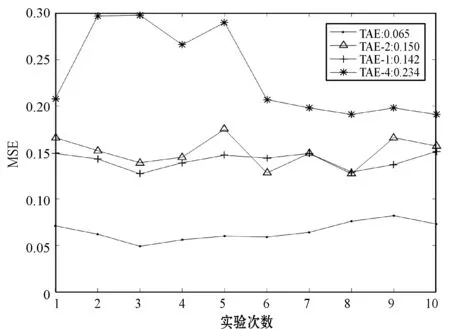
图6 保持性实验结果
均方误差(平均结果)统计如表2所示。
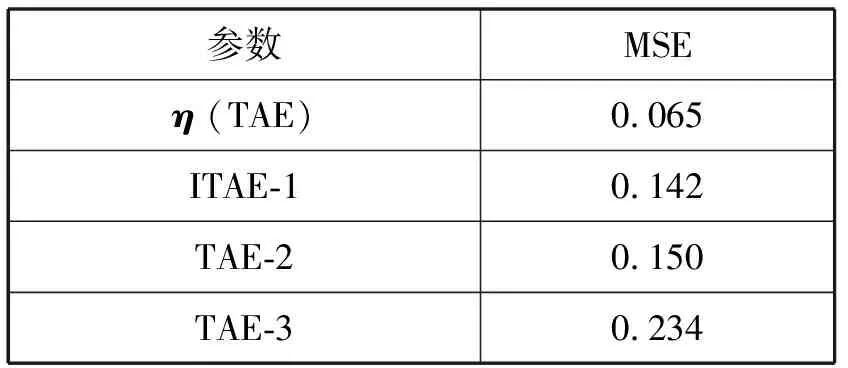
表2 MSE统计结果(保持性)
实验结果表明,以η为参数对T0进行分类得到MSE最小,因为η是基于T0进行学习获得的参数。以ITAE-1和ITAE-2为参数T0进行分类,得到MSE结果依然很低,说明两种算法对历史数据具有较好的保持性,而ITAE-3获得的MSE结果比其他参数高,因为其不包含原始数据参数信息等。
从实验结果可以得到:
(1) 新模型可保持原模型训练参数、知识结构等信息,不需要对原数据重复训练。
(2) 保存原数据信息的同时能对新进数据进行特征学习,满足大数据实时性要求,具有很好的拓展适应性。
4 结 语
本文针对大数据变化特征、异构特征等做了分析与研究,发现现有模型大部分基于向量空间表示学习,无法满足大数据实时性要求,存在局限性。为了解决此类问题,本文设计递增式迭代深层学习模型,分析与归纳该模型的关键问题,设计后向传播方法、近似一阶导方法更新参数和结构等方法。实验证明,该模型能保持原参数等信息不变的同时继续学习新进数据特征,并且不需要对原始数据重新训练,设计基于高维张量空间表示的反向算法,将向量空间拓展到张量空间,适应了大数据变化需求,提高模型计算效率,满足了当下大数据要求。
猜你喜欢
计算技术与自动化(2022年1期)2022-04-15
科技信息·学术版(2022年8期)2022-02-25
现代计算机(2021年26期)2021-11-01
安徽大学学报(自然科学版)(2021年3期)2021-05-18
北华大学学报(自然科学版)(2021年1期)2021-03-12
电子产品世界(2021年8期)2021-01-16
科学导报(2020年85期)2020-01-13
中国计算机报(2019年49期)2019-02-07
中国新闻周刊(2017年36期)2017-10-21
世界知识画报·艺术视界(2017年7期)2017-07-27
