
概率线性判别分析在语音命令词置信度判决中的应用①
2021-01-22 05:41闫宏宸
计算机系统应用 2021年1期
闫宏宸,肖 熙
(清华大学 电子工程系,北京 100084)
计算机技术的发展为人类生活带来了极大便利,基于语音的人机交互已经以命令词识别系统的形式在智能家居、可穿戴设备等平台得到了应用.命令词识别系统是一种“N选1”的识别系统,将输入语音识别为预先设定的命令词之一,系统的错误主要来自对集内命令词的错识和对集外语音或噪声的误识.有鉴于此类系统使用环境的多样性,通过某种手段拒绝错误的识别结果,特别是拒绝环境噪声和集外语音引发的错误识别结果,对提高命令词系统的可靠性极为重要.
对语音识别结果的置信程度加以检验和判决是一种比较理想的做法.在数理统计中,置信度分析是分析一个随机变量落在某个区间的概率,而在语音识别中,置信度分析通常用于衡量模型与数据之间匹配的可信程度.置信度分析方法大致可以分为基于预测特征的组合、基于后验概率和基于似然值比值(似然比)等3 大类方法[1].其中基于似然比的置信度分析方法将置信度问题转化为统计假设检验问题,设定数据由某一模型产生(零假设)和数据非由该模型产生(对立假设)两种假设,通过两种假设上的似然比检验以及阈值判断是否接受零假设.已有的置信度分析方法包括基于词网格生成后验概率的置信度[2]、基于逆模型建模对立假设计算似然比的置信度[3]等.
本文提出了一种无需声学模型、语言模型支撑的命令词置信度分析方法.调研发现,身份矢量(identity vector,i-vector)特征[4]和概率线性判别分析(Probabilistic Linear Discriminant Analysis,PLDA)方法[5]已经在说话人识别中得到了广泛应用,但是将i-vector 特征与PLDA应用于命令词语音识别的置信度分析中尚未有文献报导.i-vector 的原理是通过对所有语音数据训练,建立通用背景模型(Universal Background Model,UBM)[6],将语音表示为高维的均值超矢量(supervector),然后通过因子分析将其投影为低维、定长的矢量表示,其特点在于它能在较大的粒度范围内提取语音特征,可以作为一段语音信号的整体描述,这使得i-vector 作为无需语言模型支持的置信度判决的输入特征成为了可能.另一方面,PLDA 方法最早发源于图像领域的人脸识别应用,通过增大类间差异,达到补偿识别过程中无关因素的作用.由于在判决阶段,PLDA 通过计算假设检验的比值(也即似然比)打分,因此其可以自然地作为一种置信度分析手段.
本文首先对汉语的1254 个全音节孤立字以及连接词进行了置信度实验,考察了基于i-vector 和PLDA方法在置信度判决中的有效性.在连接词实验中分析发现,i-vector 特征对语音在全局层面上的刻画能力较强,但是对于语音中的时序特征的辨识,例如音节发音顺序辨识,其存在一定的模糊性,而时序信息是语音语义的重要成分,这在命令词识别中是不可回避的问题.针对此缺陷,本文在实验验证的基础上,尝试提出了改进方法,较好地解决了此问题.
1 置信度与基线系统概述
1.1 置信度及其评价方法
语音识别系统的性能在过去几十年中取得了长足的进步,但环境噪声、非对话内容等干扰因素依然是语音控制这类系统在实际应用中面临的一大挑战.引入置信度模型,通过后处理排除识别结果中的无关内容,是提高系统可靠性的一个有效思路.
在语音识别中,置信度代表某一语音X来自模型W的可信程度.文献[1]中对置信度予以综述,其中将置信度估计方法大致分为3 类:1)基于预测特征的组合,即收集解码过程中各环节的相关特征并融合为判据;2)基于后验概率,即使用识别过程中的后验概率;3)基于似然值比值(似然比):将置信度转换为一个假设检验问题处理,零假设 H0表示语音X来自模型W,对立假设 H1反之.根据Neyman-Pearson 准则,对上述假设的最优检验为似然比检验:
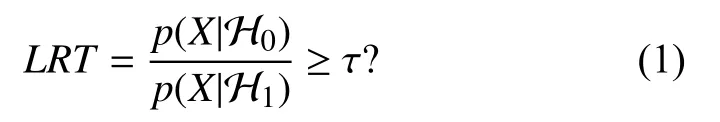
其中,τ为与虚警概率相关的阈值.
在置信度估计中一般会遇到两类错误:第1 类错误(漏报),即实际情况符合零假设 H0时,检验结果拒绝H0;第2 类错误(虚警),即实际情况不符合零假设H0时,检验结果接受 H0.两类错误以及它们衍生出的接收者操作特征(Receiver Operating Characteristic,ROC)曲线、检测错误权衡(Detection Error Tradeoff,DET)曲线、等错误率(Equal Error Rate,EER)等均为评价置信度的统计手段.根据置信度在语音识别中的应用场景,可以在帧搜索阶段就融入置信度得分信息,达到实时剪枝提高识别率的作用,也可以作为后处理方法,对识别结果的正确性进行检验.对于后者,在实际应用中更关注根据置信度进行拒识后对系统性能的影响,可以采用拒绝率(Rejection Rate,RR)和拒绝后的识别准确率(Accuracy after Rejection,AR)来考察置信度在语音命令识别中的作用:

1.2 基线系统
在基于GMM-HMM 的语音识别系统的识别过程中,语音识别器对每次输出能给出N-best 候选的似然值得分.在基线系统中我们采用首选输出的似然值得分与次优候选的似然值得分之比来作为置信度判断的依据,对识别结果进行后处理,简单易行且应用广泛.

其中,p(X|w1) 为首选似然值,p(X|w2)为次优候选的似然值,二者均已根据帧长度做归一化.似然比LR≥τ则接受w1作为首选识别结果.
2 基于i-vector 和PLDA 的置信度判决方法
2.1 通用背景模型
传统的语音识别系统常常是通过训练一个高斯混合模型(Gaussian Mixture Model,GMM),对其语音特征的分布进行建模,通过求取并比较测试语音在不同GMM 上的似然值确认其相似程度,完成识别.但是实际应用中,用于训练特定GMM 的语音往往长度较短或语料较少,导致训练数据不足,无法训练出高质量的GMM 模型;另一方面也存在大量未标注的语料,其中的信息无法被利用.Reynolds 等人提出的通用背景模型(Universal Background Model,UBM)[6]利用所有数据训练得到一个混合分量数较高的GMM 模型,其代表了全局语音特征的分布情况.训练得到UBM 模型之后,通过自适应算法适应特定语句的数据,可以得到各语句的GMM 模型,其特征分布随语句内容而不同,可用于识别确认.
UBM 的训练采用传统的EM 算法,反复迭代更新UBM 各分量的权重wi、均值µi、方差 Σi.在自适应阶段,对于给定语音数据x=x1,x2,···,xt,···,xT,实际应用中一般采用最大后验概率(Maximum A Posteriori,MAP)算法,且只更新UBM 的均值.首先计算数据xt与UBM中第i个分量的相似度:

然后计算充分统计量:

最后计算新均值Ei(x),并与原均值µi加权融合:

其中,αi称作自适应系数,用于控制新旧参数对UBM的影响.在特征空间中,xt的分布只能覆盖到UBM 的部分分量,这些分量的Ni较 高,相应地 αi也较高,更新的均值倾向于在数据x上 训练得到的Ei(x);类似地,未被覆盖到(数据量不足)的分量,其倾向于UBM 中经充分背景数据训练得到的µi.通过根据数据分布情况有选择地调整UBM 参数,能够获得与数据相匹配且高质量的GMM 模型.
2.2 i-vector 模型
前述GMM-UBM 方法得到的特定GMM 模型可以用于常规的GMM 似然值得分确认,但考虑到各GMM 的均值足以代表特征的分布情况,因此可以将均值拼接起来,称为均值超矢量,作为反映变长语音特性的一种定长特征,其同样包含了说话内容等信息.常见的利用此超矢量的方式包括将其送入支持向量机(Support Vector Machine,SVM)等分类器中训练判别[7],或通过联合因子分析(Joint Factor Analysis,JFA)[8]对超矢量建模并进行分解:

其中,M为语音的超矢量,m一般取UBM 的均值超矢量;V为本征语音(eigenvoice)矩阵,y为语音因子;U为本征信道矩阵,x为信道因子;D为残差矩阵(对角阵),z为残差因子.y、x、z均服从标准高斯分布.通过训练V、U、D矩阵,对语音和信道空间分别建模并求解,理论上可以得到仅包含有用信息的因子y作为新的语音特征.
然而在文献[9]中,Dehak 等人通过实验发现上述分离方法较为理想化,在信道因子中同样存在语音信息,并在文献[4]中提出了i-vector 模型:

其中,T表示的全局差异空间(total variability space)包含了说话内容、信道等各方面的信息,w为全局因子,服从标准高斯分布,又称为身份矢量(identity vector,ivector).i-vector 模型可以看做JFA 的简化,不再试图完全分离无关信息,而是使用全局差异空间同时予以刻画.i-vector 主要起对均值超矢量的降维作用,与均值超矢量同样包含说话内容相关的信息,文献[10]等已有研究中通过实验证明其确实对内容具有一定的鉴别能力;另一方面,由于均值超矢量代表语句整体的特征分布,未包含语句中音节内容的时间顺序信息,因此基于UBM 均值超矢量产生的i-vector 特征类似地具备对语音片段的全局刻画能力,而对内容的时序信息缺乏更精确的描述.
使用EM 算法训练T矩阵[11].对于给定语音数据x=x1,x2,···,xt,···,xT,由式(5)中的充分统计量Ni、Fi得到中心化一阶统计量:

将x在各分量i上 的统计量拼接为N(x)、(x).
令UBM 的均值超矢量、方差为m、Σ,并随机初始化矩阵T.E 步骤中,更新隐变量w的后验分布:

M 步骤中,更新矩阵T:

反复迭代更新得到矩阵T后,语音x的i-vector 为:

2.3 概率线性判别分析模型
概率线性判别分析(Probabilistic Linear Discriminant Analysis,PLDA)最早由Prince 等在文献[5]中提出,应用于图像识别中的人脸识别任务.PLDA 的原始形式如下:

其中,wij为第i个人的第j次采样特征,µ为全局均值,V表示类间差异空间,U表示类内差异空间,zij为残差.µ+Vyi是wij的信号分量(只与i相关),Uxij+zij是噪声分量.
与此前常用的线性判别分析(Linear Discriminant Analysis,LDA)[12]相比,PLDA 同样试图寻找数据的某种低维投影,使得投影后类间差异最大,但PLDA 是一种生成式(generative)模型,考虑了图像由信号与噪声两部分组成并予以显式建模,噪声模型更为完备,因而取得了更好的效果.
在原始PLDA 模型的基础上,由于在语音相关任务中无需求解类内差异,文献[13]中引入了简化的PLDA模型:
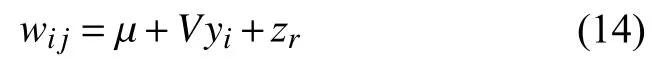
其中,隐变量yi服从标准高斯分布,类内差异被合并为zr,其协方差为Σ.
使用EM 算法训练PLDA 模型,迭代优化完全数据的对数似然函数的期望Q得到最合理的参数θ={µ,V,Σ}:

随机初始化矩阵V、Σ.E 步骤中,更新隐变量y的后验分布只需估计其均值和方差:
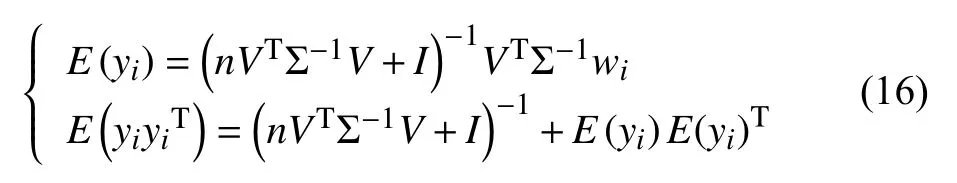
M 步骤中,更新矩阵V、Σ:

其中,N为训练i-vector 总数,n为yi所属的语句对应的i-vector 总数.
测试阶段,给定两条待比对的i-vectorw1、w2,假设 Hs表示二者由相同的因子y生成,Hd表示二者由不同的因子y生成,PLDA 模型通过计算两种假设的似然值得分给出w1、w2之间的相似度:

其中,Σtot=VVT+Σ,Σac=VVT.
与1.1 节中基于似然比的置信度对比可以发现,PLDA 可以比较自然地作为一种置信度计算方法,以语音整体的i-vector 作为输入,不依赖声学模型和语言模型即可完成似然比检验.
2.4 孤立字语音识别置信度检验实验
音节是汉语发音的基本单元,因此考察i-vector 特征对音节的置信度的检测能力,是该方法能否成功应用于连接词识别置信度检验的基础.本实验采用IsoWord孤立字数据集,其包含了50 名男性、50 名女性、每人1254 个有调音节,覆盖了汉语的全部具有实义的音节,采样率16 kHz.随机选取1 名男性的语音样本作为测试集,其余作为训练集.使用1.1 节中的拒绝率和拒绝后的识别准确率评价系统的性能.
本文采用45 维MFCC 特征,对输入的单帧语音信号,去除直流,预加重(系数取0.98),加汉明窗(帧长20 ms、帧移10 ms)后,提取14 维Mel 倒谱系数,对相邻帧计算一阶、二阶差分系数,并加入三者的归一化能量系数.
为了确定理想的模型参数,本文首先在识别率有代表性的数据样本上进行了调参实验,调整的参数包括UBM 混合分量数和i-vector 维度.可以观察到不同参数的组合对性能有微小的影响.以第25 号孤立字男声样本为例,实验结果见表1和表2.
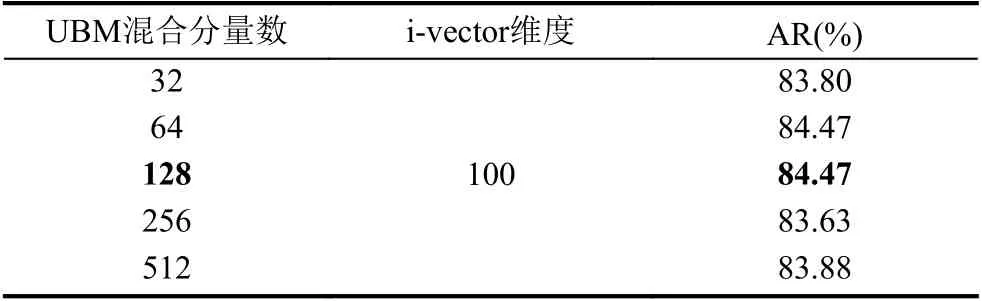
表1 UBM 混合分量数对性能的影响

表2 i-vector 维度对性能的影响
根据调参实验结果,本文在孤立字的置信度判决实验中,UBM 模型混合数取128,i-vector 维数取100.
在确定了模型参数后,在训练阶段,首先训练UBM模型,对每条语音计算所需的充分统计量,然后训练ivector 模型的T矩阵.参照文献[14]中的建议,使用已知的语音对应的说话内容作为训练标签,对i-vector 预先做LDA 降维,从而初步补偿类间差异.由于文献[13]中发现i-vector 具有较强的非高斯性,为使其符合前述基于高斯假设的PLDA 模型,参照文中建议对i-vector做白化与长度规整后,再训练PLDA 模型,PLDA 因子维度与LDA 维度相同(不再做进一步降维).每条语音的代表i-vector 取该语音所有说话人语音样本对应的i-vector 的均值.测试阶段,将测试语音通过训练集上训练好的UBM 模型、T矩阵、LDA 矩阵,得到测试ivector,在PLDA 模型上与每条语音的代表i-vector 逐对计算似然值得分.部分实验流程使用MSR Identity Toolbox[15]完成.
图1、图2为采用基线系统和i-vector+PLDA 对随机两组男声孤立字各1254 个发音样本置信度检测的RR-AR 曲线.可以看出,不论是对于原本识别率较低还是较高的男性语音样本,i-vector+PLDA 都能通过拒识提高其性能,且效果较基线系统有一定的提升.

图1 第17 号孤立字男性语音样本上的RR-AR 曲线

图2 第50 号孤立字男性语音样本上的RR-AR 曲线
表3为将RR固定为5%时,各系统在所有男声样本上轮流训练测试的平均性能,其中原始无置信度辅助的GMM-HMM 孤立字识别系统的平均识别率是89.81%.可以看出置信度的拒识使系统输出的正确率绝对提高约2%,且i-vector+PLDA 相比基线系统再绝对提高约0.3%.

表3 置信度辅助的系统在IsoWord 数据集上的性能
2.5 连接词短语置信度检验与拒识实验
连接词实验采用的SbPhrase 短语语料数据库包含了699 条四字短语,较为均衡地覆盖了所有的汉语音节及音节间的连接关系,可以较为客观地评测命令词系统的一般性能.该数据库包含了50 名男性、50 名女性的录音样本,采样率16 kHz,每条短语时长约1 s.
置信度检验实验中,以前25 名男性的所有短语语音作为训练集,训练GMM-HMM 系统,其余男性语音作为测试集,并使用置信度对识别结果做后处理.MFCC特征提取与2.4 节相同,根据实验调整i-vector 提取参数为512 分量UBM、200 维i-vector.
图3、图4为随机两个男声连接词短语样本置信度检测的RR-AR 曲线.
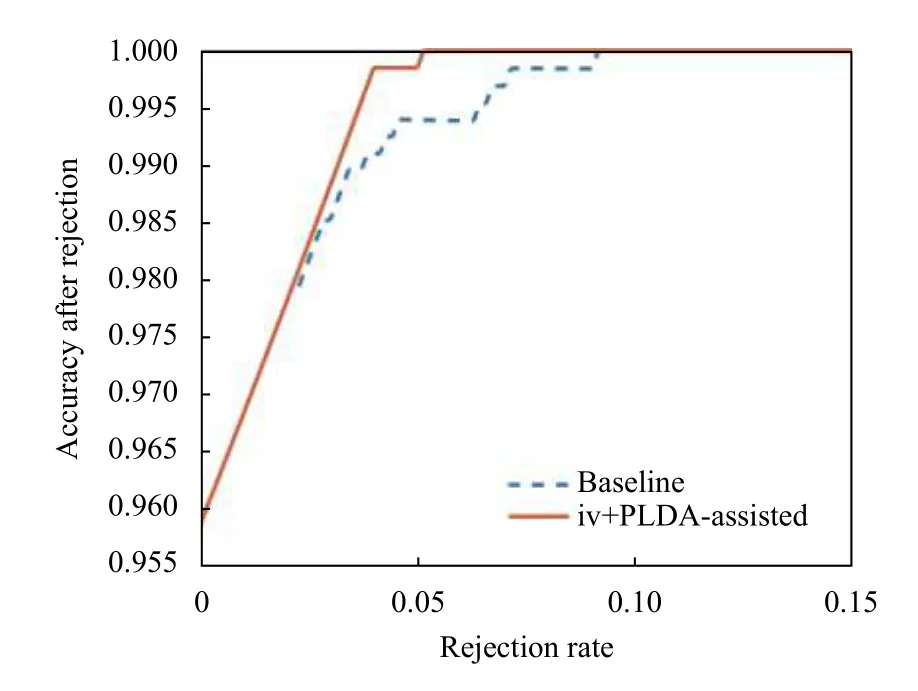
图3 第30 号男性连接词语音样本上的RR-AR 曲线

图4 第41 男性连接词语音样本上的RR-AR 曲线
表4为将RR 固定为5%时,各系统在所有样本上的平均性能,其中原始GMM-HMM 连接词识别系统的平均识别率是95.97%.与孤立字类似地,置信度的引入提高了系统的识别性能,而i-vector+PLDA 的效果更佳.

表4 置信度辅助的系统在SbPhrase 数据集上的性能
在命令词识别系统中,对集外词或噪声的有效拒识至关重要,我们通过实验单独测试了系统的拒识性能.仍然使用SbPhrase 数据库的男声部分,取数据库中的前300 条短语作为集内词训练PLDA 模型并确定其阈值,其余作为集外词进行实验.除此之外,采用从CMU NoiseX-92 数据集[16]中截取的噪声片段考察系统对噪声的抵抗能力,该数据集包含了白噪声、工厂噪声、背景说话声等常见噪声类型.使用虚警率评价系统的性能.
表5中的结果表明,i-vector+PLDA 系统性能良好,不论对语音类的集外词还是非语音类的干扰噪声都具有较高抗性,保证了系统的稳健性.

表5 i-vector+PLDA 系统的集外词、噪声拒识性能
3 融合DTW 的置信度判决方法
3.1 i-vector 时序鉴别能力分析
在2.1 节中已经指出,GMM-UBM 模型通过自适应得到每条语音对应的GMM 模型,这种建模方式的一个缺陷是不包含时序信息:对于仅字序、词序不同的语音,由于使用了相同或相近的音素,全局上看,各自的特征集内其特征分布彼此相似,因而在这类系统上会体现为相似度较高.换言之,虽然i-vector 的全局描述能力较好,但缺乏对其中时序信息的描述,理论上,若单独使用i-vector 特征,对于较长的命令词导致鉴别力下降的可能性会增大.在实际应用中,这会导致部分与命令词在字序、词序上相似的集外词无法被系统有效拒识,引发不必要的虚警.
有鉴于i-vector 的上述特点,一种解决方法是利用命令词识别系统在识别时给出的最佳音节分割点,对组成命令词的每个音节或是单词分别进行确认,如在汉语系统中可以检验组成命令词的单字,此时系统对这些单元的分辨能力则至关重要,这点在2.4 节中已经予以验证.然而,此种实现依赖于上游的分割结果,为系统带来了新的困难.除此之外,另一种思路则是尝试增强系统本身的时序鉴别能力.
例如,在i-vector 框架下,一般通过隐马尔科夫模型(Hidden Markov Model,HMM)、长短期记忆网络(Long Short-term Memory,LSTM)等时序相关的模型建模时序特征,产生新的i-vector 或作为已有i-vector的补充.文献[10]对比了i-vector、d-vector、s-vector三种特征对不同语音特性(如说话人身份、说话速度等)的刻画能力.其中对于词序特性,该文通过在两段拼接顺序不同的语音上的分类任务予以验证,在此实验中i-vector 的鉴别效果较差,接近随机猜测,说明其几乎没有时序鉴别能力,而基于LSTM 的s-vector 效果突出,因此该文通过拼接二者得到所谓i-s-vector,在包括词序区分的大部分任务上均取得了最优结果.Hossein 等[17]则提出使用HMM 代替GMM 作为UBM模型的基础,通过对每个音素训练HMM 并拼接,得到特定语句的HMM模型,由此模型产生的i-vector 与语句的相关性更强.
上述方法通过引入其它时序相关的模型增强ivector 的时序鉴别性能,其共同局限性在于需要与语句相关的信息,如每段语句的音素标签,用于训练对应的HMM 或神经网络模型,而实际应用中我们希望在仅具备录入语音,没有关于语音内容知识的情况下,完成系统的训练.动态时间规整(Dynamic Time Warping,DTW)算法[18]是语音领域的经典方法之一,其通过对语音序列进行非线性扭曲实现序列间对齐,从而求取相似度,算法直观且易于实现,其约束条件决定其适于衡量时序差异,且不依赖语音以外的信息.因此,本文提出将DTW 与原有i-vector+PLDA 系统融合,期望二者融合而成的系统可以兼顾i-vector+PLDA 的低错误率和DTW 的时序鉴别能力.
3.2 得分计算、似然比校准与系统融合
DTW 算法产生两段序列之间的相似度得分,而在很多命令词系统中,单个词语对应存在多个模板(训练语音片段).本文中将目标语音在某词语下所有模板上的DTW 得分的平均值作为该语音与此词语的相似度.
尽管上述得分与对数似然比同为相似度的体现,但由于计算方式、统计特性上的差异,数学上二者并不相容.本文采用文献[19]中的逻辑回归校准方法,通过在同源、不同源得分上训练二元逻辑回归模型得到模型系数,并校准原始得分s,使其等价于对数似然比:

系统融合采用两系统似然比的连乘,即对数似然比的简单相加:

3.3 逆序短语拒识实验
第2.5 节实验中使用的SbPhrase 数据集不含有实验所需的音素相近但字序不同的短语对,因此为SbPhrase 中前50 条短语重新采集语音,构建小型子数据集SbPhrase-T.对于每条短语,除其正序(如“曼彻斯特”)外,另行采集部分逆序(如“斯特曼彻”) 和完全逆序(如“特斯彻曼”)两份语音.将SbPhrase 中前50 条短语作为集内词训练i-vector+PLDA 系统,将两种逆序语音作为集外词进行拒识实验.
图5为短语的3 种字序在原系统上对数似然比得分的混淆矩阵(confusion matrix),展示了所有语音在所有正序短语的PLDA 模型上的相似度情况.其中,为方便横向比较,横轴每3 列对应一条短语,其下三列依次对应正序、部分逆序、完全逆序语音的得分.观察对角线可以发现,两种逆序语音在其对应序号正序模型上的得分总体较高,说明系统不能将其有效拒识,再次确认了前述i-vector 在时序鉴别能力方面的弱点.

图5 原系统的混淆矩阵(部分)
图6为DTW 与i-vector+PLDA 系统融合后,新系统上得分的混淆矩阵,经DTW 修正后,混淆矩阵的对角线更加清晰,两种逆序语音的得分明显降低,接近背景(短语不匹配情况)水平.
表6为两种系统对逆序语音拒识的量化实验结果.数据表明,相比单i-vector+PLDA 系统,融合系统有效降低了系统在逆序语音上的虚警,说明DTW 得分的引入提高了系统的时序鉴别能力.
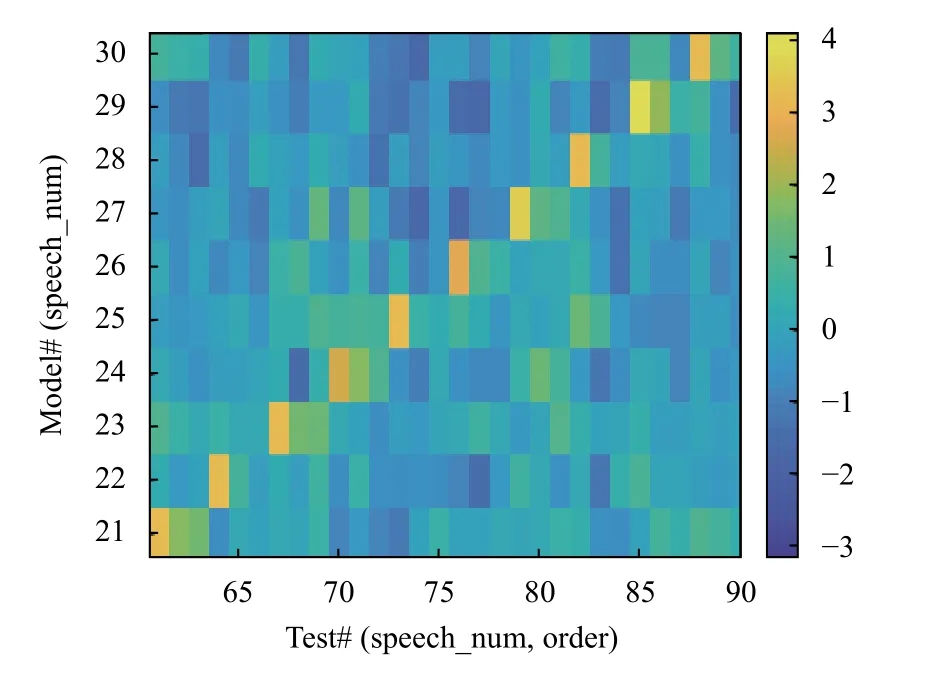
图6 新系统的混淆矩阵(部分)

表6 不同系统在SbPhrase-T 数据集上的拒识性能
4 i-vector+PLDA 置信度应用意义分析
相比传统的置信度估计方法,上文提出的基于ivector 和PLDA 以及融合DTW 的方法具有两点优势:
其一,无需训练声学模型及语言模型.传统方法,特别是基于后验概率的置信度判决方法,依赖基本语音识别单元(如音素或音节)声学模型的似然值得分和相应的声学模型.这些信息常常与特定系统及其使用的声学模型、语言模型相关,迁移至传统语音识别系统的诸多变种以及未来更新颖的语音识别框架中存在困难.本文方法训练过程则仅需语音及对应的类别标签,外部系统不额外提供其他先验的声学和语言模型信息,一方面使得系统结构直观、易于实现,另一方面因为无需考虑前端系统的实现细节,可以独立测试与部署,达成一定程度的模块化,使用更加灵活广泛.
其二,无需提供语句内容相关信息.实际应用中,很多命令词系统通过非确定性的命令词加强安全性或保证用户体验.例如,用户可以根据个人喜好为智能音箱、手环等智能设备录入自选的唤醒词,后续通过该词唤醒设备进入工作状态.此类场景中,设备在录入阶段无法获知命令词的内容,因此文献[10,17]中的方法缺乏训练所需的标签.本文方法通过DTW 完成时序信息的补充,避免了对此类“标签”的依赖,可以应对较为复杂多变的命令词.在电话银行、智能家居等应用中,通过本文方法对语音识别系统的结果进行验证,既有助于降低错误,提升用户体验,同时仍不失原系统交互过程中的灵活性,对命令词系统的改进具有实际价值.
此外,第2 节的置信度检验实验结果中,本文方法辅助语音识别系统对连接词识别率的提升相比孤立字更为显著.越长的语音片段,其中包含的语音内容信息越丰富,通过相应增加UBM 混合数和i-vector 维度,得到的i-vector 能够充分包含此信息,而特征信息量的增加也有益于PLDA 对有用信息的分离与鉴别.因此,相比孤立字,本文方法更适合用于词语、短句等较长的语音.
5 结束语
本文提出将i-vector 以及PLDA 模型用于置信度判决.i-vector 语音特征包含了包括说话内容在内的各种差异信息,利用PLDA 可以中和其他信息的影响,有效鉴别说话内容,且其形式上符合基于似然比的置信度分析,在孤立字、连接词实验中体现出了良好潜力.通过与DTW 融合,补充缺失的时序信息,得到不依赖声学、语言模型以及语句标签的置信度分析方法,在应用中较传统的置信度分析方法有其独特优势.
猜你喜欢
电子技术与软件工程(2022年15期)2022-11-11
导航定位学报(2022年5期)2022-10-13
小型微型计算机系统(2022年4期)2022-05-09
小猕猴智力画刊(2022年3期)2022-03-28
农业工程学报(2022年1期)2022-03-25
意林·作文素材(2021年23期)2021-01-22
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
发明与创新·中学生(2017年5期)2017-05-12
中国科技纵横(2016年20期)2016-12-28
