
智慧园区电动汽车有序共享充电需求分析①
2021-01-22 05:43石进永赵明宇汪映辉
计算机系统应用 2021年1期
石进永,赵明宇,汪映辉
1(南瑞集团(国网电力科学研究院)有限公司,南京 211106)
2(国电南瑞南京控制系统有限公司,南京 211106)
电动汽车是当下新能源产业重要组成部分,是缓解能源危机及环境问题的有效工具[1,2].目前,我国在电动汽车充换电设施标准体系建设、关键技术研究、关键设备研制和示范工程建设等方面已取得重要进展.但同时,我国当前普遍应用的电动汽车充电系统无法满足用户个性化充电需求.因此,通过对电动汽车充电技术的不断创新和优化,采取科学合理的控制策略,可以改善整体电力系统管理和能源效率,同时也可以使电力系统的运行更加清洁、高效和经济[3,4].
智慧园区能源管理和配置问题分析是掌握用户和电力市场的重要手段,尤其随着充电设施的广泛接入,更需要优化配置智慧园区能源形式.文献[5]为了充分利用电力大数据中的异构数据源挖掘出电网中存在的安全威胁,采用循环神经网络对得到的嵌入式向量数据建立画像,实现了数据中异常事件的检测;文献[6]提出一种面向电动汽车、快速充电站、配电网多元需求的电动汽车快速充电引导策略;文献[7]基于电动汽车充放电优化模型以及实时更新的配电系统预测负荷曲线,构造出动态分时电价更新策略;文献[8]提出基于不确定性测度的居民小区电动汽车充电定价策略并建立起电动汽车充电负荷动态概率模型,分析了电动汽车响应分时电价的不确定性而导致的居民负荷随机波动加剧等问题.文献[9]提出一种在线控制和离线优化相结合的有序充电控制方法,在电动汽车用户在住宅区利用夜晚时段进行充电的情况下,解决了移峰填谷、减少负荷波动的问题.
上述文献对电动汽车充电方式及策略研究较深入,但缺乏智慧园区电动汽车有序共享充电需求及管理模式研究.基于此,本文利用电动汽车(Electric Vehicles,EV)潜在的移动储能特性,提出一种适用于智慧园区共享充电桩的在线自主充电需求建模分析方法,在自动检测和识别用户电动汽车充电需求基础上,将其转移至电价较低时段以加强对住宅小区电力需求的管理.首先提出一种在线识别不同类型电动汽车的方法,采用基于人工神经网络监督学习方法分类得出每个电动汽车类别信息,并用支持向量机(Support Vector Machines,SVM)方法验证所提方法的可行性;其次,根据分类信息利用功率谱密度估计为每个EV 提供统计模型,进行统计分析;最后根据台区接收的日前负荷响应指令预测充电需求,对充电习惯采用核密度估计建模,利用实测数据证明该方法的可行性和有效性.
1 智慧园区EV 共享充电场景分析
依据园区已有能量管理系统(Energy Management Systems,EMS)需求响应策略,在确保用户舒适度的前提下,实现共享充电[10],图1展现一个典型的园区EV调度场景.车主进入园区后,EMS 确定该EV 及充电需求后,根据来自其他EV、电器和电价等信息制定该EV 充电计划.
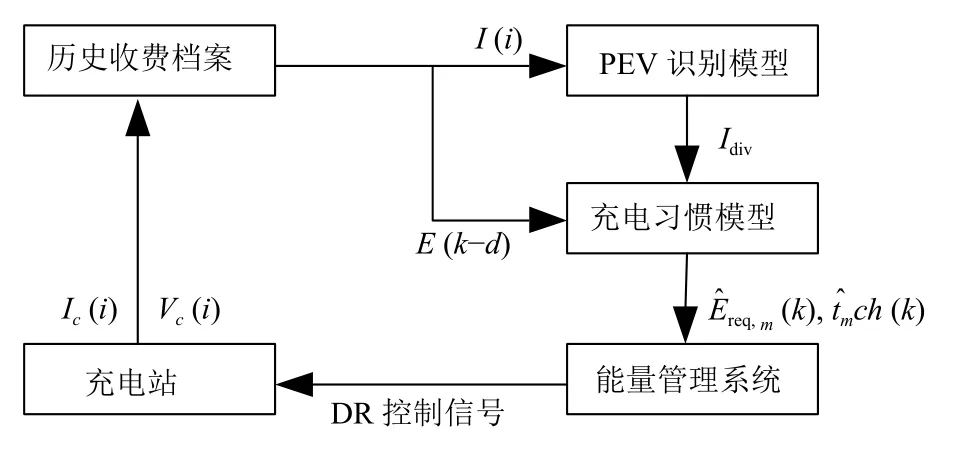
图1 智慧园区EV 典型充电场景
假设该园区已建M个共享充电桩,第m个EV 最佳充电起始时间tst,m取决于其充电所需电量Ereq,m和对应充电桩可用时间tav,m.EMS 可以利用每个EV 充电习惯统计建模,预测充电电量需求和高峰时段负荷优先级.
设Ereq(T)为某天充电站所需总能量,T表示24 小时.

其中,Ereq,m(i)为当天第m个EV 充电所需电量;Pm(i)为第m个EV 瞬时充电功率;Δt为时间步长.

其中,V(i)为时段i处的充电点电压,Im(i)为充电点电流的测量值,c os(φm(i))为功率因数.
EMS 的目标是估测Ereq,m(i+p),其中p是预测范围(p>0).假设Δt和V(i)是常数,因此该问题可简化为预测Im(i)的任何可能值.这主要取决于第m辆EV 的充电计划、电池容量以及电池初始充电状态(State of charge,SOC)SOCini,m.对于一个共享充电站,如何用当前测量值来预测未来Ereq,m值是一个挑战.本文采用两步法来解决该问题:第1 步识别每个单独EV 充电情况;第2 步建立并更新之前识别的每个EV 充电模式统计模型.通过提出的EV 识别算法来支持EMS 的最终目标或功能.通过这种方式,可以预测每辆车的充电需求,从而优化充电策略.
2 EV 充电识别模型
模式识别和数据分类过程在各个领域一直都引起广泛关注[11].在本文中,共享充电站下的EV 充电识别问题是使用小样本电流测量对M辆EV 充电配置进行分类.这种识别EV 的方法不需要任何额外昂贵的安装费用.然而,由于在相同的电池容量范围内,EV 充电电流幅值有明显的相似性,这也带来了一个很大的挑战.用于EV 识别方法分两步,第1 步是提取和选择交流充电电流原始样本特征,旨在创建有区别的特性,帮助提供更有效的分类;第2 步是对候选车辆充电曲线的电流幅值进行分类[12].Idiv是充电识别后的分类电流幅值.
2.1 信号特征提取
识别过程为了避免共享充电站混淆不同车辆,需要算法足够精确可靠,需要从原始的充电电流测量中提取有用的识别特征,以便在相同的电池容量范围内对不同的车辆分类正确.基于输入信号的不同物理性质,选用的信号特征也不同,在时域中常用的特征是一阶统计量和高阶统计量;在频域中常用的特征包括小波系数、FFT 和功率谱密度.因此需要选择一个包括丰富信息的特征空间,通过图2所示的序列前向选择法选择最优特征.

图2 序列前向选择特征
序列前向选择法从空集开始,每次选择一个新的特征fi+加入特征子集Fsubset,k使特征函数J(Fsubset,k+fi)最优化,得到的特征子集就是最佳分类[13].针对智慧园区共享充电需求分析,需考虑尽可能多的充电特征,因此选取一组12 阶的特征向量,见式(4)、式(5),其中包括原始样本、Welch 功率谱密度估计、Thomson 功率谱密度估计、标准差、偏度、第6 个非中心矩以及用离散小波变换从测量样本中提取的3 个不同分辨率信号的标准差,并选择了最常用的哈尔特征.

其中,σrw是测量样品的偏度;Rwdata为交流充电电流的原始样品;PSDW和PSDT分别为Welch 功率谱密度估计和Thomson 功率谱密度估计;s为测量样品的标准偏差;t6是第6 个非中心时刻;和分别是第i级标准差的小波分解近似系数和细节系数.
2.2 用于EV 识别分类方法
2.2.1 前馈神经网络
前馈神经网络是模式分类任务中最常用的一类神经网络[14].本文所使用的网络拓扑结构为两层前馈神经网络,如图3所示.
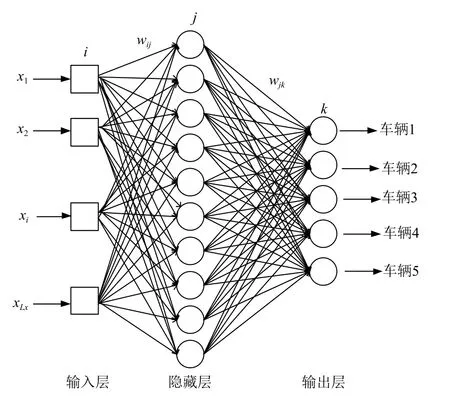
图3 两层前馈网络拓扑图
在隐藏层中,激活函数Zj和非线性激活函数σj分别由式(6)和式(7)定义.所使用的非线性激活函数为Sigmoid 函数.
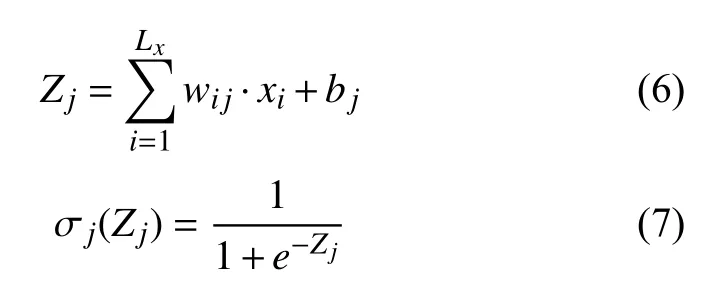
其中,wij和bj分别表示隐藏层的权值和偏差;xi是输入特征;Lx是输入层的神经元数量.
在输出层,激活函数Zk和非线性激活函数yk分别由式(8)和式(9)定义.所使用的非线性激活函数为Softmax 传递函数.

其中,wik和bk分别表示输出层的权值和偏差;Lh是隐含层的神经元数量.

对于目标矩阵,每一列表示为:

2.2.2 支持向量机
支持向量机(SVM)是一种在模式分类和识别方面表现出良好性能的监督分类器[15,16].最优的分离超平面将是边界最大的超平面,定义为数据到决策面的最小距离(对应于图4中的超平面).准确落在边界上的训练数据称为支持向量,支持最大边界超平面.

图4 用ci 和cj 两类样本训练支持向量机的最大超平面和边界值示意图
构造nclass×(nclass−1)分类器,其中nclass在类的数量中与两个不同类的数据组成一个序列.鉴于ci和cj的训练数据(x1,y1),···,(xij,yij)已知,现将下面的二元分类问题转化为凸二次优化问题.

其中,wcicj表示特征空间中最优超平面的参数;xt是训练样本;bcicj是偏差;是松弛变量;C是正则化参数.考虑分类cm,这种方法是每次一个分类器指出x在cm类中使用决策函数 s gn((wcicm)Txt+bcicm)时,cm类的投票就增加一个,x就是最终得票最多的那一类.
3 充电习惯统计模型
对于EMS 而言,任何一辆EV 充电所需电量主要受充电时EV 的SOC 和预计出发时间影响[17].为了预测电动汽车充电能量需求,需建立充电电量和出发时间的统计模型,确定充电策略中充电优先级.该模型旨在建立一个基于充电习惯和与其他间接观测变量相关的模型,从而为EV 充电调度框架提供一个有效的自动管理.主要使用直方图和核估计对观测到的随机变量行为进行统计建模[18].
3.1 日充电需求直方图
设Em(1)、Em(2),···,Em(N)为第m个EV 的日充电能量测量样本,f(x)为对应的概率密度函数.为了建立直方图,充电能量数据的范围被划分为B1,B2,···,BL,通常选择相同的大小,但也可以改变大小.利用以下公式构建直方图:

其中,countl为数据Em(i)落入Bl的个数,Bl∈B.
3.2 基于插入时间的充电需求直方图
通过整合插入时间方式表述充电需求直方图,利用三维直方图分布对这种相关性进行了建模.因此,插入时间bpa的直方图分布定义为:
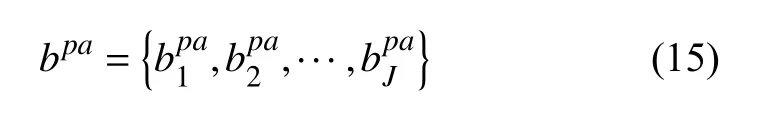
表示Emi在时间落入Bl的个数.
3.3 日充电需求核密度估计
直方图方法的主要优点是易于构造和理解,在统计分析中普遍存在.但缺点是随着样本量的增大,收敛速度相对较慢,密度估计存在不连续,这与底层密度假定的平滑性相矛盾.通过估计核密度可以弥补这两个缺点.这些可以看作是滑动直方图的推广,或者是经验分布函数与光滑核函数的卷积.核密度估计可表示为:
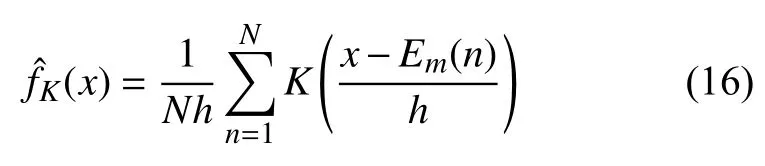
其中,K是一个平滑函数,称为核函数,h>0 是控制平滑量的平滑带宽.Em(i)是日充电能量测量数据的第i个样本.N是测量数据的个数.高斯核函数表达式如下:
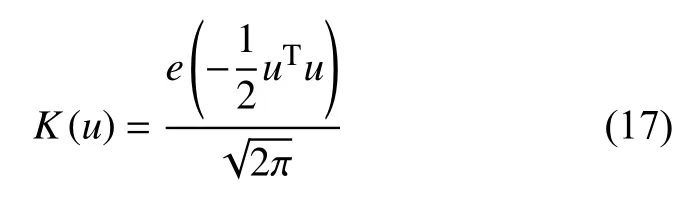
3.4 EV 模型更新
统计建模需要考虑不同充电习惯的随机性.对于每个单独的EV,有必要使用新的测量方法定期更新统计模型,以捕获在能源需求、充电位置和连接时间方面的不同趋势.EMS 首先将不同的消费配置文件存储在数据库中,再使用所提出的识别方法在线更新每个消费分布的新测量信息,并创建图5所示的动态统计模型.

图5 EV 模型更新
4 算例分析
4.1 数据收集
本实验数据采集频率为1200 Hz,并且每秒钟采集一次电网侧的充电电流幅值.通过5 辆电动汽车共享场景对识别算法进行测试.这5 辆车的详细情况如表1所示.

表1 5 辆电动汽车的相关特性
4.2 EV 识别模型
EV 识别部分使用数据库已经分成两组,如表2所示.第1 个数据库包含83 个充电数据(2019年8月5日~25日),第2 个数据库包含49 个充电数据(2019年9月6日~20日).对于所有提出的结果,EV 识别是通过车辆接入后使用300 个测量窗口来呈现.

表2 识别过程中每个EV 的充电数据的数量
4.2.1 基于前馈神经网络分类器的EV 识别
模型构建和在线性能测试采用独立数据.对于模型的构建(训练70%、验证15%、测试15%),使用表2中的数据库1.然后在线测试建立在数据库2 中收集的新数据上的模型的性能.用Matlab 神经网络模式识别进行分类.
在输入层,从测量样本中提取的12 个特征,如表3所示.识别过程通过300 个测窗口进行,故F1 的维度为300,通过计算确定Welch 功率谱密度估计、Thomson功率谱密度估计的FFT 长度为2 的7 次幂及2 的8 次幂,其特征空间维度分别为129 与257,其余特征空间维度均为1.输入层的神经元最终数量即所有特征空间维度之和为695.通过改变隐藏层神经元的数目进行了多次模拟,最后选择了包含10 个神经元的隐层.分类结果如图6所示.虽然不同车辆的充电电流幅值非常相似,但该方法在5 种电动汽车的分类方面表现出了非常令人满意的性能,在验证和测试阶段全部识别.离线构建后,对数据库2 中49 个新的充电电流测量值进行了在线测试,如图7所示.因为该模型成功地识别了5 种EV,准确率达96%.在充电的49 次测量中,对两辆车的识别只出现了两次混淆.此外,增加训练数据库的大小可以改进识别过程.本次验证研究中用于识别的EV 类数量为5 个.这个数可少可多,取决于小区内的EV 用户数量.

表3 前馈神经网络输入层中使用的特征值

图6 数据库1 前馈神经网络分类结果

图7 基于数据库2 模型的在线验证性能分类结果
4.2.2 特征选择和模型敏感性研究
特征选择就是从提取的特征中挑选出最有用的子集特征.将序列前向选择方法应用于695 个特征的初始特征空间,以选择最合适的子集特征,再将得到的子集特征与使用所有特征空间得到的子集特征的识别模型进行性能比较.此外,还使用了不同大小的数据库进行特性选择.所选的子集特征维数为3 和10.在对几个核函数进行仿真评估后,选择一个线性核函数作为支持向量机分类器.研究4 种场景(即25%、50%、75%和100%)的数据来选择不同的子集特征,使用相同比例的数据库1 用于训练,数据库2 用于测试阶段,用获得的子集特征测试EV 识别模型泛化能力.
利用式(5)中局部最优特征得到的序列前向选择结果和精度如表4所示.从不同的场景中得到的结果表明,在原始信号和用Welch 和Thomson 方法估计的功率谱密度中,信息丰富的特征更加集中.敏感性研究还强调了数据库大小对选择子集特性的重要性,以及数据库中包含的数据质量.随着更多的数据被用来选择特征,序列前向选择算法更好地收敛到全局最优特征.不同规模数据库4 种场景中利用所有特征空间的性能几乎相同,如图8所示.

表4 不同数据库SVM 分类器子集特征选择结果
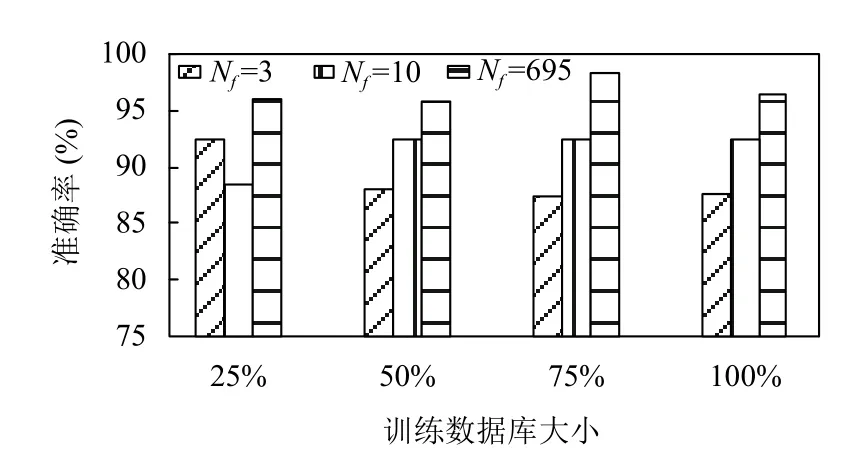
图8 不同数据库规模的EV 识别模型的泛化能力与支持向量机分类器的最优特征比较
4.2.3 支持向量机和前馈神经网络性能比较
使用相同的输入特征和数据库,将SVM 分类器的性能与前馈神经网络分类器进行了比较,所利用的特征是全局最优特征.随机生成的数据库1 的75%为训练数据库,而数据库2 用于测试阶段.SVM 分类器采用线性核函数,前馈神经网络采用13 神经元隐层,对比结果如图9所示.

图9 使用最优特征的SVM 分类器性能与前馈神经网络分类器的比较
SVM 和前馈神经网络的性能非常接近,所以这两种方法都适合于EV 识别的实际实现.然而,因为在线应用是本文的主要目标,所以与前馈神经网络相比,SVM 是一种计算开销较大的方法.SVM 由多个分类器组成,考虑分类器的数量就增加了计算时间.而前馈神经网络可以只用一个分类器实现.
4.3 EV 充电需求统计建模
4.3.1 EV日充电需求直方图
直方图是通过将能量轴划分为多个区间B={[0,5],[5,10],[15,20],···,[60,65]}来构建的.
由图10可以看出五种电动汽车的充电习惯非常不同.EV2、EV3、EV4 的分布较窄,带宽较低.因此,他们的能量需求更容易预测.相比之下,EV1 和EV5的消耗分布较为均匀,具有一定的非平稳特性.在这种情况下,充电能量与其他变量如充电时间、天气的相关性研究可以帮助预测充电需求.EV1 统计模型的演变如图11所示.如果某一天EV 没有在小区充电站充电,也可以通过识别模型捕捉到这一点.

图10 5 个EV 历史充电能量的直方图和核平滑图
4.3.2 根据插入时间和工作日充电需求直方图
针对EV1,根据插入时间和星期几构建了充电能量需求的直方图模型,结果如图12和图13所示.
从图12可以看出,充电到EV 电池电量与EV1 的连接时间有关.同样,从图13中可以看出,充电能量需求也与EV1 的星期几有关.因此,对于EV1,EMS 利用与日期中某些变量的相关性来预测充电所需的能量.而其他变量可以减少估计误差,比如是否晴天,是否下雨或下雪等天气数据.

图11 EV1 的在线统计建模
5 总结
在当前面向智慧园区电动汽车充电模式和充电策略研究基础上,本文针对用户自主充电需求管理提出了一种适用于智慧园区有序共享充电需求分析模型.通过对电网侧充电电流测量,实现了对单个充电电动汽车充电习惯的在线识别和统计建模.由于识别EV所需的充电电流样本更少,首先分析了小区能量管理系统协助管理共享充电站充电调度任务;然后通过人工神经网络监督分类,建立识别模型在线识别EV,针对EV 充电习惯建立统计模型,预测其充电能量需求,其中充电习惯包括电池充电状态、电动汽车插入时间以及是否是工作日;最后,根据采集实测数据验证了所提出建模方法的有效性,为将来新兴住宅小区规模化电动汽车有序共享充电提供帮助.
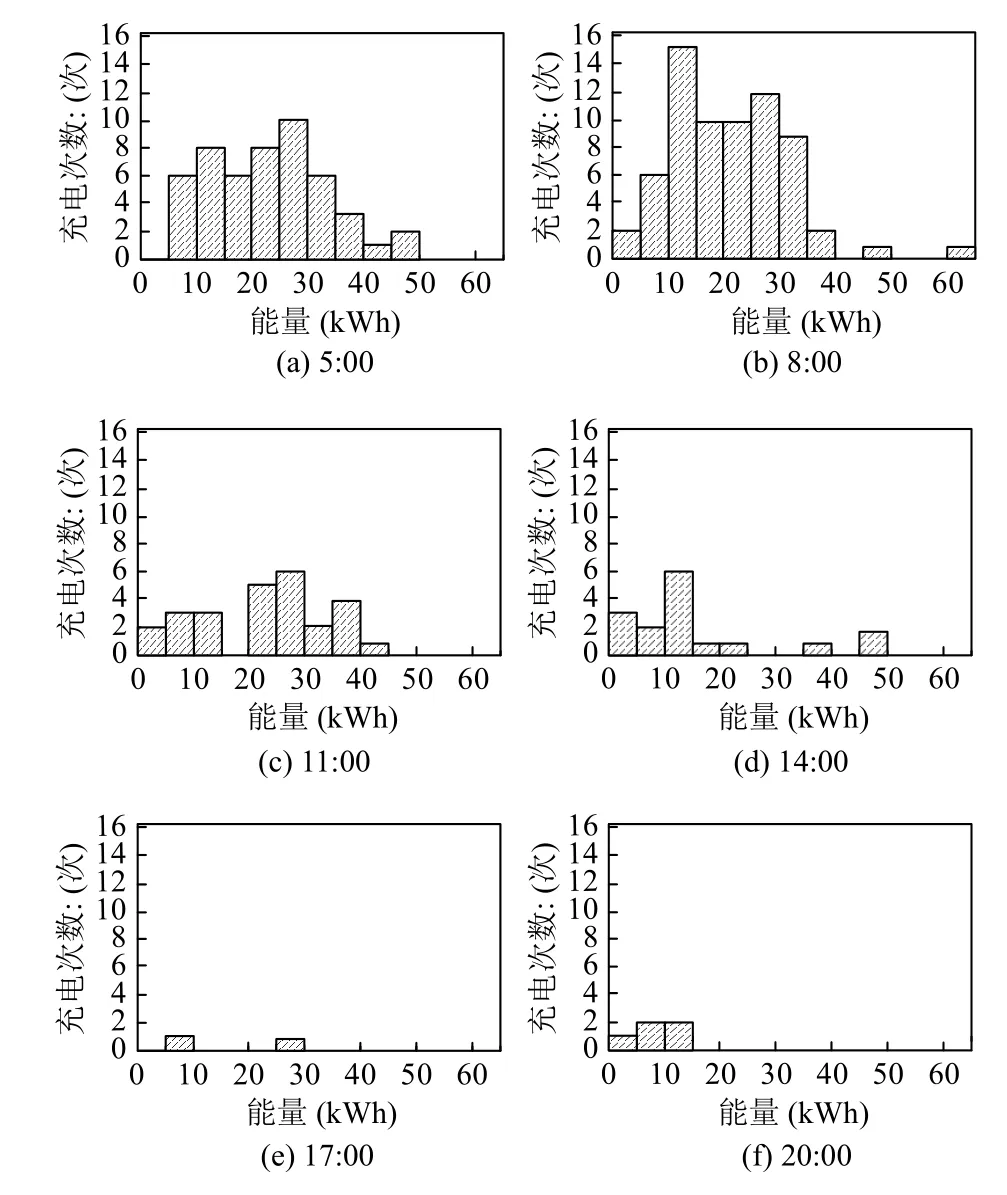
图12 EV1 插入时间与充电能量直方图
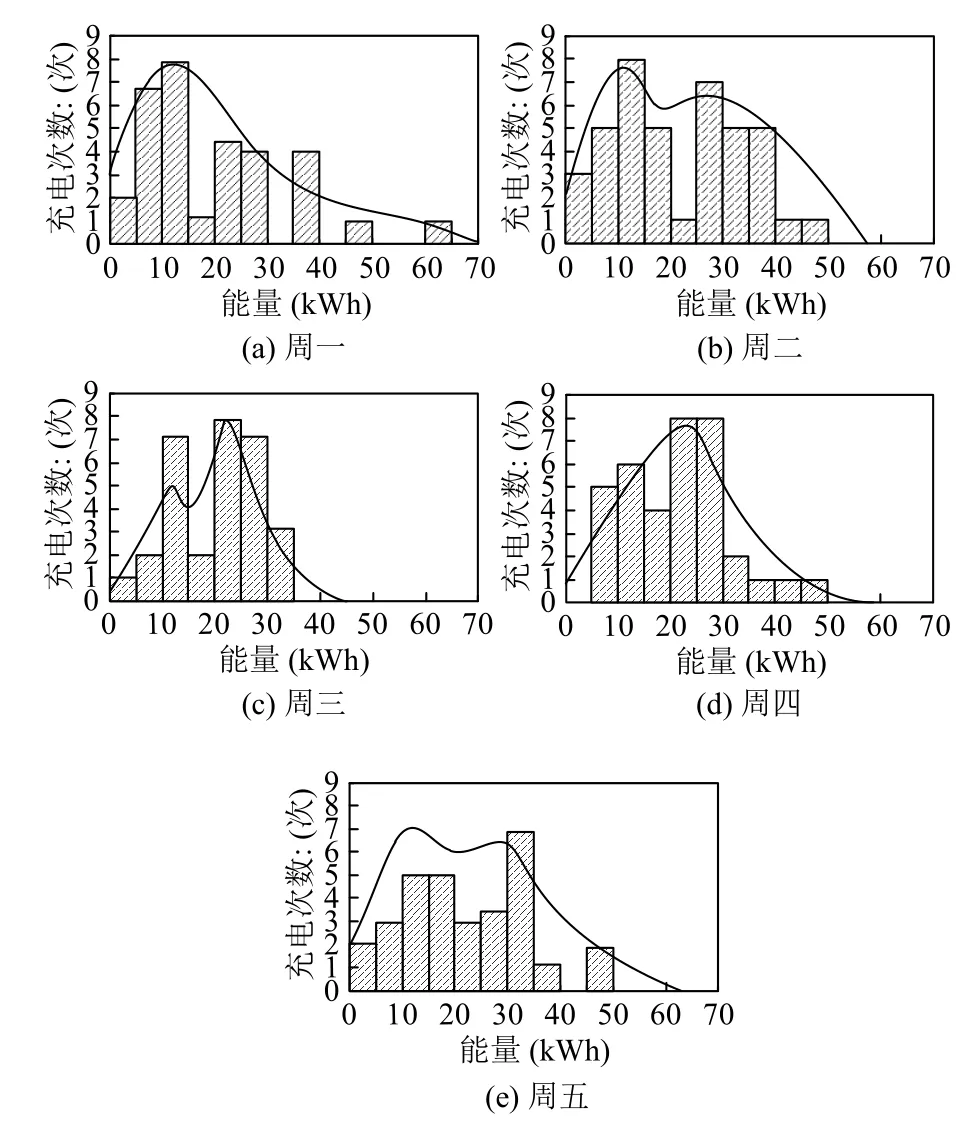
图13 EV1 充电能量的直方图和核平滑图
猜你喜欢
现代电子技术(2022年15期)2022-07-28
舰船科学技术(2022年11期)2022-07-15
中国教育信息化·高教职教(2022年4期)2022-05-13
电子产品世界(2022年4期)2022-04-21
煤气与热力(2022年2期)2022-03-09
计算机系统应用(2021年2期)2021-02-23
影像视觉(2018年12期)2018-11-29
软件(2017年6期)2017-09-23
软件导刊(2017年4期)2017-06-20
中学生数理化·高一版(2017年2期)2017-04-25
