
一种基于随机掩码的低通信量Logistic回归外包训练方案
2021-02-11 09:31黄晓文王政杰崔硕硕张宇浩邓国强
科技资讯 2021年34期
黄晓文 王政杰 崔硕硕 张宇浩 邓国强



摘要:Logistic回归是一种典型的机器学习模型,因其在疾病诊断、金融预测等许多应用表现优越而受到广泛关注。logistic回归模型的建立不仅依赖于算法,更依赖于大量有效的训练数据。尽管构建高精度模型并提供预测服务有诸多优点,但用户的敏感信息数据造成隐私问题。因此,该文提出一个新的logistic回归外包训练方案。在该方案中,用户会预先对私有数据进行处理,并添加随机掩码的数据矩阵上传给聚合器,聚合器将聚合得到的全局训练矩阵上传给云服务器进行训练。该方案在满足数据隐私的安全性需求下具有较高的计算效率和较低的通信开销。
关键词:Logistic回归隐私保护随机掩码低通信量
中图分类号:TP309 文献标识码:A 文章编号:1672-3791(2021)12(a)-0000-00
An Outsourcing Training Scheme of Low-traffic Logistic Regression Based on Random Mask
HUANG XiaowenWANG ZhengjieCUI ShuoshuoZHANG YuhaoDENG Guoqiang*
(School of Mathematics and Computing Science, Guilin University of Electronic Technology, Guilin, Guangxi Zhuang Autonomous Region, 541004 China)
Abstract: Logistic regression is a typical machine learning model, and its superior performance in many applications such as disease diagnosis and financial forecasting is widely welcomed. Providing user data to the server for logistic regression is a new service mode. Although predictive services have many advantages, the user 's sensitive data itself has privacy problems. Therefore, a new outsourcing privacy protection logistic training framework is proposed. In our framework, the user processes the private data in advance, and uploads the data matrix with random mask to the aggregator. The aggregator uploads the aggregated global training matrix to the cloud server for training. The scheme meets the security requirements of data privacy and has high efficiency in computing and communication overhead.
Key Words: Logistic regression; Privacy-preserving; Random mask; Low-traffic
機器学习模型在各种应用领域取得了前所未有的发展[1-3]。然而,由于庞大的数据量,训练过程是一项计算和存储密集型任务。此外,通常针对敏感数据(如医疗记录、浏览历史记录或金融交易)进行训练时,会引发数据集的安全性和隐私问题。
一方面,由于其复杂性,训练过程往往需要外包给如云这样的更强大的计算平台。另一方面,训练数据集通常是敏感的,它可能包含一些敏感或私有信息,一旦披露,将导致灾难性后果。因此,对于参与云计算的数据需要进行隐藏得到密文数据。然而,机器学习算法不能直接访问密文,如果将解密密钥提供给诚实且好奇的云服务器又无法确保数据隐私。由此可见,如何在保护数据隐私的前提下进行高效机器学习训练是一个极具挑战的问题。
Logistic回归是一种典型的机器学习算法,可以理解为一种广义的线性回归,被应用于生物医疗[4],金融服务[5]等分类问题上。近年来,由于logistic回归的广泛使用,数据安全问题受到了更多的重视,学者们针对logistic回归隐私保护问题提出了许多方案。
李娟等研究者[6]基于HEAAN全同态加密,提出有效保护数据隐私的多分类logistic回归模型,可用于安全训练多个分类器,该模型可以在解决多分类问题的同时保证数据的隐私安全。全同态加密是一种特殊的加密方案,可以保证密文下运算得到的输出结果与未加密运算输出的结果一致, 不影响模型的准确率,然而由于涉及复杂的密码学操作,效率上一般比较低。因此,针对纵向分布的数据,宋蕾[7]采用效率更高的部分同态系统Paillier对私有数据加密,通过对数据进行特征维度的划分,将其纵向分布在用户间,通过和服务方进行协同训练,交换logistic训练中间结果而不直接暴露隐私数据。这两种方案需要重复执行复杂度较高的同态运算,并且在每次迭代过程中,需要云服务器与数据所有者进行交互。为了提高隐私保护下训练的效率,也有学者使用差分隐私[8-9]对用户数据进行隐藏,可以有效地处理分布式存储数据并保护隐私,然而这种方法需要对本地数据添加噪声,会对训练出来的模型精度产生较大影响。
该文使用了一种预处理本地数据的方法,用户将其处理完成得到的矩阵添加掩码后直接上传给聚合器,之后便不参与其他任何环节,大幅降低了通信量,为了防止外部攻击使用Paillier对中间数据加密,云服务器解密得到结果之后,相当于在明文下进行模型训练,大量降低了计算成本。
4 数值实验
使用Python编程语言完成了该文所有实验。在两个UCI真实数据集pima和BCD上实现了本文方案,并与明文下做对比以评估方案的性能,数据集详细信息见表1。通过建立类来模拟各个参与方,训练任务在一台个人计算机上进行,该计算机配置为Intel (R) Core(TM) i7-1065G7 CPU,1.5GHz处理器和8GB RAM。
4.1 精度测试
该节对方案进行精度测试并与明文下做对比,使用精准率(Precision)和召回率(Recall)作为评估指标,根据表2给出的实验结果,可见由于本文方案本质上等价于明文下全局数据训练,因此在精度上与明文相比几乎没有损失,证明了方案的可行性较强。
4.2 效率测试
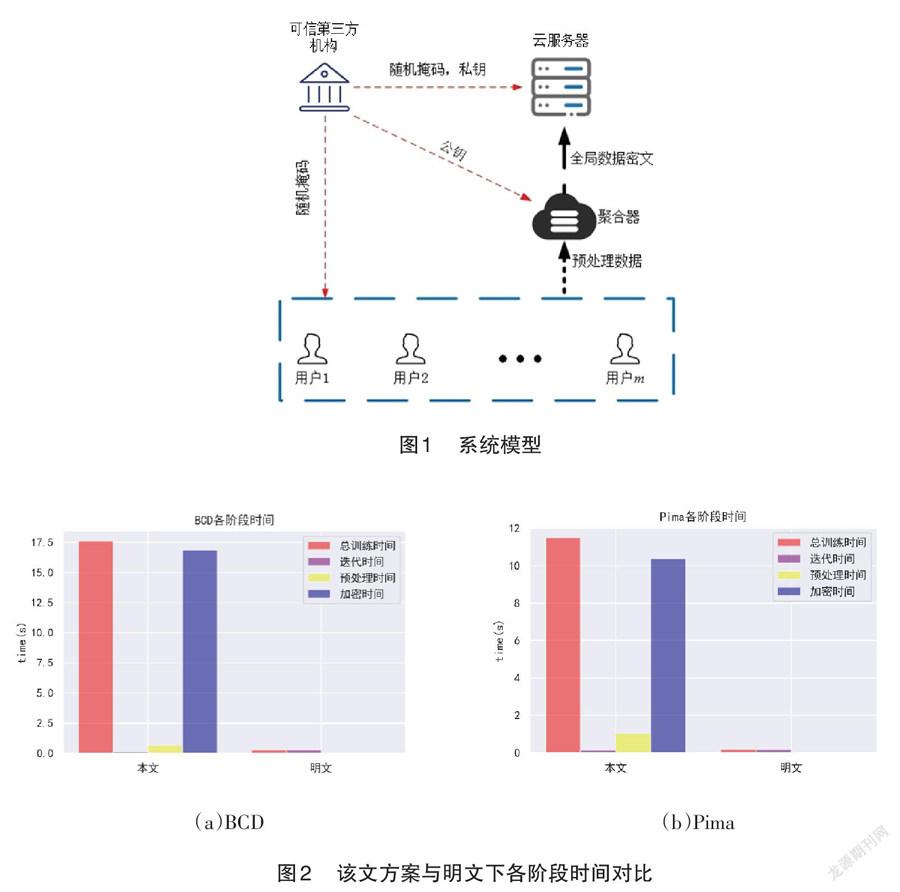
图2(a)-(b)给出的是本文方案与明文下各阶段时间对比,可以看出该方案总训练用时稍大于明文训练的,主要原因在于使用了Paillier同态系统加密数据,这花费了方案的大部分计算开销,但总体上方案表现地依然十分高效,特别是迭代时间几乎与明文训练的迭代时间相同,因此,适合隐私保护需求的logistic回归训练任务。
为了进一步测试迭代次数对方案效率的影响,分别对数据集进行了1 000到5 000次的迭代测试,并与明文训练做对比,测试结果如图3(a)-(b)所示。尽管方案比明文训练时间上多了几秒钟,因为本地用户的预处理都是在明文下进行的,同时使用添加掩码的方式隐藏私有數据,计算复杂度较低,训练阶段云服务器实际也是在明文下训练模型,因此在一定范围内迭代次数对方案效率的影响可以忽略。
5 结语
该文提出了一个新的logistic回归隐私保护方案。通过分离数据,让一些计算任务在用户本地提前将进行,而不必再花费更多的通信开销用于交互。结合随机掩码与加同态秘密系统Paillier,实现了保护数据的目的。通过对比实验发现,在效率稍低于明文的情况下,达到了与明文相同精度,因此节省了大量计算成本和通信开销,能够用于大规模logistic回归外包训练。
参考文献
[1] 周奕文.人工智能技术在眼前节疾病及近视诊疗中的应用[J].中华实验眼科杂志,2021,39(9):821-826.
[2] 沈国良,钱济人.基于系统辨识的机器学习模型参数可调性研究[J].自动化应用,2019(3):97-98.
[3] 饶元,吴连伟,王一鸣,等.基于语义分析的情感计算技术研究进展[J].软件学报,2018,29(8):2397-2426.
[4] 谷鸿秋,王春娟,李子孝,等.基于Logistic回归与XGBoost构建缺血性卒中院内复发风险预测模型的初步比较研究[J].中国卒中杂志,2020,15(6):587-594.
[5] 王宇茜,彭连,夏乙月.基于PCA和Logistic回归的A股36家上市券商排名的研究[J].经济学,2020,3(3):53-55.
[6] 李娟,马飞.基于同态加密的分布式隐私保护线性回归分析模型[J].微电子学与计算机,2016,33(1):110-113,118.
[7] 宋蕾.基于数据纵向分布的隐私保护逻辑回归[J].计算机研究与发展,2019,56(10):2243-2249.
[8] 王璞玉,张海.分布式隐私保护–Logistic回归[J].中国科学:信息科学,2020,50(10):1511-1528.
[9] 葛宇航.基于差分隐私的线性回归分析[J].科技经济导刊,2019,27(14):163-164.
[10] WANG F,ZHU H,LU R,et al.A Privacy-preserving and Non-interactive Federated Learning Scheme for Regression Training with Gradient Descent[J].Information Sciences,2021,552:183-200.
猜你喜欢
阅读与作文(英语初中版)(2021年8期)2021-09-13
电脑爱好者(2020年6期)2020-05-26
阅读(低年级)(2019年2期)2019-04-19
中国计算机报(2018年30期)2018-11-12
民间故事选刊·上(2018年1期)2018-01-02
中学生理科应试(2017年7期)2017-08-09
课堂内外(小学版)(2017年5期)2017-06-07
小小说月刊·下半月(2016年6期)2016-05-14
故事会(2015年19期)2015-05-14
数码精品世界(2009年3期)2009-03-30
